[CVPR 2022 | 论文简读] 视觉语言表征学习的统一Transformer

[CVPR 2022 | 论文简读] 视觉语言表征学习的统一Transformer

智能生信
发布于 2022-12-29 17:02:44
发布于 2022-12-29 17:02:44
简读分享 | 汪逢生 编辑 | 赵晏浠
论文题目
UFO: A UniFied TransfOrmer for Vision-Language Representation Learning
论文摘要
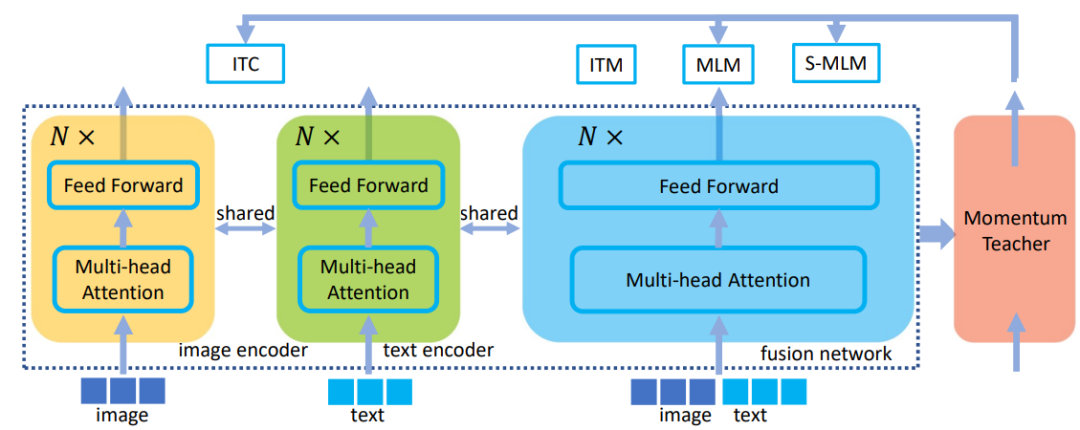
视觉语言表征学习的统一Transformer 论文摘要: 在本文中,作者提出了一种统一Transformer(UFO),它能够处理单模态输入(例如图像或语言)或多模态输入(例如图像和问题的concatenation),用于视觉语言(VL)表示学习。现有方法通常为每个模态设计一个单独的网络和或为多模态任务设计一个特定的融合网络。为了简化网络结构,作者使用单个Transformer网络,在VL预训练期间实施多任务学习,包括图像文本对比损失、图像文本匹配损失和基于双向和seq2seq注意力掩码的mask语言建模损失。在不同的预训练任务中,相同的Transformer网络用作图像编码器、文本编码器或融合网络。根据实验,作者观察到不同任务之间的冲突较少,在视觉问答、COCO图像字幕(交叉熵优化)和nocaps(SPICE)方面达到了新的水平。在其他下游任务上,例如图像文本检索,UFO也取得了有竞争力的性能。
论文链接
https://arxiv.org/abs/2111.10023
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-10-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号