数据结构初步(六)- 复杂链表的分析与C语言实现

数据结构初步(六)- 复杂链表的分析与C语言实现

怠惰的未禾
发布于 2023-04-27 21:32:20
发布于 2023-04-27 21:32:20
本节继续探讨对链表的学习,介绍结构更加复杂的链表的结构以及实现!
1. 链表的分类
首先我们来看链表结构的分类,以下三类链表两两组合就有8中结构。
1.1 单向链表与双向链表
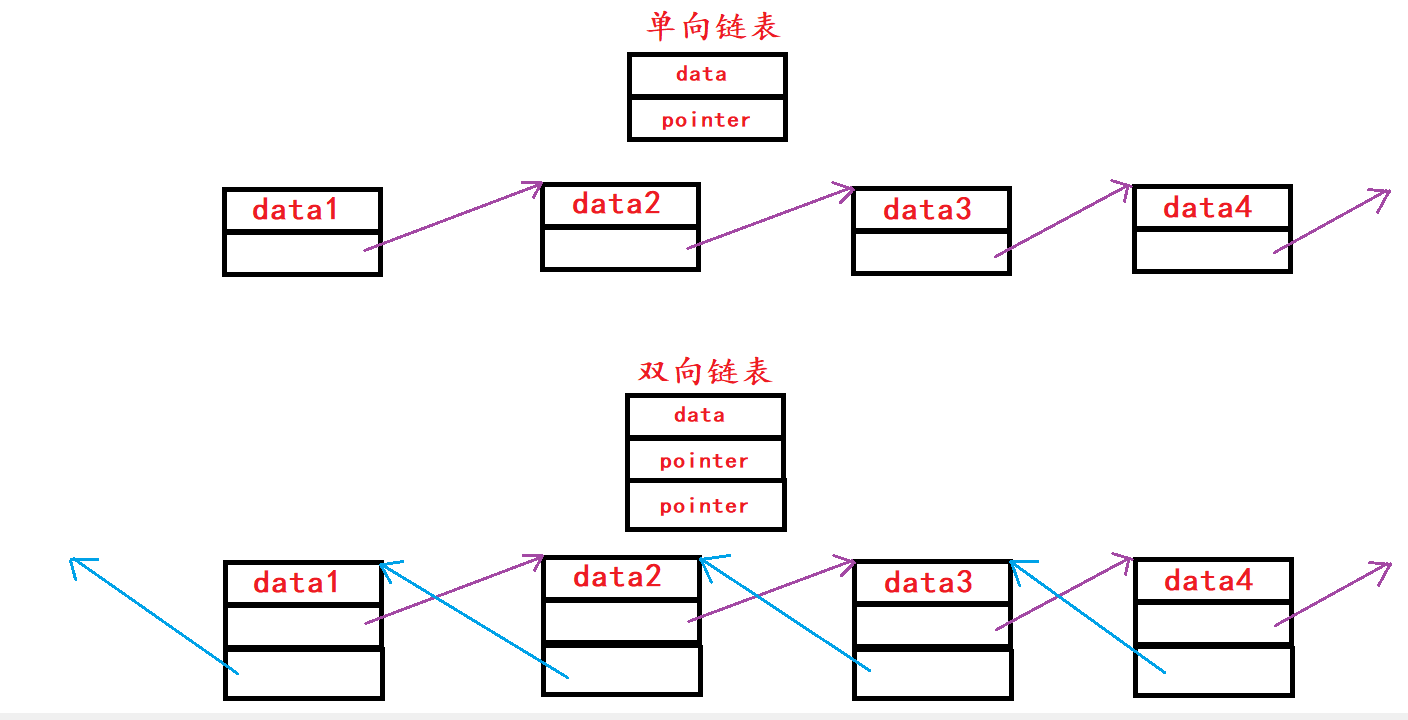
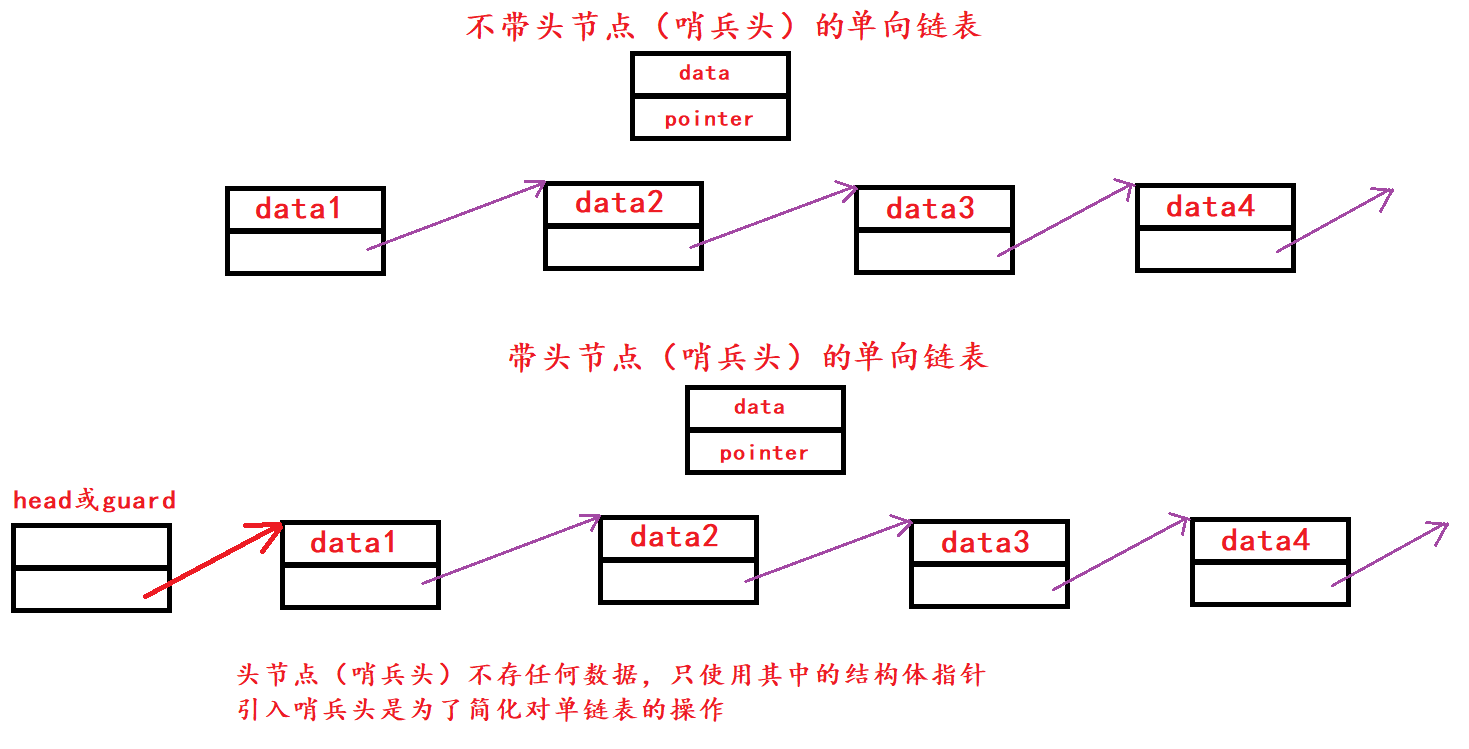
1.2 不带头节点(哨兵头)与带头结点(哨兵头)的链表
1.3 循环链表与不循环链表
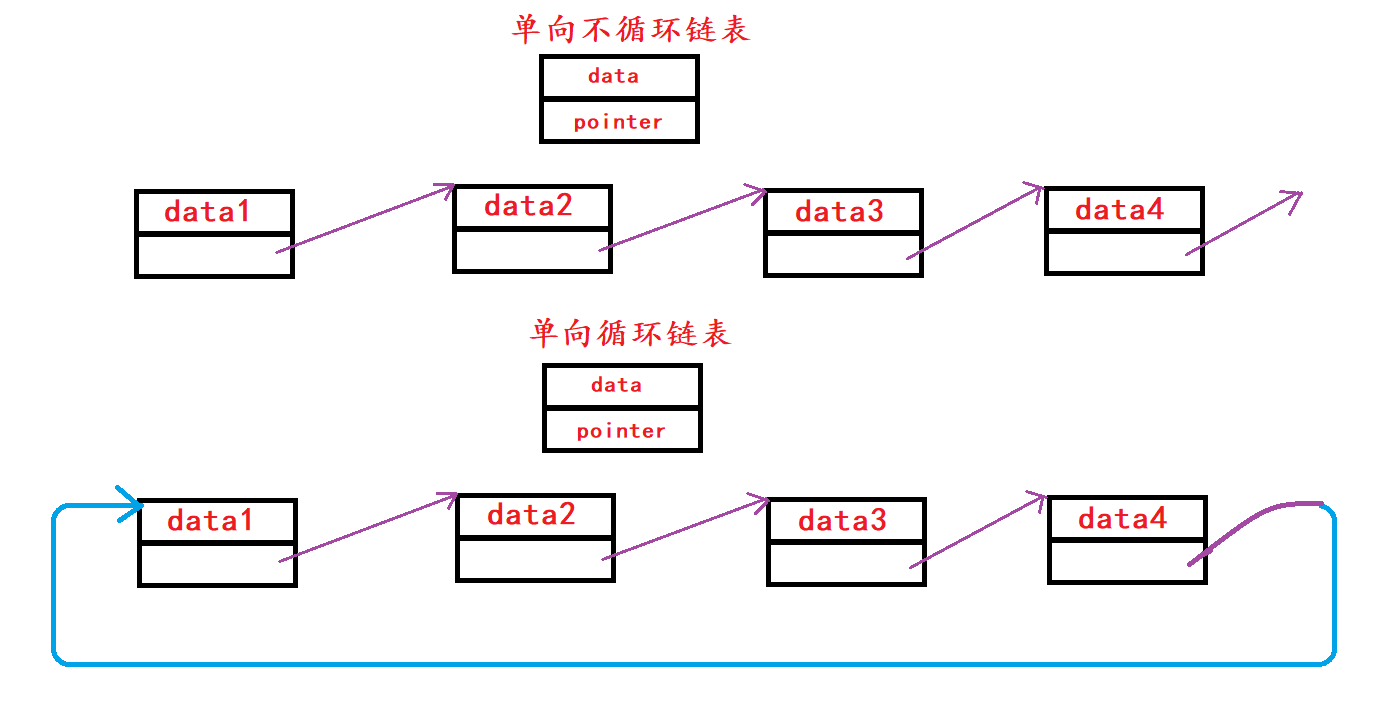
无头单向不循环链表:结构简单,一般不会单独用来储存数据。实际中更多的是作为其他数据结构的子结构,如哈希桶等; 带头双向循环链表:结构最复杂,一般用于单独储存数据。实际中使用的链表数据结构,都是带头双向循环链表。这个结构虽然复杂,但是使用代码实现时反而简单,这是优势的结构所带来的便利。
2. 带头双向循环链表的分析与实现
2.1 说明
带头双向循环链表基本结构相对于单向链表来说结构十分复杂,实际上正是因为其复杂的结构(已知条件变多)才使得头插头删尾插尾删操作的时间复杂度都是O(1),并且真正的代码层面反而更加简单。
单链表解决了动态顺序表
- 头插、头删操作时时间复杂度较高;
- 申请的空间存在浪费情况;
- 申请空间对于系统开销越来越大等问题。
没有解决动态顺序表
