实时音视频-小程序端WebRTC互通
原创
实时音视频-小程序端WebRTC互通
原创
用户6610288
修改于 2019-11-01 10:27:55
修改于 2019-11-01 10:27:55
版本支持
我们在 LiteAVSDK 的最新版本里面加入了对 WebRTC 的支持能力,并且已经跟随微信APP的 6.6.6 版本发布出来,此文档主要介绍如何使用原生的 <live-pusher> 和 <live-player> 标签实现 WebRTC 互通能力。
接入成本
此文档介绍的方法接入成本偏高,适合喜欢全面定制的同学;我们同步提供了一套封装度更高的自定义组件方案 —— <webrtc-room> ,更加推荐您来使用。
接入流程
step1. 开通云服务
小程序跟 WebRTC 的互通是基于实时音视频(TRTC)服务实现的,需要开通该服务。
注册账号之前点先领取腾讯云2860元代金券,用于购买腾讯云CVM云服务器、云数据库产品时可以用来抵用,节约财务成本。
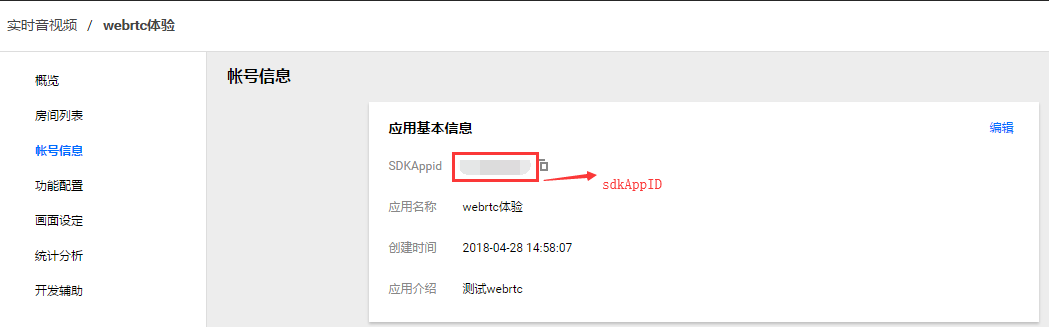
- 从实时音视频控制台获取
sdkAppID、accountType、privateKey,在 step4 中会用的:
step2. 生成key信息
按照如下表格获取关键的key信息,这是使用腾讯云互通直播服务所必须的几个信息:
KEY | 示例 | 作用 | 获取方案 |
|---|---|---|---|
sdkappid | 1400087915 | 用于计费和业务区分 | 上文中有介绍 |
userid | xiaoming | 用户名 | 可以由您的服务器指定,或者使用小程序的openid |
usersig | 加密字符串 | 相当于 userid 对应的登录密码 | 由您的服务器签发(PHP / JAVA) |
roomid | 12345 | 房间号 | 可以由您的服务器指定 |
privateMapKey | 加密字符串 | 进房票据:相当于是进入 roomid 的钥匙 | 由您的服务器签发(PHP / JAVA) |
下载 sign_src.zip 可以获得服务端签发 usersig 和 privateMapKey 的示例代码。
生成 usersig 和 privateMapKey 的签名算法是 ECDSA-SHA256。
step3. 获取roomsig
小程序端可以通过如下 url 向腾讯云请求 roomsig,roomsig 是小程序跟 WebRTC 互通必须的关键信息,请求 roomsig 所使用的关键信息已经在 step2 中做了详细描述 (这里的 identifier 就是上文中的 userid ):
https://official.opensso.tencent-cloud.com/v4/openim/jsonvideoapp?
