科大讯飞CTR预估挑战赛Top3方案总结


前一阵子,老肥参加了科大讯飞AI开发者大赛的部分比赛,主要包括结构化、音频、文本以及图像这四大类型,总体来看都是较为简单的任务并且解题方案也较为简单,后续会跟大家一一分享。
今天要分享的是结构化的赛题-创意视角下的数字广告CTR预估挑战赛。
赛题任务
广告的CTR预估需要强大的数据作为支撑,本次大赛提供了讯飞AI营销云海量的现网流量和创意数据作为训练样本,参赛选手需基于提供的样本构建模型,预测测试集的点击率,点击率的准确性将直接影响评价结果。
数据说明
本次比赛的数据主要包括:标注数据、媒体流量数据、广告创意数据以及其他业务Embedding向量。其中,标注数据为样本的Label信息,媒体流量数据主要是流量媒体APP和广告位来源信息。本次挑战赛首次公开了元素级广告创意数据,包含创意的文字、图片素材等,选手可基于创意进行深度的特征工程挖掘,包含但不限于大小,色系,利益点,元素Embedding等。
总体来说就是包含了多个ID信息、Embedding特征以及文本图像的一个多模态的数据。
评价指标
评价指标采用GAUC,在这其中, 权重取为流量媒体的广告位上的点击数,为媒体广告位上的AUC。
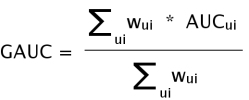
方案概述
首先对文本和图像进行特征提取,确认多模态信息的有效性。文本直接采用TF-IDF再进行SVD降维得到特征表示拼接到主表,图像采用预训练模型VIT直接抽取Embedding向量再拼接到主表,经过线下和线上的验证得出本题多模态信息提取意义不大的结论。于是,最终确定的整体解决方法为基于特征工程的树模型,整体方案如下所示。

对于本方案,首先进行数据处理。
第一步讲初赛的训练集与复赛的训练集进行拼接,
第二步对数据进行去重(包含部分数据所有字段值完全相同的情况),
第三步对数据进行压缩处理,节省内存的使用。
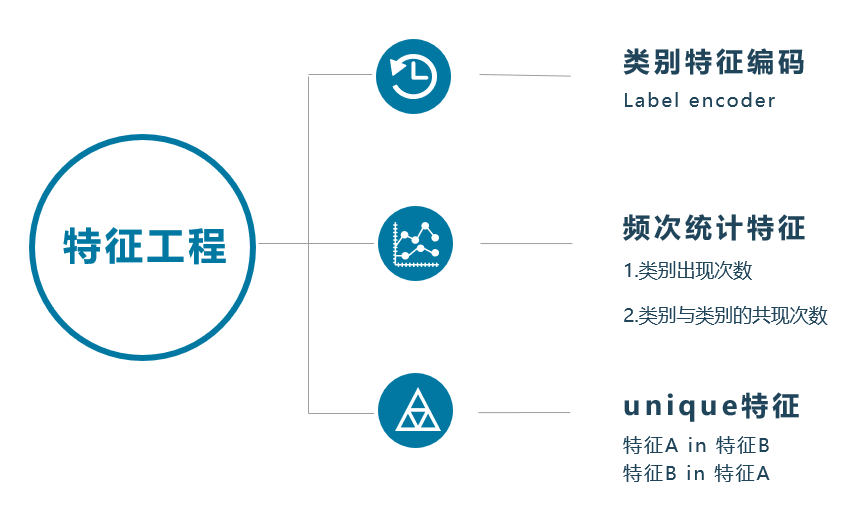
然后是特征工程部分,包含常规的一些统计特征:包括频数统计特征(单类别出现的次数以及类别共现次数)、unique特征(A类别在B类别中的unique,B类别在A类别中的unique),以及类别变量的Label Encoder编码。对于240维的Embedding,我们对低信息量的特征进行删除(unique值较小),对剩余Embedding特征进行mean、std的统计(groupby各个ID特征)。
最后是模型训练的部分,采用常规的分层五折交叉验证,将对测试集的预测概率取均值得到最后的预测结果。该方案在线上排名到第三位的成绩,另外,如果我们不进行重复数据删除,而是对数据重复次数进行统计作为特征输入,再应用上述方案可以排到排行榜第一位,得分为0.68098。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-11-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号