- 尾插、尾删操作时间复杂度较高
O(n)问题
而带头双向循环链表完美解决了动态顺序表的遇到的问题,这都得益于其有优势的结构。
2.2 带头双向循环链表结构分析
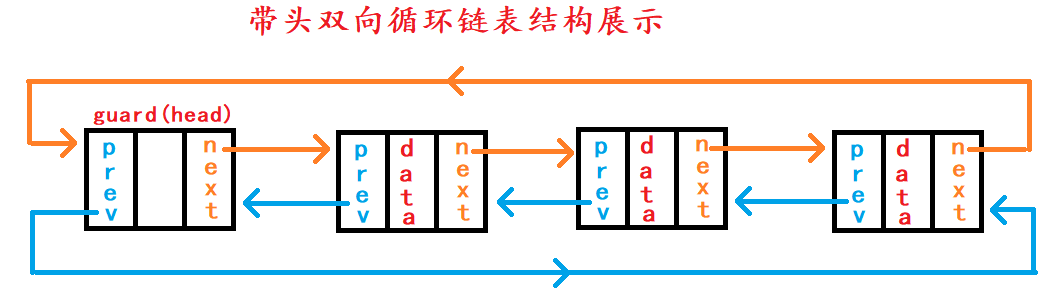
在链表开头就有一个头节点哨兵头,所以链表一定不会为空至少有一个头节点,只不过这个头节点并不存放任何数据;
双向指对于每一个节点结构体来说,都有一个数据成员变量,一个节点指针next指向下一个节点,一个节点指针prev指向上一个节点;
循环是指链表的尾节点指针成员next指向了链表头结点head或哨兵头guard,而链表头节点哨兵头指针成员prev指向了尾节点
2.3 功能分析
1. 防止头文件被重复包含
方法1: 条件编译指令
#ifndef __SeqList__
#define __SeqList__
//....
#endif方法2:在头文件最开始的位置加上一行代码
#pragma once2. 头文件的包含
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>3. 定义节点结构体类型
一个节点包括储存数据的变量、指向下一个节点的指针、指向上一个节点的指针。
typedef int DLTDataType;
typedef struct DListNode {
DLTDataType data;
struct DListNode* next;
struct DListNdoe* prev;
}DLTNode;重定义一个通用数据类型的名字,这样以后需要按修改案数据类型时只需要在开头修改一次。 把结构体类型名重定义一个较短且有含义的新名字,这样敲打方便。
