解密游戏推荐系统的建设之路
原创

作者:vivo 互联网服务器团队- Ke Jiachen、Wei Ling
本文从零开始介绍了游戏推荐项目的发展历程,阐述了大型项目建设中遇到的业务与架构问题以及开发工程师们的解决方案,描绘了游戏推荐项目的特点以及业务发展方向,有着较好的参考与借鉴意义。
一、游戏推荐的背景与意义
从信息获取的角度来看,搜索和推荐是用户获取信息的两种主要手段,也是有效帮助产品变现的两种方式,搜索是一个非常主动的行为,并且用户的需求十分明确,在搜索引擎提供的结果里,用户也能通过浏览和点击来明确的判断是否满足了用户需求。
然而,推荐系统接受信息是被动的,需求也都是模糊而不明确的。
推荐系统的作用就是建立更加有效率的连接,更有效率地连接用户与内容和服务,节约大量的时间和成本。以此背景,游戏推荐系统由此诞生。

游戏推荐系统从设计之初就作为游戏分发的平台,向公司内所有主要流量入口(游戏中心、应用商店、浏览器、jovi等)分发游戏,系统通过各种推荐算法及推荐策略,为用户推荐下载付费意愿较高且兼顾商业价值的游戏,从而为公司带来收入。发展至今天,该系统还具备类游戏内容与素材的推荐功能。
二、游戏推荐的初期模型
游戏推荐的目的是推出用户想要且兼顾商业价值的游戏,以此来提高业务的收入指标。此处的商业价值是由运营侧通过策略规则去把控的,而用户意向游戏则是通过算法排序得到的,算法排序所需要的特征数据,以及推荐效果的反馈数据则由埋点信息上报以供计算分析。
因此我们的模型可以分成四大块:
- 运营推荐规则配置
- 算法模型训练
- 推荐策略生效
- 数据埋点上报
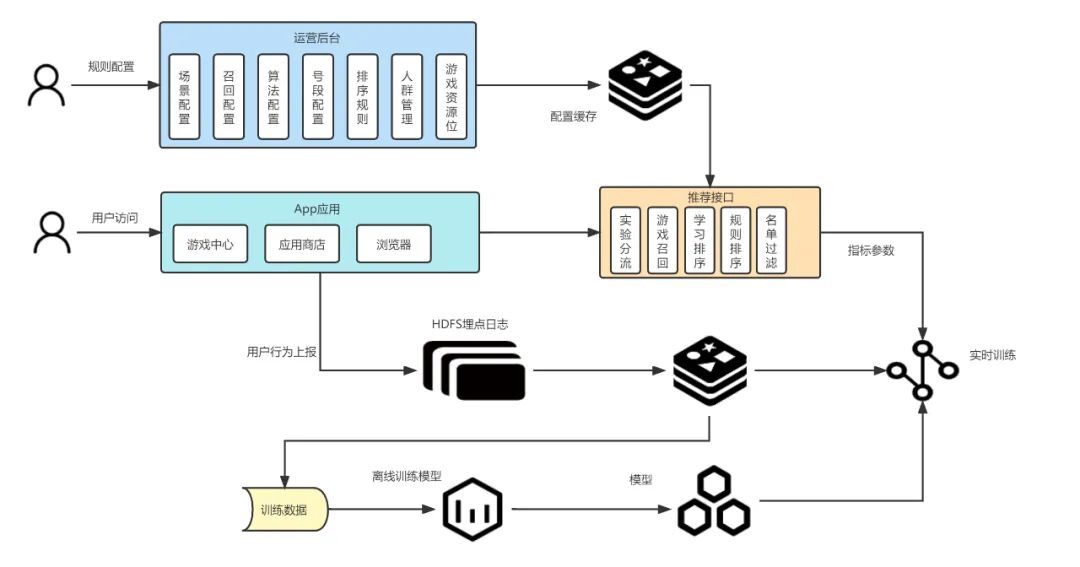
模块间的交互如下:在策略生效前,运营会先在配置中心生成对应的配置规则,这些规则会以缓存的形式存储以供推荐高并接口调用。当用户访问app应用某些特定页面时,其后台会带着对应的场景信息来请求游戏推荐后台,推荐后台根据场景信息映射相关配置(召回,标签,过期,算法等..........)调用算法服务并进行资源排序,最终将推荐的结果反馈给app应用。
app应用在展示推荐页面的同时,也将用户相应的行为数据以及推荐数据的相关埋点进行上报。
三、业务增长与架构演进
随着接入系统带来的正向收益的提升,越来越多的业务选择接入游戏推荐系统,这使得我们支持的功能日益丰富。
