Learn R1 1-2
原创

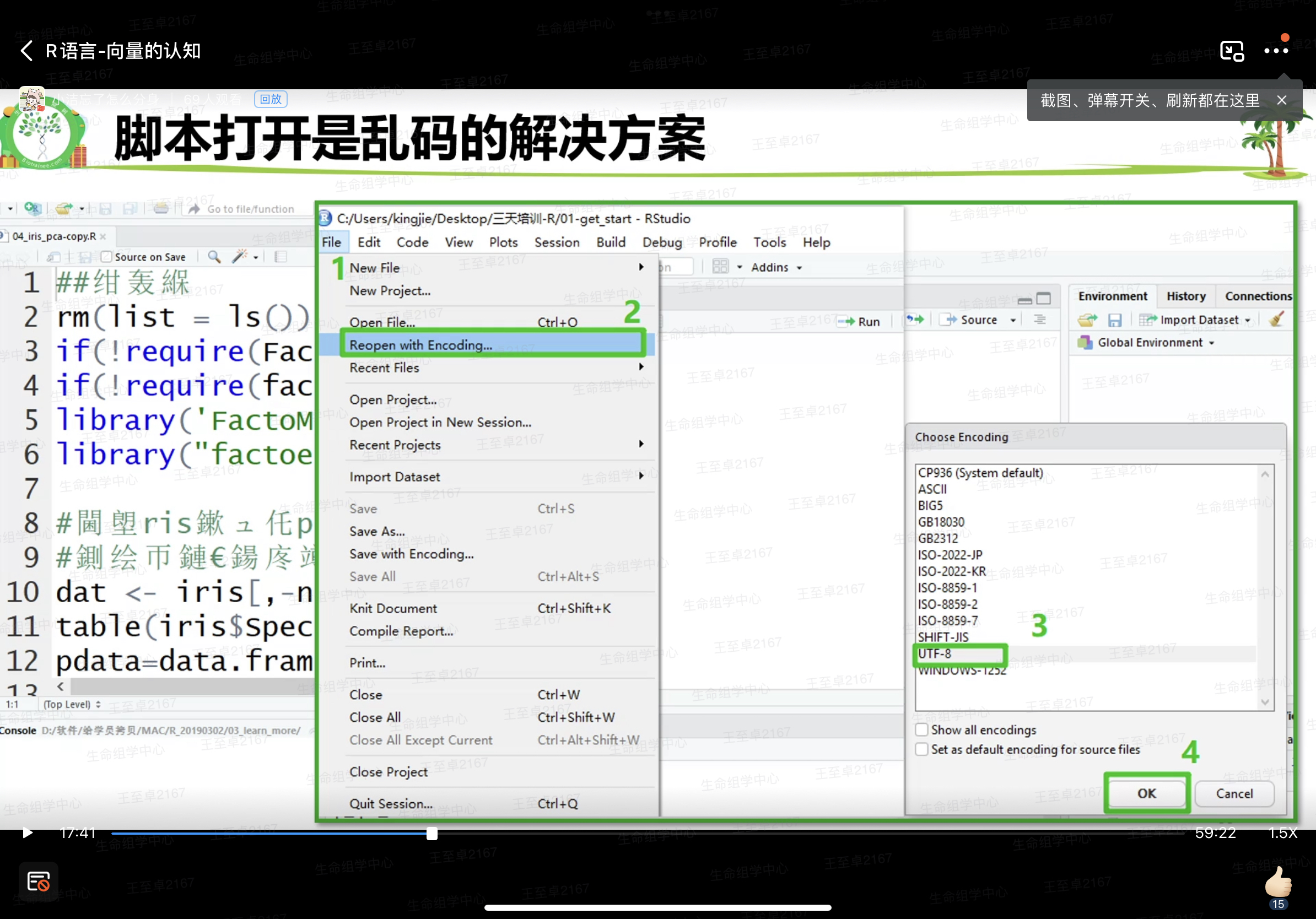
脚本打开是乱码的解决方案
#####2.1.向量生成🌟#####
#(1)用 c() 结合到一起
c(2,5,6,2,9)
c("a","f","md","b") #字符型的向量一定要用引号
#(2)连续的数字用冒号“:”
1:5
#(3)有重复的用rep(),有规律的序列用seq(),随机数用rnorm()
rep("x",times=3) #把x字符重复三次
seq(from=3,to=21,by=3) #从3-21 每三个数取一个数
rnorm(n=3) #生成三个随机数(用于测试数据)
#(4)通过组合,产生更为复杂的向量。
paste0(rep("x",times=3),1:3) 1"x1" "x2" "x3" paste(rep("x",times=3),1:3) 1 "x 1" "x 2" "x 3"
#####2.2对单个向量进行的操作####
#(1)赋值给一个变量名 不输出
x = c(1,3,5,1) #随意的写法 x既称为向量也称为对象
x <- c(1,3,5,1) #规范的赋值符号 Alt+减号
#赋值+输出一起实现
x <- c(1,3,5,1);x #必须用;分开,相当于两行代码和在了一行
(x <- c(1,3,5,1)) #用()直接括起来 空格和减号都是特殊字符 不要随意用
#(2)简单数学计算
x+1 # x中的每个向量都+1
log(x)
sqrt(x)
#(3)根据某条件进行判断,生成逻辑型向量
x>3
x==3 #x是否等于3
#(4)初级统计
max(x) #最大值 x所有向量中的最大值
min(x) #最小值 x所有向量中的最小值
mean(x) #均值 x所有向量的平均值
median(x) #中位数
var(x) #方差
sd(x) #标准差
sum(x) #总和
length(x) #长度x向量中有几个元素
unique(x) #去重复重复:是指从左往右第二/多次出现的相同的元素会被去除
duplicated(x) #对应元素是否重复对x中的元素进行是否重复的判断
!duplicated(x)#对应元素不是重复——TRUE
table(x) #重复值统计 对每个元素重复的次数进行统计
sort(x) #排序 默认从小到大排列
sort(x,decreasing = F) #默认从小到大排序相当于sortsort( )
sort(x,decreasing = T) #从大到小排序用decrease
###2.2 练习###
1.生成1到15之间所有偶数
seq(from = 1,to = 15,by = 2) seq(from = 2,to = 15,by = 2)
2.生成向量,内容为:"student2" "student4" "student6" "student8" "student10" "student12" "student14"
提示:paste0
paste0(rep("student",times = 7),seq(from = 2, to = 15,by = 2)) paste0(rep("student"),seq(2,14,2))