4. 初始化链表
由于链表有头结点哨兵头,链表只要存在就有一个哨兵头,所以我们需要对链表进行初始化:创建一个哨兵头并使哨兵头两个指针成员next和prev都指向自己(哨兵头),以此达成在没有有效数据(节点)时链表也是一个闭环。

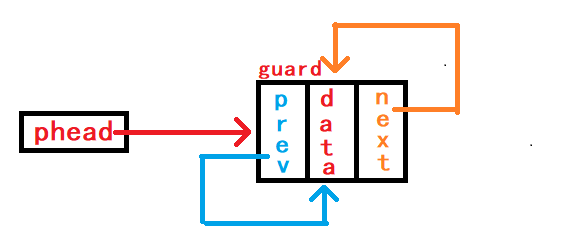
初始化就需要修改外部的头指针
phead, 方法一: 传头指针本身,然后函数返回新的头指针,使用一级结构体指针;
DLTNode* DListInit() {
DLTNode* guard = (DLTNode*)malloc(sizeof(DLTNode));
//malloc()申请空间失败
if (!newnode) {
if (!guard) {
perror("DListInit");
exit(-1);
}
guard->next = guard;
guard->prev = guard;
return guard;
}方法二: 传外部头指针的地址在函数内部修改头指针,使用二级结构体指针
void DListInit(DLTNode** pphead) {
assert(pphead);
DLTNode* guard = (DLTNode*)malloc(sizeof(DLTNode));
if (!guard) {
perror("DListInit");
exit(-1);
}
*pphead = guard;
guard->next = guard;
guard->prev = guard;
