浅谈词向量


将词语表示为向量的技术并不是最近几年的新思想。例如向量空间模型将词表示为词典维度的高维向量。这种表示带来的问题主要包括两个方面。一方面词与词之间相互独立,无法表达词语之间的关系。另一方面向量过于稀疏,计算和存储的效率都不高。
一种当前主流的技术是将是将词表示低维(通常为几十到几百维)的稠密向量,这种技术称为词向量(word embedding),也称为词嵌入。
有了低维的向量后,词之间可以进行相似度计算。将词向量作为底层输入时,词向量已经被证实有助于提高很多自然语言处理任务的性能,例如命名实体识别和情感分析等。
那么怎样将词表示为低维稠密实数向量呢?本节我们介绍三种方法。Word2Vec从预测局部上下文的角度构造神经网络,将词向量当做神经网络的参数进行学习。GloVe则利用了语料库全局信息,试图让词向量重构词与词之间的全局共现频次信息,能够揭示一些罕见词之间的相关性和语料库中一些有趣的线性结构。
Word2Vec和GloVe针对一个词只能学习到一个唯一的词向量表示,无法有效建模多义词现象。本节即将介绍的第三种词向量方法ELMo,能够学习到一个模型,该模型能够实时针对单词序列预测每个单词的词向量。因此当一个词出现在不同的上下文时,可以得到不同的词向量表示。
Word2Vec
Word2Vec是谷歌于2013年提出的一种词向量方法,其主要思路构造浅层神经网络来对词或上下文进行预测。根据预测任务的不同,Word2Vec包括两种不同的模型。一种模型将某个词的上下文作为输入来预测这个词本身,称作连续词袋模型(Continuous Bag-Of-Words, CBOW)。另一种模型将词作为输入来预测词的上下文,称作Skip-gram模型。在CBOW和Skip-gram模型中,词的上下文使用固定窗口大小的邻居词来表示。
例如对于句子"昨晚 这场 足球 比赛 十分 精彩",假设当前关注的中心词为"比赛"。CBOW模型尝试使用上下文信息"这场 足球 十分 精彩"预测"比赛"。而Skip-gram模型则尝试使用"比赛"这个词预测其上下文"这场 足球 十分 精彩"。CBOW和Skip-gram模型的示意图如下所示。
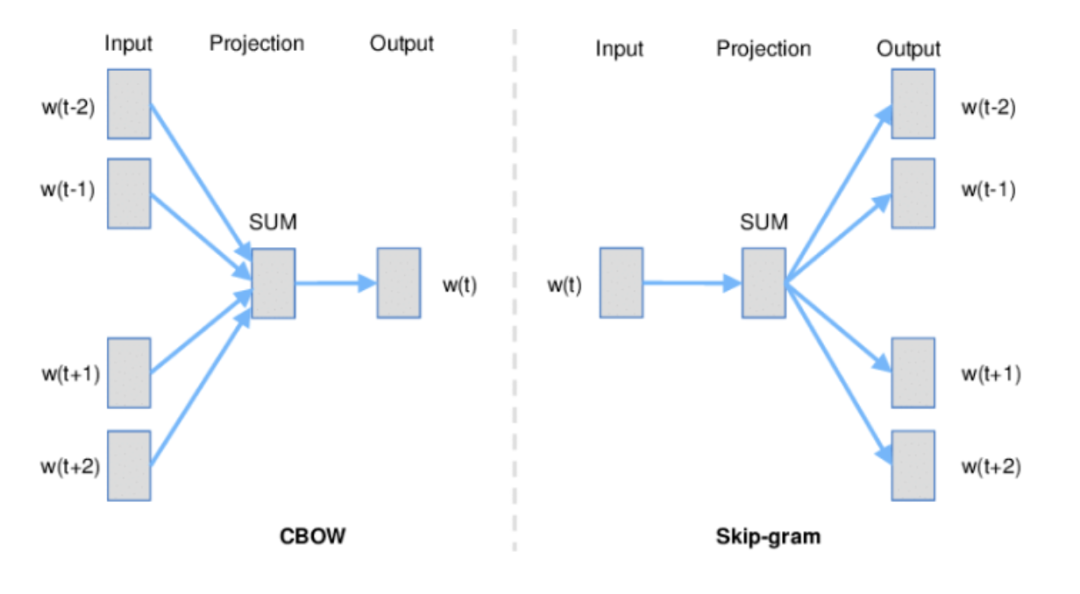
窗口大小是一个可配置的超参数,它对最终生成的词向量的相似度有很大影响。有研究指出,较大的窗口倾向于生成主题相似的词向量,而较小的窗口则倾向于生成更多的功能和句法相似度。在Word2Vec论文中,窗口大小设置为5,词向量维度为300。
训练模型最后输出层的计算开销大。以CBOW为例,若词典有10000个词,假设前一层神经元个数为300,维度为300
10000,后续还要将10000维的向量送入Softmax函数进行计算。为了减少计算开销,Word2Vec提出分层Softmax(hierarchical Softmax)和负采样(negative sampling)两种加快训练速度的优化技巧。
分层Softmax能够将单个词的训练复杂度从
降低为