目前游戏推荐覆盖的场景有分类、专题、榜单、首页、搜索等;包含的策略类型有干预、打散、资源配比、保量;支持的推荐类型更是丰富:联运游戏、小游戏、内容素材、推荐理由。
这些丰富的使用场景使得业务的复杂度成本增长,令我们在性能,扩展性,可用性上面临着新的挑战,也推动着我们架构变革。
3.1 熵增环境下的通用组合策略
在0 到 1 的过程中,游戏推荐聚焦于提高分发量,这时候考虑得更多的是怎么把游戏推出去,在代码实现上使用分层架构来划分执行的业务。
但是在1 到 2 的过程中, 我们游戏推荐不仅仅推荐游戏,也推荐内容和素材;同时在策略调用上也更加灵活,不同场景其调用的策略是不同的,执行顺序也是不同的;更重要的是加入了很多用户个性化业务与动态规则,这些都使得现有业务代码急剧膨胀,扩展起来捉襟见肘,无从下手。因此我们急需一个高复用,易扩展,低代码的策略框架去解决这些问题。
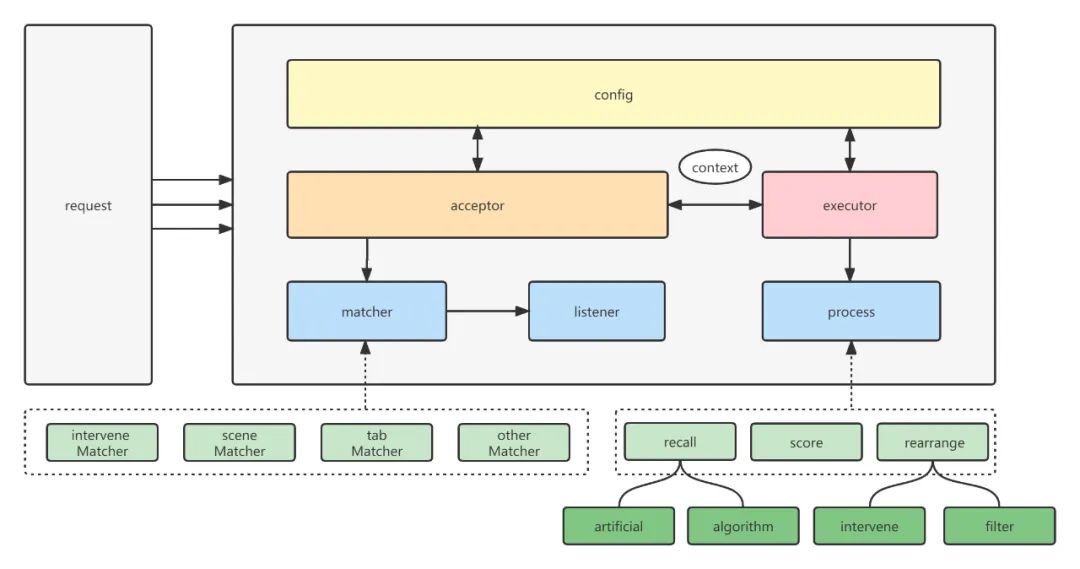
如图所示,通用组合策略负责流转的角色有两个acceptor和executor,通讯媒介是推荐上下文context。负责执行逻辑的角色有三个matcher,listener和process,它们都有多个不同逻辑的实现类。当请求游戏推荐系统时,acceptor会先从配置中动态查询策略模板进行匹配,接着listener组件会执行相应的预处理逻辑。处理后acceptor通过上下文context将任务流转给executor处理器。executor再根据配置,将process根据前置条件进行筛选并排列组合,最后埋点返回。
经过这套通用的策略,我们在实现一般业务的时候,只要扩展具体matcher和process,并在配置中心将场景和处理优先级绑定起来,就能完成大部分的场景开发,这样研发者可以更聚焦于某个逻辑流程的开发,而不用疲于梳理代码,并进行扩展设计。
3.2 多级缓存与近实时策略
游戏推荐系统服务于手机游戏用户,处于整个系统链路的下游,峰值流量在3W TPS左右 ,是个读远多于写的系统。“读”流量来自于用户在各种推荐场景,列表、搜索、下载钱下载后、榜单等,写数据主要来源于运营相关策略的变更,所以我们面临的一个重大挑战就是如何在保证可用性的前提下应对高频的读请求。
