Sounds Identification on CM7

Sounds Identification on CM7

用户6026865
发布于 2023-03-03 09:21:32
发布于 2023-03-03 09:21:32
Sensory was credited for “inventing the wake word”. Sensory certainly helped to evangelize and popularize it, but we didn’t “invent” it. What we really did was substantially improve upon the state of the art so that it became useable. And it was a VERY hard challenge since we did it in an era before deep learning allowed us to further improve the performance.
Today Sensory is taking on the challenge of sound and scene identification.
Sensory announced our initial SoundID solution at CES 2019.
Since then we have been working on accuracy improvements and adding gunshot identification into the mix of our sounds (CO2 and smoke alarms, glass break, baby cry, snoring, door knock/bell, scream/yell, etc.) to be identified.
General Approach. Sensory is using its TrulySecure Speaker Verification platform for sound ID. This approach using proprietary statistical and shallow learning techniques runs smaller models on device. It also uses a wider bandwidth filtering approach as it is intended to differentiate speech and sounds as opposed to simply recognizing words.
A 2nd stage approach can be applied to improve accuracy. This second stage uses a DeepNet and can also run on device or in the cloud. It is more MIPS and memory intensive but by using the first stage power consumption is easily managed, and the first stage can be more accepting while the 2nd stage eliminates false alarms.
Second Stage (Deep Neural Network) eliminates 95% of false alarms from the first stage, while passing 97% of the real events. This enables to tune to the desired operating point (1 FA/day, .5 FAs/day, etc…). FR rate stays extremely low (despite of FA reduction) due to very accurate deep neural network and a “loose” first stage that is less discriminative.
Second stage classifier (deep neural network) is trained on many target sound examples. In order to separate target events from similar sounding non-target events we apply proprietary algorithmic and model building approaches to remove false alarms. Combined model (1st and 2nd stage) smaller than 5 MB.
Does a 3rd stage make sense? Sensory uses its TrulyHandsfree (THF) technology performing key word spotting for its wake words, and often transfers to TrulySecure for higher performance speaker verification. This allows wake words to be listened for at the lowest possible power consumption. Sensory is now exploring using THF as an initial stage for Sound ID to enable a 3 stage approach with the best in accuracy and the best in power consumption. This way power consumption can average less than 2 milliamps.
The difference between a quiet and noisy environment is quite pronounced. It’s easy to perform well in quiet and very difficult to perform great in noise, and it’s a different challenge than we faced with speech recognition, as the noises we are looking to identify can cover a much wider range of frequencies that can more closely match background noises.
Recorded sound effects are quite different than they sound live. The medium of playback (mobile phone vs PC vs high end speaker) can have a very big impact on the frequency spectrum and the ability to identify a sound. Once again this is quite different than human speech which falls into a relatively narrow frequency band and isn’t as affected by the playback mechanism. For testing, Sensory is using only high-quality sound playback.
Some sounds are repeated others aren’t. This can have a huge effect on false rejects where the sound isn’t properly identified. It can be a “free” second chance to get it right. But this ability varies from sound to sound, for example, a glass break probably happens just once and it is absolutely critical to catch it; whereas a dog bark or baby cry happening once and not repeating may be unimportant and OK to ignore. We will show the effect on repeated sounds on accuracy tests.
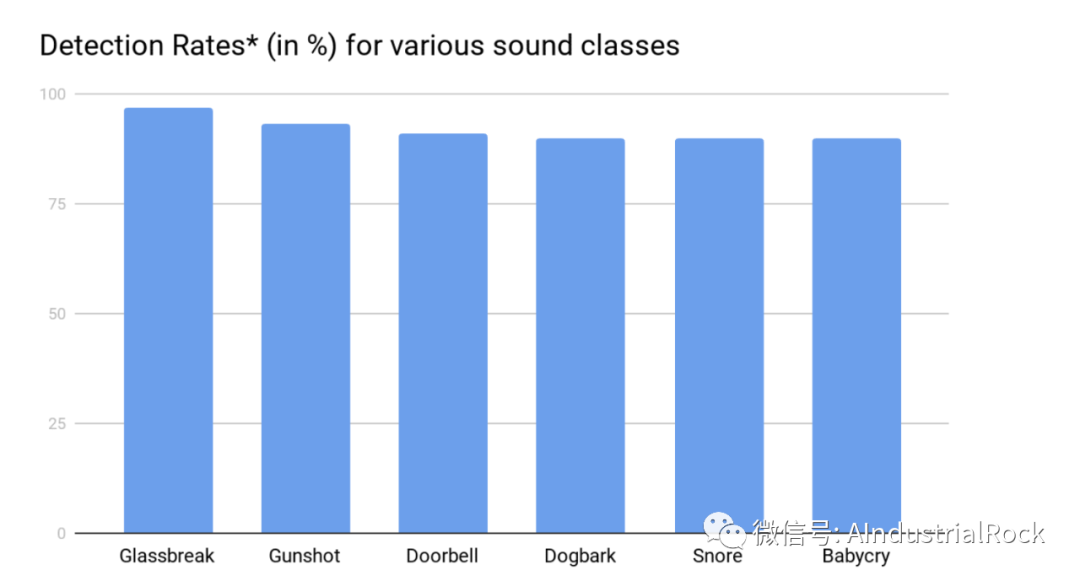
This at 1 FA in 24 hours on balanced mix of noise data. We tend to work on the sounds until we exceed 90% accuracy with 1 FA/day. So its no surprise that they hover in the same percentage region…some of these took more work than others.