3.将两种不同类型的数据用c()组合在一起,看输出结果
#数据类型转换的优先顺序,c( ) 只允许一种类型的数据
c(1,"a") #数值型和字符型在一起 强行将1转化为字符型 c(TRUE,"a") #逻辑值和字符型在一起,强行转换为字符型 c(1,TRUE) #逻辑型和字符型放在一起时,逻辑值转换为0(F)和1(T)
#####2.3.对两个向量进行的操作#####
x = c(1,3,5,1) y = c(3,2,5,6)
#(1)比较运算,生成等长的逻辑向量
x == y 1 FALSE FALSE TRUE FALSE y == x 1 FALSE FALSE TRUE FALSE
#(2)数学计算
x + y #等位运算 1 4 5 10 7
#(3)连接
paste(x,y,sep=",") 1 "1,3" "3,2" "5,5" "1,6"
#注意 连接#
x=c("a","a","a") y=c("b","b","b") paste(x,y) 1 "a b" "a b" "a b" paste0(x,y) 1 "ab" "ab" "ab" c(x,y) 1 "a" "a" "a" "b" "b" "b"
#paste与paste0的区别
paste(x,y) #paste( )中间有空格;paste0( )中间没有空格 1 "1 3" "3 2" "5 5" "1 6" paste0(x,y) 1 "13" "32" "55" "16" paste(x,y,sep = "") #相当于paste0( ) 1 "13" "32" "55" "16" paste(x,y,sep = ",") 1 "1,3" "3,2" "5,5" "1,6"
#当两个向量长度不一致
x = c(1,3,5,6,2) y = c(3,2,5) x == y # 啊!warning! 1 FALSE FALSE TRUE FALSE TRUE #后两个F和T是因为y的3和2 发生了循环补齐
Warning message:
In x == y : longer object length is not a multiple of shorter object length
#利用循环补齐简化代码
paste0(rep("x",3),1:3) 1 "x1" "x2" "x3" paste0("x",1:3) 1 "x1" "x2" "x3"
#(4)交集、并集、差集
intersect(x,y) #xy取交集 1 3 5 2 union(x,y) #xy取并集 1 1 3 5 6 2 setdiff(x,y) #xy取差集返回结果 在x中存在在y中不存在的元素 1 1 6 setdiff(y,x) #返回结果 在y中存在,在x中不存在的元素 numeric(0)
#x的每个元素在y中存在吗
x = c(1,3,5,1) y = c(3,2,5,6) x %in% y 1 FALSE TRUE TRUE FALSE #例如x中的1不存在于y中则输出FALSE y %in% x #y的每个元素在x中存在吗 1 TRUE FALSE TRUE FALSE