为了保证系统的读性能,我们采用了redis + 本地缓存的设计。配置更新后先写mysql,写成功后再写redis。本地缓存定时失效,使用懒加载的方式从redis中读取相关数据。这种设计能保证最终一致性,软状态时服务集群数据存在短暂不一致的情况,早期对业务影响不大,可以认为是一个逐步放量的过程。
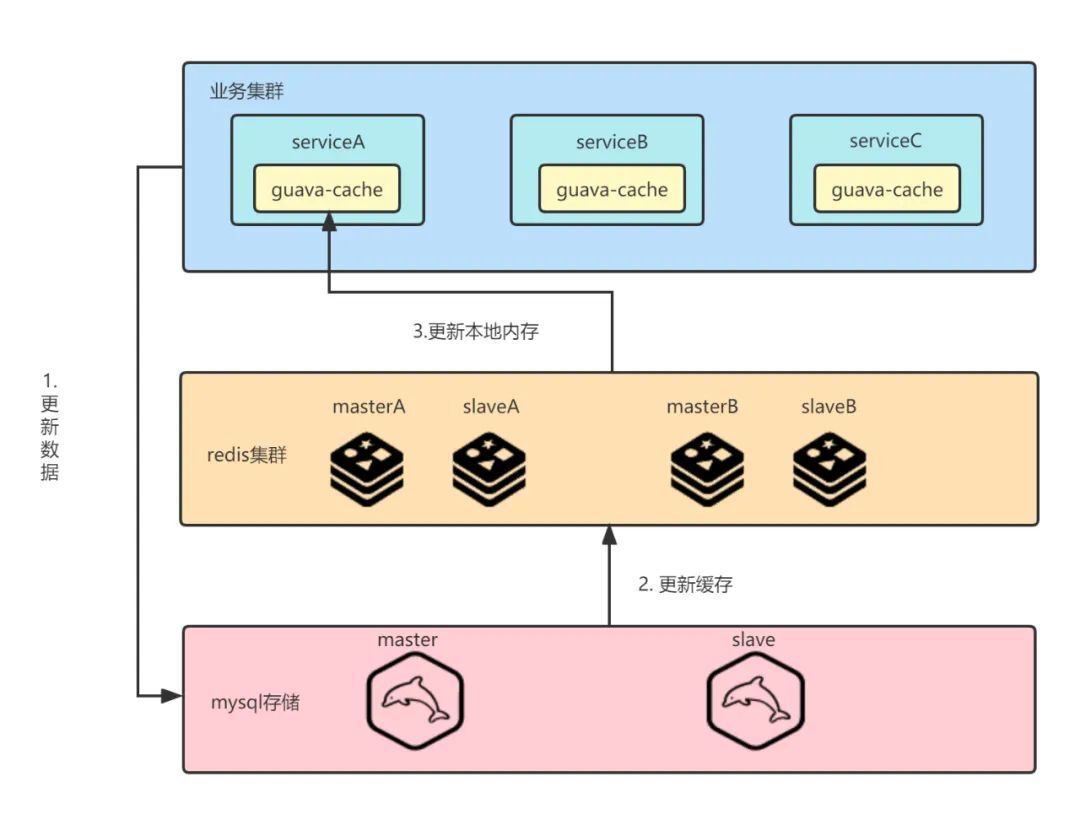
早期原先部署节点较少,整个系统达到最终一致性的时间较短,但随着节点增加到数百台,这个时间就变得不是那么和谐了。
同时随着业务复杂度的增加,常常是多个配置策略决定这一个推荐结果,此时本地缓存的状态极大影响了测试和点检的便利,如果配置更改不能做到立马更新本地缓存,那就要等待漫长的一段时间才能开始验证逻辑。因此,我们对缓存结构做出了如下的调整:

与先前不同的是,我们加入消息队列并通过配置版本号的比对来实现策略的实时更新同步,取得了很好的效果。
3.3 高并服务的垃圾回收处理
任何一个java服务都逃离不了FGC的魔咒,高并服务更是如此。很多服务每天两位数的FGC更是家常便饭,显然这对业务的稳定性和服务性能影响是巨大的。游戏推荐这边通过不断实践总结了一套较为通用的方法很好地解决了这个问题:
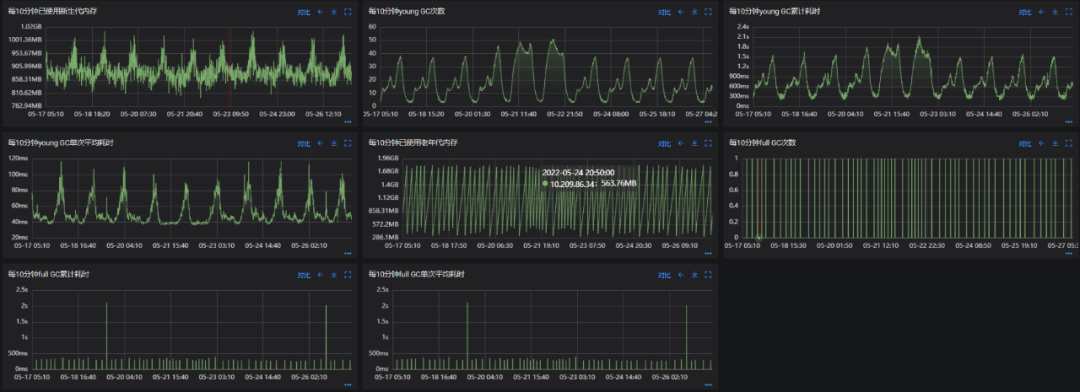
可以看到起初jvm配置较为常规:1G的年轻代,2G的老年代以及一些其他常见的多线程回收的配置,其结果就是每天10次的FGC,YGC单次耗时在100ms,FGC耗时在350 - 400ms。我们知道线上接口容忍的范围一般是200ms以内,不超过300ms,这样显然是不达标的。
通过分析,我们发现高并服务的高频FGC来源于这几个方面:
- 大量的本地缓存(堆内)占据了老年代的空间,大大增加了老年代叠满的频率。
- 高并请求导致了对象的急速生成,年轻代空间不足以容纳这剧增的对象,导致其未达到存活阈值(15次)就晋升至老年代。
- 引入的监控组件为了性能,常常延迟 1 - 2 min再将数据上报服务端,导致这部分数据也无法在年轻代被回收。
当然这还不是问题的全部,FGC还有个致命问题就是stop the world,这会导致业务长时间无法响应,造成经济损失。反过来,就算FGC频繁,stop the world 只有1ms,也是不会对业务造成影响的,因此不能单单以FGC的频率来判断jvm服务的gc性能的好坏。经过上面的探讨,我们在实践中得到了如下的解决方案:
