因子评估全流程详解


00
序
首先,这是一篇值得收藏的干货文。基本上覆盖到了因子评估的每个方面每个细节,小白友好型,很长,慢慢看。
关于因子评估,很早之前写过三篇单因子测试的三篇文章:上、中、下,分别写了因子中性化、回归测试和分组测试,也可以参考这三篇。但是鉴于这篇写的过于早,现在再回过头来看,很多代码的效率非常低,有些说法非常不成熟,所以今天重新梳理一遍因子评估的全流程。
另一方面,小白入门最难的是找不到可以实操的例子,只看不练,其实也不太能学会,所以这篇也提供代码和数据,可以自己拿着练一练,相信会有很大的收获,也可以对比之前三篇的代码,找找差异,获取方式见文末。
因子评估,一般可以分为单因子的评估和多因子两部分,单因子是多因子的基础。一个新的因子要加入原有的模型,必须对这个因子做细致全面的分析,本文给出各种单因子分析的方法和理论。包括因子收益、因子稳定性、因子行业表现等等各方面。为了便于阅读和理解,每部分单独给出相应的数据和代码,以及图表结果。
01
数据说明
先对用到的数据做一个简单说明,本文以三个月动量(反转)因子为例,进行测试。因子定义为过去三个月的收益率,不做更多的处理,因子效果也不用太在意,本文的目的不在于找一个好因子,只是给出单因子评估全流程。数据总览如下
mtkcap是企业的市值,数据格式如下
price是股票的复权收盘价

ST是股票ST记录,三列分别为股票代码、被ST日期和去除ST日期

股票上市日期格式如下

沪深300成分股和中证500成分股为每个日期下的成分股列表,格式如下
沪深300价格和中证500价格为价格序列,格式如下

中信一级行业为给定日期下,股票所属的中信行业代码,行业代码的前四位表示一级行业

中信行业代码表为行业代码和行业名称的对应关系
在python中读入数据
接下来进行各种因子分析。
02
因子定义和预处理
因子定义前文已经提到,三个月的动量(反转)因子,A股没有动量,都是反转。

因子的预处理对因子的效果有非常明显的影响,一般对因子的预处理包括缺失值填补、异常值处理等。
缺失值填补,一般填0或者填横截面均值,财务数据一般向前填充。动量因子没有缺失值,不涉及填补的问题。
异常值处理包括异常样本的处理和离群值的处理,异常样本包括新股、ST、PT等。比如新股可以定义为上市未满一年的股票,踢掉每一期的新股和PT、ST等股票,本文只踢ST股,有时也会考虑ST摘帽不满一年也踢掉。离群值为一些非常大或者非常小远超出正常范围的值,异常值产生的原因千奇百怪,这里不做总结,这里对离群值处理直接做winsor,即超出5%和95%分位数的点,拉到这两个分位点 。
03
因子统计描述
因子统计描述包括因子的分布、因子自相关性、因子行业分布等。
因子分布
对因子按年划分绘制分布图(怎么划分根据需要,这里就看看),分别给出做winsor和不做winsor的结果,实现过程见函数plotFactor
不做winsor的结果
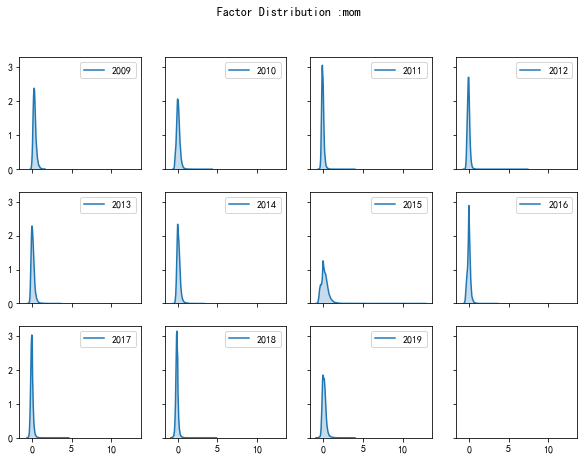
不做winsor的结果来看,因为有离群值,明显尖峰。做winsor的结果如下
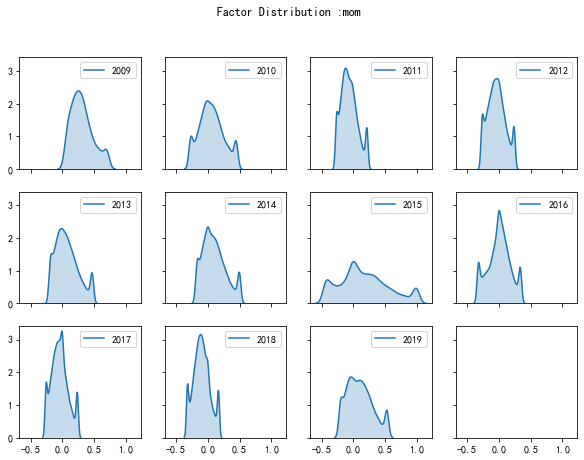
做winsor的结果来看要正常很多,有些因子有季节效应,因子的分布图上会有明显的特征。
自相关分析
计算每一期因子和上一期的相关系数,实现过程见函数getFactorADF和plotADF
这部分如果做的更细致,可以算滞后更多期的因子自相关系数,因子的自相关性主要是反映因子整体的稳定性,或者说因子的动量特征,如果因子的正自相关性很高,说明这个因子的持续性会很好,强者恒强,可以合理预期组合的换手会很低,负相关性很高则反之。当然这种方式的换手估计会很粗糙,之后会直接计算换手率。用上述两个函数计算自相关系数并作图结果如下