}传头指针的地址时,头指针的地址一定不为空
NULL,所以需要对其进行断言判断。
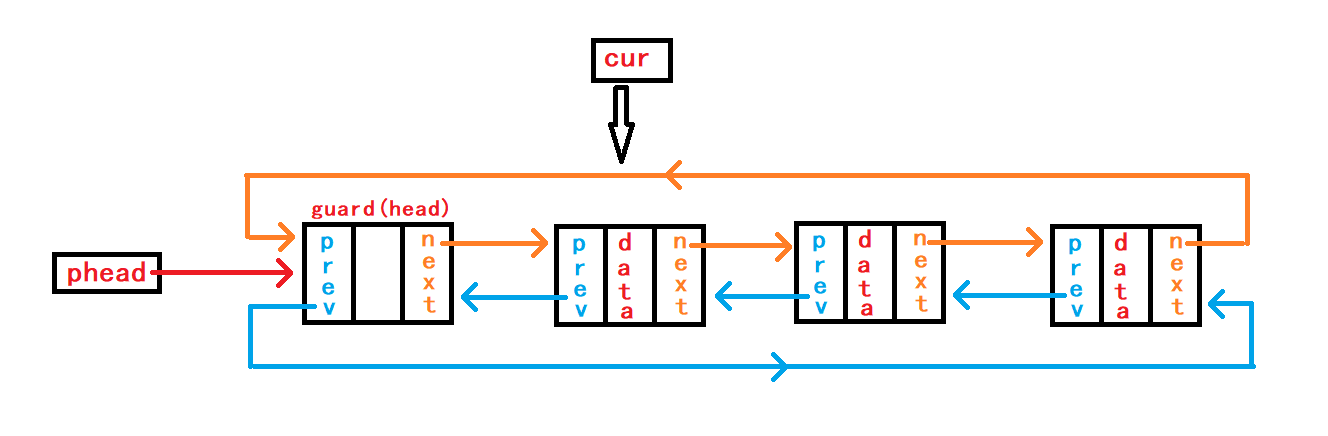
5. 遍历链表并输出节点储存的数据
//遍历链表,输出数据
void DListPrint(DLTNode* phead) {
assert(phead);
DLTNode* cur = phead->next;
while (cur != phead) {
printf("%d<==>", cur->data);
cur = cur->next;
}
printf("\n");
}注意点:
- 由于头节点
哨兵头的存在,除了初始化链表接口函数,其他不涉及头节点本身改变的情况的函数都可以不使用二级指针作为参数。 - 与不带头的链表相比,带哨兵头的链表由于不存放数据,虽然我们传参传的是哨兵头的地址,但是遍历链表实际是从哨兵头的下一个节点开始的。
- 与头尾不相连的链表相比
尾节点指向空,头尾相连的链表的遍历结束条件也有所不同:从头节点的下一个节点开始遍历到头节点结束。
6. 申请一个新节点并赋值和初始化
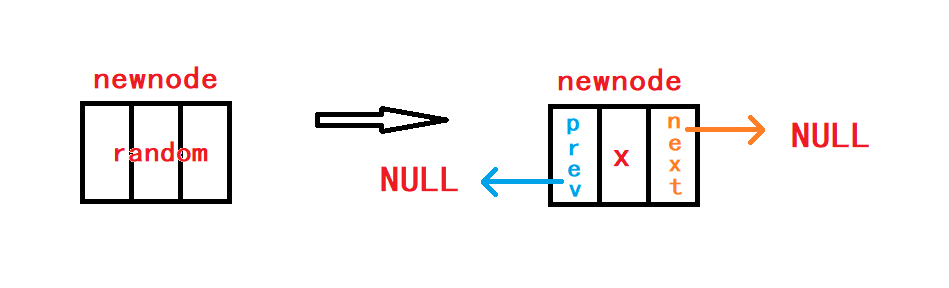
本函数是为了与头插数据、尾插数据、某个节点前插数据提供便利,需要新增节点时直接调用本函数,将返回新节点的地址。
//申请一个新节点
DLTNode* BuyDLTNode(DLTDataType x) {
DLTNode* newnode = (DLTNode*)malloc(sizeof(DLTNode));
//malloc()申请空间失败