- 不常变化的缓存(小时级别)移到堆外,以此减少老年代叠满的基础阈值。
- 变化不那么频繁的缓存(分钟级别)更新的时候进行值对比,如果值一样则不更新,以此减少老年代的堆积。
- 使用G1回收器:-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=25 -XX:MaxNewSize=3072M -Xms4608M -Xmx4608M -XX:MetaspaceSize=512M -XX:MaxMetaspaceSize=512M

其效果如上所示,调整后各项指标都有很大的进步:由于年轻代中的复制算法使其垃圾清理速度较快,所以调大其容量使对象尽量在其中回收,同时设置每次清理的时间,使得mix gc控制在200ms以内。
3.4 限流降级与兜底策略
为了保证业务的可用性,大部分业务都会引入hystrix, sentinel, resilience4j 这类熔断限流组件, 但这些组件也不能解决全部的问题。
对于游戏推荐来说,一台节点往往承载着不同的业务推荐,有些业务十分核心,有些不是那么重要,限流降级的时候不是简单的哪个服务限流多少问题,而是在权衡利弊的情况下,将有限的资源向哪些业务倾斜的问题,对此我们在分层限流上下足了功夫。
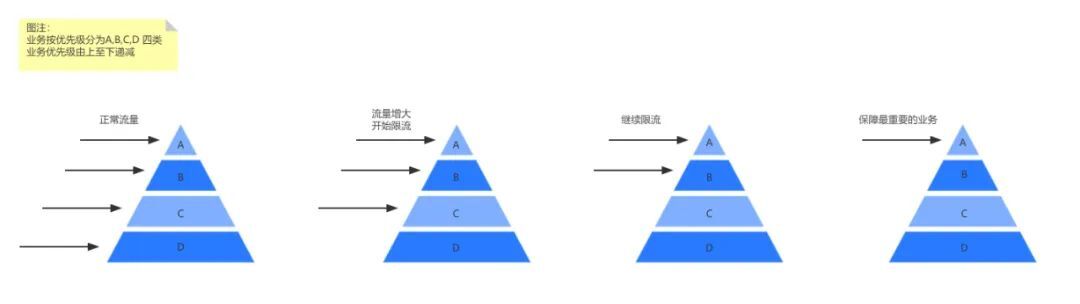
同时对于个性化业务来说,仅仅返回通用的兜底会使推荐同质化,因此我们的策略是将用户的历史数据存储下来,并在下次兜底的时候作为推荐列表进行返回。

四、精细化运营模式的探索
在经历过了0 到1 的开疆拓土 与 1 到 2 的高速增长后,游戏的推荐架构已经趋于稳定。这时候我们更加关注效能的提高与成本的下降,因此我们开始着手于系统运营的精细化设计,这对推荐系统的良性发展是意义重大的。
精细化运营不仅能提高尾量游戏的收入,提高运营人员的工作效率,还能实时快速反馈算法在线效果并立马做出调整,做到一个业务上的闭环。首先就不得不提到游戏推荐系统的分层正交实验平台,这是我们做精细化运营的基础。
4.1 多层 hash 正交实验平台
