Google资源管理器简析


9.2.2 Borg[1]
Borg是一个集群管理器,负责对来自几千个应用程序所提交的Job进行接收、调试、启动、停止、重启和监控,这些Job将用于不同的服务,运行在不同数量的集群中,每个集群各自可包含最多几万台服务器。Borg的目的是让开发者能够不必操心资源管理的问题,让他们专注于自己的工作,并且做到跨多个数据中心的资源利用率最大化。图9.2描述了Borg的主要架构。
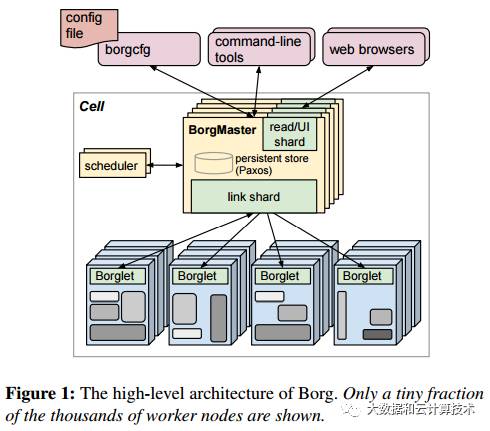
图9.2
该架构中包含了以下几个组件。
单元(Cell):将多台机器的集合视为一个单元。单元通常包括1万台服务器,但如果有必要的话也可以增加这个数字,它们各自具有不同的CPU、内存、磁盘容量等。
集群:一般来说包含了一个大型单元,有时也会包含一些用于特定目的的小单元,其中有些单元可以用作测试。一个集群通常来说限制在一个数据中心大楼里,集群中的所有机器都是通过高性能的网络进行连接的。一个网站可以包含多个大楼和集群。
Job:一种在单元的边界之内执行的活动。这些Job可以附加一些需求信息,例如CPU、OS、公开的IP等。Job之间可以互相通信,用户或监控Job也可以通过RPC方式向某个Job发送命令。
Task:一个Job可以一个或多个任务组成,这些任务在同一个可执行进程中运行。这些任务通常直接运行在硬件上,而不是在虚拟环境中运行,以避免虚拟化的成本。任务的程序是静态链接的,以避免在运行时进行动态链接。
分配额(Alloc):专门为一个或多个任务所保留的机器资源集。分配额能够与运行于其上的任务一起被转移到一台不同的机器上。一个分配额集表示为某个Job保留的资源,并且分布在多台机器上。
Borglet:一个运行在每台机器上的代理。
BorgMaster:一个控制器进程,它在单元级别上运行,并保存着所有Borglet上的状态数据。BorgMaster将Job发送到某个队列中以执行。BorgMaster和它的数据将会进行5次复制,数据将被持久化在一个Paxos存储系统中。所有的BorgMaster中有一个领导者。
调度器:对队列进行监控,并根据每台机器的可用资源情况对Job进行调度。
Borg系统的使用者将向系统提交包含了一个或多个任务的Job,这些任务将共享同样的二进制代码,并在一个单元中执行,每个Borg单元由多台机器组成。在这些单元中,Borg会组合两种类型的活动:一种是如Gmail、GDocs、BigTable之类的长期运行服务,这些服务的响应延迟很短,最多为几百毫秒;另一种是批量处理的Job,它们无须对请求进行即时响应,运行的时间也可能会很长,甚至是几天。第一种类型的Job被称为prodjob(生产Job),它们相对于批量Job来说优先级更高;第二种类型的Job被认为非生产环境中的Job。生产Job能够获得一个单元的CPU资源中的70%,并且占用所有CPU数量的大约60%,还能分配到55%的内存,并占用其中的大约85%。
某些单元的任务量是每分钟接受1万个新的任务,而一个BorgMaster能够使用10~14个CPU内核,以及50GB的内存。一个BorgMaster能够实现99.99%的可用性,但即使某个BorgMaster或Borglet出现停机状况,任务也能够继续运行。有50%的机器会运行9个或9个以上的任务,而某些机器能够在4500个线程中运行25个任务。任务的启动延迟平均时间是25秒,其中的20秒用于安装包。这些等待时间中的大部分与磁盘访问有关。
这套系统的主要安全机制是LinuxChroot Jail及SSH,通过Borglet进行任务调试的工作。对于运行在GAE或GCE中的外部软件,Google将使用托管的虚拟机作为一个Borg任务在某个KVM进程中运行。
Google在过去十年间在生产环境上所学到的某些经验与教训已经应用在Kubernetes的设计上:对属于同一服务的job的操控能力、一台机器多个IP地址、使用某种简化的Job配置机制、使用PODS(其作用与分配额相同)、负载均衡、深度反思为用户提供调试数据的方式。
9.2.3 Omega
1.背景
Google的论文Omega:flexible,scalable schedulersfor large compute clusters中把调度分为3代:第一代是独立的集群;第二代是两层调度(Mesos,YARN);第三代是共享状态调度,如图9.3所示。

图9.3
2.架构
为了克服双层调度器的局限性,Google开发了下一代资源管理系统Omega。Omega是一种基于共享状态的调度器,该调度器将双层调度器中的集中式资源调度模块简化成了一些持久化的共享数据(状态)和针对这些数据的验证代码,而这里的“共享数据”实际上就是整个集群的实时资源使用信息。一旦引入共享数据后,共享数据的并发访问方式就成为该系统设计的核心。而Omega则采用了传统数据库中基于多版本的并发访问控制方式(也称为“乐观锁”,Multi-VersionConcurrency Control,MVCC),大大提升了Omega的并发性。由于Omega不再有集中式的调度模块,因此,不能像Mesos或者YARN那样,在一个统一模块中完成以下功能:对整个集群中的所有资源分组;限制每类应用程序的资源使用量;限制每个用户的资源使用量等。这些功能全部由各个应用程序调度器自我管理和控制。根据论文所述,Omega只是将优先级这一限制放到了共享数据的验证代码中,即当多个应用程序同时申请同一份资源时,优先级最高的那个应用程序将获得该资源,其他资源限制全部下放到各个子调度器。引入多版本并发控制后,限制该机制性能的一个因素是资源访问冲突的次数,冲突次数越多,系统性能下降得越快。而Google通过实际负载测试证明,这种方式的冲突次数是完全可以接受的。该论文中还谈到,Omega是从Google现有系统中演化而来的。既然这篇论文只介绍了Omega的调度器架构,我们可推测它的整体架构类似于Mesos。这样,如果你了解Mesos,那么就可知道,我们可以通过仅修改Mesos的Master将之改造成一个Omega。
3.优缺点
(1)优点:共享资源状态,支持更大的集群和更高的并发。
(2)缺点:只有论文,无具体实现,在小集群下没有优势。
本文选自本人新作《大数据架构详解:从数据获取到深度学习》9.2节。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2017-02-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号