if (!newnode) {
perror("BuyDLTNode");
exit(-1);
}
newnode->data = x;
newnode->next = newnode->prev = NULL;
return newnode;
}注意
malloc()函数可能申请空间失败,需要判断一下。
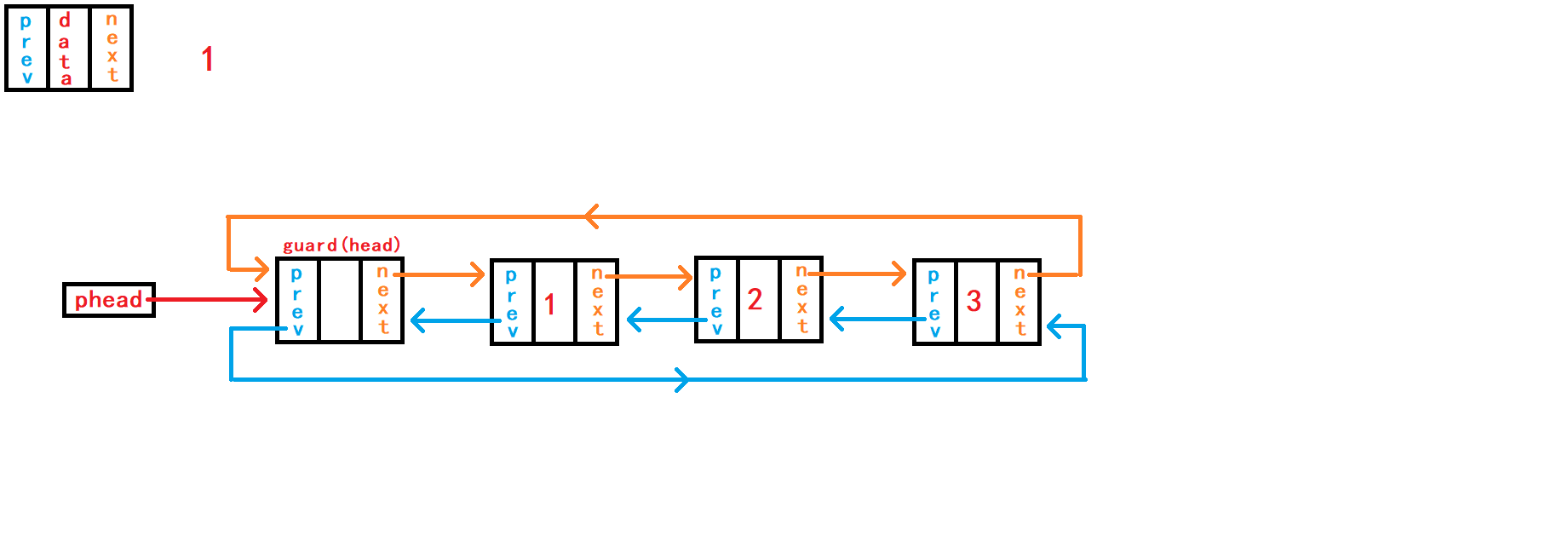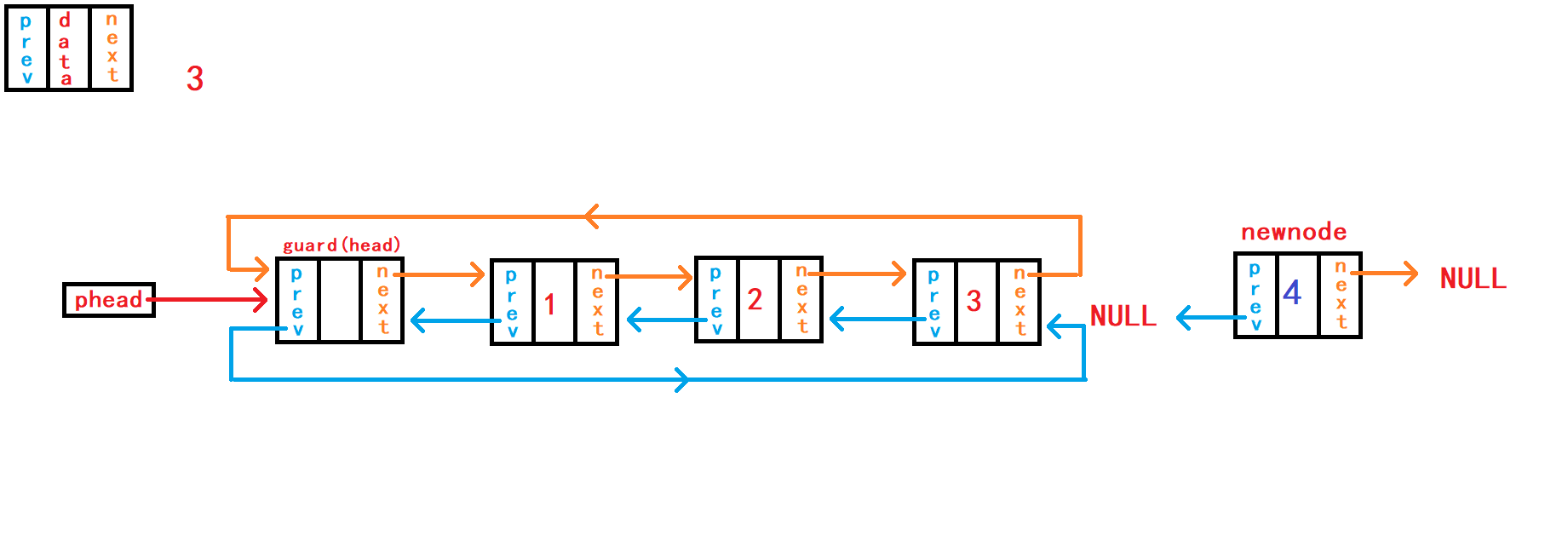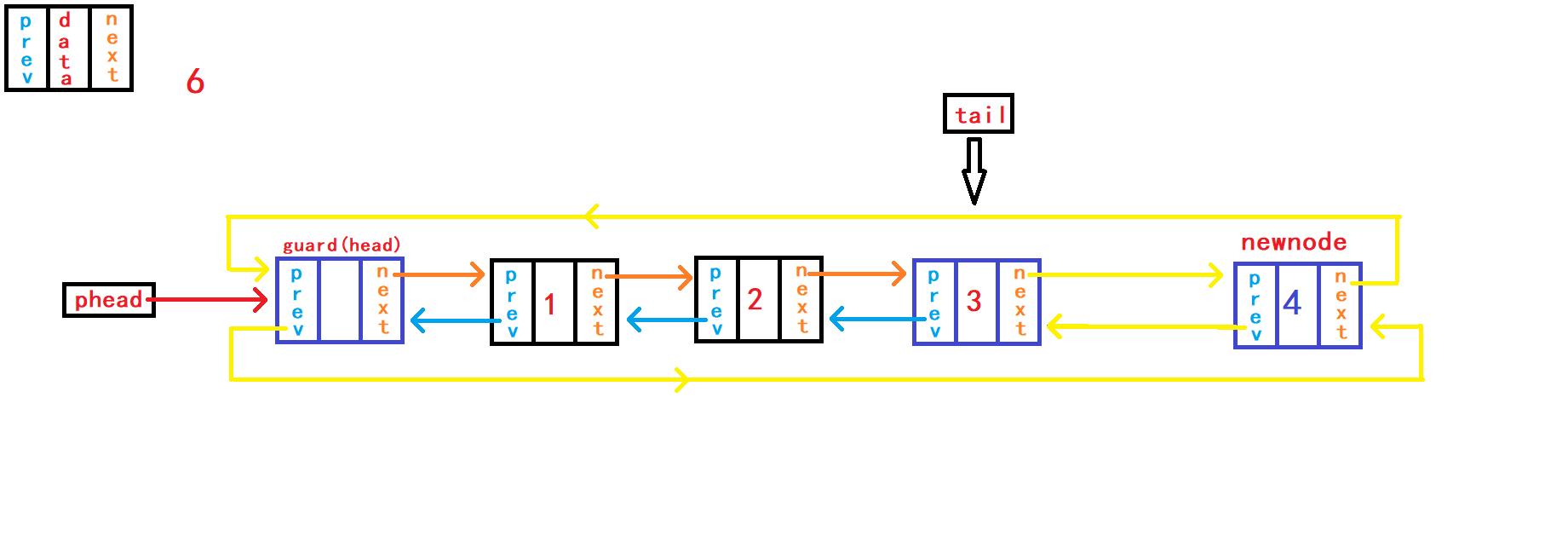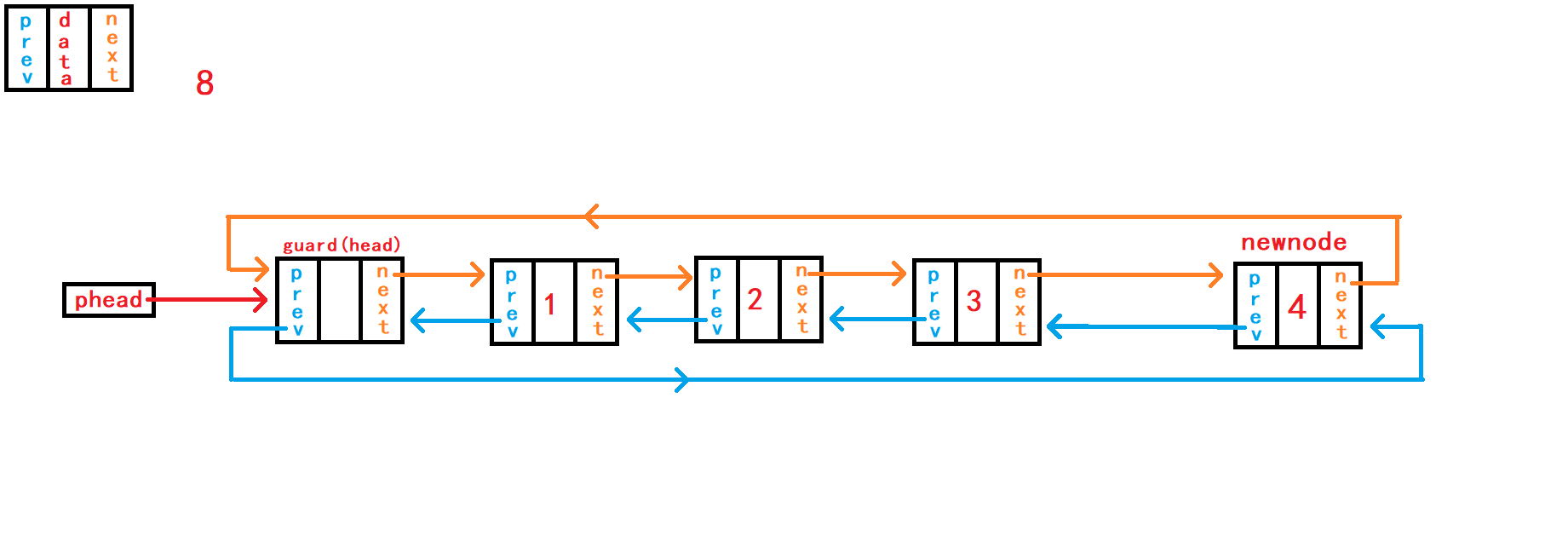
7. 尾插数据
void DListPushBack(DLTNode* phead, DLTDataType x) {
assert(phead);
DLTNode* newnode = BuyDLTNode(x);
DLTNode* tail = phead->prev;
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
phead->prev = newnode;
}尾插数据,需要先找到尾节点
tail:借助头指针副本``phead通过头节点哨兵头内部指针找到尾节点。 再断开哨兵头与尾节点的链接,使新节点newnode与尾节点tail进行链接,再与头结点哨兵头进行链接。