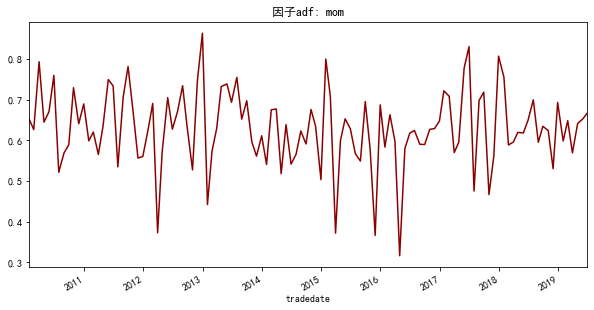
可以看出,因子的取值上,整体是呈现动量特征,即过去三个月跌的多的,下一个月三个月大概率也跌的多,这也符合常识。
因子的行业分析
因子的行业分析也非常重要,可以直观的看到哪些行业的因子暴露比较高,集中度比较高,更进一步可以预期构建的组合会倾向于哪些行业,从行业层面分析因子有效的逻辑。这部分直接算每个行业的因子暴露均值和因子暴露标准化均值,即均值除以标准差,这样可以反映整个行业因子暴露的一致性,即集中度。这部分通过函数plotIndf实现。
调用函数绘制行业均值和标准化均值的柱状图如下
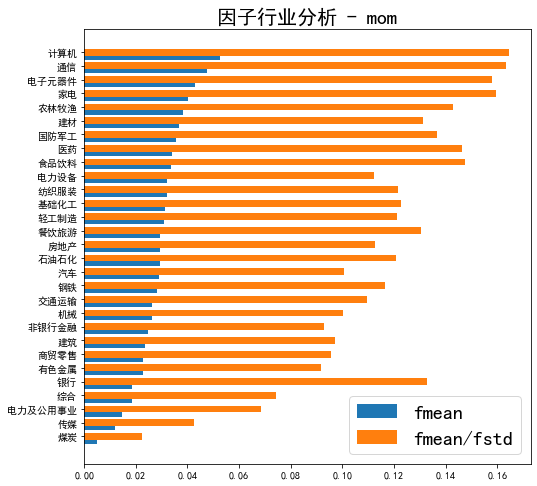
这张图包含了很多信息,蓝色为因子的行业均值,黄色线为标准化均值,结合因子的定义,平均来看,三个月平均涨幅最高的行业为计算机、通信、家电等等,同时稳定性也很高。三个月平均涨幅最低的行业包括煤炭、传媒、银行等等,并且可以看出,银行虽然平均涨幅很低,但标准化涨幅很高,说明这个行业涨幅的稳定性非常好,是非常低波动的行业。如果有一些行业研究的背景,可以对这些现象做一些更细致的分析。
上述都是因子自身的分析,当然除了行业,也可以从更多风格上分析因子的取值,比如看不同市值上的因子取值等等。接下来做一些因子和股票未来收益的分析,这部分也是大家最关注的部分,做之前首先做中性化处理。
04
因子中性化
因子中性化主要是为了剔除因子在行业和市值上的特异性,让因子在行业和市值上可比。比如从上面的分析也可以明显看出, 每个行业的因子大小和稳定性是有明显差异的,所以如果直接构建组合,结果会明显集中于部分行业。有时除了这两个之外,也会考虑更多因素,做一些风格中性化,或者说正交化。
中性化的原理为用因子值对市值和行业虚拟变量做回归,取回归的残差,因为回归残差和自变量之间是相互正交的。另外也可以证明,对行业虚拟变量回归去残差和在行业内减均值除以标准差的效果是一样的。
这部分通多函数norm和NormFactor实现
def OlsResid(y,x):
df = pd.concat([y,x],axis = 1)
# print(df)
if df.dropna().shape[0]>0:
resid = sm.OLS(y,x,missing='drop').fit().resid
return resid.reindex(df.index)
else:
return y
def norm(data,if_neutral):
data = data.copy()
"""
数据预处理,标准化
"""
# 判断有无缺失值,若有缺失值,drop,若都缺失,返回原值
datax = data.copy()
if data.shape[0] != 0:
classname = data['classname']
mkt = data['mktcap']
data = data.drop(['classname','mktcap'],axis = 1)
## 去极值
data = data.apply(lambda x:winsor(x),axis = 0)
## 中性化
if if_neutral: # 是否中性
class_var = pd.get_dummies(classname,columns=['classname'],prefix='classname',
prefix_sep="_", dummy_na=False, drop_first=True)
class_var['mktcap'] = np.log(mkt)
class_var['Intercept'] = 1
x = class_var
# 每个因子对所有自变量做回归,得到残差值
data = data.apply(func = OlsResid, args = (x,), axis = 0)