#x和y元素个数不相同
x<-c(1,3,5,1) y<-c(3,2,5,6,9) x %in% y 1 FALSE TRUE TRUE FALSE #注意出现了4个逻辑值,它不满足循环补齐的条件(1.一对一运算 2.长度不相等)其中的条件1
#满足循环补齐的函数 加减乘除、== 、paste;%in%不是 unique( ) 不是

#####2.4.向量筛选(取子集)--看ppt#####
x <- 8:12
#根据逻辑值取子集
xx==10 #[]中是想要的逻辑值 1 10 xx<12 8 9 10 11 xx %in% c(9,13) 9 #练习1 把随机数里面大于0的数都改成10086# x=rnorm(10) x 1 -0.80788011 -2.17147456 0.74719442 1.17157261 -0.1899580
6 0.07555805 -0.52079008 -0.53392890 1.55157572
-1.48103628
xx>0=10086 x 1 -0.8078801 -2.1714746 10086.0000000 10086.0000000
5 -0.1899580 10086.0000000 -0.5207901 -0.5339289
9 10086.0000000 -1.4810363
#练习2 把FALSE的值挑选出来#
x=rnorm(10) x 1 0.6204891 -0.2190496 -0.4356478 0.4491465 0.8036250 1.3489907
7 -0.7365150 1.2559808 1.2250024 -0.4733760
x>0 1 TRUE FALSE FALSE TRUE TRUE TRUE FALSE TRUE TRUE FALSE x!(x>0) #挑选出x不大于0的数 1 -0.2190496 -0.4356478 -0.7365150 -0.4733760
#练习3 去重#
x=rep(c("a","b","c","d"),each=3) x 1 "a" "a" "a" "b" "b" "b" "c" "c" "c" "d" "d" "d" duplicated(x) 1 FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUE
12 TRUE
xduplicated(x) "a" "a" "b" "b" "c" "c" "d" "d" x!duplicated(x) "a" "b" "c" "d"
#根据位置取子集
#按照位置:[]中是由x的下标组成的向量(第几个元素)
#按照逻辑值:[]中是与x等长且一一对应的逻辑值向量
x4 11 x2:4 9 10 11 xc(1,5) #不能写x1,5 第一位和第五位不连续,得按照左格式写 1 8 12 x-4 #不要第四个元素 注意:“-”给数字用 ;“!”给逻辑值用 1 8 9 10 12 x-(2:4) 8 12
####2.5.修改向量中的某个/某些元素:取子集+赋值####