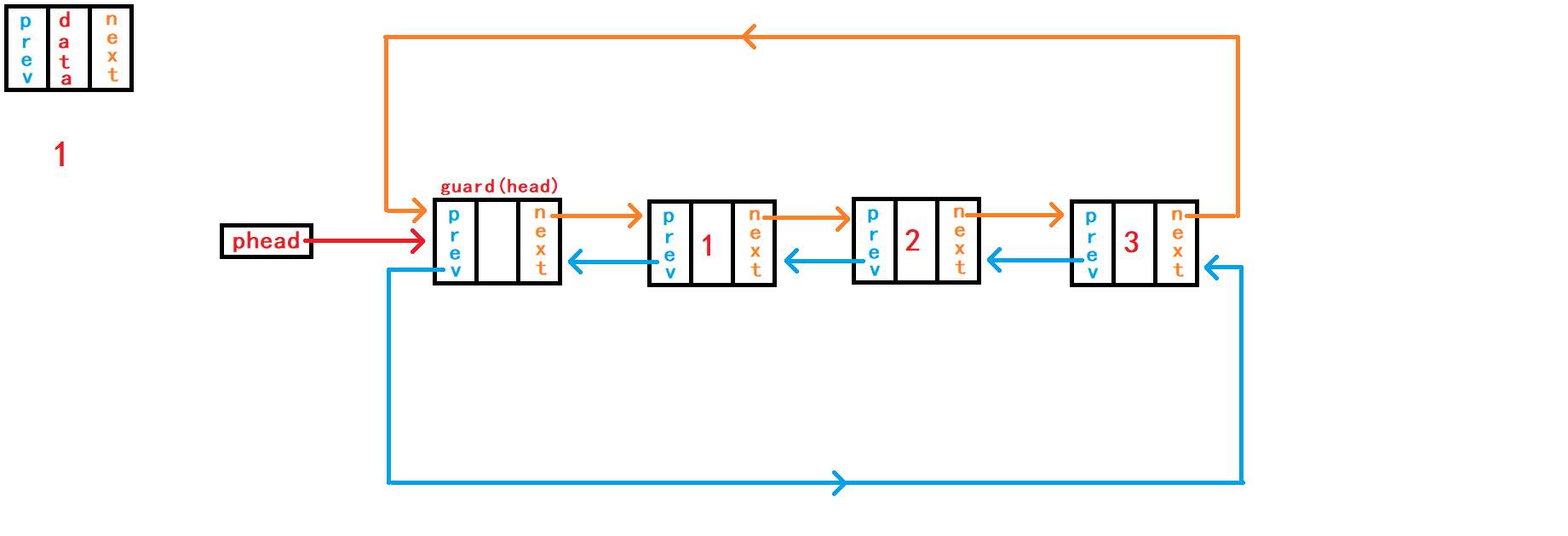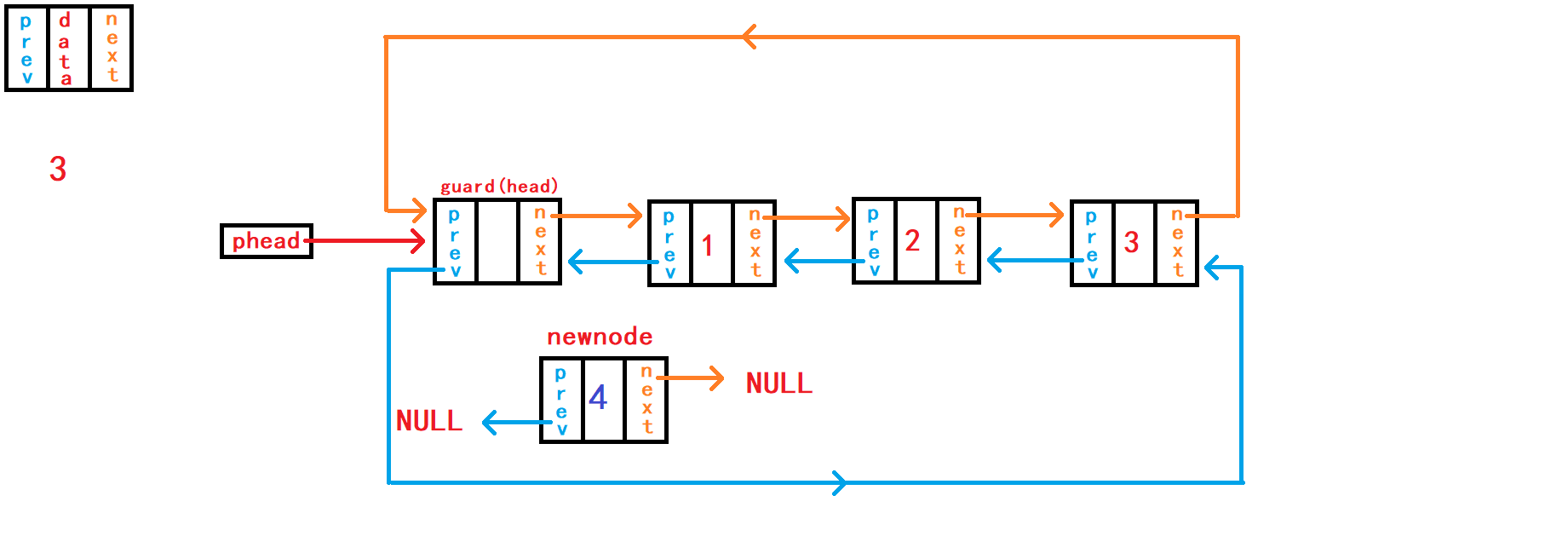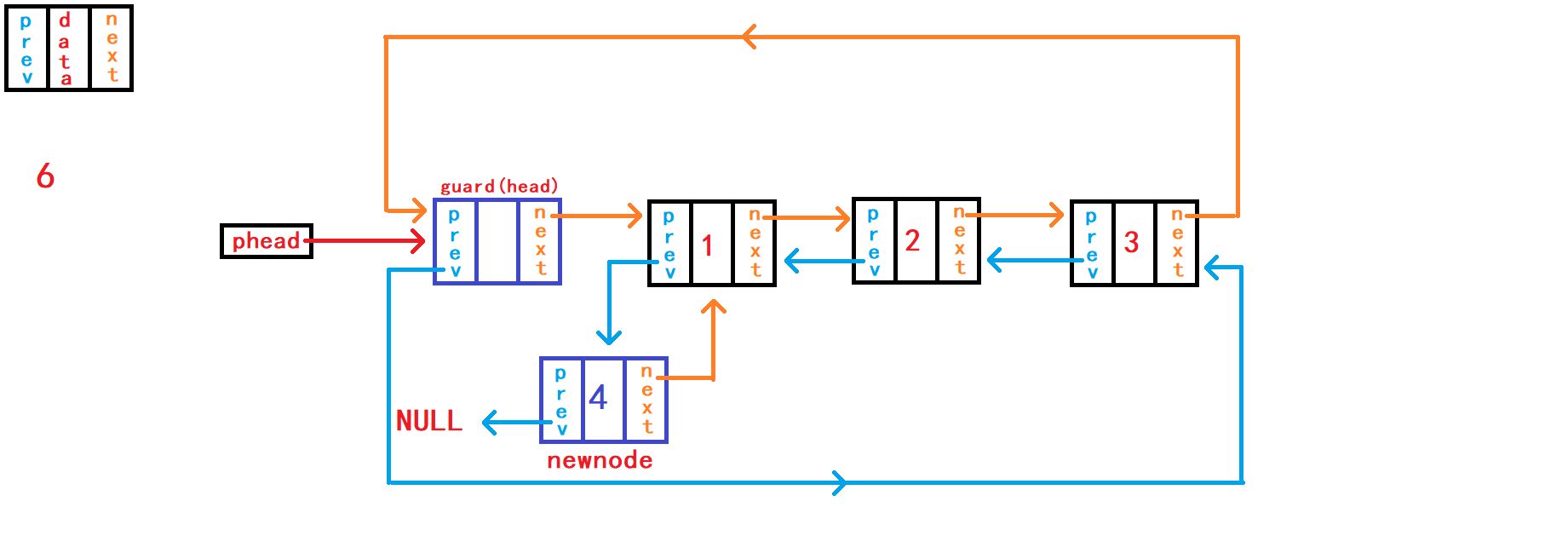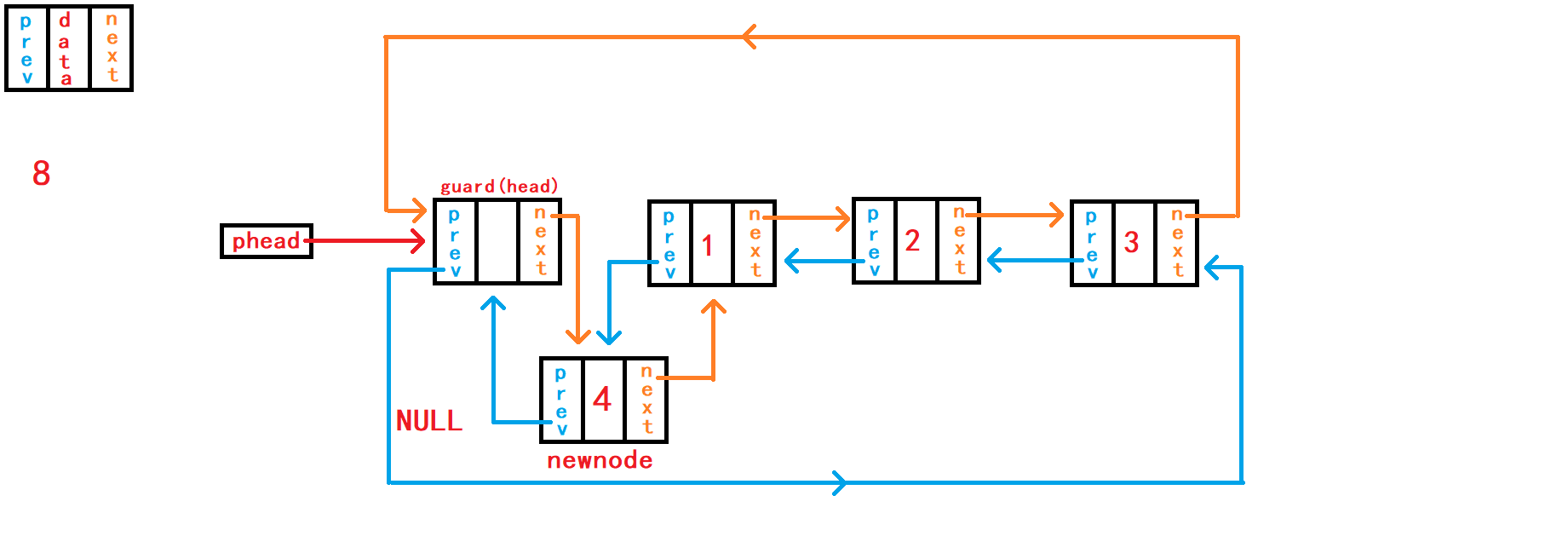
8. 头插数据
头插数据,需要注意的并不是在头节点哨兵头之前插入数据,而是应该在头节点哨兵头的下一个节点之前插入数据,因为头节点的下一个节点才是链表第一个真正储存数据的节点。
这样需要断开头节点与头节点下一个节点的链接,再使头节点与新节点链接,新节点与头节点下一个节点链接。 在链接操作中有两种思路: 思路1: 不借助额外指针变量来储存头节点下一个节点的地址,需要慎重、仔细考虑新节点分别与头结点和头结点下一个节点之间的链接顺序。 新节点先与头节点下一个节点链接,再与头节点链接。 如果新节点先与头节点链接,又没有额外指针变量记录
头节点下一个节点的地址,这样头节点下一个节点的地址就无法找到了,也就无法使新节点newnode与其链接了。
void DListPushFront(DLTNode* phead, DLTDataType x) {
assert(phead);
DLTNode* newnode = BuyDLTNode(x);
//方法1
newnode->next = phead->next;
phead->next->prev = newnode;
phead->next = newnode;
newnode->prev = phead;
方法二
//DLTNode* first = phead->next;
//phead->next = newnode;
//newnode->prev = phead;
