Node.js 应用全链路追踪技术——全链路信息存储
原创
Node.js 应用全链路追踪技术——全链路信息存储
原创
2020labs小助手
发布于 2023-02-06 10:25:00
发布于 2023-02-06 10:25:00
作者:vivo 互联网前端团队- Yang Kun
本文是上篇文章《Node.js 应用全链路追踪技术——全链路信息获取》的后续。阅读完,再来看本文,效果会更佳哦。
本文主要介绍在Node.js应用中, 如何用全链路信息存储技术把全链路追踪数据存储起来,并进行相应的展示,最终实现基于业界通用 OpenTracing 标准的 Zipkin 的 Node.js 方案。
一、背景
目前业界主流的做法是使用分布式链路跟踪系统,其理论基础是来自 Google 的一篇论文 《大规模分布式系统的跟踪系统》。
论文如下图所示:
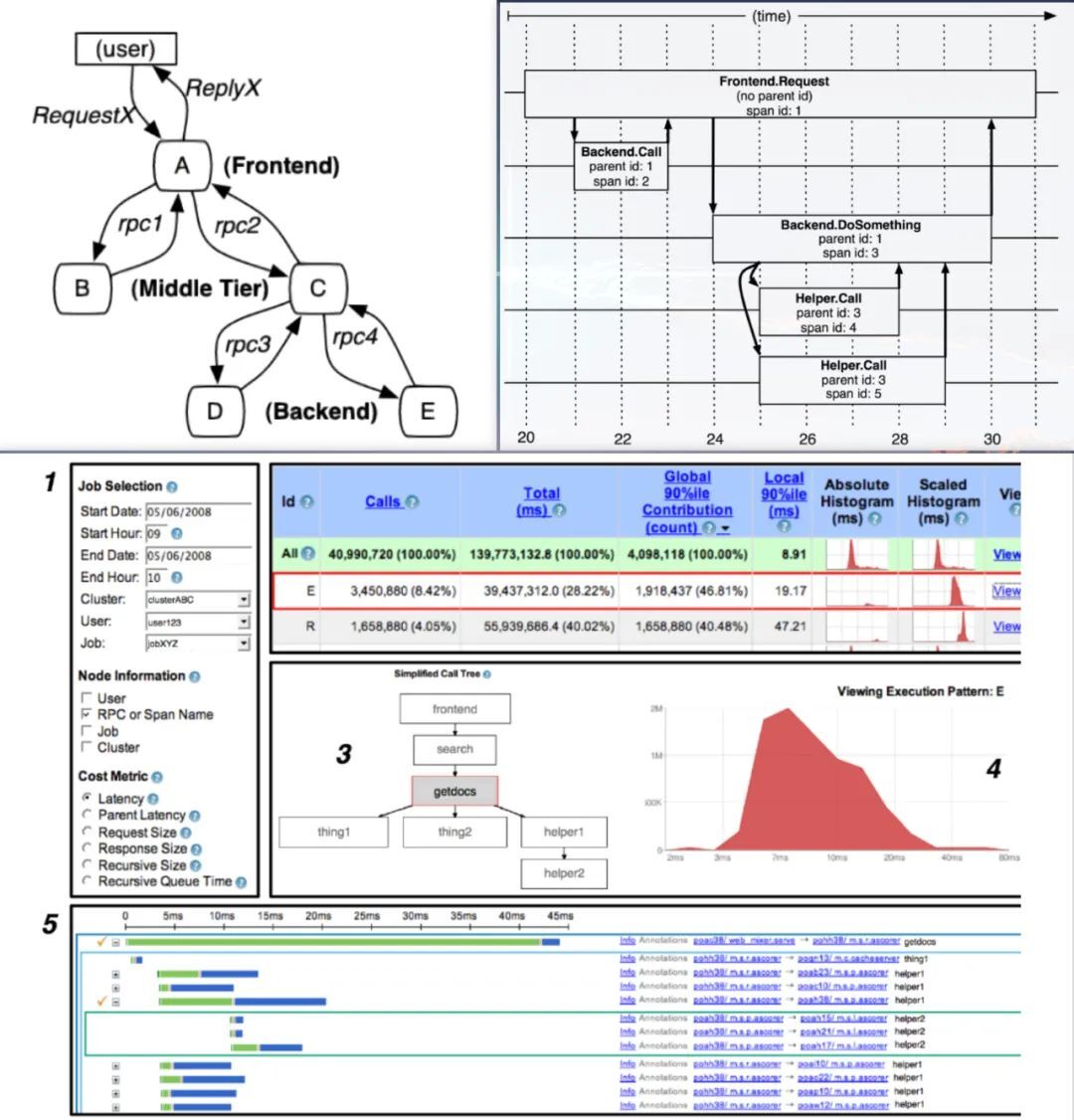
(图片来源:网络)
在此理论基础上,诞生了很多优秀的实现,如 zipkin、jaeger 。同时为了保证 API 兼容,他们都遵循 OpenTracing 标准。那 OpenTracing 标准是什么呢?