。在上述两种模型中,每遇到一个训练样本,需要调整所有神经元权重参数。这意味着每次训练步骤,除了要更新当前词的词向量参数,还需要更新词典中所有其他词的词向量参数。负采样技术的主要思想时,在更新当前词的参数时,仅仅采样一部分其他词(称为负样本词)的参数进行更新。通常建议采样5
20个负样本词,如果语料库规模巨大,则选择2
5个负样本词。
GloVe
Word2Vec只能利用一定窗长的上下文环境,即利用局部信息,没有利用整个语料库的全局信息。GloVe利用了全局上下文信息,克服上述问题,这也是其得名的原因(Global VEctors,GloVe)。GloVe是一种无监督学习算法,用于获得词向量表示。对来自语料库的聚合的全局词共现统计数据进行训练,得到的词向量展示了向量空间的有趣线性子结构。
假设已经从一个大型语料库构建了词与词之间的共现矩阵
,其行代表词,列代表词的上下文。矩阵元素
表示词
在词
的上下文中出现的次数。在实际计算
时,通常还要根据词
与词
在不同上下文中的距离
设置一个衰减权重,例如
。
假设词
和词
的词向量分别为
和
。GloVe的优化目标是让词向量的点积与词之间共现概率的对数尽量相同,即极小化如下均方误差
:
其中
是词典的大小。
和
为词向量偏置项。
是一个权重函数。如果词
没有在词
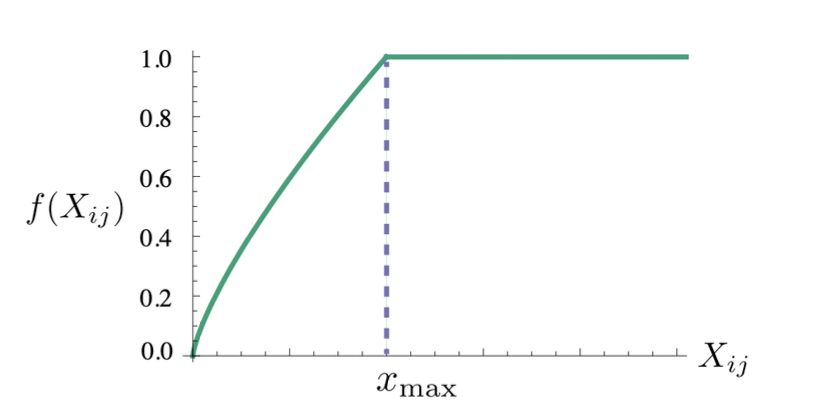
的上下文出现过,则权重为零。两个单词共同次数越多,权重越大,因此权重函数是非递减函数。我们也不希望共同次数特别大的单词的权重过大,因此有必要对权重的取值范围做限制。常见的做法的当权重增加到一定数值后保持不变。一种常见的权重函数如下式所示。
其中
和
为可配置参数,通常设置为
,
。函数图像如下图所示。
可以使用AdaGrad梯度下降法求解极小化目标函数。通常上下文窗口大小范围控制在6
10,词向量维度为300。得到词向量后,通过欧式距离可以计算词的近邻。利用这种方法有时能够发现一些超出普通人词汇量的罕见相关词。例如,通过计算词向量的距离,得到词frog的近邻词分别为frogs, toad, litoria, leptodactylidae, rana, lizard和eleutherodactylus。

ELMo
无论是Word2Vec还是GloVe,一个词只能得到一个唯一的词向量。而同样的词在不同的上下文可能表达不同的含义。为了解决这个问题,研究者提出了ELMo模型(Embeddings from Language Models)。ELMo是一种深度语境化的单词表示, 它既模拟了单词使用的复杂特征(例如语法和语义),又模拟了这些使用在语言语境中的变化(即模拟多义词)。这些单词向量是深度双向语言模型(biLM)内部状态的学习函数,该模型在大型文本语料库上进行了预训练。它们可以很容易地添加到现有模型中,并在广泛的具有挑战性的NLP问题(包括问答、文本蕴涵和情感分析)中取得了较好的效果。
ELMo解决多义词表征问题,能够理解上下文语境。使用多层双向 LSTM,以半监督方式进行预训练。
双向语言模型
给定包含
个词的序列
。前向语言模型通过建模给定历史序列
时每一个词
的条件概率来计算整个序列的概率,如下式所示。