## zscore
data1 = (data - data.mean())/data.std()
# 缺失部分补进去
data1 = data1.reindex(datax.index)
else:
data1 = data
return data1
"""
调用norm中性化所有因子
"""
def NormFactors(datas,if_neutral):
# datas = factorall.copy()
fnormall = []
dates = datas.tradedate.unique()
for dateuse in dates: # dateuse = dates[0]
datause = datas.loc[datas.tradedate == dateuse]
stockname = datause[['tradedate','stockcode']]
fnorm = norm(datause.drop(['tradedate','stockcode'],axis = 1) ,if_neutral)
fnormall.append(pd.concat([stockname,fnorm],axis = 1))
print('{}中性化完成!'.format(dateuse))
fnormall = pd.concat(fnormall,axis = 0)
fnormall = fnormall.sort_values(by = ['tradedate','stockcode'])
return fnormall.reset_index(drop = True)
def winsor(x):
if x.dropna().shape[0] != 0:
x.loc[x < np.percentile(x.dropna(),5)] = np.percentile(x.dropna(),5)
x.loc[x > np.percentile(x.dropna(),95)] = np.percentile(x.dropna(),95)
else:
x = x.fillna(0)
return x这部分的结果没有图表呈现,当然也可以再去看看中性化后因子统计描述的结果,不做赘述。
05
因子IC分析
因子IC定义为因子值和股票未来一期收益率的相关系数,这里月频调仓的话也就是和未来一个月收益率的相关系数,也是很好理解的,如果相关性很高,并且时序上一直很高,即波动很小,说明因子预测能力很好,稳定性也很好,是一个比较有效的因子。
对于因子的IC值,一般比较关注的指标为因子IC的均值和ICIR,即IC均值除以IC标准差再年化。除此外,也会关注IC的衰减情况,半衰期,分层的IC,比如分行业、分市值的IC取值。有时也会关注IC的胜率,IC绝对值等等,也是为了分析因子的稳定性,本文略过。
IC和ICIR
IC和ICIR通过函数getICSeries和plotIC实现
作图结果如下
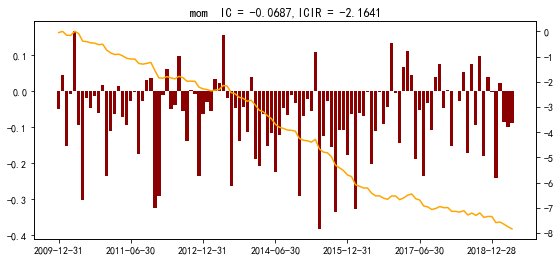
从结果来看,首先是明显的反转效应,IC = -6%,其次因子稳定性也很高,ICIR <-2,关于ICIR,可以类比T值来看。
除此外,如果要分析的更细致一些,也可以看看在各种指数成分股中的IC和ICIR,比如300、500、800、1000里,本文给出在沪深300和中证500成分股中IC、ICIR的结果如下。
300结果如下
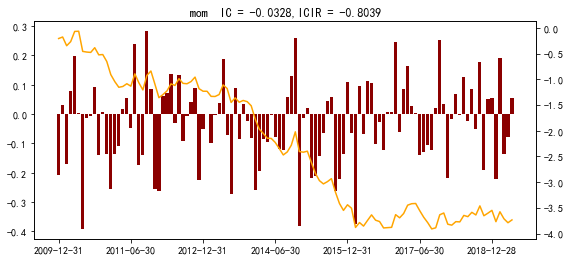
稳定性明显要差一些,但IC仍有-3%,还是有效的,但近几年太平了,效果很差。500的结果如下
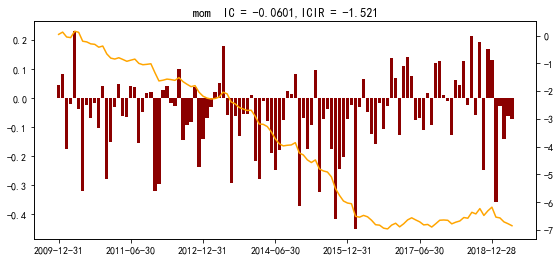
500的IC和ICIR都要更高一些,表现更好,但近几年也很平,也许是最近几年这个因子被用的太多了,谁知道呢。