OpenTracing 翻译为开发分布式追踪,是一个轻量级的标准化层,它位于应用程序/类库和链路跟踪系统之间的一层。 这一层可以用下图表示:
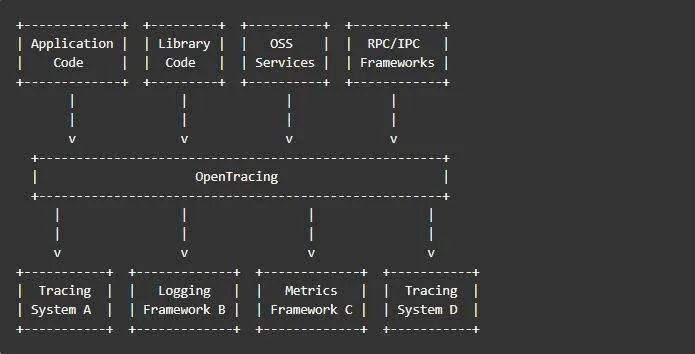
从上图可以知道, OpenTracing 具有以下优势:
- 统一了 API ,使开发人员能够方便的添加追踪系统的实现。
- OpenTracing 已进入 CNCF ,正在为全球的分布式链路跟踪系统,提供统一的模型和数据标准。
大白话解释下:它就像手机的接口标准,当今手机基本都是 typeC 接口,这样方便各种手机能力的共用。因此,做全链路信息存储,需要按照业界公认的 OpenTracing 标准去实现。
本篇文章将通过已有的优秀实现 —— zipkin ,来给大家阐述 Node.js 应用如何对接分布式链路跟踪系统。
二、zipkin
2.1 zipkin 是什么?
zipkin 是 Twitter 基于 Google 的分布式追踪系统论文的开发实现,其遵循 OpenTracing 标准。
zipkin 用于跟踪分布式服务之间的应用数据链路。
2.2 zipkin 架构
官方文档上的架构如下图所示:
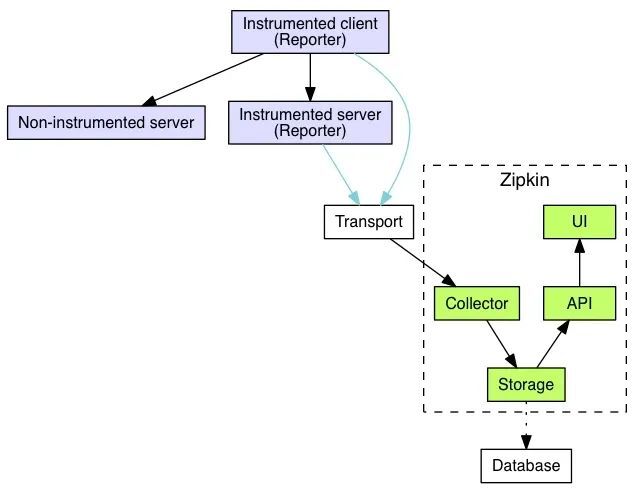
为了更好的理解,我这边对架构图进行了简化,简化架构图如下所示:
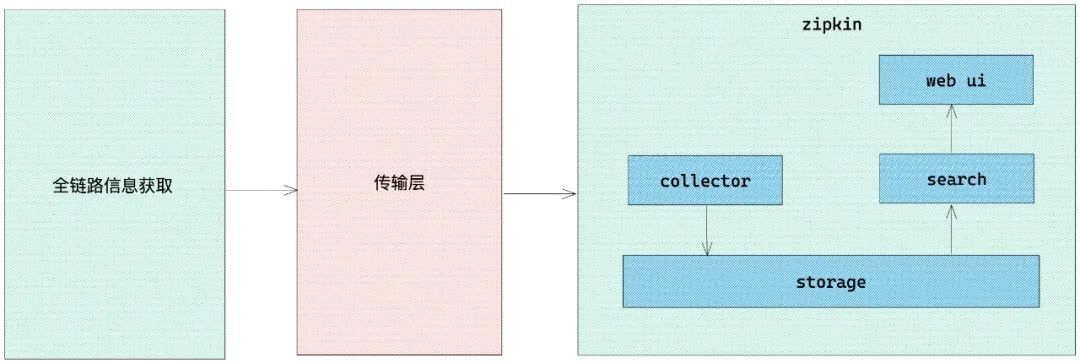
从上图可以看到,分为三个部分:
第一部分:全链路信息获取,我们不使用 zipkin 自带的全链路信息获取,我们使用 zone-context 去获取全链路信息
第二部分:传输层, 使用 zipkin 提供的传输 api ,将全链路信息传递给 zipkin
第三部分: zipkin 核心功能,各个模块介绍如下:
- collector 就是信息收集器,作为一个守护进程,它会时刻等待客户端传递过来的追踪数据,对这些数据进行验证、存储以及创建查询需要的索引。
- storage 是存储组件。zipkin 默认直接将数据存在内存中,此外支持使用 ElasticSearch 和 MySQL 。
- search 是一个查询进程,它提供了简单的 JSON API 来供外部调用查询。
- web UI 是 zipkin 的服务端展示平台,主要调用 search 提供的接口,用图表将链路信息清晰地展示给开发人员。
至此, zipkin 的整体架构就介绍完了,下面我们来进行 zipkin 的环境搭建。
2.3 zipkin 环境搭建
采用 docker 搭建, 这里我们使用 docker 中的 docker-compose 来快速搭建 zipkin 环境。
docker-compose.yml 文件内容如下:
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.0
container_name: elasticsearch
restart: always
ports:
- 9200:9200
healthcheck:
