关于Linux中使用USE(使用率/饱和度/错误)方法分析系统性能的一些笔记

关于Linux中使用USE(使用率/饱和度/错误)方法分析系统性能的一些笔记

山河已无恙
发布于 2023-01-30 15:22:26
发布于 2023-01-30 15:22:26
1写在前面
- 今天和小伙伴们分享通过
USE方法对系统进行性能分析和性能调整 - 博文内容涉及:
- 什么是USE方法,以及USE的使用建议
- 具体的USE指标采集分析
- 食用方式: 需要Linux基础知识
- 理解不足小伙伴帮忙指正
傍晚时分,你坐在屋檐下,看着天慢慢地黑下去,心里寂寞而凄凉,感到自己的生命被剥夺了。当时我是个年轻人,但我害怕这样生活下去,衰老下去。在我看来,这是比死亡更可怕的事。--------王小波
如果说希望通过USE做一些调优的工作,我觉得还是需要一定的能力的,但是我们可以通过USE来定位机器的性能瓶颈,做一些排故工作。比如机器上的应用发生某些已知的未知故障,比如客户感知卡顿,工单流转,编排,调度任务等特别慢的情况,希望确认是机器性能问题,还是应用程序问题,这个时候,使用USE方法是一个很好的策略。
2USE方法
USE方法(utilization、saturation、errors)可以用于性能研究,用来识别系统瓶颈,同时有感知故障,可以定位问题。
关于什么是USE?即围绕服务器物理元器件(CPU、内存等资源),某些软件资源也能算在内,通过使用率、饱和度和错误三个指标的采集分析,对系统进行性能研究,在故障发生前发现系统瓶颈。
- 使用率 :在规定的时间间隔内,
资源用于服务工作的时间百分比。虽然资源繁忙,但是资源还有能力接受更多的工作,不能接受更多工作的程度被视为饱和度。 - 饱和度 :资源不能再服务更多额外工作的程度,通常有
等待队列。 - 错误 :错误事件的个数。
这里需要注意的是:某些资源类型,比如内存,磁盘使用率指的是资源所用的容量。这与基于时间的定义是不同的,比如CUP等,一旦资源的容量达到100%的使用率,就无法接受更多的工作,资源或者会把工作进行排队(饱和),或者会返回错误,用USE方法也可以予以鉴别。错误需要调查,因为它们会损害性能`,如果故障模式是可恢复的,有对应的容灾策略,错误可能难以立即察觉。这包括操作失败重试,还有冗余设备池中的设备故障。
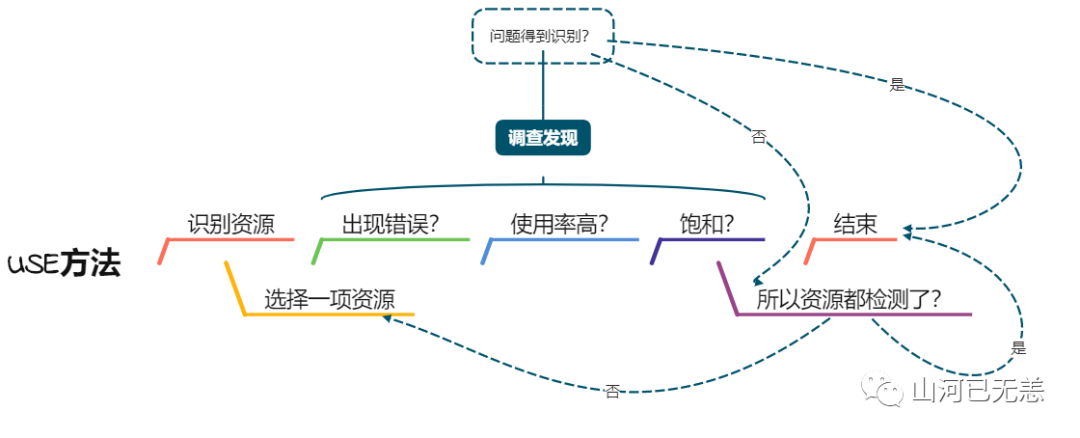
通过上面的方法辨别出的很可能是系统瓶颈问题。不过,一个系统可能不只面临一个性能问题,可能一开始就能找到问题,但所找到的问题并非你关心的那个。在根据需要返回USE方法遍历其他资源之前,每个发现可以用更多的方法进行调查,z需要查阅相关的资料。
当然有那种很明显的情况。由客户感知或者指标监控发现 ,通过全局的观测工具可以很快定位问题的那种,往往不需要通过USE流程方法:
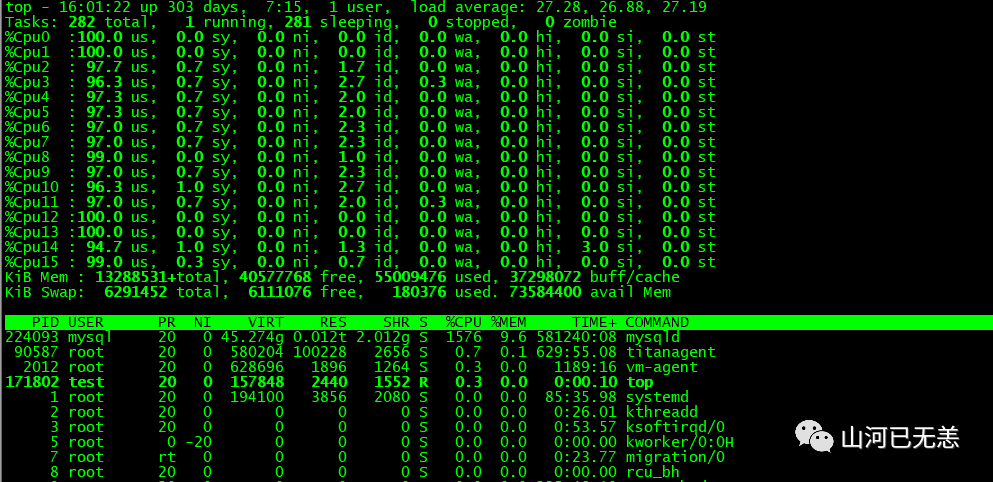
如上面的这个图片。我们可以看到明显的问题,top 命令中,mysql进程CUP相关指标明显异常,从三个地方可以看到:
- 系统平均负载:最上面的CUP负载,
load average:27.28,,26.88,27.19为CPU最近1/5/15分钟的平均负载,负载平均数超过了CPU数量通常代表CPU饱和。当前核数为16核,即CPU不足以服务线程.
