pandas读取数据(1)

pandas读取数据(1)

python数据可视化之路
发布于 2023-02-23 21:20:48
发布于 2023-02-23 21:20:48
访问数据是进行各类操作的第一步,本节主要关于pandas进行数据输入与输出,同样的也有其他的库可以实现读取和写入数据。
1、文本格式数据读写
将表格型数据读取为DataFrame是pandas的重要特性,下表总结了实现该功能的部分函数。
pandas的解析函数
函数 | 描述 |
|---|---|
read_csv | 读取csv文件,逗号为默认的分隔符 |
read_table | 读取table文件,也就是txt文件,制表符('\t')为默认分隔符 |
read_clipboard | read_table的剪贴板版本,在将表格从Web页面转换成数据时有用 |
read_excel | 读取XLS或XLSX文件 |
read_hdf | 读取pandas存储的HDF5文件 |
read_html | 从HTML文件中读取所有表格数据 |
read_json | 从JSON字符串中读取数据 |
read_sql | 将SQL查询结果读取为pandas的DataFrame |
read_stata | 读取Stata格式的数据集 |
read_feather | 读取Feather二进制格式 |
根据以前的读取经验,read_csv、read_table、read_excel和read_json三个最为常用。
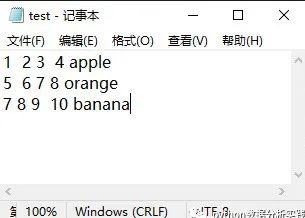
如图一个文本文件,我们用pandas读取。
import pandas as pd
data = pd.read_table(r"C:\Users\ASUS\Desktop\test.txt")
print('原始数据:\n', data)原始数据:
1 2 3 4 apple
0 5 6 7 8 orange
1 7 8 9 10 banana如果不是制表符,我们读取的时候可以指定分隔符:
data = pd.read_table(r"C:\Users\ASUS\Desktop\test.txt", sep='\s+')#sep为分隔符如果没有表头,我们可以读取的时候取消表头:
data = pd.read_table(r"C:\Users\ASUS\Desktop\test.txt", sep = '\s+', header = None)
print(data[:5]) 0 1 2 3 4
0 1 2 3 4 apple
1 5 6 7 8 orange
2 7 8 9 10 banana同时也可以指定列名:
data = pd.read_table(r"C:\Users\ASUS\Desktop\test.txt", sep = '\s+', names = ['l1', 'l2', 'l3', 'l4', 'name'] l1 l2 l3 l4 name
0 1 2 3 4 apple
1 5 6 7 8 orange
2 7 8 9 10 banana指定索引,可以传给参数index_col:
data = pd.read_table(r"C:\Users\ASUS\Desktop\test.txt", sep = '\s+', names = ['l1', 'l2', 'l3', 'l4', 'name'], index_col = 'name') l1 l2 l3 l4
name
apple 1 2 3 4
orange 5 6 7 8
banana 7 8 9 10如果想从多个列中形成分层索引,可以在index_col传入一个列表:
data = pd.read_table(r"C:\Users\ASUS\Desktop\test.txt", sep = '\s+', names = ['l1', 'l2', 'l3', 'l4', 'name'], index_col = ['name', 'l1']) l2 l3 l4
name l1
apple 1 2 3 4
orange 5 6 7 8
banana 7 8 9 10也可以使用skiprows跳过某一行或几行:
data = pd.read_table(r"C:\Users\ASUS\Desktop\test.txt", sep = '\s+', skiprows = 2)#跳过开头两行
data = pd.read_table(r"C:\Users\ASUS\Desktop\test.txt", sep = '\s+', skiprows = [0, 2, 3])#跳过第1、3、行缺失值的处理:是文件解析中一个重要的部分。通常情况下,缺失值要么不显示(空字符串),要么用一些标识值。pandas常见的标识值有:NA和NULL。

data = pd.read_table(r"C:\Users\ASUS\Desktop\test.txt", sep=',')
pd.isnull(data)
-----结果-----
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
可以对每列指定缺失值标识:
sentials = {'message':['foo', 'NA'], 'something':['two']}
pd.read_table(r"C:\Users\ASUS\Desktop\test.txt", sep = ',', na_values=sentials)
-----结果-----
something a b c d message
0 one 1 2 3.0 4 NaN
1 NaN 5 6 NaN 8 world
2 three 9 10 11.0 12 NaN分块读入文本文件:对于大型文件,我们可能只需要读取一小部分,我们在读取的时候仅需传入nrows即可。
data = pd.read_table(r"C:\Users\ASUS\Desktop\test.txt", sep = ',', nrows = 2)#读取前两行
-----结果-----
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world将数据写入文本文件:数据写入文本文件与数据读取相反,用到了to_csv方法。测试数据如下:
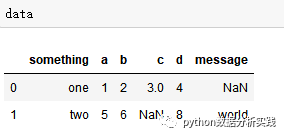
data.to_csv(r"C:\Users\ASUS\Desktop\result.txt")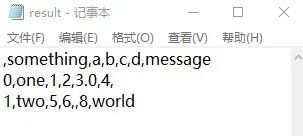
其他操作:sep可以指定分隔符;na_rep可以对缺失值进行标注;index和header可以指定行和列的标签是否被写入,值为True或False;columns可以根据指定的列的顺序传入。
data.to_csv(r"C:\Users\ASUS\Desktop\result.txt", sep = '\t', na_rep = '数据缺失', index = False, header = True, columns = ['message', 'something', 'a', 'b', 'c', 'd'])
总结:
在pandas读取文本文件(txt),常用参数有:
(1)sep:指定分隔符,默认为逗号
(2)header = None:取消读取首行
(3)names:指定列名,是一个列表
(4)index_col:指定索引列,可以为单列,也可以为多列
(5)skiprows:跳过前n行
(6)na_values:指定缺失值标识
(7)nrows:读取前n行
pandas输出文本文件(txt),常用参数有:
(1)sep:指定分隔符,默认为逗号
(2)na_rep:标注缺失值
(3)index:是否输出索引,默认输出
(4)header:是否输出列名,默认输出
(5)columns:指定输出时列的顺序
数据的读取和存储十分重要,规范化的数据能为后续的数据分析大大节约时间。下一篇将介绍Excel的读取和存储。
如果觉得本文有用,可以关注公众号——python数据分析实践,会不定期更新文章。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2021-01-25,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 python数据可视化之美 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号