游戏推荐的关键就一个"准"字,这就需要通过精细化策略迭代来提升效率和准确度,从而不断扩大规模优势,实现正向循环。然而策略的改变并不是通过“头脑风暴”空想的,而是一种建立在数据反馈上的机制,以带来预期内的正向变化。这就需要我们分隔对照组来做A/Btest。
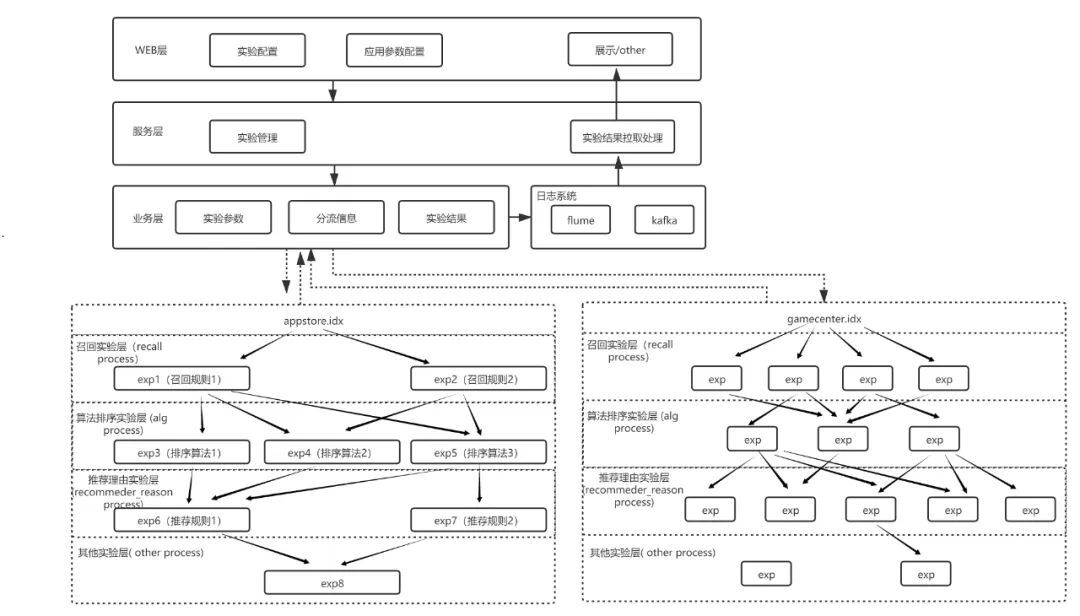
一般线上业务常见的A/B test是通过物理方式对流量进行隔离,这种方法常见于H5页面的分流实验,但面对复杂业务时却存在着部署较慢,埋点解析困难等问题,其典型的架构方式如下:

对于游戏推荐来说,其完成一次推荐请求的流程比较复杂,涉及到多组策略,为了保证线上流量的效率与互斥,就不能采用简单的物理分配流量的方式。
因此在业务层我们建立了一套多层hash正交实验规则来满足我们A/B test的要求。
其流量走势如下图所示,
与物理隔离流量,部署多套环境的方式不同,分层模型在分流算法中引入层级编号因子(A)来解决流量饥饿和流量正交问题。每一实验层可以划分为多个实验田,当流量经过每一层实验时,会先经过Function(Hash(A)) 来计算其分配的实验田,这样就能保证层与层之间的流量随机且相互独立。
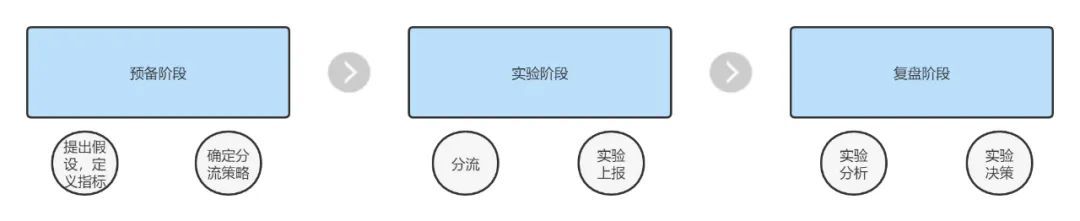
以上就是推荐业务和一般业务实验流量隔离的不同之处,在实验设计上我们又将一个完整的实验周期分为以下几个阶段。在预备阶段需要跟根据业务指标的需求,提出实验假设,划分好基线和实验田的流量比例,并上线配置(放量)。
在实验阶段,线上流量进入后,服务会根据流量号段的匹配响应的策略进行执行,并将实验数据上报。放量一段时候后,我们会根据上报的埋点数据进行数据分析,以确定此次策略的好坏。
和实验阶段划分相对应地,我们将实验平台划分为实验配置,埋点上报和实验结果分析三个模块,在实验配置模块,我们根据实验需求来完成分流配置和业务场景的映射关系。

并在hash实验管理中将业务层级划分,以便流量的流通。
在埋点上报模块中,我们通过sdk的方式植入业务代码中,当流量进入该实验田时就会进行分析和埋点上报,我们将上报的埋点分为游戏和请求维度,节省上报流量的同时以满足不同的分析需求:
游戏维度:
{
"code": 0,
"data": [
{
"score": 0.016114970572330977,
"data": {
"gameId": 53154,
"appId": 1364982,