test: ["CMD-SHELL", "curl --silent --fail localhost:9200/_cluster/health || exit 1"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- TZ=Asia/Shanghai
ulimits:
memlock:
soft: -1
hard: -1
zipkin:
image: openzipkin/zipkin:2.21
container_name: zipkin
depends_on:
- elasticsearch
links:
- elasticsearch
restart: always
ports:
- 9411:9411
environment:
- TZ=Asia/Shanghai
- STORAGE_TYPE=elasticsearch
- ES_HOSTS=elasticsearch:9200在上面文件所在的目录下执行 docker-compose up -d 即可完成本地搭建。
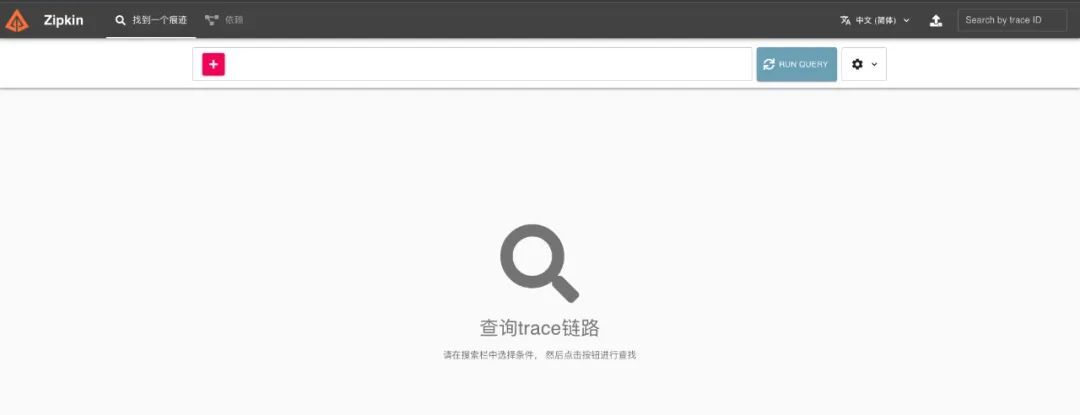
搭建完成后,在浏览器中打开地址 http://localhost:9411 ,会看到如下图所示页面:
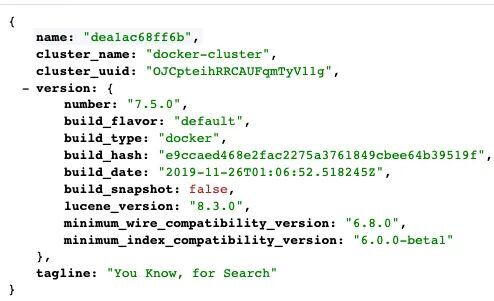
接着打开地址 http://localhost:9200 ,会看到如下图所示页面:
至此, zipkin 的本地环境就搭建好啦。 下面我就将介绍 Node.js 应用如何对接 zipkin。
三、Node.js 接入 zipkin
3.1 搞定全链路信息获取
这个我在 《Node.js 应用全链路追踪技术——全链路信息获取》 文章中,已经详细阐述了,如何去获取全链路信息。
3.2 搞定传输层
因为 zipkin 是基于 OpenTracing 标准实现的。因此我们只要搞定了 zipkin 的传输层,也就搞定了其他主流分布式追踪系统。
这里我们用到了 zipkin 官方提供的两个 npm 包,分别是:
- zipkin
- zipkin-transport-http
zipkin 包是官方对支持 Node.js 的核心包。 zipkin-transport-http 包的作用是将数据通过 HTTP 异步发送到 zipkin 。
下面我们将详细介绍在传输层,如何将将数据发送到 zipkin 。
3.3 传输层基础封装
核心代码实现和相关注释如下:
const {
BatchRecorder,
Tracer,
// ExplicitContext,
jsonEncoder: { JSON_V1, JSON_V2 },
} = require('zipkin')
const { HttpLogger } = require('zipkin-transport-http')
// const ctxImpl = new ExplicitContext();
// 配置对象
const options = {
serviceName: 'zipkin-node-service',