平均负载表示了对CPU资源的需求,一个有64颗CPU的系统的平均负载为128。这意味着平均每个CPU上有一个线程在运行,还有一个线程在等待。而同样的系统,如果平均负载为10,则代表还有很大的余量,在所有CPU跑满前还可以运行54个CPU消耗型线程。但是
Linux平均负载除了CPU还把不可中断状态执行磁盘I/O的任务也计入平均负载。
- 单个CPU饱和:top命令+1 展示每个cup的负载情况,
us项为用户进程消耗CUP使用率,sy为系统进程消耗,id为当前CPU的空闲,从us和id项可以看出,当前多个CUP饱和,空闲率为0 - 进程CPU利用率近饱和:top的进程列表可以看到,当前 mysqld 的进程,主内存(%MEM)占比为9.6,
CPU占比(%CPU)为1576(16c为1600m),占比近100%,成饱和状态,而且TIME值也不太正常,进程虚拟内存使用总量(VIRT)为45.274g(包括了应用程序分配到但未使用的全部内存),共享内存(SHR)为2.012g,应用程序实际使用的物理内存总量(RES)为0.012t(12.288g)。总内存为126g,所以应该不是内存方面的问题,不存在泄露之类的情况
$ free -h
total used free shared buff/cache available
Mem: 126G 44G 25G 2.5G 57G 79G
Swap: 6.0G 851M 5.2G
$
通过上面的简单指标查看,可以推断mysqld进程异常,多个CPU呈现饱和状态,可能存在着类似死循环的操作,不断的创建线程,导致CUP饱和。进而我们可以排查mysqld服务的进程信息 show processlist;。后排查发现确实存在。kill掉对应的外挂,mysqld恢复正常,然后排查外挂的问题。
指标表述
USE方法的指标通常如下。
使用率:一定时间间隔内的百分比值(例如,“单个CPU运行在90%的使用率上”)。饱和度:等待队列的长度(例如,“CPU的平均运行队列长度是4”)。错误:报告出的错误数目(例如,“这个网络接口发生了50次滞后冲突”)。
即便整体的使用率在很长一段时间都处于较低水平,一次高使用率的瞬时冲击还是能导致饱和与性能问题的。某些监控工具汇报的使用率是超过5分钟的均值。所以指标监控要
举个例子,每秒的CPU使用率可以变动得非常剧烈,因此5分钟时长的均值可能会掩盖短时间内100%的使用率,甚至是饱和的情况。
想象一下高速公路的收费站。使用率就相当于有多少收费站在忙于收费。使用率100%意味着你找不到一个空的收费站,必须排在别人的后面(饱和的情况)。如果我说一整天收费站的使用率是40%,你能判断当天是否有车在某一时间排过队吗?很可能在高峰时候确实排过队,那时的使用率是100%,但是这在一天的均值上是看不出的。
资源列表
USE方法的第一步是要建一张资源列表,要尽可能完整。下面是一张服务器通常的资源列表,配有相应的例子。
- CPU:插槽、核、硬件线程(虚拟CPU)
- 内存:DRAM
- 网络接口:以太网端口
- 存储设备:磁盘
......
每个组件通常作为一类资源类型。例如,内存是一种容量资源,网络接口是一类I/O资源(IOPS或吞吐量)。有些组件体现出多种资源类型:例如,存储设备既是I/O资源也是容量资源。这时需要考虑到所有的类型都能够造成性能瓶颈,同时,也要知道I/O资源可以进一步被当作排队系统来研究,将请求排队并被服务。
某些物理资源,诸如硬件缓存(如CPU缓存),可能不在清单中。USE方法是处理在高使用率或饱和状态下性能下降的资源最有效的方法,当然还有其他的检测方法。如果你不确定清单是否该包括一项资源,那就包括它,看看在实际指标中是什么样的情况。
指标
一旦你掌握了资源的列表,就可以考虑这三类指标:使用率、饱和度,以及错误。下表列举了一些资源和指标类型,以及一些可能的指标(针对一般性的OS)。这些指标要么是一定时间间隔的均值,要么是累计数目。
资源 | 类型 | 指标 |
|---|---|---|
CPU | 使用率 | CPU使用率(单CPU使用率或系统级均值) |
CPU | 饱和度 | 分配队列长度(又名运行队列长度) |
内存 | 使用率 | 可用空闲内存(系统级) |
内存 | 饱和度 | 匿名换页或线程换出(页面扫描是另一个指标),或者OOM事件 |
网络接口 | 使用率 | 接收吞吐量/最大带宽,传输吞吐量/最大带宽存储设备/O使用率设备繁忙百分比存储设备/O饱和度等待队列长度 |
存储设备/O | 错误 | 设备错误(“硬错误”、“软错误”) |
重复所有的组合,包括获取每个指标的步骤,记录下当前无法获得的指标,那些是已知的未知。最终你得到一个大约30项的指标清单,有些指标难以测量,有些根本测不了。所幸的是,常见的问题用较简单的指标就能发现(例如,CPU饱和度、内存容量饱和度、网络接口使用率、磁盘使用率),所以这些指标要首先测量。
一些较难的组合示例可见下表
资源 | 类型 | 指标 |
|---|---|---|
CPU | 错误 | 例如,可修正的CPU缓存ECC事件,或者可修正的CPU故障(如果操作系统加上硬件支持) |
内存 | 错误 | 例如,失败的malloc()(虽然这通常是由于虚拟内存耗尽,并非物理内存) |
网络 | 饱和度 | 与饱和度相关的网络接口或操作系统错误,例如,Linux的overrun和Solaris的nocanput |
存储控制器 | 使用率 | 取决于控制器,针对当前活动可能有最大IOPS或吞吐量可供检查 |
CPU互联 | 使用率 | 每个端口的吞吐量/最大带宽(CPU性能计数器) |
内存互联 | 饱和度 | 内存停滞周期数,偏高的平均指令周期数(CPU性能计数器) |
I/O互联 | 使用率 | 总线吞吐量/最大带宽(可能你的硬件上有性能计数器,例如,Intel的“非核心”事件) |
上述的某些指标可能用操作系统的标准工具是无法获得的,可能需要使用动态跟踪或者用到CPU性能计数工具。
使用建议
对于使用上述这些指标类型,这里有一些总体的建议。
- 使用率 :
100%的使用率通常是瓶颈的信号(检查饱和度并确认其影响)。使用率超过60%可能会是问题,基于以下理由:时间间隔的均值,可能掩盖了100%使用率的短期爆发- 一些资源,诸如硬盘(不是CPU),通常在操作期间是不能被中断的,即使做的是优先级较高的工作。随着使用率的上升,排队延时会变得更频繁和明显。
关于为什么是60%使用率,基于排队理论,随着使用率的增加,资源的响应时间成本增加,类似于幂函数 y=x^2
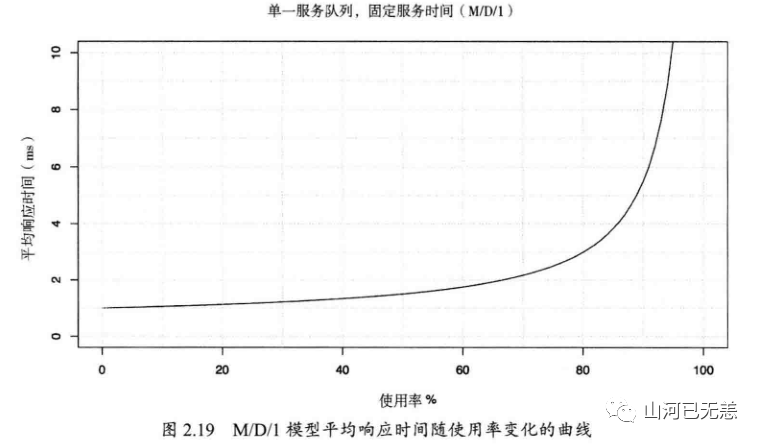
使用率超过60%,平均响应时间会变成两倍。在80%时,平均响应时间变成了三倍。 磁盘I/0延时通常是应用程序的资源限制,两倍或更多的平均延时增加会给应用程序带来显著的负面影响。
排队系统内的请求是不能被打断的(通常而言),必须等到轮到自己,这就是磁盘使用率在达到100%之前就会变成的问题的原因。CPU资源与之不同,更高优先级的任务是可以抢占CPU的。
- 饱和度 :
任何程度的饱和都是问题(非零)。饱和程度可以用排队长度或者排队所花的时间来度量。 - 错误 :错误都是值得研究的,尤其是随着错误增加性能会变差的那些错误。