"recommendReason": null,
},
"gameps": "埋点信息",
}
],
"reqId": "20200810174423TBSIowaU52fjwjjz"
}
请求维度:
{
"reqId":"20200810142134No5UkCibMdAvopoh",
"scene": "appstore.idx",
"imei": "869868031396914",
"experimentInfo": [
{
"experimentId": "RECOMMENDATION_SCENE",
"salt":"RECOMMENDATION_SCENE",
"imei": "3995823625",
"sinfo": "策略信息"
},
{
"experimentId": "AUTO_RECOMMENDATION_REASON",
"salt":"RECOMMENDATION_SCENE",
"imei": "1140225751",
"sid": "3,4,5"
}
]
}在实验结果分析模块中,我们将采集的埋点的数据上报只大数据侧,并由其进行分析计算,其结果指导这我们对实验策略进行进一步的分析迭代。对于游戏请求的上报格式,我们可以直接通过appId和gameps的信息直接分析得出该类游戏的推荐结果和用户行为的关系。同时加入请求维度的分析(包含策略信息),可以直接分析出决策对各项指标的影响。
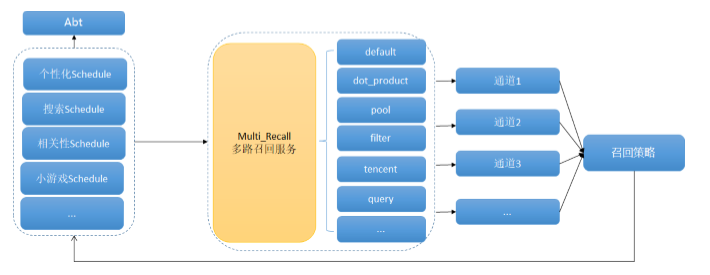
4.2 召回优化之多路召回
召回在游戏推荐业务中就是利用一定的规则去圈选一批游戏,这是为了将海量的候选集快速缩小为几百到几千的规模。而召回之后的排序则是对缩小后的候选集进行精准排序,最终达到精准推荐的目的。
然而这种单路的召回在业务上却有着很大的缺陷:
- 通常为了保证计算效率,圈选的数量在几百个左右,由于数量限制其无法完全覆盖完整的目标用户候选集。
- 随着业务的复杂度变高,召回策略的种类也开始膨胀,其召回规则是剥离的无法统一,这也意味着在某些业务场景下,在种类上无法覆盖完全。

因此,权衡了计算效率和业务覆盖度(召回率)的问题,我们逐步上线了多路召回功能。