IC衰减
IC看的是相关性的高低,IC衰减看的是相关性的稳定性,如果衰减很慢,那么说明这个因子很稳定,可以做的比较长期一点,如果衰减很快,比较适合做短线。
因子衰减一般看IC的半衰期,首先计算因子值和未来一期、两期、三期等等的IC值(显然是越往后相关性越低的),这里不累计,半衰期定义为IC值衰减到一半所用的时间。这部分通过函数getHalfValue、plotHalfIC和calhalfic实现。
def getHalfValue(factors,method,ret):
"""
计算因子半衰期
"""
# factors = fnormall;ret = retdata
halfic = []
for i in range(12):
ret1 = ret.pivot(index = 'tradedate',columns = 'stockcode',values = 'ret').shift(-i).stack().reset_index()
ret1 = ret1.rename(columns = {ret1.columns[-1]:'ret'})
ic = getICSeries(factors,ret1,method)
print('滞后{}期IC完成!'.format(i))
halfic.append(pd.DataFrame(ic.mean(),columns = ['lag_' + str(i)]))
halfic = pd.concat(halfic,axis = 1)
halficvalue = halfic.apply(calhalfic,axis = 1)
return halfic,halficvalue
def plotHalfIC(halfic):
halficvalue = halfic.apply(calhalfic,axis = 1)
for i in range(halfic.shape[0]): # i= 1
fig = plt.figure(figsize = (10,5))
halfic.iloc[i].plot(kind = 'bar')
halfic.iloc[i].plot(kind = 'line',color = 'darkred',linewidth = 2)
plt.title('IC衰减 :{},半衰期 = {}'.format(halfic.index[i],str(halficvalue[i]).strip('>')),fontsize = 20)
def calhalfic(x):
"""
计算因子半衰期的函数
"""
target = abs(x[0]/2)
position = np.where(x.abs() < target)
if len(position[0]) >0:
return position[0][0]
else:
return '>{}'.format(len(x))结果如下图
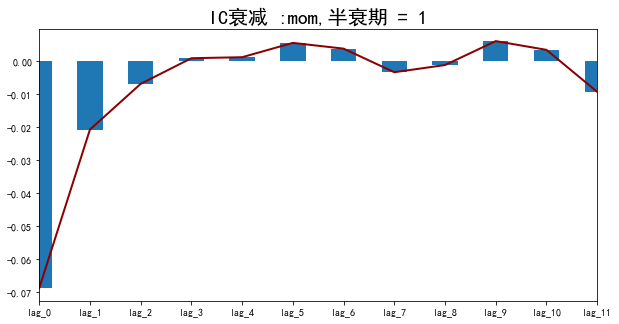
半衰期是1,衰减很快,一般量价因子都衰减很快,财务类的比较慢。
分层IC
分层IC主要是看因子在行业、市值等其他风格上的分层表现,严格意义上已经不算是单因子的分析了,算是多个因子的分析,如果要做的更细致,可以做doublesort和fama-macbeth回归,之前也写过,可以点开看看。本文只做按因子值分层和行业分组的IC。
按因子值的分层即安因子值大小等分为若干份,计算每一份的IC,不同因子取值下的IC值可能会有差异,也能看到很多信息。这部分通过函数getGroupICSeries实现
def getGroupICSeries(factors,ret,method,groups):
# method = 'spearman';factors = fnorm.copy();ret = ret
icall = pd.DataFrame()