低使用率、无饱和、无错误:这样的反例研究起来容易。这点要比看起来还有用缩小研究的范围能帮你快速地将精力集中在出问题的地方,判断其不是某一个资源的问题,这是一个排除法的过程。
下面为上面提到的资源和对应指标查看工具Demo,只是涉及部分
3CPU 使用率
CPU使用率通过测量一段时间内CPU实例忙于执行工作的时间比例获得,以百分比表示。也可以通过测量CPU未运行内核空闲线程的时间得出,这段时间内CPU可能在运行一些用户态应用程序线程,或者其他的内核线程,或者在处理中断。高CPU使用率并不一定代表着问题,仅仅表示系统正在工作。
CPU在高使用率的情况下,性能并不会出现显著下降,因为内核支持了优先级、抢占和分时共享。这些概念加起来让内核决定了什么线程的优先级更高,并保证它优先运行。
CPU使用率通常被分成内核时间(%sys)和用户时间(%usr)两个指标。
- 计算密集型的CPU用户/内核时间比可达到99/1,
- I/O密集型的CPU用户/内核时间比可达到70/30,
每个CPU
mpstat -P ALL查看每个CPU的使用率,%idle指CPU的空闲率,通过检查单个热点(繁忙)CPU,挑出一个可能的线程扩展性问题。(不太懂,先记下来)
┌──[root@liruilongs.github.io]-[~]
└─$ mpstat -P ALL
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月05日 _x86_64_ (6 CPU)
22时59分30秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
22时59分30秒 all 5.44 0.00 7.91 0.51 0.00 0.30 0.00 0.00 0.00 85.85
22时59分30秒 0 5.65 0.00 7.43 0.60 0.00 0.29 0.00 0.00 0.00 86.02
22时59分30秒 1 5.34 0.00 9.01 0.47 0.00 0.33 0.00 0.00 0.00 84.85
22时59分30秒 2 5.80 0.00 7.12 0.40 0.00 0.36 0.00 0.00 0.00 86.32
22时59分30秒 3 5.68 0.00 7.74 0.50 0.00 0.30 0.00 0.00 0.00 85.77
22时59分30秒 4 3.84 0.00 6.08 0.23 0.00 0.23 0.00 0.00 0.00 89.62
22时59分30秒 5 6.30 0.00 10.04 0.86 0.00 0.27 0.00 0.00 0.00 82.54
┌──[root@liruilongs.github.io]-[~]
└─$
也可用通过 sar -P ALL的命令来查看,sar可以获取平均数据,%idle指CPU的空闲率,反过来即为使用率
┌──[root@liruilongs.github.io]-[~]
└─$ sar -P ALL
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月05日 _x86_64_ (6 CPU)
22时56分20秒 LINUX RESTART
23时00分01秒 CPU %user %nice %system %iowait %steal %idle
23时10分01秒 all 0.21 0.00 0.39 0.01 0.00 99.39
23时10分01秒 0 0.20 0.00 0.42 0.01 0.00 99.36
23时10分01秒 1 0.33 0.00 0.60 0.01 0.00 99.06
23时10分01秒 2 0.30 0.00 0.45 0.01 0.00 99.24
23时10分01秒 3 0.14 0.00 0.25 0.01 0.00 99.61
23时10分01秒 4 0.19 0.00 0.33 0.01 0.00 99.48
23时10分01秒 5 0.12 0.00 0.27 0.02 0.00 99.60
平均时间: CPU %user %nice %system %iowait %steal %idle
平均时间: all 0.21 0.00 0.39 0.01 0.00 99.39
平均时间: 0 0.20 0.00 0.42 0.01 0.00 99.36
平均时间: 1 0.33 0.00 0.60 0.01 0.00 99.06
平均时间: 2 0.30 0.00 0.45 0.01 0.00 99.24
平均时间: 3 0.14 0.00 0.25 0.01 0.00 99.61
平均时间: 4 0.19 0.00 0.33 0.01 0.00 99.48
平均时间: 5 0.12 0.00 0.27 0.02 0.00 99.60
┌──[root@liruilongs.github.io]-[~]
系统范围
vmstat 1 1查看所有的CPU使用率,id列为系统空闲消耗的总CPU时间的百分比,当等于0的时候,即没有空闲
可以每秒运行vmstat,然后检查空闲列,看看还有多少余量。少于10%可能相关进程存在问题
┌──[root@liruilongs.github.io]-[~]
└─$ vmstat 1 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 23268840 3104 849968 0 0 168 26 239 296 2 3 96 0 0
sar -u的方式,%idle指CPU的空闲率,获取启动以来的平均数据
┌──[root@liruilongs.github.io]-[~]
└─$ sar -u
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月05日 _x86_64_ (6 CPU)
22时56分20秒 LINUX RESTART
23时00分01秒 CPU %user %nice %system %iowait %steal %idle
23时10分01秒 all 0.21 0.00 0.39 0.01 0.00 99.39
平均时间: all 0.21 0.00 0.39 0.01 0.00 99.39
dstat 工具,需要单独装包,idl:指CPU的空闲率
┌──[root@liruilongs.github.io]-[~]
└─$ dstat -c 1 2
----total-cpu-usage----
usr sys idl wai hiq siq
1 2 97 0 0 0
0 0 99 0 0 0
0 0 100 0 0 0
┌──[root@liruilongs.github.io]-[~]
└─$
每个进程
top命令,%CPU:CPU消耗, 默认会按照CPU用量排序
- 最上面会显示当前系统平均负载,以及CUP相关的平局值
%Cpu(s): 0.2 us, 0.2 sy, 0.0 ni, 99.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st - 每个进程的CPU用量通过
TIME+和%CPU列表示,TIME列显示了进程自从创建开始消耗的CPU总时间(用户态+系统态),格式为“小时:分钟:秒”。 - Linux上,
