数据虚拟视图定位与智能化实现



随着企业数据应用的深化,尤其是低代码开发理念的提出,业务人员能便捷地看数和用数,即业务人员在其业务分析场景构思完成后,可以快速实现数据分析,进行论证和调整,成为数据应用效率和成效提升的关键。
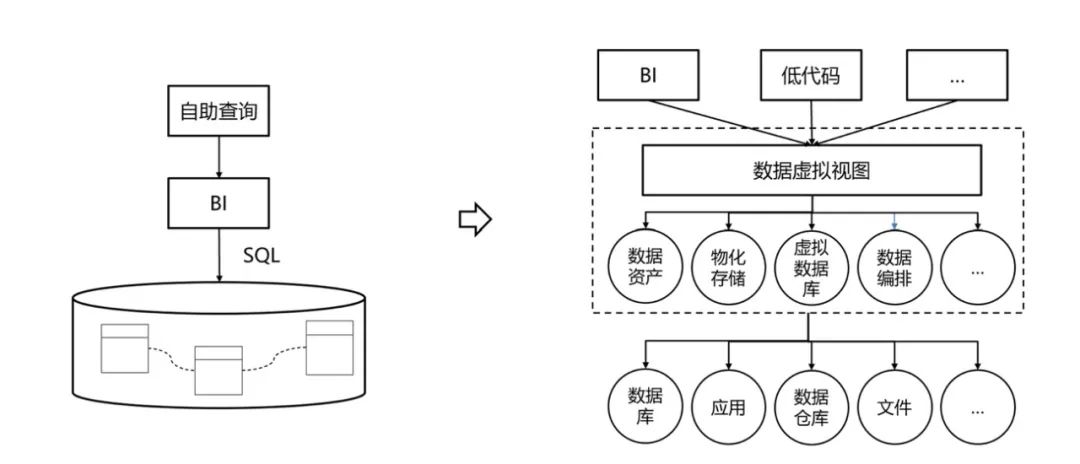
传统数据分析多由技术人员进行数据准备、分析模型实现、报表或主题分析界面开发等工作,如果业务需求与技术实现存在偏差,就需要多次调整,时效性较差。例如:企业部门管理者对下属销售人员进行效能分析,以部门主营业务视角,分析销售人员主要客群、商机转化、执行力等影响业绩因素,涉及的商机、合同、合同相关产品或服务、客户、客户行业板块等数据在CRM系统;收款、收入、成本、利润等数据在财务系统。那么就需要此部门提交需求,由技术人员进行数据同步、融合处理、报表展示等开发工作。
目前各种 BI 软件,虽然具备了“自助报表”能力,可以让业务人员根据数据库表,自助配置查询或者报表,但存在如下问题:
1)对于多表关联的情况,自定义查询依旧比较复杂,不能像单表(宽表)那样使用简便,还会出现关联过多,查询性能低,过多占用数据库资源的问题;
2)自助查询的数据必须依赖于预置式构建,无法穷尽所有数据组合,业务人员不能构建数据集;
3)数据必须物理存在于中央存储中,通过 ETL 形式复制数据,无法直接针对源系统进行查询。
为了解决上述问题,我们考虑引入数据编织的设计理念,数据编织是一种跨平台的数据动态整合方式,以连接替代收集,构建对不同系统数据的虚化连接网络。在数据编织的能力之上我们可以实现一种数据虚拟视图体系,通过数据虚化连接构建数据分析所需的个性化数据集;同时根据不同场景,利用物化存储、数据编排、内存计算、虚拟数据库等多种方式,智能化选择数据虚拟视图的实现。通过这种手段,在数据分析时能够自助实现灵活的数据集定义,同时可以利用 BI/低代码工具,基于适合的数据集做自助查询。
01
基于业务化数据资产的多源数据编织,
便于自助查询
虚拟视图是在业务人员或者数据分析师有分析需求时,基于数据资产目录进行检索,选定涉及的数据资产,根据数据资产的元数据选择某些维度和指标,并根据需要配置相关计算公式,由虚拟视图平台进行实时构建,组装为分析所需的个性化数据集,提供给报表、BI、机器学习、隐私计算等工具做为数据源,使业务人员或数据分析师自助化构建分析数据集和实现分析工作。
虚拟视图需要对不同来源系统数据,进行多模式数据库适配,在逻辑层定义一致化语义,实现逻辑连接,包括关联、组合、嵌套等连接形式,还涉及分组聚合、分支判断等逻辑规则,根据相应的规则配置智能生成数据访问路径,根据路径节点分布生成不同数据源的多模式数据访问SQL,将多源查询结果自动化归并融合,支持拼接、包含等多种合并方式,形成最终结果数据集,并且要考虑大小表关联、嵌套查询、数据拼接、查询条件等优化策略。
这样就可以对虚拟视图网络能够触达的系统数据进行数据分析,大大扩展了数据范围,使数据分析能超越数据湖/数据仓库限制,由中心集中式,变为结合虚拟视图的广域覆盖式。对于虚拟视图与数据仓库区别,首先,在于适配不同场景,虚拟视图是用来满足基于个性化数据集进行的个性化数据分析工作,数据仓库用于满足普适通用场景下,基于固化数据集的数据分析工作;其次,虚拟视图更多是以一个宽表形态的结果集呈现,数据仓库则是包含事实表、维表等数仓模型的体系结构。
虚拟视图也可以和数据仓库有机结合,对于一些高频使用的虚拟视图,可转化为为数据仓库中固化的事实表,使之成为广泛、普适的分析场景。
02
虚化与物化的智能化转换,
提高数据查询的性能
虚拟视图并不意味不做持久化,反而通过物化存储,可发挥临时、缓冲的作用,提供高效的性能支撑,使数据查询的反馈效率更快。但什么时候、什么场景进行物化存储,则需要掌握虚化与物化的划分策略,根据场景智能化选择,并且在一定情况下可以动态灵活转换,从而更有效地利用资源,对用户得到最佳体验。
在虚拟视图进行物化存储时,需要考虑存储架构、生存周期、数据更新等方面设计:
- 存储架构:虚拟视图的物化存储不是以长周期和大量数据存储为目的,且存在高频读写的场景,因此不适用数据湖和传统hadoop平台的存储架构,可采用PostgreSQL、ClickHouse、Redis、Ignite等相对高吞吐、高并发存储架构。
- 生存周期:虚拟视图需要进行严格的生存周期管理,包括视图自身的生存周期以及物化存储数据生存周期,对不使用的虚拟视图进行销毁,对已过期的物化存储数据进行删除。
