Learn R 函数和R包
原创

函数与参数
形式参数与实际参数 形式参数99%可以删除
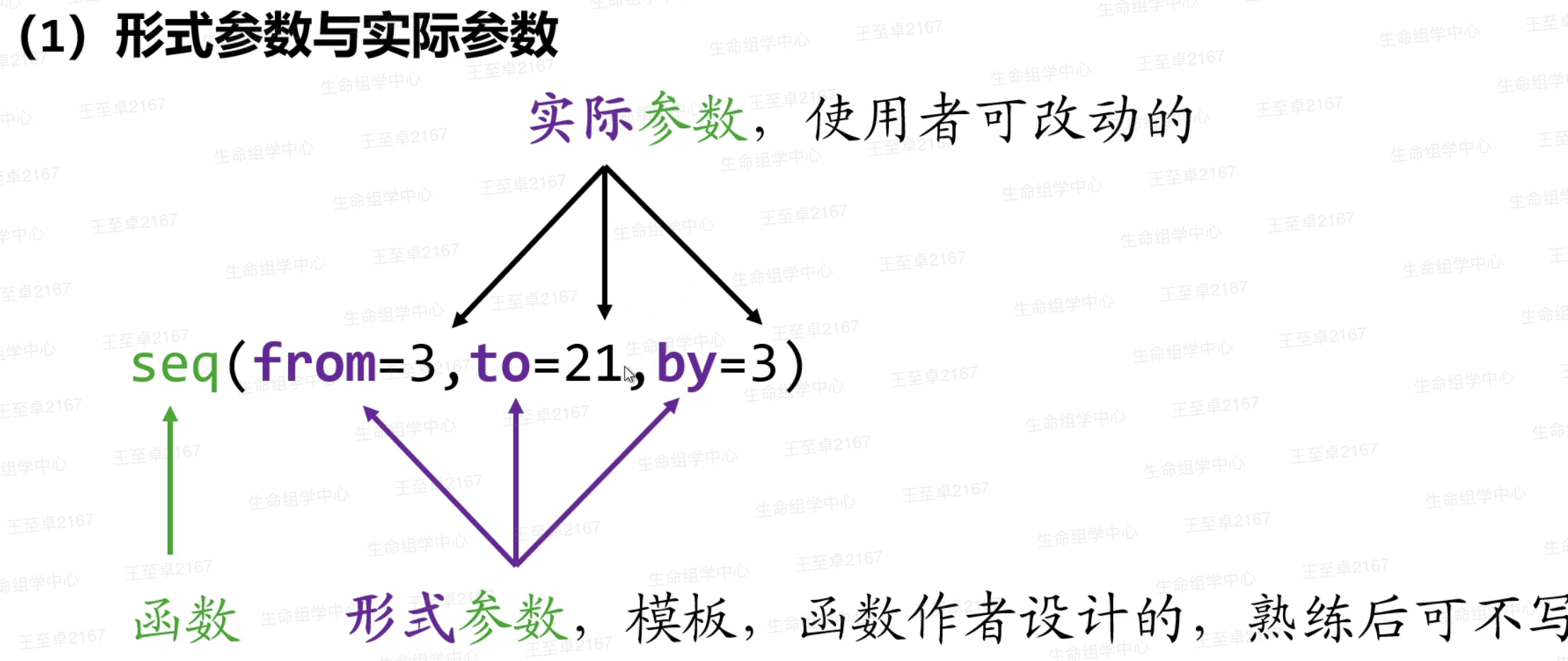
形式参数与实际参数
命名新的函数
> jimmy <- function(a,b,m = 2){
+ (a+b)^m
+ }。#命名jimmy这个函数,自己设置 m=2是默认值
> jimmy(a = 1,b = 2)
[1] 9
> jimmy(1,2) #省略写法
[1] 9
> jimmy(3,6)
[1] 81
> jimmy(3,6,-2) #更改m的值 有2改为-2
[1] 0.01234568
复习:绘图函数plot()
par(mfrow = c(2,2)) #把画板分成四块,两行两列
x = c(2,5,6,2,9);plot(x)
x = seq(2,80,4);plot(x)
x = rnorm(10);plot(x)
x = iris$Sepal.Length;plot(x)
#只要是数值型向量都可以画图思考:plot画iris的前四列?
