「阿里」SCI:基于子空间学习的个体干预效果(ITE)估计方法

「阿里」SCI:基于子空间学习的个体干预效果(ITE)估计方法

秋枫学习笔记
发布于 2023-01-30 15:13:43
发布于 2023-01-30 15:13:43

关注我们,一起学习~
标题:SCI: Subspace Learning Based Counterfactual Inference for Individual Treatment Effect Estimation 地址:https://dl.acm.org/doi/10.1145/3459637.3482175 会议:CIKM 2021 公司:阿里
1. 导读
本文是一篇短文,针对因果效应预估方面提出的方法,现有的表征学习方法侧重于学习一个平衡的特征空间,而忽略了某些预测结果的信息。为了充分利用预测信息,本文提出了一种基于子空间学习的反事实推理(SCI)方法来估计个体因果效应(ITE)。
2. 方法

本文的思路是比较直观的,如图所示即将表征学习分成三个子模块,分别学习公共部分和干预的部分,然后将得到的输出进行拼接,结合相应的分布约束和重构损失来促进学习。总体损失函数如下,接下来分别介绍各个部分。
2.1 对照子空间
这部分的目的是去学习对照组数据特有的信息,通过DNN
学习得到对照组数据的表征Z,然后有两个输出,一方面通过linear层预测对照的伪输出
,这部分输出可以构建相应的损失函数,如下所示,
为对应的标签,T为是否干预。这里只是单纯的采用对照组数据进行学习,存在样本偏差,因此输出为伪输出,当伪输出接近标签时,学到的表征Z也就更能反映对照组的信息。
另一方面的输出,是将表征Z送入后续的模块进行拼接和预测。
2.2 干预子空间
和对照子空间同理,干预子空间也是采用干预组的数据进行相应的学习,同样可以构建类似的损失函数。
2.3 公共子空间
前面两个子空间分别学习对照和干预特定的信息,公共子空间用于学习两者的公共信息,这部分采用对照和干预的所有数据,表征表示为
,通过类似CFR中的IPM对其中的对照组和干预组的表征的分布进行约束,可以采用mmd,Wasserstein距离等方式构建分布约束损失
。
2.4 子空间结合
公共子空间学习的表征可能不足以进行结果预测,而干预,对照子空间学习到的表征可能有限。为了克服使用单个子空间的不足,SCI从公共子空间和干预,对照子空间学习到的规范化表征拼接起来,然后利用HSIC(希尔伯特-施密特独立性准则)进行约束,损失函数如下。对消化损失函数的过程中,可以使表征X与干预T的关联性更弱。
2.5 重构和预测
为了使级联表征更有意义,SCI引入了解码器网络
,
重建原始的输入数据:
,
重构损失计算如下,
并且利用拼接后的数据进行相应的预测,构建预测值与真实值之间的损失函数,如下所示,
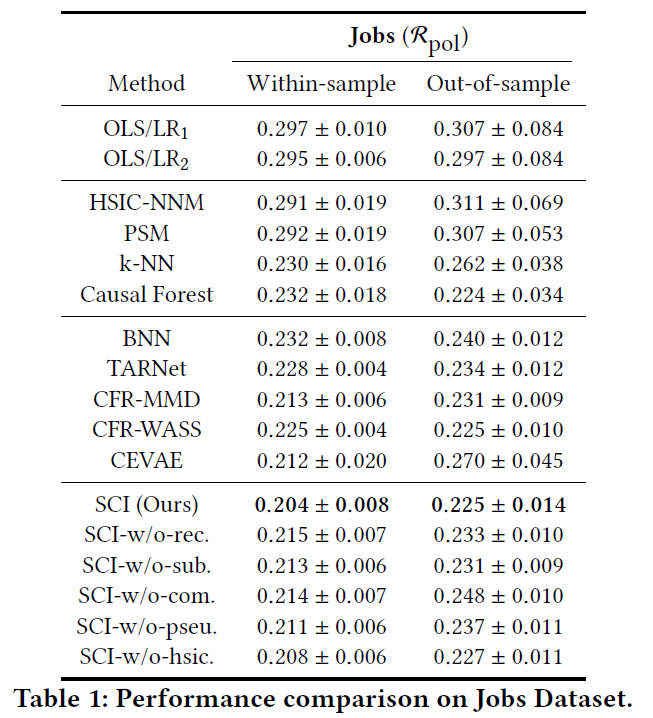
3. 结果
在真实数据集Jobs和生成的数据集上能够取得不错的效果。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-10-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号