CPU列显示了在前一秒内所有CPU上的CPU用量之和。一个单线程的CPU型进程会报告100%。而一个双线程的CPU型进程则会报告200%。
top - 23:15:42 up 19 min, 1 user, load average: 0.01, 0.05, 0.10
Tasks: 279 total, 1 running, 278 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.2 sy, 0.0 ni, 99.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 32927488 total, 22911768 free, 8894024 used, 1121696 buff/cache
KiB Swap: 11534328 total, 11534328 free, 0 used. 23608488 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
935 etcd 20 0 10.7g 26756 11124 S 1.3 0.1 0:15.74 etcd
8108 chrony 20 0 863480 578404 9964 S 1.3 1.8 0:30.36 bundle
8112 992 20 0 541256 93800 12008 S 1.3 0.3 0:08.27 prometheus
955 root 20 0 1256580 50788 19868 S 0.3 0.2 0:02.40 containerd
4686 tom 20 0 12.6g 2.9g 26428 S 0.3 9.4 0:49.63 java
8113 chrony 20 0 583592 24052 6168 S 0.3 0.1 0:01.47 gitaly
8121 nginx 20 0 41636 12160 1600 S 0.3 0.0 0:05.71 redis-server
8214 chrony 20 0 2756524 65824 8124 S 0.3 0.2 0:04.84 ruby
。。。。。。。。。。。。。。。。
也可以使用 htop工具
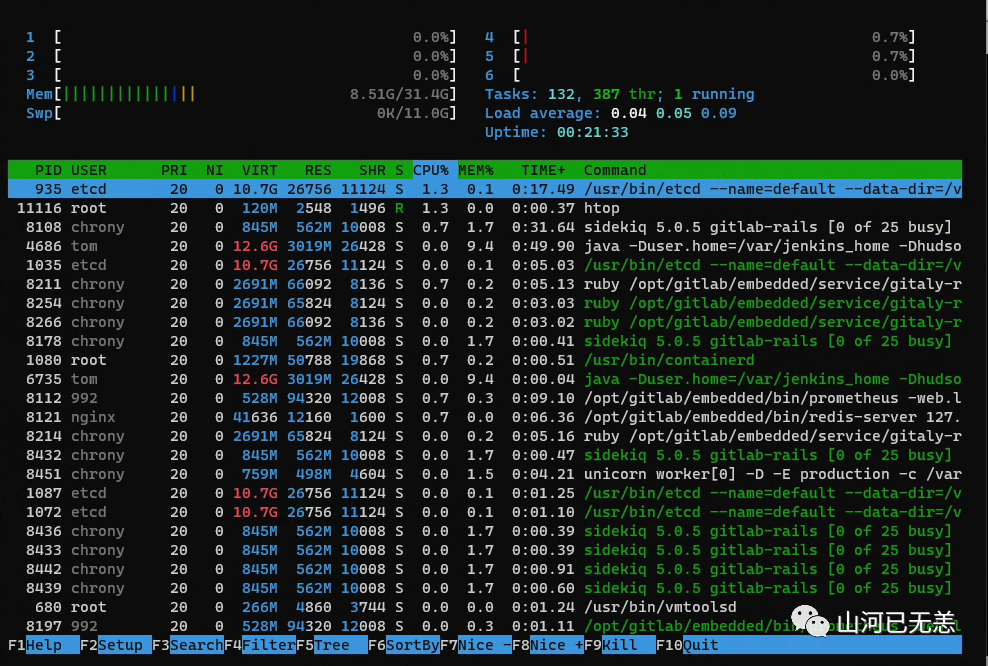
或者 ps :%CPU
┌──[root@liruilongs.github.io]-[~]
└─$ ps -o pcpu,cmd
%CPU CMD
0.0 /bin/bash /assets/wrapper
0.0 runsvdir -P /opt/gitlab/service log: ................................................................
0.0 /bin/bash /opt/gitlab/bin/gitlab-ctl tail
0.0 /opt/gitlab/embedded/bin/ruby /opt/gitlab/embedded/bin/omnibus-ctl gitlab /opt/gitlab/embedded/servic
0.0 sh -c find /var/log/gitlab -type f -not -path */sasl/* | grep -E -v '(config|lock|@|gzip|tgz|gz)' | x
0.0 xargs tail --follow=name --retry
0.0 tail --follow=name --retry /var/log/gitlab/sshd/current /var/log/gitlab/gitlab-shell/gitlab-shell.log
0.0 -bash
0.0 ps -o pcpu,cmd
pidstat 1 1命令会按照进程打印CPU的用量,包括用户态和系统态时间的分解,
- %CPU:进程占用cpu的百分比
- CPU:处理进程的cpu编号
┌──[root@liruilongs.github.io]-[~]
└─$ pidstat 1 1
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月05日 _x86_64_ (6 CPU)
23时20分54秒 UID PID %usr %system %guest %CPU CPU Command
23时20分55秒 996 935 0.00 0.99 0.00 0.99 0 etcd
23时20分55秒 998 8108 0.00 0.99 0.00 0.99 2 bundle
23时20分55秒 998 8211 0.99 0.00 0.00 0.99 4 ruby
23时20分55秒 0 11670 0.00 0.99 0.00 0.99 2 pidstat
平均时间: UID PID %usr %system %guest %CPU CPU Command
平均时间: 996 935 0.00 0.99 0.00 0.99 - etcd
平均时间: 998 8108 0.00 0.99 0.00 0.99 - bundle
平均时间: 998 8211 0.99 0.00 0.00 0.99 - ruby
平均时间: 0 11670 0.00 0.99 0.00 0.99 - pidstat
┌──[root@liruilongs.github.io]-[~]
└─$
4CUP 饱和度
一个100%使用率的CPU被称为是饱和的,线程在这种情况下会碰上调度器延时,因为它们需要等待才能在CPU上运行,降低了总体性能。这个延时是线程花在等待CPU运行队列或者其他管理线程的数据结构上的时间。
另一个CPU饱和度的形式则和CPU资源控制有关,这个控制会在云计算环境下发生。尽管CPU并没有100%地被使用,但已经达到了控制的上限,因此可运行的线程就必须等待轮到它们的机会。这个过程对用户的可见度取决于使用的虚拟化技术,
一个饱和运行的CPU不像其他类型资源那样问题重重,因为更高优先级的工作可以抢占当前线程。但往往持续的饱和是存在问题的
系统范围
vmstat 1 2 虚拟内存统计命令,最后的几列会打印全局范围的CUP平均负载, 当r > CUP数量即为饱和状态,列r报告了那些正在等待以及正在CPU上运行的线程。
- r:当前可运行的进程数(运行队列的长度)。这些进程没有等待I/0,而是已经准备好运行。理想状态下,
可运行进程数应与可用CPU的数量相等 - b:等待1/0完成的被阻塞进程数
- us:用户态时间。
- sy:系统态时间(内核)。
- id:空闲。
- wa:等待I/O,即线程被阻塞等待磁盘I/O时的CPU空闲时间。
- st:偷取(未在输出里显示),CPU在虚拟化的环境下在其他租户上的开销。
┌──[root@liruilongs.github.io]-[~]
└─$ vmstat 1 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 22877932 3104 1122588 0 0 74 35 173 246 1 1 98 0 0