> plot(iris[,1],col = iris[,5]) #按照第五列给每个点分配颜色
> plot(iris[,2],col = iris[,5])
> plot(iris[,3],col = iris[,5])
> plot(iris[,4],col = iris[,5])
#当一个代码需要复制粘贴三次,就应该写成函数或使用循环,用新的函数进行代替
> jimmy <- function(i){
+ plot(iris[,i],col=iris[,5])
+ }
> jimmy(1)
> jimmy(2)
> jimmy(3)
> jimmy(4)练习4-1
# 写一个函数,参数是一个数值型向量,输出结果是该向量的平均值加2倍的标准差,并写出用户使用该函数的代码 。
> m2d=function(x){+mean(x)+2*sd(x)} #sd()是标准差 不会是一个值
> m2d(rnorm(10))
[1] 1.738949R包 介绍
R包都在哪里
#### 1) CRAN网站
>install.package( ) #包名要加“”
#### 2) Bioconductor 网站
>BiocManager::install( )
#### 3) github
>devtools::install_github( ) #需要把用户名也写上
#如果不知道包从哪里来 先试前两个 若不行 就是github上的
# 安装完之后的加载(相当于打开软件)
>library() #load()是加载数据的
>require()
#注:一次安装,每次打开新的session(窗口)都要加载
#国内镜像推荐
清华镜像(tuna,Beijing)
http://mirrors.tuna.tsinghua.edu.cn/CRAN/
http://mirrors.tuna.tsinghua.edu.cn/bioconductor/
中科大镜像(ustc,Hefei)
http://mirrors.ustc.edu.cn/CRAN/