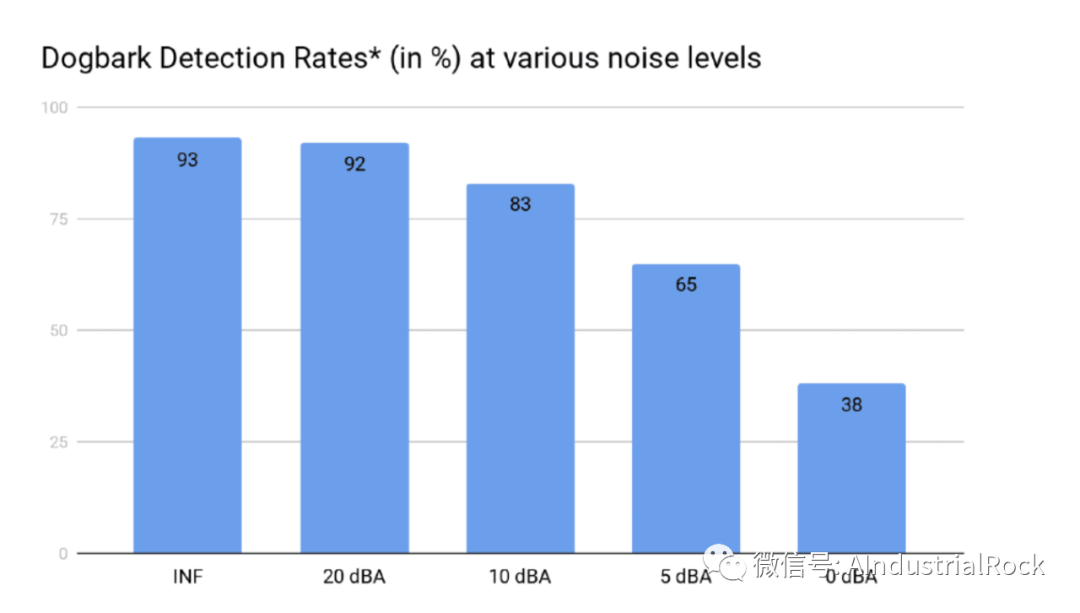
Once again at 1 FA in 24 hours on balanced mix of data. You can see how detection accuracy drops as noise levels grow. Of course we could tradeoff FA and FR to not drop performance so rapidly, and as the chart below shows we can also improve performance by requiring multiple events.
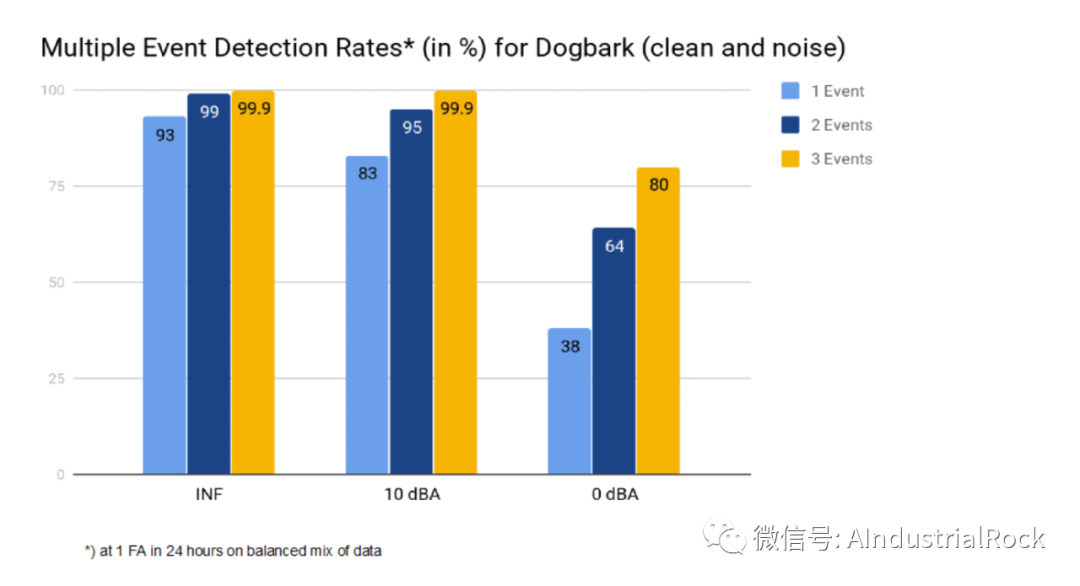
Assuming 1 FA in 24 hours on balanced mix of data. The general effects of multiple instances hold true across sound ID categories. So for things like repeated dog barks or baby cries the solution can be very accurate.
As a dog owner, I really wouldn’t want to be notified if my dark barked once or twice in a minute, but if it barked 10 times within a minute it might be more indicative of an issue I want to be notified about. Devices with Sensory technology can allow parametric controls of the number of instances to cause a notification.
Sensory is very proud of our progress in sound identification. We welcome and encourage others to share their accuracy reporting…I couldn’t find much online to determine “state of the art”.
Now we will begin work on scene analysis…and I expect Sensory to lead in this development as well!
Below is a demo to showcase Sensory's SoundID running on Cortext M7 MCU from STMicro.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-12-22,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 SmellLikeAISpirit 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号