sdkappid=xxx&identifier=xiaoming&usersig=yyy&random=9999&contenttype=jsonbody:
{
"ReqHead":
{
"Cmd":1, //命令字,固定填1
"SeqNo":1, //请求序列号,uint32
"BusType": 7, //业务类型,固定填7
"GroupId": 10001 //群组Id(房间Id),uint32
},
"ReqBody":
{
"PrivMap": 255, //非必填,明文权限位
"PrivMapEncrypt": "ed868cdc281d8b", //必填,权限位加密串
"IsIpRedirect": 0, //非必填,默认0;0非重定向;1是重定向
"TerminalType": 1, //必填,终端类型,对应0x109中的TERMINAL_TYPE;Android:4;ios:2;
"FromType": 3, //必填,请求来源类型:1:avsdk;2:webrtc;3:微信小程序;
"SdkVersion": 26280566 //非必填,整型版本号
}
}Attention: 获取roomsig的操作必须在客户端完成,后台完成会引入选路错位问题,导致视频卡顿严重。
step4. 拼装URL
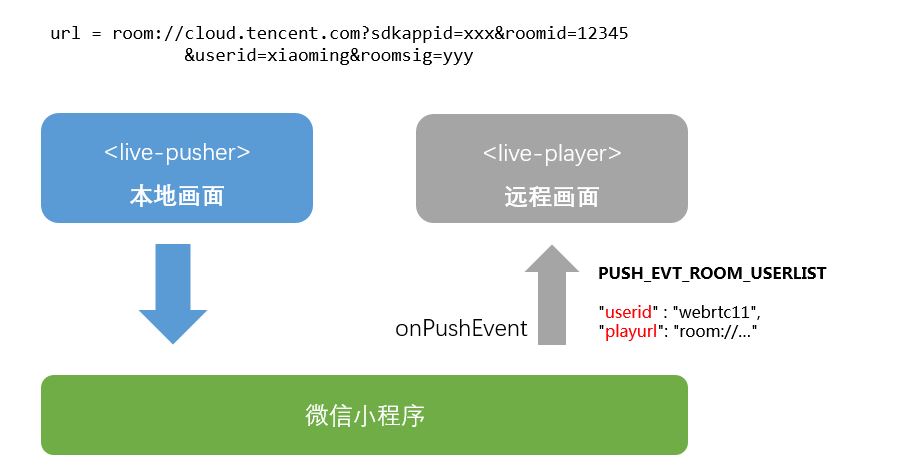
如果希望将小程序跟 WebRTC 打通,不能使用普通的 rtmp:// 推流地址,而是使用新的 room:// 协议的推流地址,该地址的格式如下:
room://cloud.tencent.com?sdkappid=xxx&roomid=12345&userid=xiaoming&roomsig=yyystep5. 加入(或创建)房间
在小程序的 <live-pusher> 标签里,指定 url 属性为 step4 中拼装出的url,这相当于进入指定的 roomid, <live-pusher> 的 视频画面会显示本地摄像头的影像。
如果您指定的 roomid 是第一次使用,腾讯云后台会自动为您创建一个房间号为 roomid 的房间。
step6. 远程的视频画面
step5 解决了本地camera画面的问题,远程的画面怎么获取呢?
当 <live-pusher> 开始推流后,腾讯云会通过 onPushEvent (PUSH_EVT_ROOM_USERLIST = 1020) 通知您的小程序代码:房间里还有哪些人?
当有新的人加入房间以后,<live-pusher> 也会重新通知 onPushEvent (PUSH_EVT_ROOM_USERLIST = 1020),这样客户可以根据 ROOM_USERLIST 的变化,了解房间里有哪些人进入了,或者哪些人离开了。
ROOM_USERLIST 里每一项都是一个二元组(如果是 1v1 的视频通话,ROOM_USERLIST 里只会有一个人): userid 和 playurl。 userid 代表是哪个用户, playurl 则是这个用户远程画面的播放地址。
ROOM_USERLIST内容格式如下:
{
"userlist": [
{
"userid": "webrtc11",
"playurl": "room://183.3.225.15:1935/webrtc/1400037025_107688_webrtc11"
},
{
"userid": "webrtc12",
"playurl": "room://183.3.225.15:1935/webrtc/1400037025_107688_webrtc12"
}
]
}之后,使用 <live-player> 标签,并指定 src 为 ROOM_USERLIST 里的 playurl, 即可看到远程画面了。
小程序跟 WebRTC 的互通是基于实时音视频(TRTC)服务实现的,需要开通该服务。
注册账号之前点先领取腾讯云2860元代金券,用于购买腾讯云CVM云服务器、云数据库产品时可以用来抵用,节约财务成本。
1、腾讯云产品3折特惠,热门云产品3折起,服务更稳,速度更快,价格更优
step7. Chrome 对接
了解腾讯云官网的 webrtc 服务,可以对接 Chrome 端的 H5 视频通话,因为不是本文档的重点,此处不做赘述。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
作者已关闭评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号