http://mirrors.ustc.edu.cn/bioc/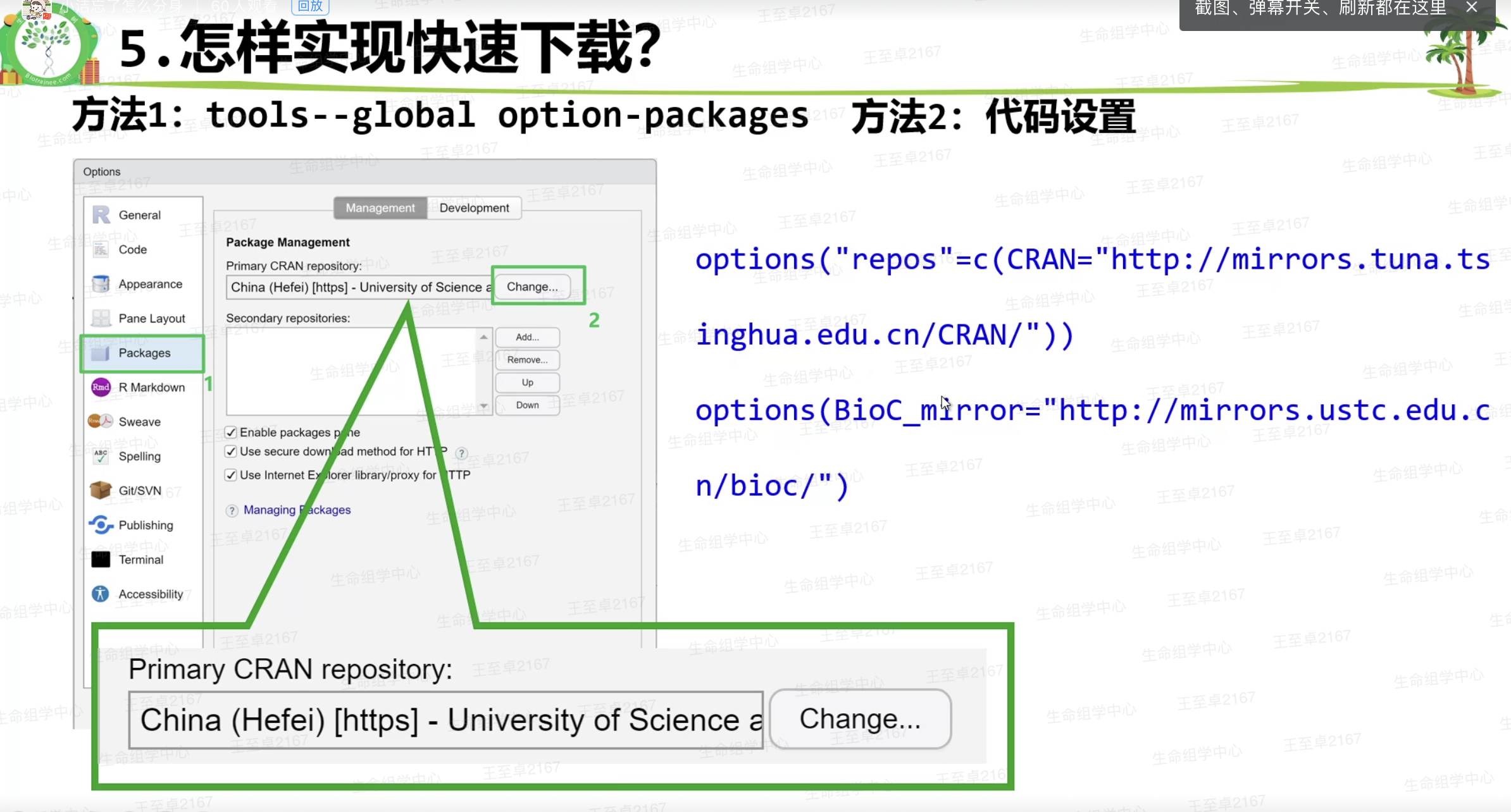
Rstudio中直接从镜像下载设置
#已经安装的包,可用::快速调用
>pheatmap::pheatmap(volcano)
#相当于
>library(pheatmap)
>pheatmap(volcano)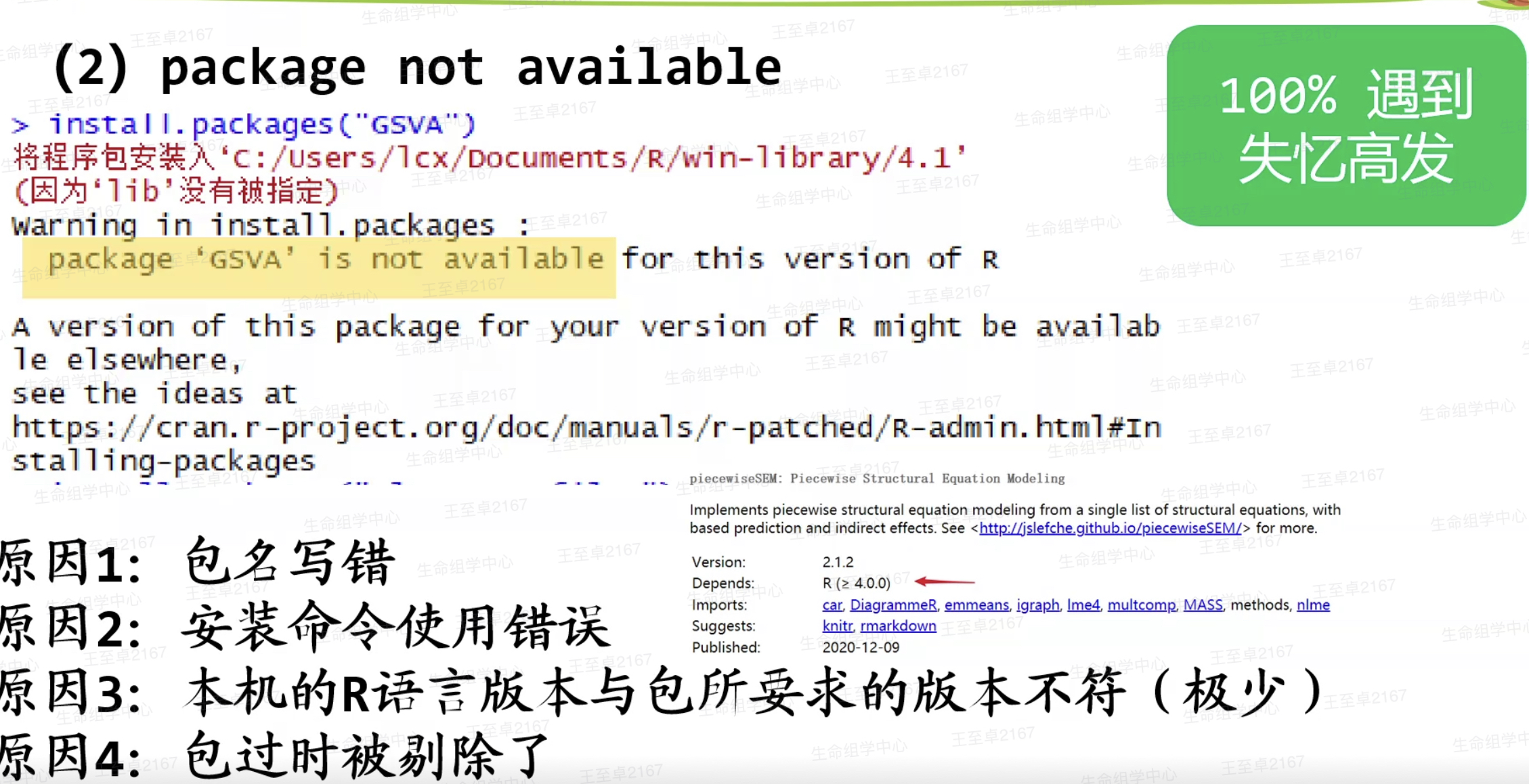
下载包是常见问题

#require()和library()的区别
if(!require(stringr))install.packages("stringr") #如果没有安装str这个包则安装
library() #没安装就会报错
require() #没安装只为warning
as.logical(require( )) #require可以转换为逻辑值,加载成功为T否则为F获取帮助
?seq #查询seq()函数
library(stringr)
browseVignettes("stringr") #浏览网页版stringr()函数的功能
ls("package:stringr") #ls是展示出该包中的函数R语言中的函数
()前的是函数
[] 是取子集,一定是个数据 【】里有“,”->向量或矩阵
[[]] 前的通常是个列表 列表取子集
$ 数据框取子集
<- 赋值
= 赋值,或连接形式参数与实际参数
== 判断是否相等
! 否定
{ } 用于容纳多行代码
#注释
" " 字符型数据
::包::函数#文件名必须带引号,且在能识别文件名称的函数括号里面,实际参数位置上
文件的读写
csv格式
> read.csv("ex3.csv")
CSV (Comma Separated Values) 以逗号为分隔符
TSV (Tab Separated Values) 以tab为分隔符
#读取csv文件的方式 tab键输入
#1.csv的默认格式是表格;
#2.记事本也可以打开;
#3.sublime(适用大文件)打开