targetServer: '127.0.0.1:9411',
targetApi: '/api/v2/spans',
jsonEncoder: 'v2'
}
// http 方式传输
async function recorder ({ targetServer, targetApi, jsonEncoder }) => new BatchRecorder({
logger: new HttpLogger({
endpoint: `${targetServer}${targetApi}`,
jsonEncoder: (jsonEncoder === 'v2' || jsonEncoder === 'V2') ? JSON_V2 : JSON_V1,
})
})
// 基础记录
const baseRecorder = await recorder({
targetServer: options.targetServer
targetApi: options.targetApi
jsonEncoder: options.jsonEncoder
})至此,传输层的基础封装就完成了,我们抽离了 baseRecorder 出来,下面将会把全链路信息接入到传输层中。
3.4 接入全链路信息
这里说下官方提供的接入 SDK ,代码如下:
const { Tracer } = require('zipkin')
const ctxImpl = new ExplicitContext()
const tracer = new Tracer({ ctxImpl, recorder: baseRecorder })
// 还要处理请求头、手动层层传递等事情上面的方式缺点比较明显,需要额外去传递一些东西,这里我们使用上篇文章提到的 Zone-Context , 代码如下:
const zoneContextImpl = new ZoneContext()
const tracer = new Tracer({ zoneContextImpl, recorder: baseRecorder })
// 仅此而已,不再做额外处理对比两者,明显发现, Zone-Context 的实现方式更加的隐式,对代码入侵更小。这也是单独花一篇文章介绍 Zone-Context 技术原理的价值体现。
自此,我们完成了传输层的适配, Node.js 应用接入 zipkin 的核心步骤基本完成。
3.5 搞定 zipkin 收集、存储、展示
这部分中的收集、展示功能, zipkin 官方自带完整实现,无需进行二次开发。存储这块,提供了 MySQL 、 Elasticsearch 等接入方式。可以根据实际情况去做相应的接入。本文采用 docker-compose 集成了 ElasticSearch 。
四、总结
自此,我们已经完成基于业界通用 OpenTracing 标准实现的 zipkin 的 Node.js 方案。希望大家看完这两篇文章,对 Node.js 全链路追踪,有一个整体而清晰的认识。
参考资料:
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号