- 数据更新:物化存储就必然存在数据更新的问题,从更新策略上来看,分为全量和增量:全量更新可一次性构建或者在每次分析前初始化数据;增量更新,可依据时间戳或顺序增长主键等条件进行数据更新。从更新频度上看,以定时更新为主,粒度可从准实时至长周期。根据虚拟视图的定义以及源系统的情况,可以智能化生成相应的ETL过程,同时对 ETL 过程进行监控,实现物化存储的自动化。
这里未考虑实时的原因,是因为需要实时的场景,几乎不太会进行物化存储,并且准实时可以做到分钟级,就可以解决大部分分析场景需求。
03
多级递进的数据筛选编排,
支撑更丰富的数据场景
虚拟视图可以有更充分的数据准编排过程,很多数据分析场景,需要从大的数据集中进行筛选获得最终结果,因此虚拟视图要能够对构建的数据集,通过一定的过滤或分组条件,形成新的数据集,并且可多次进行此类操作。
多级的数据筛选编排,不应由多个虚拟视图组成,因为这样对用户而言,无论配置还是使用都具有较高复杂度,应该是在一个虚拟视图中包含多个分层级的数据集,层级间是从大到小的数据集序列,且数据集间存在递进降维关系。
实现方式是通过最初数据集,进行一定数据筛选后,将其子集形成新的数据集,并还可再次进行筛选操作,最终存在多个从大到小的数据集,形成了多级的数据集序列,这些数据集可一并提供给用户进行数据分析使用,用户可以从多层级的数据集中获取结果,构建复杂数据分析,包括多维钻取、级联操作等,或者通过多级数据集构建一个多元素的分析主题。
04
模拟现实的虚拟数据库,
实现数据源的无感切换
虚拟视图需要被报表、BI、机器学习、隐私计算等分析工具调用,但虚拟视图并非实体数据库,即便虚拟视图进行物化,也是根据场景有不同策略。那么,虚拟视图如何被上层应用调用,就是一个关键问题。
基础的实现方式,是通过RESTFul API或SDK等方式供上层应用调用,这就需要上层应用具备API数据源的能力,或集成SDK,需要有一定的适配工作。很多分析应用原有的数据分析调用都是数据库连接方式,这样历史的分析功能就很难迁移到虚拟视图进行支撑。
更智能、更便捷的实现方式,是将虚拟视图以虚拟数据库方式提供使用,上层应用可以通过JDBC驱动连接,虚拟数据库支持标准SQL语法集,这样对于用户,甚至感受不到后端变化,原有的分析功能也可以做无感切换,提供最极致的体验。
05
与上下游系统通力集成,
形成整体解决方案
虚拟视图不是孤立存在的,它需要与企业数据领域相关工具进行集成,更好支撑数据分析场景,并遵循企业数据治理和数据安全规范,实现数据统一管控应用目标。虚拟视图需要具备与如下平台系统集成:
- 与数据库系统集成,包括关系数据库、Hadoop平台、列式数据库、内存数据库、文档数据库等,适配数据库连接和SQL方言。
- 与数据资产目录或数据资产管理系统集成,通过数据资产目录或数据资产管理系统获取所需的数据资产,以及数据资产相关的元数据信息。
- 与上层应用集成,将虚拟视图作为一个虚拟数据源,以数据库连接、API、SDK、插件等方式进行集成,使上层应用可以连接并读取虚拟视图数据集信息和具体数据。
- 与数据安全管理系统集成,读取数据安全分级以及脱敏、加密保护要求,虚拟视图在形成结果集时,对相关字段进行数据脱敏或加密操作。
本文通过对虚拟视图剖析,为低代码方式进行数据分析的创新建设,提供了一种新颖的解决方案思路,并给出虚拟视图支撑平台构建的关键要点,即利用智能化方式提高虚拟视图的性能,管理数据生命周期。
基于虚拟视图,业务人员或数据分析师可以便捷构建数据集,从而不依赖技术人员,自助完成业务分析工作,这样一方面可以在其业务创新点思考产生时,即时进行验证,提升业务创新效率;另一方面也可以降低业务需求与技术实现差异,减少因沟通不够细致导致的结果偏差,更有效地发挥数据价值。因此,虚拟视图必将是当下数字化转型发展中,一个重要的探索和建设方向。
关于作者:

李书超,普元信息大数据首席顾问。全面主持普元数据领域方案、产品规划建设,近20年数据领域咨询设计与项目建设经验,主导普元信息公司数据方案产品规划与研发,带领团队成功研发了普元信息公司数据中台系列产品,应用并服务了政务、金融、电信、能源、制造、工程建筑、物流、航空等多行业大型客户。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-12-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号