#4.R语言读取
#表格文件读到R语言中,就得到了一个数据框,对数据框进行的修改不会同步到表格文件,需重新导出分隔符
常见的分隔符:逗号、空格、制表符(\t)将表格文件读取到R语言中
read.table() #读取txt格式
read.csv()#读取csv格式文件的导出 不要覆盖原文件 代码可重复 数据可重现
csv格式:write.csv()
write.csv(原文件名,file="xxx.csv") #把该文件导出为名为xxx的csv格式
txt格式:write.table()
write.table(原文件名,file="xxx.txt") #把该文件导出为名为xxx的txt格式R语言特有的数据保存格式
#Rdata R语言中特有的数据储存格式,无法用其他软件打开
#保存的是变量(向量、矩阵、列表等),不是表格文件
>save() #保存 save只能用于保存Rdata
>save(test,file="xxx.Rdata")
>load() #加载
>load("xxx.Rdata")
#不需要进行赋值 如x=load("xxx.Rdata") Rdata本身含有变量的不需要再进行赋值
#在当前文件夹(data自己建立的文件夹)下用“/”打开
>read.csv("data/ex1.txt")
#同样把文件保存到当前目录的文件夹(Rdata 自己建立的文件夹)中
>save(test,file="Rdata/xxx.Rdata")
#当前在一个文件夹中想要调用另一个文件夹的Rdata
#方法一 复制路径下载
getwd()
[1] "/Users/zhuo/learn /R_02" #找到当前目录 复制路径进行修改
> load("/Users/zhuo/learn /R_01(1)/gands.Rdata")
#方法二 ../ 是一级目录
>load("../R_01/gands.Rdata")
-----注意:用tab补齐文件名称 避免出错-------文件读写部分
#1.读取ex1.txt 用read.table(" ")