dates = factors.tradedate.unique()
ret = ret.pivot(index = 'tradedate',columns = 'stockcode',values = 'ret')
for dateuse in dates: # dateuse = dates[0]
fic = pd.DataFrame()
fdata = factors.loc[factors.tradedate == dateuse,factors.columns[1:]].set_index('stockcode')
rt = ret.loc[dateuse]
for f in fdata.columns: # f = fdata.columns[0]
IC = getGroupIC(fdata[f],rt,method,groups)
IC.insert(0,'factor',f)
fic = pd.concat([fic,IC],axis = 0)
icall = pd.concat([icall,fic],axis = 0)
return icall
def plotGroupIC(groupIC):
"""
分组IC作图
"""
for f in groupIC.factor.unique():
fig = plt.figure(figsize = (10,5))
groupIC.loc[groupIC.factor == f,groupIC.columns[1:]].mean(axis =0).plot(kind = 'bar')
plt.title('因子分组IC均值 : ' + f,fontsize = 20)等分五份结果如下
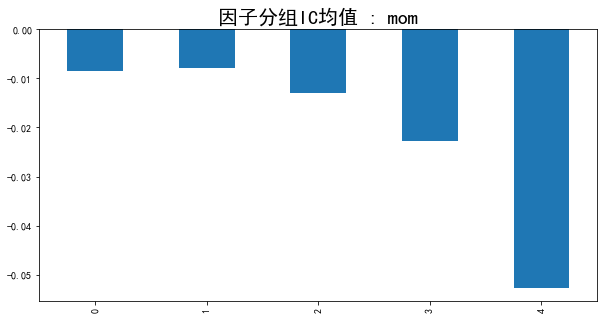
从0到1,因子值逐渐增大,可以明显看出,因子值越大,因子的IC绝对值越高,即相关性越高。仔细想想,这并不是一个好的现象,因为这是一个负向的因子,所以构建组合多头选的是取值最小的那部分股票,但这部分的IC反而是最小的,而相关性最高的这部分实际上是空头部分,A股不能做空,所以是拿不到的。很多量价因子都会有这样的现象,收益集中在空头。
接下来看分行业的IC情况,这部分的意义和前面分行业因子值差不多,可以分析这个因子在哪些行业上相关性更高,毕竟单纯的因子暴露高没有用,还要和未来收益率高才可能有效。代码和之前的差不多,不放了,需要自己取附件,计算每个行业上的IC和ICIR如下
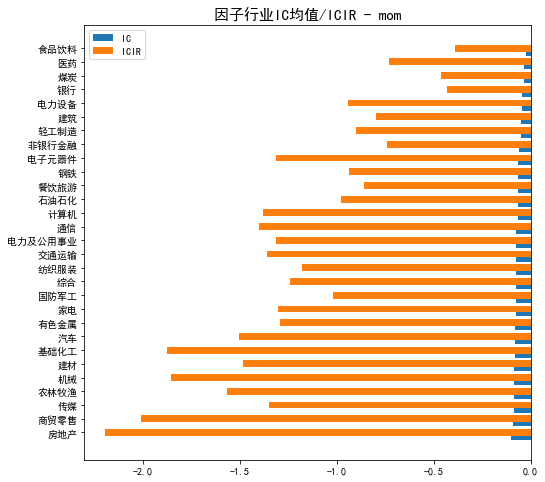
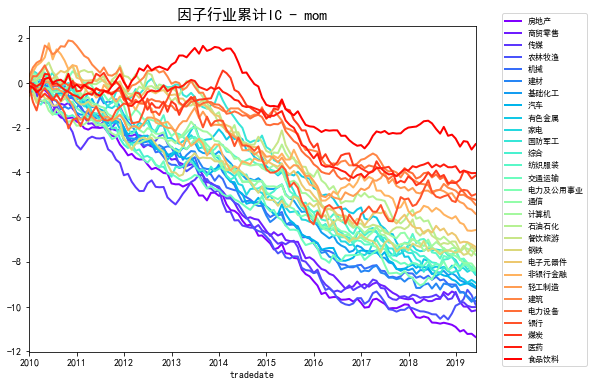
这里可以和前面因子行业取值做一个交叉分析,有的行业虽然因子值很高,但是相关性很低,有的相关性很高,但是取值不在头部,也有一些很有意思的现象,当然这里因为已经做过了中性化,实际上可以认为在每个行业上的暴露是差不多的。下面是一张每个行业的累计IC曲线,看看就好。
做完了IC,接下来算因子的收益率,对于因子收益率的计算,一般有两种算法,一种是回归法,算回归的beta,Barra最开始采用这种办法,另一种是模拟组合法,也就是常说的分层测试,一一说明。
06
因子收益率—回归法
回归法计算收益率的逻辑是,用因子未来一期的收益率和当期的因子暴露做OLS回归,取回归的beta作为因子收益率的估计值,这种方法可以一次回归一个因子,也可以一次把多个因子放在一起进行回归。本文只有一个因子进行回归。通过函数getFretSeries实现,这里两种回归方式的都写了,通过参数ftype进行控制。
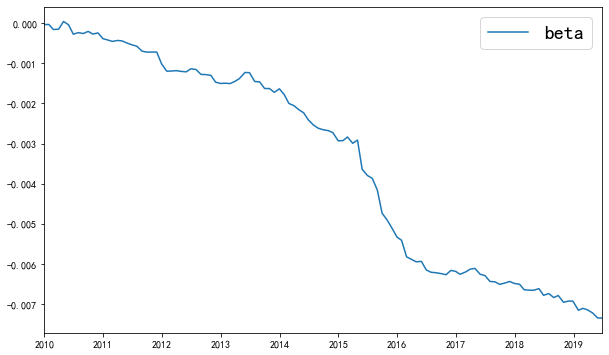