0 0 0 22878064 3104 1122592 0 0 0 25 663 1094 0 0 100 0 0
sar -q 系统活动报告器,-q 参数展示包括运行队列长度列runq-sz(等待数加上运行数,与vmstat的r列相同)和平均负载ldavg-1 ldavg-5 ldavg-15 。当 runq-sz > CUP数量时CPU饱和
┌──[root@liruilongs.github.io]-[~]
└─$ sar -q
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月05日 _x86_64_ (6 CPU)
22时56分20秒 LINUX RESTART
23时00分01秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked
23时10分01秒 1 665 0.11 0.09 0.12 0
23时20分01秒 0 667 0.00 0.03 0.08 0
平均时间: 0 666 0.06 0.06 0.10 0
dstat -p 1 2命令,当run > CPU 数量时,CPU饱和
┌──[root@liruilongs.github.io]-[~]
└─$ dstat -p 1 2
---procs---
run blk new
0 0 7.0
0 0 1.0
0 0 4.0
5内存容量使用率
主内存的使用率可由已占用的内存除以总内存得出。文件系统缓存占用的内存可当作未使用,因为它可以被应用程序重用,也可以通过修改内核参数来调整缓存和缓冲区。通过cgroup可以对内存资源进行限制。
关于内存使用率,前面的建议可得,100%的使用率通常是瓶颈的信号(检查饱和度并确认其影响)。使用率超过60%可能会是问题,所以对于内存平均使用率尽量保持到70%以内,超过70%,考虑扩容。
一般情况下,处于性能考虑,生产环境往往会禁用交换分区,或者通过修改内核参数调整交换频率,交换分区的意义是为了应付内存不足的情况。
所以如果设置了交换分区,往往内存不足的一个信号即系统开始使用交换分区,如果内存使用率低,是不会使用交换分区的。Linux系统的内存使用率高并不一定是坏事,Linux会尽可能的使用内存,提高系统IO的处理效率,一个运行了很久机器,你会发现的buff/cache会占据内存很大的一部分。
Linux永远不会存在因为内存不够而挂调的情况,除非你修改了OOM Killer相关的内核参数,默认情况下,系统的会在内存不够的时候,自动的根据打分杀掉有可能存在内存泄露的进程,具体的日志可以通过 /var/log/message 日志查看。
通过对系统内存使用率的查看,可以在系统资源瓶颈时提早扩容,通过系统内存推断是否存在异常进程
系统范围
free 命令不多讲
┌──[root@liruilongs.github.io]-[~]
└─$ free -m
total used free shared buff/cache available
Mem: 32155 9465 21113 21 1576 22275
Swap: 11263 0 11263
vmstat 命令
- swpd:交换出的内存量。
- free:空闲的可用内存。
- buff:用于缓冲缓存的内存。
- cache:用于页缓存的内存。
- si:换入的内存(换页)。
- so:换出的内存(换页)。
┌──[root@liruilongs.github.io]-[~]
└─$ vmstat 1 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 21617868 3104 1611636 0 0 1 10 7 5 0 0 99 0 0
0 0 0 21617704 3104 1611636 0 0 0 0 718 1068 0 2 98 0 0
如果si和so列一直非0,那么系统正存在内存压力并换页到交换设备或文件
通过sar -r 可以查看系统范围的内存使用率
- -B:换页统计信息
- -H:大页面统计信息
-r:内存使用率- -R:内存统计信息
- -s:交换空间统计信息
- -W:交换统计信息
┌──[root@liruilongs.github.io]-[~]
└─$ sar -r | head -5
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月07日 _x86_64_ (6 CPU)
00时00分01秒 kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
00时10分01秒 21838132 11089356 33.68 3104 1301088 7212724 16.22 9695476 573536 116
00时20分01秒 22002248 10925240 33.18 3104 1251500 7208136 16.21 9575496 531188 60
┌──[root@liruilongs.github.io]-[~]
└─$
- kbmemfree 空闲存储器/千字节
- kbmemused 占用存储器(不包括内核)/千字节
- kbbuffers 缓冲高速缓存尺寸/千字节
- kbcached 页面高速缓存尺寸/千字节
- kbcommit 提交的主存储器:服务当前工作负载需要量的估计/千字节:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
- %commit 为当前工作负载提交的主存储器,估计值/百分比
- kbactive 活动列表存储器尺寸/千字节
- kbinact 非活动列表存储器尺寸/千字节
也可以通过dstat 命令来查看,更直观一点
┌──[root@liruilongs.github.io]-[~]
└─$ dstat -m 1 2
------memory-usage-----
used buff cach free
9707M 3104k 1338M 20.6G
9707M 3104k 1338M 20.6G
9707M 3104k 1338M 20.6G
┌──[root@liruilongs.github.io]-[~]
└─$
检查内核进程相关的内存信息 kmem slab使用情况,一般用不到,我现在也看不懂
┌──[root@liruilongs.github.io]-[~]
└─$ slabtop -s c
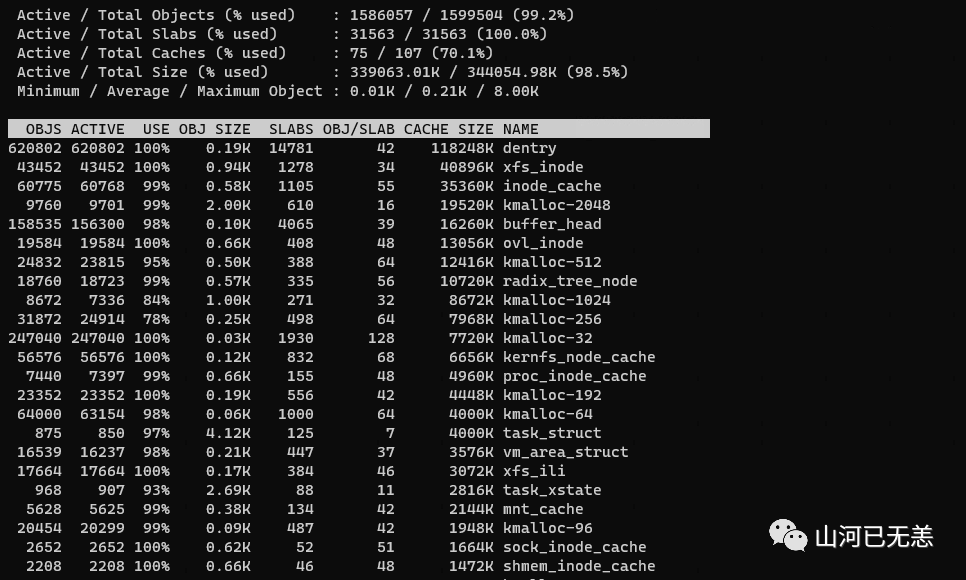
每个进程
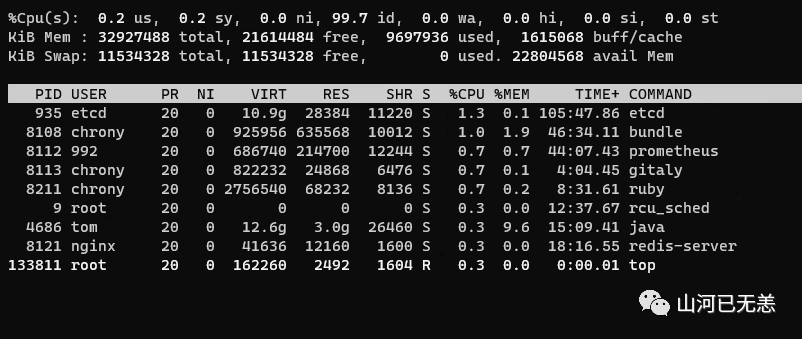
top 命令可以直观的看到每个进程的内存使用,也可以使用静态的 ps 命令不多讲
- %MEM:主存使用(物理内存、RSS)占总内存的百分比。
- RES:常驻集合大小(KB)。当前使用的内存大小
- VIRT:虚拟内存大小(KB):申请的内存,包括使用了和没有使用的
┌──[root@liruilongs.github.io]-[~]
└─$ top
可以看到,第一个进程为etcd,当前申请的虚机内存为10.9g,已经使用28384KB的内存,共享内存为11220KB