> ex1 <- read.table("ex1.txt")
> ex1 <- read.table("ex1.txt",header = T) #文件里的第一行作为列名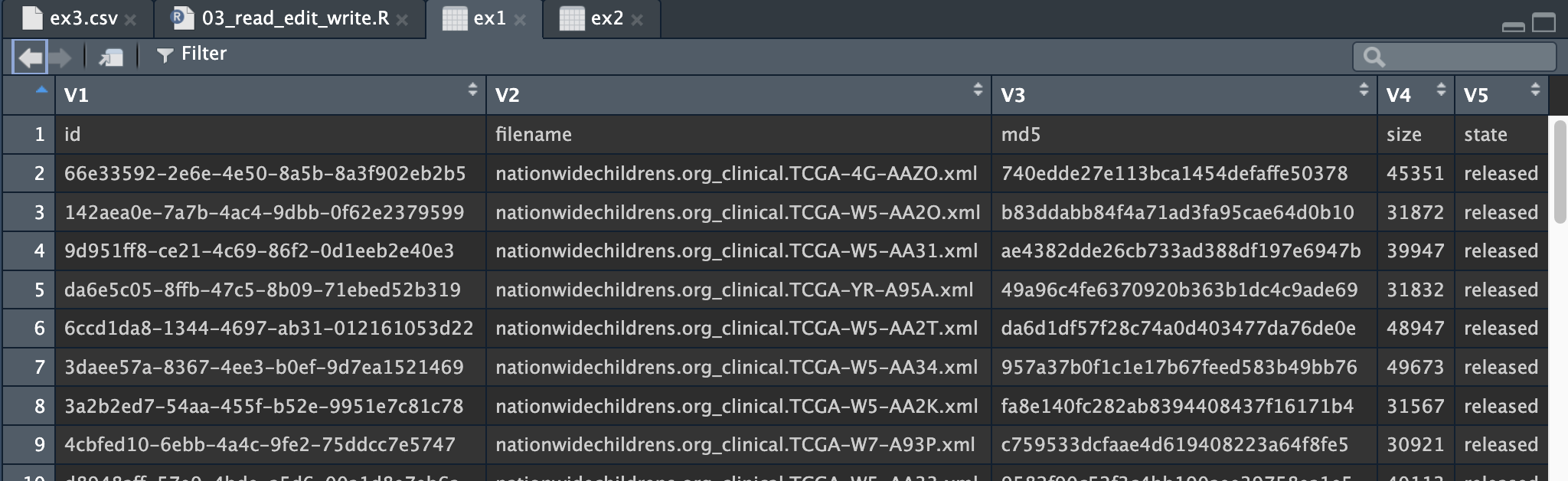
第一行不为列名
#2.读取ex2.csv
> ex2 <- read.csv("ex2.csv")
> View(ex2)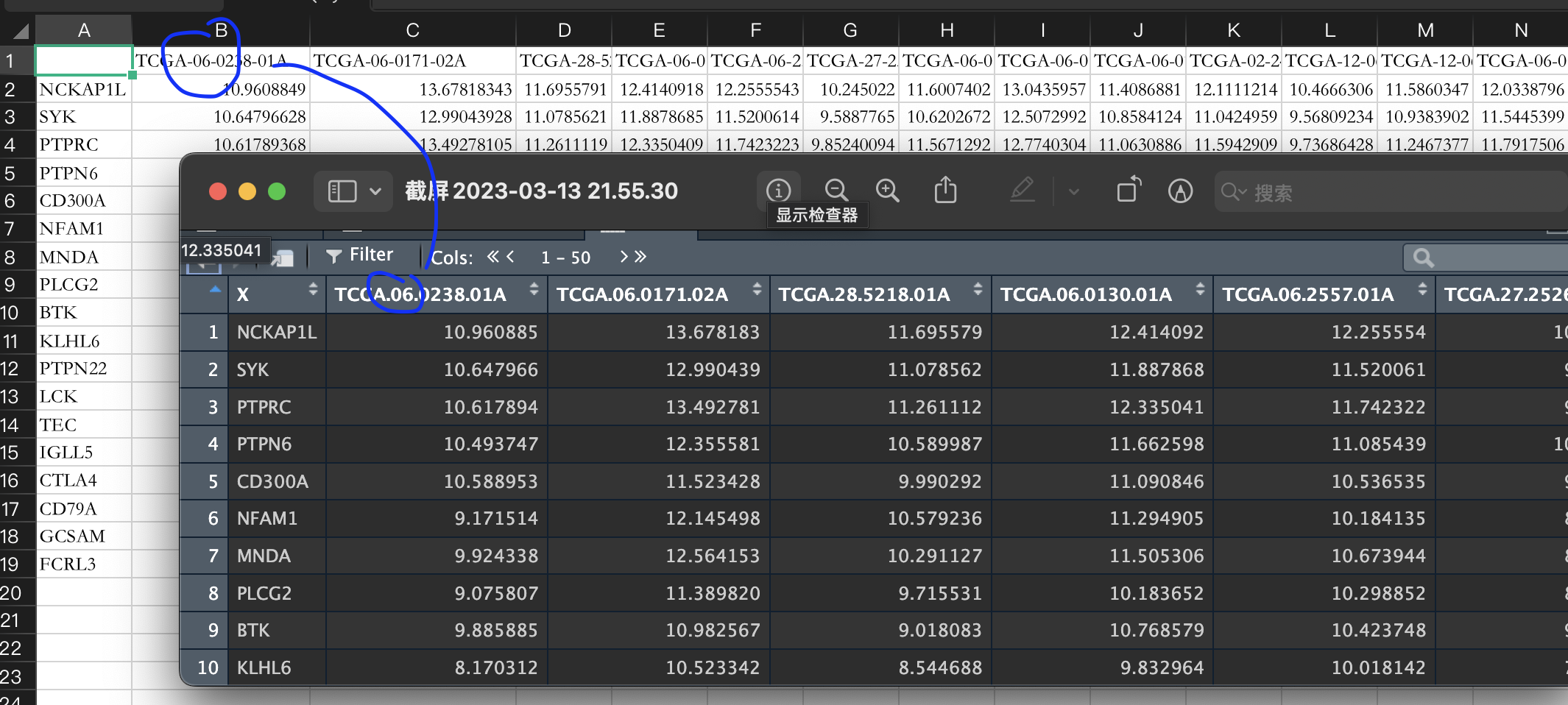
第一行不为列名,TCGA后的符号改变(R把特殊符号都改为-)
>ex2 <- read.csv("ex2.csv",row.names = 1,check.names = F)
#check.names = F不转换里面的符号;row.names = 1 设置第一列为行名
-------注意,数据框不允许有重复的行名,也就是第一列不能有重复值------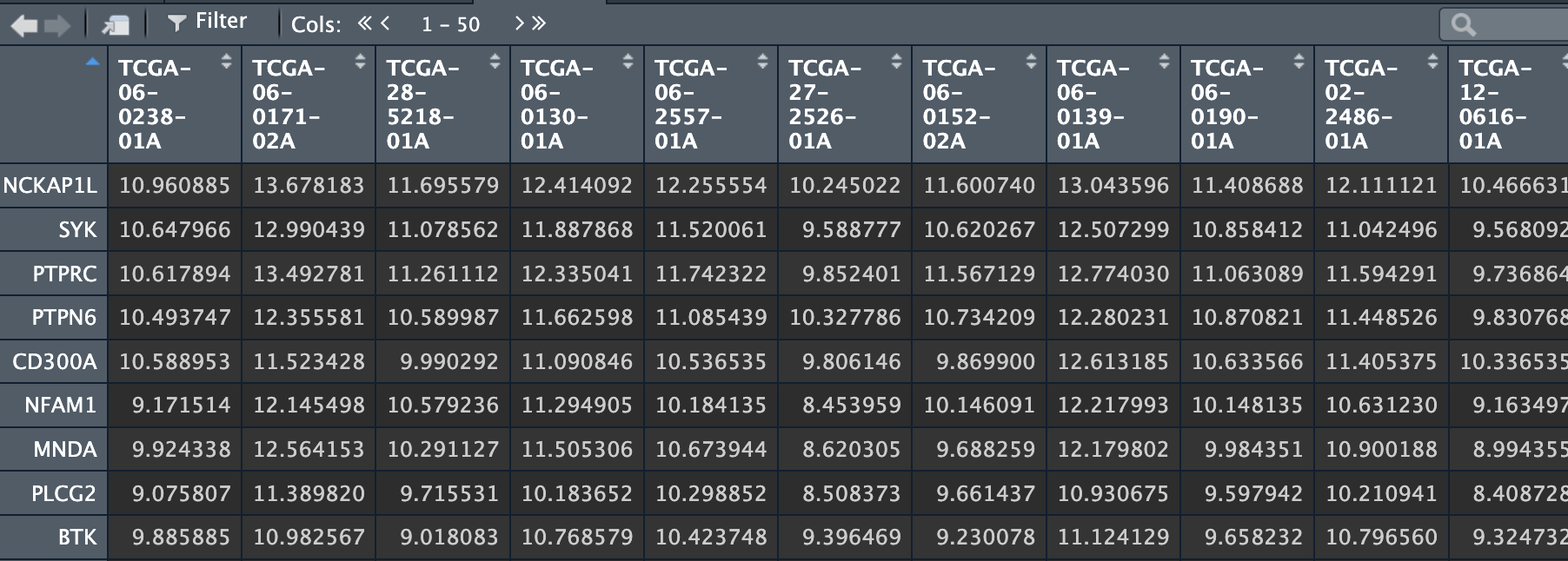
ex2.csv更改后
3.读取soft.txt
>soft <- read.table("soft.txt") #代码报错 因为数据不方正
>soft <- read.table("soft.txt",header = T,fill = T) #其实不对
#fill=T 是将有空的地方填充一下 但与原本的不对应,需加上sep=\t
>soft2 <- read.table("soft.txt",header = T,sep = "\t")4.soft 的行数列数是多少?列名是什么
> dim(soft)
[1] 1000 5
> colnames(soft)
[1] "ID" "SEQUENCE" "GeneName" "GB_ACC" "SPOT_ID"5.将soft导出为csv
>write.csv(soft,file = "soft.csv")6.将soft保存为Rdata并加载。
>save(soft,file = "soft.Rdata")