反向语言模型通过建模给定未来序列
时每一个词
的条件概率来计算整个序列的概率,如下式所示。
在ELMo中,前向语言模型和后向语言模型均使用长短期记忆模型。通过将双向语言模型(biLM)则将前向语言模型和反向语言模型结合,ELMo模型最大化以下目标函数:
其中
为前向LSTM的网络参数,
为反向LSTM的网络参数。
和
为两个LSTM网络共享的参数,分别为输入词向量参数和 Softmax输出层的参数。
下图显示了ELMo模型的结构。
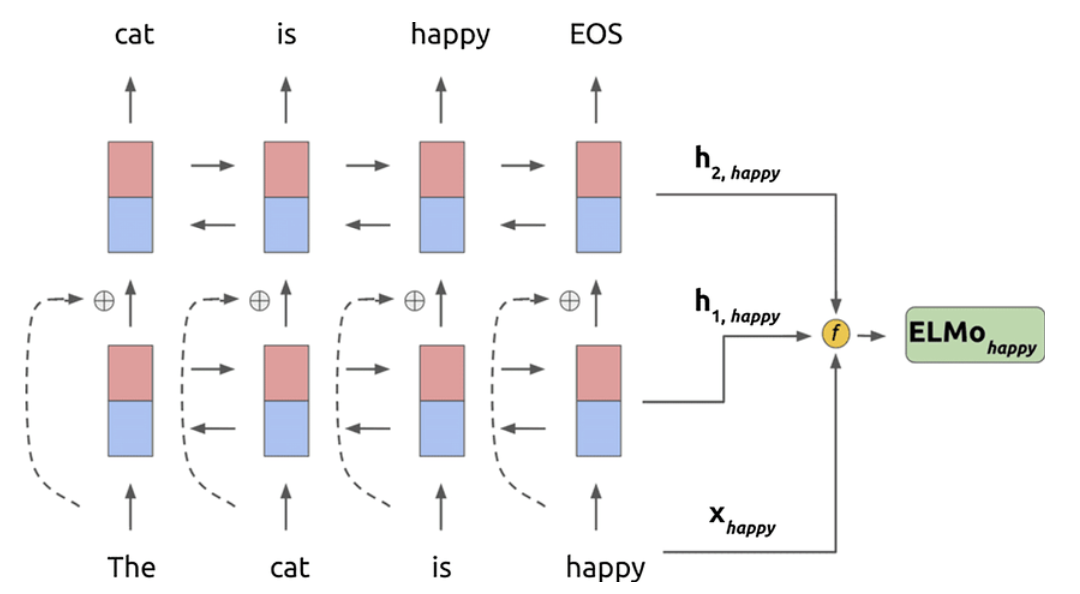
利用训练好的ELMo语言模型,可以得到输入句子中的第
个词的向量。将词向量
和双向隐层表示向量
和
加权求和,如下式所示。
其中
为隐含层表示的Softmax归一化权重,
是一个与具体任务相关的归一化因子。
由于ELMo的输入是词序列,同一个单词在不同的句子上下文可以得到不同的词向量,很好地解决了多义词的问题。例如对于句子"他很喜欢他的苹果手机"和"她很喜欢吃苹果"中的"苹果"一词,能够得到不同的词向量。
小结
很多工作已经将从大规模语料库中训练的词向量开源,均可从互联网下载。例如读者可以从Gensim工具中直接下载和使用Word2Vec模型和词向量[1]。GloVe[2]提供从维基百科、网络爬虫和推特等不同语料库训练的词向量,维度从25维到300维不等。ELMo模型[3]可以从官网下载并直接应用于给定序列的词向量生成。
我们可以直接将这些预训练的词向量,用于后续的任务,例如文本分类和情感分析。也可以将这些词向量作为再次训练的初始值,基于自己的任务微调这些词向量。如果拥有大规模语料库,也可以完成从头开始训练自己的词向量。
词向量是当前自然语言处理中的一个重要子领域,大部分现代NLP应用将词向量当做输入层。基于类似的思想,也可以将短语、句子或整个文档表示为向量。例如篇章向量算法(Paragraph Vector, PV)在词向量的基础上,针对篇章(句子或文档)也引入固定长度的向量表示。实验结果显示使用这种方法生成的文档向量在应用于文档分类等任务时比直接使用词向量效果更好。
词向量的发展甚至已超出自然语言处理的范畴。例如图表示学习(graph embedding)的核心想法是找到一种映射关系,将图或社交网络中的每个节点表示为低维实数向量。这类方法在推荐系统、计算广告学等领域获得了较为成功的应用效果。
参考资料
[1]
Word2Vec模型和词向量: https://radimrehurek.com/gensim/auto_examples/tutorials/run_word2vec.html
[2]
GloVe: https://nlp.stanford.edu/projects/glove/
[3]
ELMo模型: https://allenai.org/allennlp/software/elmo
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-11-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号