从OLS的beta表达式上,可以预期一个因子回归结果和IC的差异不会太大,这里做出因子收益率的累计曲线如下
如果你想更细,可以再做一个300、500、800里的结果出来看看。
最后要说明的一点是,回归法有一个很明显的问题,估计出来因子收益率的值的大小,没有什么实际的含义,因子的预处理方法上稍微有一点差异,最后回归出来的结果值都会差很多,接下来给出模拟组合法。
07
因子收益率-模拟组合法
模拟组合法,顾名思义,根据因子值构建投资组合,用投资组合的实际收益率,作为因子收益率的估计值。这里一般使用纯多头或者多空的收益率作为因子收益率的估计值,其实和常用的分层测试法差不多。本文首先给出分层测试+多空的结果,再给出TopN多头的结果。
分层+多空
每期按照因子的值将股票等分为5份或10份,计算每一份的投资收益,看收益曲线,好的因子应该会有区分明显、并且单调分层的曲线。多空即为最大组 - 最小组,本文因子是一个负向的因子,所以多空为最小组 - 最大组。这部分通过代码GroupTestAllFactors实现。
分层测试结果如下
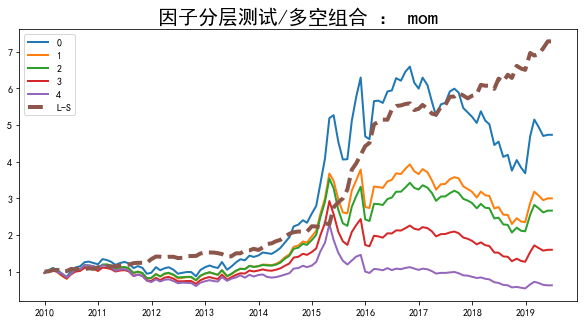
这里L-S为多头减去空头,即多空的结果,分组从0到4,因子值逐渐增大,可以看出,是明显单调的,并且0组表现最好。关于换手率,在下部分说明。
除此外,也可以在300,500,800内做分层。
TopN组合
取暴露最大(小)的前N只股票构建组合,评估组合的表现。通过函数PortfolioTopN实现。
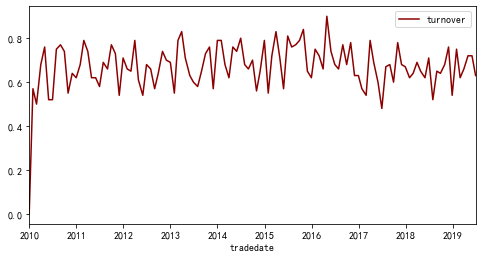
对于组合表现的评估上,本文除了给出净值曲线,也给出每个组合每期的换手率情况,换手率越高,调仓成本会越高,换手率定义好像没有统一的,这里用每期和上一期比的调出股票占上一期股票的比例定义。也有用这一期股票做分母的。换手率通过函数getturnover实现。
此外,给出分年统计的效果,如果因子不是每年都表现很好,那说明因子稳定性不是很好。分年统计通过函数performance实现。
def portfolioTopN(factors,rt,benchmark,N,if_max = True):
# rt = ret1.copy();benchmark = price300.copy();factors = fnormall.copy()
if if_max:
factors = factors.sort_values(by = factors.columns[2],ascending = 0)
stocklist = factors.groupby('tradedate').head(N).reset_index(drop = True)
else:
factors = factors.sort_values(by = factors.columns[2],ascending = 1)
stocklist = factors.groupby('tradedate').head(N).reset_index()
stockret = pd.merge(stocklist,rt,left_on = ['tradedate','stockcode'],right_on = ['tradedate','stockcode'])
stockret = stockret.sort_values(by = ['tradedate','stockcode'])
result = stockret.ret.groupby(stockret.tradedate).mean()
result = pd.DataFrame(result).shift(1).fillna(0)
result.columns = ['Portfolio']
result['Portfolio'] = (result.Portfolio+1).cumprod()