>rm(list = ls()) #将环境中的所有数据清空 为了看保存的文件
>load(file = "soft.Rdata") 练习5.1
# 1.读取complete_set.txt(已保存在工作目录)
> x=read.table('complete_set.txt',header = T)
----注,提前先打开看看数据的格式,看用不用headerheader=T----
# 2.查看有多少行、多少列
> dim(x)
[1] 50 20
# 3.查看列名
> colnames(x)
[1] "geneA" "geneB" "geneC" "geneD" "geneE" "geneF" "geneG"
[8] "geneH" "geneI" "geneJ" "geneK" "geneL" "geneM" "geneN"
[15] "geneO" "geneP" "geneQ" "geneR" "geneS" "geneT"
> # 4.导出为csv格式
> write.csv(x,file = "x.csv")
# 5.保存为Rdata,再加载它
> save(x,file="x.Rdata")
> rm(list = ls())
> load("x.Rdata")6.加载y.Rdata(已保存在工作目录),求gene1列的平均值
> load("y.Rdata")
> mean(y$gene1)
Error in y$gene1 : $ operator is invalid for atomic vectors # 报错
> class(y) #查看y的数据类型是矩阵
[1] "matrix" "array"
> mean(y[,1])
[1] NA
Warning message:
In mean.default(y[, 1]) : argument is not numeric or logical: returning NA
> y[,1]
GSM1 GSM2 GSM3 GSM4 GSM5 GSM6 #都是字符型向量