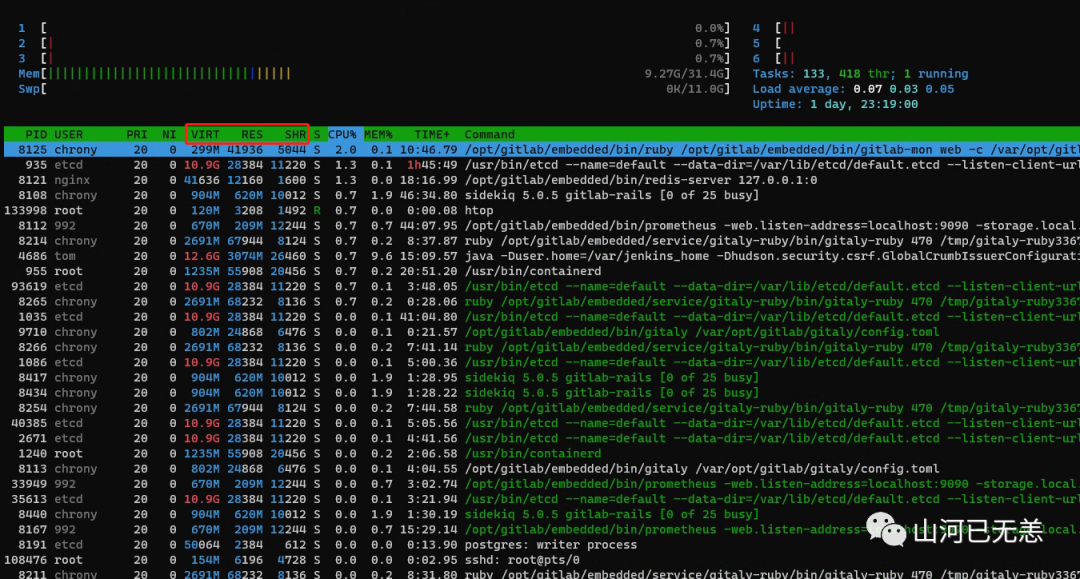
也可以通过htop工具来查看,htop命令会直观的显示启动命令,使用top的需要进去键入c键
┌──[root@liruilongs.github.io]-[~]
└─$ htop
6内存容量饱和度
对内存的需求超过了主存的情况被称作主存饱和。这时操作系统会使用换页、交换或者在Linux中用O0M终结者来释放内存。以上任一操作都标志着主存饱和。
系统范围
si so 列出现数值时,以为系统进行交换,内存达到饱和
┌──[root@liruilongs.github.io]-[~]
└─$ vmstat 1 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 21614748 3104 1612480 0 0 1 10 8 6 0 0 99 0 0
0 0 0 21614424 3104 1612484 0 0 0 9 930 1522 0 0 100 0 0
1 0 0 21613436 3104 1612484 0 0 0 0 999 1517 0 1 99 0 0
┌──[root@liruilongs.github.io]-[~]
└─$
sar -B 报告的信息为内核与磁盘之间交换的块数。此外,对v2.5之后的内核版本,该项报告的信息为缺页数量: 这里没找到对应的资料。
- pgscank/s:每秒被kswapd扫描的页个数
- pgscand/s:每秒直接被扫描的页个数
┌──[root@liruilongs.github.io]-[~]
└─$ sar -B |head -5
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月07日 _x86_64_ (6 CPU)
00时00分01秒 pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
00时10分01秒 0.00 50.77 620.39 0.00 381.90 0.00 0.00 0.00 0.00
00时20分01秒 0.00 68.26 5369.35 0.00 2179.92 0.00 0.00 0.00 0.00
┌──[root@liruilongs.github.io]-[~]
└─$
sar -W报告系统交换的页数:当有数值时意味系统使用了交换分区
┌──[root@liruilongs.github.io]-[~]
└─$ sar -W | head -5
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月07日 _x86_64_ (6 CPU)
00时00分01秒 pswpin/s pswpout/s
00时10分01秒 0.00 0.00
00时20分01秒 0.00 0.00
┌──[root@liruilongs.github.io]-[~]
└─$
每个进程
如果当前进程存在内内存饱和,影响到系统,会触发内存杀手 OOM Killer。可以通过下面的命令查看日志
┌──[root@liruilongs.github.io]-[~]
└─$ dmesg | grep killed
/proc/PID/stat中第10项(min_flt)7533,可以得次要缺页中断的次数,即无需从磁盘加载内存页. 比如COW和匿名页(这个不懂,先记录)
┌──[root@liruilongs.github.io]-[~]
└─$ cat /proc/956/stat
956 (etcd) S 1 956 956 0 -1 1077944576 7533 421 90 1 776 68808 0 0 20 0 21 0 881 11699159040 6577 18446744073709551615 94319632281600 94319648442868 140733854974784 140733854974152 94319638032483 0 1006254592 0 2143420159 18446744073709551615 0 0 17 5 0 0 6 0 0 94319650541736 94319659761249 94319676428288 140733854977417 140733854977553 140733854977553 140733854978026 0
- pid: 进程ID.
- comm: task_struct结构体的进程名
- state: 进程状态, 此处为S
- ppid: 父进程ID (父进程是指通过fork方式,通过clone并非父进程)
- pgrp:进程组ID
- session:进程会话组ID
- tty_nr:当前进程的tty终点设备号
- tpgid:控制进程终端的前台进程号
- flags:进程标识位,定义在include/linux/sched.h中的PF_*,
minflt: 次要缺页中断的次数,即无需从磁盘加载内存页. 比如COW和匿名页- cminflt:当前进程等待子进程的minflt
- majflt:主要缺页中断的次数,需要从磁盘加载内存页. 比如map文件
- majflt:当前进程等待子进程的majflt
- utime: 该进程处于用户态的时间,单位jiffies,
- stime: 该进程处于内核态的时间,单位jiffies,
- cutime:当前进程等待子进程的utime
- cstime: 当前进程等待子进程的utime
- priority: 进程优先级, .
- nice: nice值,取值范围[19, -20],
- num_threads: 线程个数,
- itrealvalue: 该字段已废弃,恒等于0
- starttime:自系统启动后的进程创建时间,单位jiffies,
- vsize:进程的虚拟内存大小,单位为bytes
- rss: 进程独占内存+共享库,单位pages,
- rsslim: rss大小上限
内存容量错误
OOM killer 也可以直接看日志
┌──[root@liruilongs.github.io]-[~]
└─$ tail -n 5 /var/log/messages
Sep 9 12:18:14 liruilongs kernel: e1000: ens32 NIC Link is Down
Sep 9 12:18:20 liruilongs kernel: e1000: ens32 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Sep 9 12:18:22 liruilongs kernel: e1000: ens32 NIC Link is Down
Sep 9 12:18:26 liruilongs kernel: e1000: ens32 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Sep 9 12:20:01 liruilongs systemd: Started Session 8 of user root.