benchmark['ym'] = pd.Series(benchmark.tradedate).apply(lambda x:x.year*100 + x.month)
benchmark = benchmark.groupby('ym').last()
benchmark = benchmark.set_index('tradedate')[['price']]
benchmark = benchmark.reindex(result.index)
benchmark['nav'] = benchmark['price']/benchmark.price[0]
result['benchmark'] = benchmark.nav.values
result['RS'] = result.Portfolio/result.benchmark
plt.figure(figsize = (8,4))
plt.plot(result.Portfolio,linewidth = 2,c = 'deepskyblue',label = 'Portfolio')
plt.plot(result.benchmark,linewidth = 2,c = 'darkred',label = 'benchmark')
plt.plot(result.RS,linewidth = 2,c = 'orange',label = 'Portfolio/benchmark')
plt.legend(fontsize = 12)
return stockret.reset_index(drop = True),result
# 分年统计
def performance(stocklist,result):
# result = res_300
tunover1 = getturnover(stocklist)
result['y'] = pd.Series(result.index).apply(lambda x:x.year).values
result_y = result.groupby('y').last()/result.groupby('y').first()-1
result_y['超额收益'] = result_y.iloc[:,0] - result_y.iloc[:,1]
result_y = result_y.T
return tunover1,result_y取100只股票,在全A股中的结果如下,基准为沪深300。
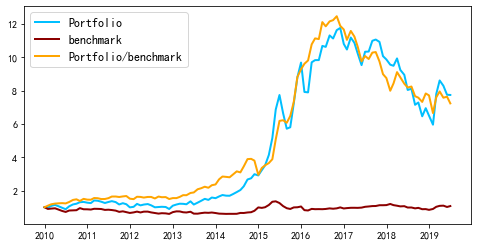
换手率如下
分年表现如下

可以看出,相比于基准,除2017、2018年外,都有正的超额收益。源码里还给出了在300、500中的结果,限于篇幅,这里不写了。
08
还可以做什么
以上,对于小白,如果都能搞清楚原理,并且实现一遍,找一个金工实习不难的。当然也可以想想,还可以做什么?对于多因子,可以做的事情很多了,这里还是只说对于单因子,除了这些,还能做些什么?
1、除了TopN组合,还可以构建行业TopN组合,强制在每个行业取等量股票,看效果。
2、改变调仓日期、调仓频率看效果,月频换周频、季度频,调仓从月末改成月初等等。
3、关于组合评估,可以计算更多的指标,比如Sharp、最大回撤、索提诺比率比率,组合收益率计算上,可以对比等权和市值加权等等
4、最重要的一点,要结合以上的结果,从逻辑上分析,为什么这个因子是有效的,收益的来源是什么?
这些基本都写过,工作量不大,有兴趣的童鞋开源再加上去。
- End -
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2020-03-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号