x 1 8 9 10 11 12 #改一个元素 x4 <- 40 x 1 8 9 10 40 12
#改多个元素
xc(1,5) <- c(80,20) x 1 80 9 10 40 20 ###练习###
说明:运行load("gands.Rdata"),即可得到和使用我准备的向量g和s,如有报错,说明你的代码写错或project没有正确打开
4.用函数计算向量g的长度
load("~/learn /R_01(1)/gands.Rdata") length(g) 1 100
5.筛选出向量g中下标为偶数的基因名。
seq(2,100,2) gseq(2,100,2)6.向量g中有多少个元素在向量s中存在(要求用函数计算出具体个数)?将这些元素筛选出来 提示:%in% table(g %in% s) FALSE TRUE
37 63
gg %in% s7.生成10个随机数: rnorm(n=10,mean=0,sd=18),用向量取子集的方法,取出其中小于-2的值 z = rnorm(n=10,mean=0,sd=18) z 1-29.534972 19.014519 37.658389 -24.993111 -18.333294 -43.418767 77.730602 14.916551 18.325965 7.863617 zz<-2 #减号变成了赋值符号 所以取不到小于-2的值 19.01452 z 1 2 z = rnorm(n=10,mean=0,sd=18) z 10.638509 -1.533141 9.431280 -0.333989 -56.018240 -6.863237 77.216812 -20.718159 -19.116807 -20.390819 zz< -2 #<与 -2之间有空格 1-56.018240 -6.863237 -20.718159 -19.116807 -20.390819 zz<(-2) #或者加上( ) 1-56.018240 -6.863237 -20.718159 -19.116807 -20.390819
2.6 简单向量作图
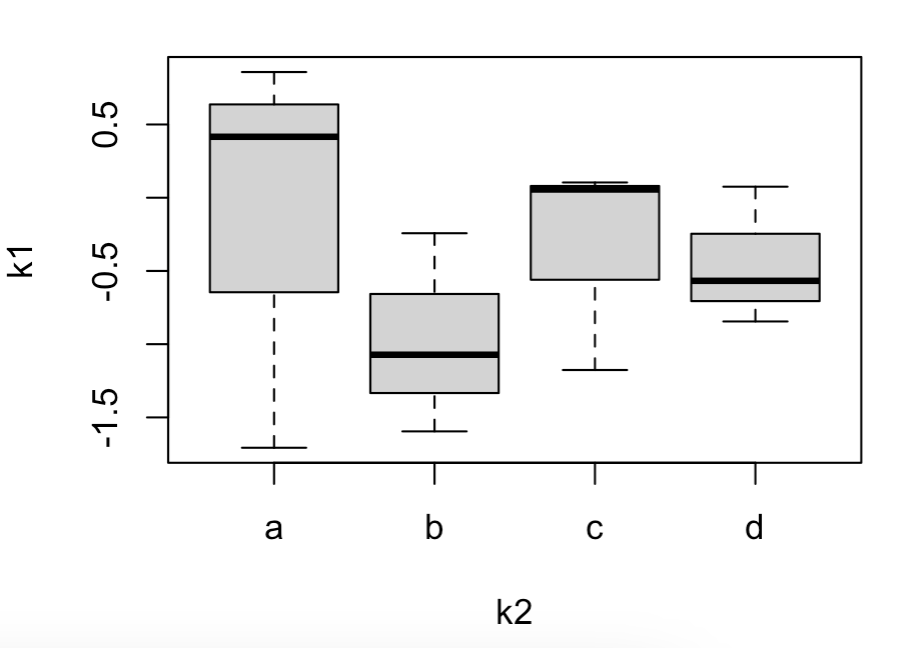
k1 = rnorm(12);k1 10.41621131 0.85797112 -1.70712163 -1.07183627 -1.59533478 6-0.24251939 -1.17634092 0.10404740 0.05605911 0.07524737
11-0.84484659 -0.56730440
k2 = rep(c("a","b","c","d"),each = 3);k2 1 "a" "a" "a" "b" "b" "b" "c" "c" "c" "d" "d" "d" plot(k1) boxplot(k1~k2) #箱线图 k1为纵坐标;k2为横坐标
----来自生信技能树----
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
作者已关闭评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号