┌──[root@liruilongs.github.io]-[~]
└─$ dmesg | tail -n 5
[ 45.978294] hrtimer: interrupt took 3043780 ns
[ 3399.493638] e1000: ens32 NIC Link is Down
[ 3405.505696] e1000: ens32 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
[ 3407.509927] e1000: ens32 NIC Link is Down
[ 3411.522461] e1000: ens32 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
┌──[root@liruilongs.github.io]-[~]
└─$
7网络接口利用率
ip -s link: 利用率计算为:RX/TX: 吞吐量除以最大带宽,RX代表接收,TX代表发送。查看最大带宽的方式:带宽为 Speed: 1000Mb/s 千兆
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ethtool ens32
Settings for ens32:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: No
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
MDI-X: off (auto)
Supports Wake-on: d
Wake-on: d
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
ip -s link部分字段说明
列 | 说明 |
|---|---|
bytes | 发送或接收的字节数 |
packets | 发送或接收的数据包数 |
errors | 发送或接收时发生的错误数 |
dropped | 由于网卡缺少资源,导致未发送或接收的数据包数 |
overruns | 网络没有足够的缓冲区空间来发送或接收更多数据包的次数 |
mcast | 已接收的多播数据包的数量 |
carrier | 由于链路介质故障(如故障电缆)而丢弃的数据包数量 |
collsns | 传送时设备发生的冲突次数。当多个设备试图同时使用网络时就会发生冲突 |
┌──[root@liruilongs.github.io]-[/proc]
└─$ ip -s link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
RX: bytes packets errors dropped overrun mcast
763056 14652 0 0 0 0
TX: bytes packets errors dropped carrier collsns
763056 14652 0 0 0 0
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:9f:48:81 brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
3734602 6125 0 0 0 0
TX: bytes packets errors dropped carrier collsns
2793821 2982 0 0 0 0
。。。。。。。。。。。。
也可以使用sar命令查看,利用率为: rx/tx kB/s 除以最大带宽
列 | 说明 |
|---|---|
rxpck/s | 数据包接收速率 |
txpck/s | 数据包发送速率 |
rxkB/s | kb接收速率 |
txkB/s | kb发送速率 |
rxcmp/s | 压缩包接收速率 |
txcmp/s | 压缩包发送速率 |
rxmcst/s | 多播包接收速率 |
┌──[root@liruilongs.github.io]-[/proc]
└─$ sar -n DEV
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月13日 _x86_64_ (6 CPU)
22时20分01秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
22时30分01秒 vethe257c0b 0.01 0.01 0.00 0.00 0.00 0.00 0.00
22时30分01秒 br-4b3da203747c 0.00 0.00 0.00 0.00 0.00 0.00 0.00
22时30分01秒 ens32 0.02 0.02 0.00 0.00 0.00 0.00 0.00
。。。。。。。
平均时间: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
平均时间: vethe257c0b 0.01 0.01 0.00 0.00 0.00 0.00 0.00
平均时间: br-4b3da203747c 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: ens32 0.55 0.73 0.04 1.00 0.00 0.00 0.00
平均时间: br-0e0cdf9c70b0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: vethcb79321 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: lo 0.13 0.13 0.01 0.01 0.00 0.00 0.00
平均时间: docker0 0.01 0.01 0.00 0.00 0.00 0.00 0.00
┌──[root@liruilongs.github.io]-[/proc]
└─$
查看内核问题的方式,/proc/net/dev,Receive/Transmit 吞吐量字节数除以最大值,不知道这里的最大值什么?
┌──[root@liruilongs.github.io]-[/proc]
└─$ cat /proc/net/dev | head -n 5
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
vethe257c0b: 74504 1362 0 0 0 0 0 0 3321668 1387 0 0 0 0 0 0
br-4b3da203747c: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ens32: 3749200 6320 0 0 0 0 0 0 2823625 3102 0 0 0 0 0 0
┌──[root@liruilongs.github.io]-[/proc]
└─$
8网络接口饱和度
网络接口饱和度通过下面两项排查,当有值时,说明存在网络接口饱和
overruns网络没有足够的缓冲区空间来发送或接收更多数据包的次数dropped发送或接收时丢弃的数据包数
┌──[root@liruilongs.github.io]-[/proc]
└─$ ifconfig ens32
ens32: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.26.55 netmask 255.255.255.0 broadcast 192.168.26.255
inet6 fe80::20c:29ff:fe9f:4881 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:9f:48:81 txqueuelen 1000 (Ethernet)
RX packets 6414 bytes 3756184 (3.5 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3157 bytes 2834195 (2.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
或者通过netstat -s的方式查询,这个对应指标值不太清楚
┌──[root@liruilongs.github.io]-[/proc]
└─$ netstat -s
Ip:
19334 total packets received
545 forwarded
0 incoming packets discarded
18786 incoming packets delivered
17742 requests sent out
4 dropped because of missing route
。。。。。
9网络接口错误
ifconfig ens32 : errors项,dropped项查看错包和丢包的情况
┌──[root@liruilongs.github.io]-[/proc]
└─$ ifconfig ens32
ens32: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.26.55 netmask 255.255.255.0 broadcast 192.168.26.255
inet6 fe80::20c:29ff:fe9f:4881 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:9f:48:81 txqueuelen 1000 (Ethernet)
RX packets 6709 bytes 3778697 (3.6 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3327 bytes 2860201 (2.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
RX-ERR/TX-ERR
┌──[root@liruilongs.github.io]-[/proc]
└─$ netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
br-0e0cdf9c70b0 1500 6728 0 0 0 3339 0 0 0 BMU
br-4b3da203747c 1500 1368 0 0 0 1393 0 0 0 BMU
docker0 1500 1368 0 0 0 1388 0 0 0 BMRU
ens32 1500 6728 0 0 0 3339 0 0 0 BMRU
lo 65536 14760 0 0 0 14760 0 0 0 LRU
vethcb79321 1500 0 0 0 0 11 0 0 0 BMRU
vethe257c0b 1500 1368 0 0 0 1393 0 0 0 BMRU
errors dropped
┌──[root@liruilongs.github.io]-[/proc]
└─$ ip -s link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
RX: bytes packets errors dropped overrun mcast
768880 14764 0 0 0 0
TX: bytes packets errors dropped carrier collsns
768880 14764 0 0 0 0
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:9f:48:81 brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
3787251 6822 0 0 0 0
TX: bytes packets errors dropped carrier collsns
2868359 3393 0 0 0 0
..............