"40" "20" "51" "46" "38" "49"
> mean(as.numeric(y[,1])) #转变为数字型向量
[1] 40.66667
#第二种
> y[,1] = as.numeric(y[,1])
> y[,1]
GSM1 GSM2 GSM3 GSM4 GSM5 GSM6 #出现的仍是字符型“ ”,因为矩阵中只允许一种数据类型 要把整个都改为数字型
"40" "20" "51" "46" "38" "49" R语言可以读取的文件格式
###通用格式
csv. xls. txt. tsv. json. pdf. spss.
###生信格式
fasta. fastq. bam. vcf. bed. gtf.#参考基因组注释文件读取文件格式
#### 1.base包
>read.tabel()
>read.csv()
>read.delim() #替代read.table() 默认参数sep=/t ,不用在重新输入
>write.table()
>write.csv()
#### 2.readr包
>read_tabel()
>read_csv()
>read_tsv()
>write_table()
>write_csv()
#### 3.fread()函数读取 read.table()智能版
>a=data.table::fread("soft.txt",data.table = F)#读取很智能,不会导致窜列
#### 4.rio包 可以读取任何形式,但有问题的文件仍有问题,根据文件的后缀读取,特殊
>import()
>import_list()
>export()
>rio::export(a,file="a.xlsx")
>b=rio::import("a.xlsx")
-----来自生信技能树----
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
作者已关闭评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号