在业务实现上,多路召回兼容了原有的个性化召回、算法召回、游戏池召回、分类/标签/专题/同开发者)召回等召回路径,通过圈选多个游戏池做为召回策略,经过合并、过滤、补量、截断等策略最终筛选出一批进行算法预估打分的游戏。
本质上,多路召回利用各简单策略保证候选集的快速召回,从不同角度设计的策略保证召回率接近理想状态。
4.3 曝光干预之动态调参
一个推荐系统的效能如何,除了运营策略之外很大程度上取决于推荐算法的结果,而推荐算法的结果又是以曝光量,下载量,ctr等作为评价指标的。所以在游戏推荐业务的生命周期中,推荐算法一直致力于优化这些指标。
但是在开发中有个实际问题就是,从算法结果的数据反馈,到代码改进上线这个时间周期较长,对一些需要快速响应的业务场景来说是不符合要求的。因此我们需要一套规则来对线上的算法结果做动态调整,以满足业务的要求,这就是动态调参。
目前游戏业务的营收中,曝光量是个极其重要的指标,而大盘在一段时间内的曝光量是确定的,太多或太少都会严重影响业务,由此推荐算法就会根据线上实时反馈的一些数据对游戏的曝光进行调整。

经过设计, 我们先将调参游戏划分为多个等级,并将游戏的生命周期划分为几个时间段,同时在每个时间段内以游戏曝光量,评级,数量等因素作为计算因子来计算曝光的分配权重。
接着系统根据实时采集的游戏曝光信息及所计算的游戏目标曝光对实际曝光进行调整,最终实现游戏曝光的动态调控。
对于正向调控来说,动态调参就是最有效的扶持机制,增加了游戏曝光的同时提升了导流能力。对于负向调控,动态调参能对品质和要求不达标的游戏,通过减少曝光的方式进行打压,提升用户体验。
五、展望之智能化建设
经过多年的探索实践,游戏推荐系统成就了一套完整的推荐体系。
在架构上的演进使得我们能更好地应对复杂多变的业务需求,在精细化运营上的探索与建设令我们能更加敏锐地把握住市场的变化以做出响应,这些建设也很好地反馈的反馈到了业务结果中,提升了众多效能和收益指标,得到了业务方的一致好评。
但当分发效率和收入效益问题解决了之后,我们在思考自己还能做什么,原先游戏推荐做的比较多的是接入服务,在单链路上去做闭环提高效益,但这是远远不够的。
在未来我们会考虑如何打造覆盖搜广推+ 智能运营的全栈业务支撑系统(智能礼券,智能push,用户反馈智能处理系统),以提升平台和渠道的价值。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号