sar -n EDEV :显示每个网卡的发送和接收错误信息
┌──[root@liruilongs.github.io]-[/proc]
└─$ sar -n EDEV | head -n 5
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月13日 _x86_64_ (6 CPU)
22时20分01秒 IFACE rxerr/s txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s
22时30分01秒 vethe257c0b 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
22时30分01秒 br-4b3da203747c 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
通过内核文件/proc/net/dev中的errs,drop项可以查看错误的和丢弃的包
┌──[root@liruilongs.github.io]-[/proc]
└─$ cat /proc/net/dev
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
vethe257c0b: 74662 1365 0 0 0 0 0 0 3321806 1390 0 0 0 0 0 0
br-4b3da203747c: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ens32: 3773382 6641 0 0 0 0 0 0 2850239 3284 0 0 0 0 0 0
br-0e0cdf9c70b0: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
vethcb79321: 0 0 0 0 0 0 0 0 878 11 0 0 0 0 0 0
lo: 767008 14728 0 0 0 0 0 0 767008 14728 0 0 0 0 0 0
docker0: 55552 1365 0 0 0 0 0 0 3321416 1385 0 0 0 0 0 0
10磁盘IO利用率
系统范围
通过 iostat的查看磁盘统计信息
一般%util 利用率 大于70%,I/O压力就比较大,读取速度有较多的wait。
┌──[root@liruilongs.github.io]-[/proc]
└─$ iostat -xz 1 1
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月13日 _x86_64_ (6 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.18 0.00 0.39 0.01 0.00 99.41
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.17 0.49 2.01 7.53 57.35 51.85 0.00 1.68 5.02 0.86 0.54 0.13
┌──[root@liruilongs.github.io]-[/proc]
└─$
统计数据 | 说明 |
|---|---|
rrqm/s | 在提交给磁盘前,被合并的读请求的数量 |
wrqm/s | 在提交给磁盘前,被合并的写请求的数量 |
r/s | 每秒提交给磁盘的读请求数量 |
w/s | 每秒提交给磁盘的写请求数量 |
rsec/s | 每秒读取的磁盘扇区数 |
wsec/s | 每秒写入的磁盘扇区数 |
rkB/s | 每秒从磁盘读取了多少KB的数据 |
wkB/s | 每秒向磁盘写入了多少KB的数据 |
avgrq-sz | 磁盘请求的平均大小(按扇区计) |
avgqu-sz | 磁盘请求队列的平均大小。 |
await | 完成对一个请求的服务所需的平均时间(按毫秒计),该平均时间为请求在磁盘队列中等待的时间加上磁盘对其服务所需的时间 |
svctm | 提交到磁盘的请求的平均服务时间(按毫秒计)。该项表明磁盘完成一个请求所花费的平均时间。与await不同,该项不包含在队列中等待的时间 |
%util | 利用率 |
┌──[root@liruilongs.github.io]-[/proc]
└─$ sar -d
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月13日 _x86_64_ (6 CPU)
22时20分01秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
22时30分01秒 dev8-0 2.34 0.03 149.81 64.13 0.00 1.56 0.54 0.13
22时40分01秒 dev8-0 2.44 5.65 146.44 62.38 0.00 1.60 0.56 0.14
22时50分01秒 dev8-0 2.39 0.00 152.13 63.70 0.00 0.86 0.45 0.11
23时00分01秒 dev8-0 2.36 2.28 141.90 61.01 0.00 0.91 0.49 0.12
23时10分01秒 dev8-0 2.31 2.89 135.45 59.94 0.00 1.39 0.57 0.13
平均时间: dev8-0 2.37 2.17 145.15 62.24 0.00 1.27 0.52 0.12
┌──[root@liruilongs.github.io]-[/proc]
└─$
每个进程
查看每个进程的磁盘利用率可以通过iotop命令来查看
前两行READ和WRITE为读写速率总计
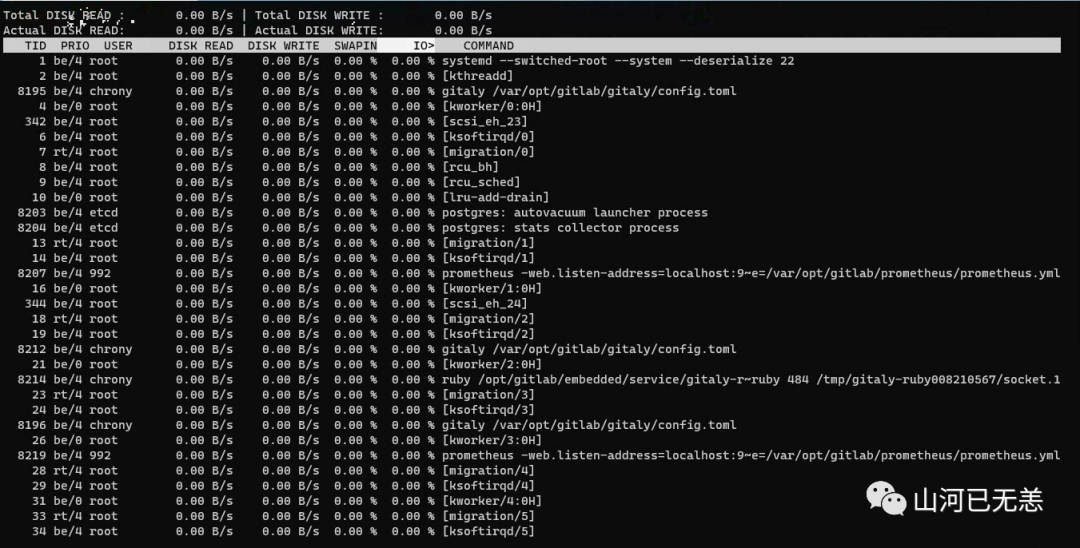
进程列表的含义:
- tid:线程id,按p可转换进程pid
- PRIO:优先级
- DISK READ:磁盘读取速率
- DISK WRITE:磁盘写取速率
- SWAPIN:用了多少交换分区
IO>:IO等待所占用百分比(该进程占磁盘利用率的百分比)- COMMAND:线程/进程详细信息(TID对应的进程名称)
也可以查看运行生成内核参数/proc/956/sched,但是这里并没有找到书里讲的内核参数值,可能是版本的问题
┌──[root@liruilongs.github.io]-[/proc]
└─$ cat /proc/956/sched
etcd (956, #threads: 22)
-------------------------------------------------------------------
se.exec_start : 13685.700041
se.vruntime : 43.362799
se.sum_exec_runtime : 258.986765
se.nr_migrations : 65
nr_switches : 368
nr_voluntary_switches : 227
nr_involuntary_switches : 141
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 116
mm->numa_scan_seq : 0
numa_migrations, 0
numa_faults_memory, 0, 0, 1, 0, -1
numa_faults_memory, 1, 0, 0, 0, -1
┌──[root@liruilongs.github.io]-[/proc]
└─$
11磁盘IO饱和度
当avgqu-sz的值特别大的时候,且请求等待时间await远远高于请求服务svctm所花费时间,且利用率%util为100%的时候,表明该磁盘处于饱和状态。产生的I/O请求太多,I/O系统已经满负载,I/O队列太长
iostat可以显示每个盘的指标值
┌──[root@liruilongs.github.io]-[/proc]
└─$ iostat -xNz 1 1
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月13日 _x86_64_ (6 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.18 0.00 0.39 0.01 0.00 99.41
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.17 0.54 2.01 8.58 57.83 52.07 0.00 1.65 4.61 0.86 0.53 0.14
sar -d的方式显示当前系统所有盘的数据汇总
┌──[root@liruilongs.github.io]-[/proc]
└─$ sar -d
Linux 3.10.0-1160.71.1.el7.x86_64 (liruilongs.github.io) 2022年09月13日 _x86_64_ (6 CPU)
22时20分01秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
22时30分01秒 dev8-0 2.34 0.03 149.81 64.13 0.00 1.56 0.54 0.13
22时40分01秒 dev8-0 2.44 5.65 146.44 62.38 0.00 1.60 0.56 0.14
22时50分01秒 dev8-0 2.39 0.00 152.13 63.70 0.00 0.86 0.45 0.11
23时00分01秒 dev8-0 2.36 2.28 141.90 61.01 0.00 0.91 0.49 0.12
23时10分01秒 dev8-0 2.31 2.89 135.45 59.94 0.00 1.39 0.57 0.13
23时20分01秒 dev8-0 2.09 0.24 130.58 62.59 0.00 0.89 0.53 0.11
23时30分01秒 dev8-0 11.65 410.73 281.56 59.40 0.01 0.70 0.33 0.38
平均时间: dev8-0 3.65 60.26 162.55 60.98 0.00 0.98 0.43 0.16
┌──[root@liruilongs.github.io]-[/proc]
└─$
关于 Linux 性能查看,USE方法就和小伙伴们分享到这,这里只展示了部分可以查到指标查找方式,大部分指标没有展示。
12博文内容参考
《Linux性能优化》 (美)菲利普G.伊佐特 著;贺莲 龚奕利 译
《性能之巅:洞悉系统、企业与云计算》(美)格雷格(Gregg,B.)著;徐章宁,吴寒思,陈磊 译
Linux常用监控命令:https://www.cnblogs.com/chuyiwang/p/7111522.html
/proc/stat解析:https://blog.csdn.net/houzhizhen/article/details/119948608
在 Linux 中如何使用 iotop 和 iostat 监控磁盘 I/O 活动?:https://linux.cn/article-10815-1.html
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-09-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号