//
//newnode->next = first;
//first->prev = newnode;
}思路2: 借助额外结构体指针变量
first记录头结点的下一个节点的地址。 这样就不需要考虑新节点与头节点、新节点与头结点下一个节点链接的顺序。 随便你怎样的链接顺序。
void DListPushFront(DLTNode* phead, DLTDataType x) {
assert(phead);
DLTNode* newnode = BuyDLTNode(x);
//方法二
DLTNode* first = phead->next;
phead->next = newnode;
newnode->prev = phead;
newnode->next = first;
first->prev = newnode;
}
9. 判断链表是否为空
若本链表只有一个头结点
哨兵头时对应链表为空,此时头节点哨兵头两个指针成员都指向了自己(头节点);否则头节点的两个指针成员都不会指向自己(头节点)。 故判断头节点的两个指针之一的指向是否等于指向头节点的指针即可。
bool DListEmpty(DLTNode* phead) {
assert(phead);
return phead->next == phead;
//return phead->prev == phead;
}链表为空就返回
true,不为空就返回false返回类型时bool类型,当然也可以用int整型。 注意传入的头指针副本的值一定不为NULL。
链表为空:
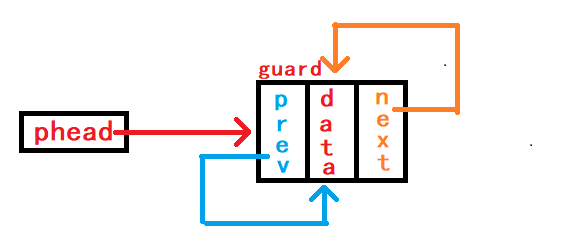
链表不为空:
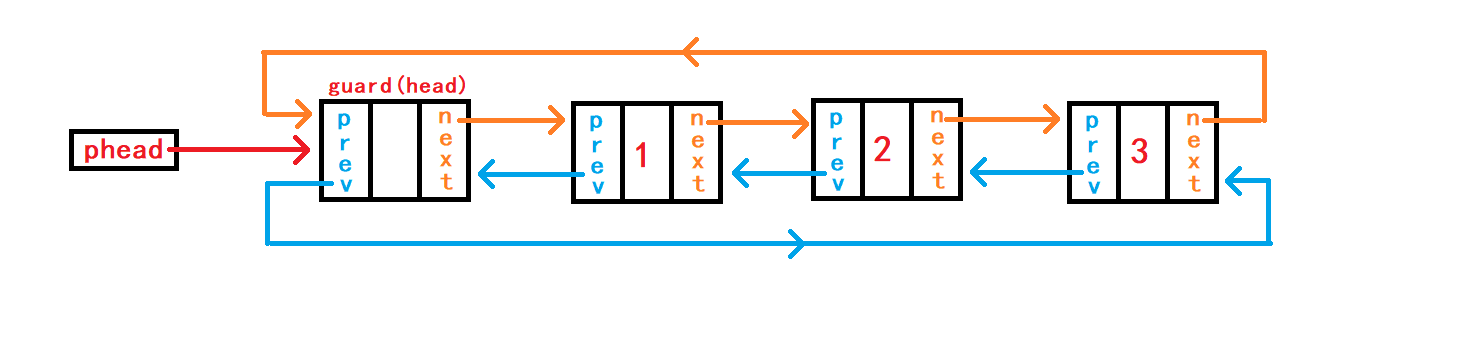
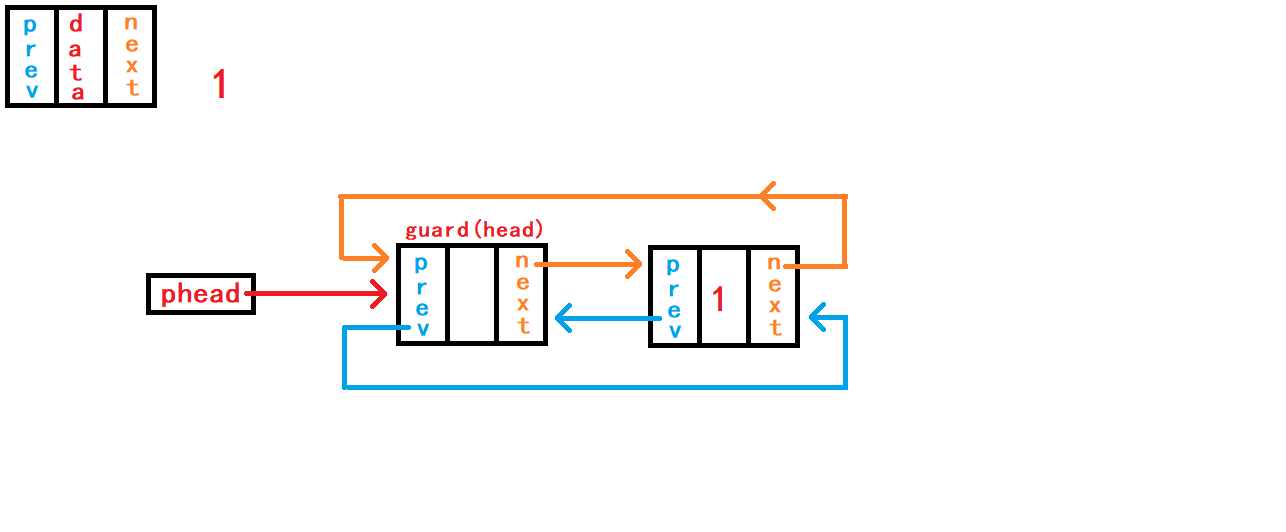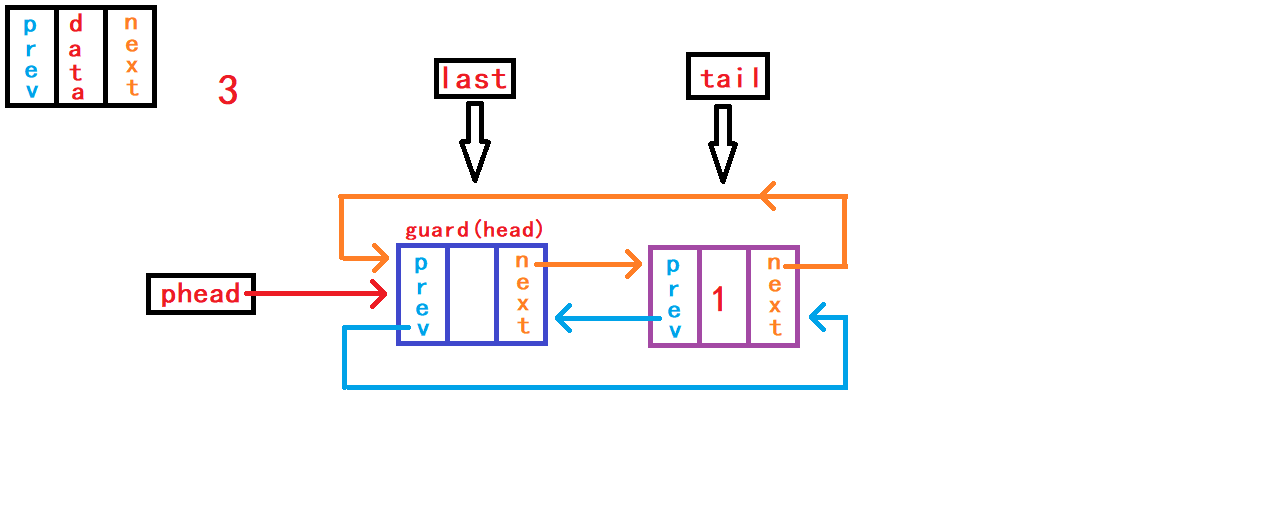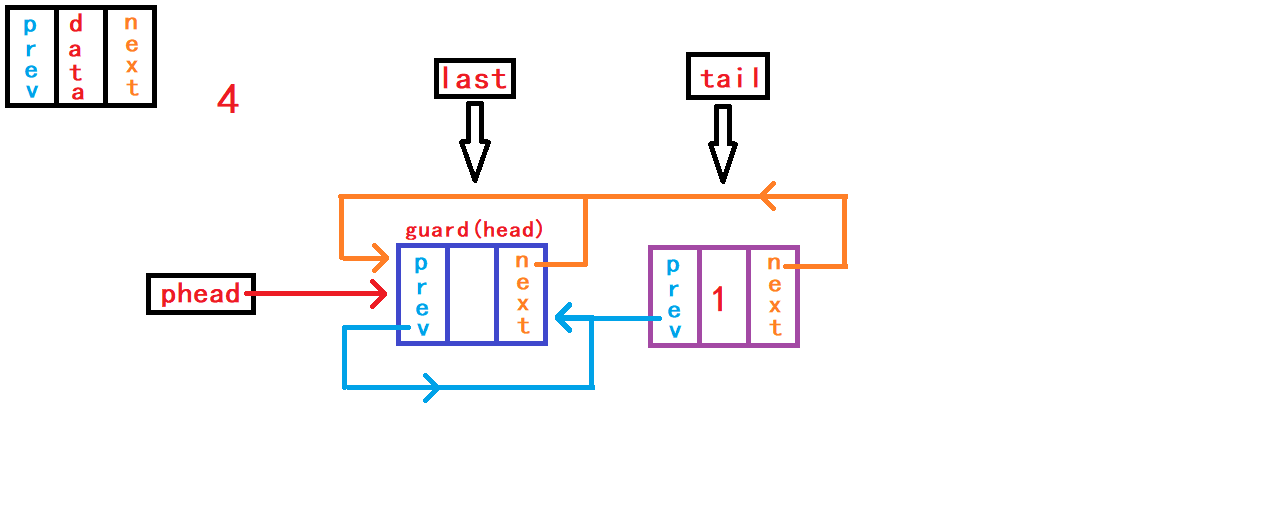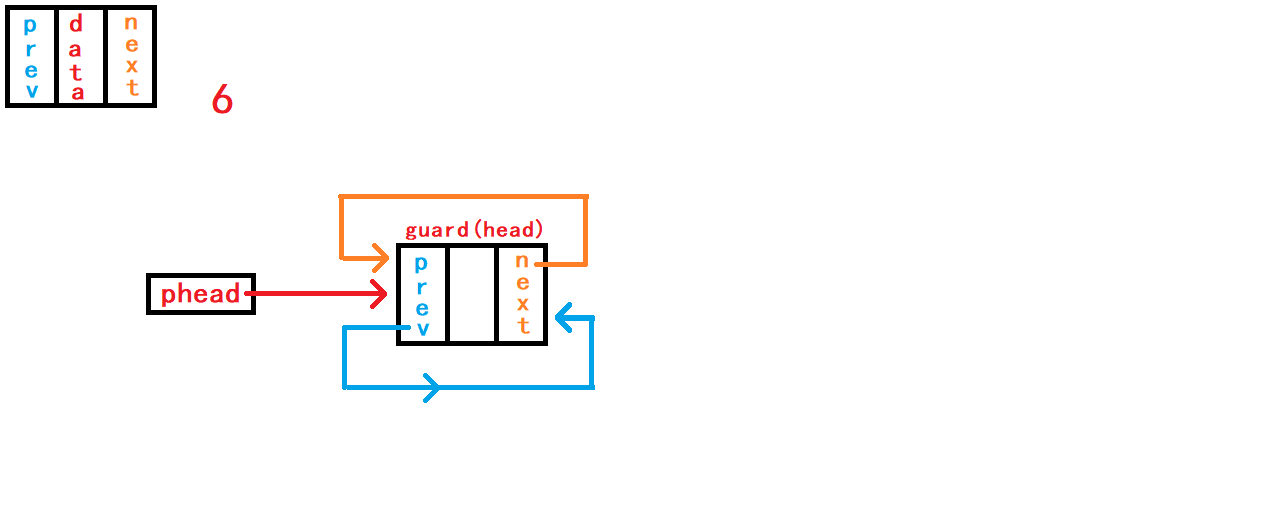
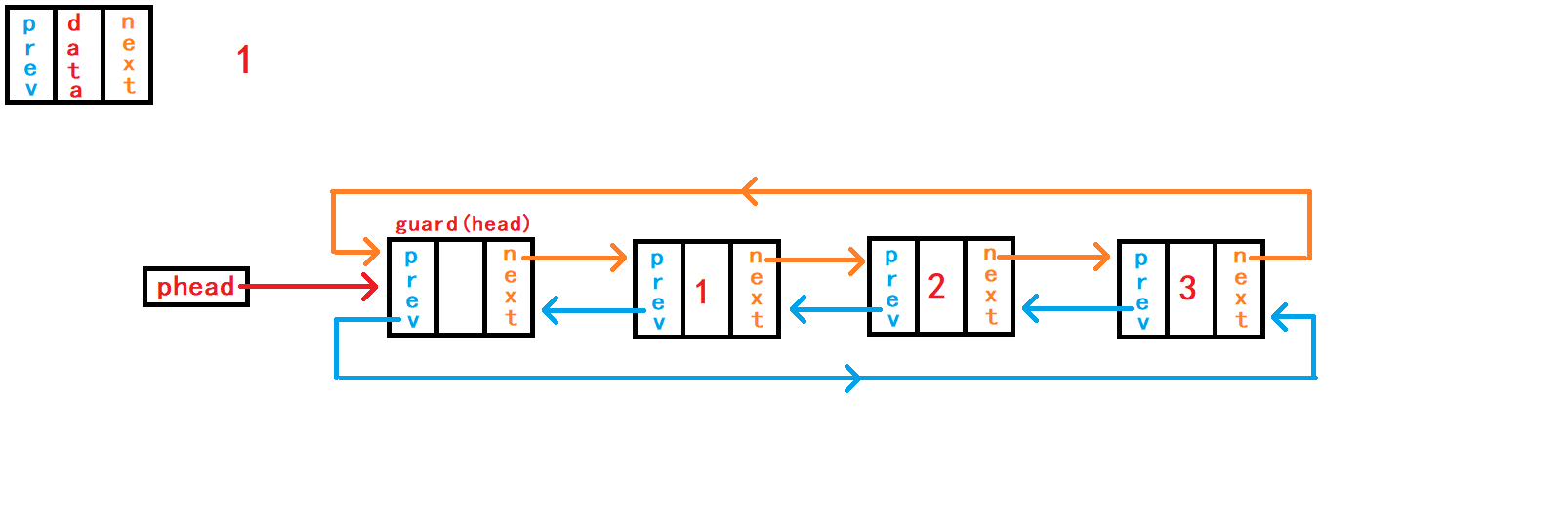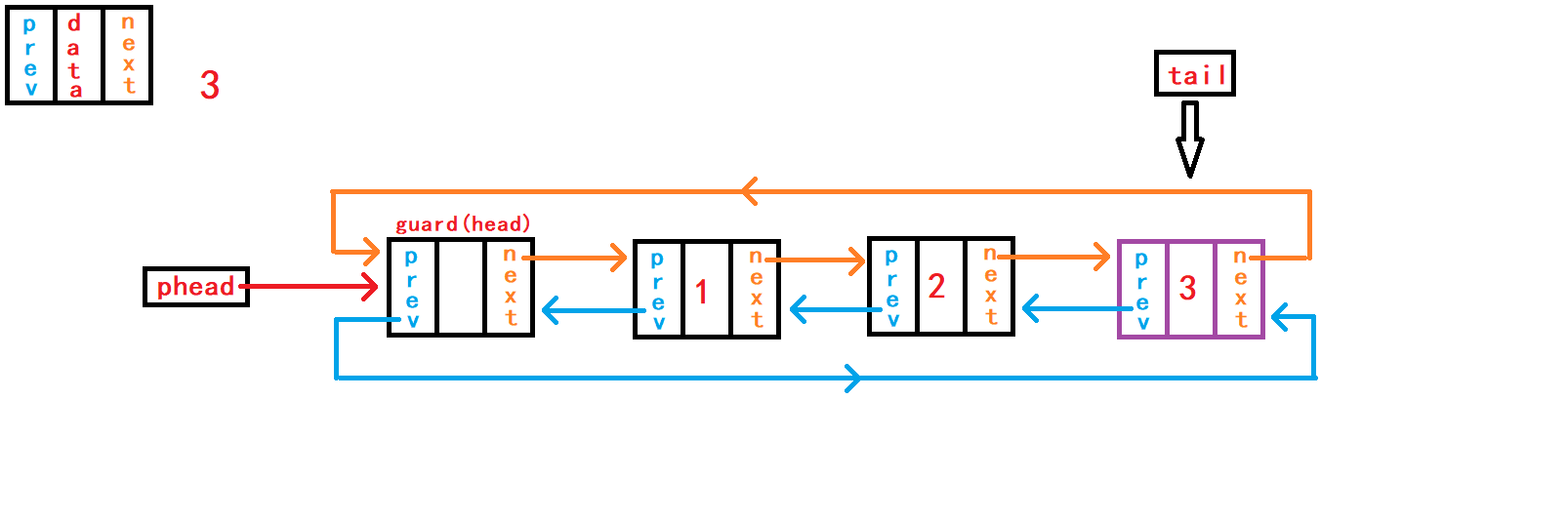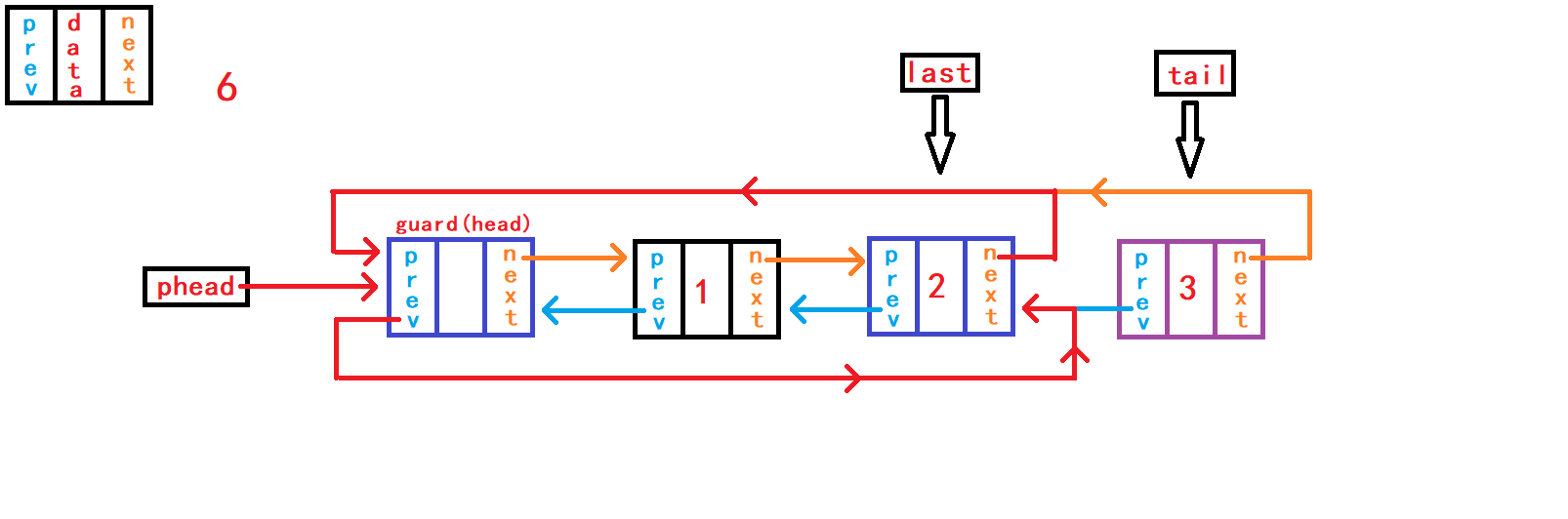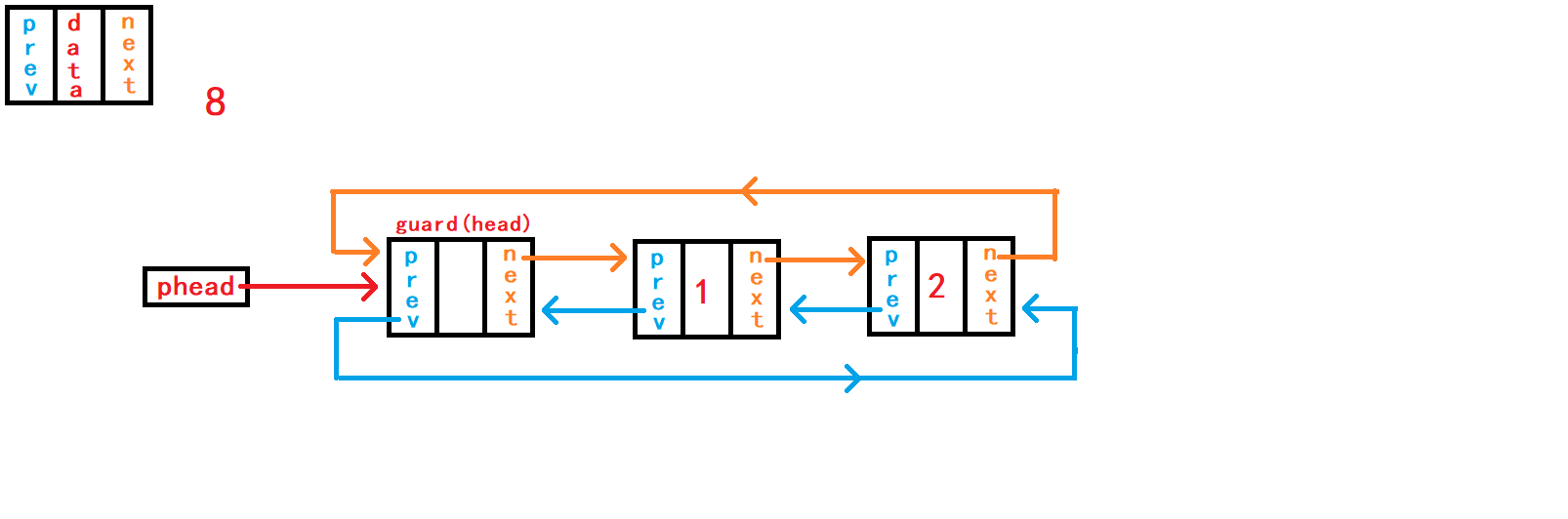
10. 尾删数据
void DListPopBack(DLTNode* phead) {
assert(phead);
assert(!DListEmpty(phead));
DLTNode* tail = phead->prev;
DLTNode* last = tail->prev;
last->next = phead;
phead->prev = last;
free(tail);
//tail = NULL;
}尾删数据,首先判断链表是否为空; 然后需要先找到尾节点
tail和尾节点的上一个节点last。 可以通过头节点内部指针成员prev直接找到尾节点结构体指针tail指向;再通过tail尾节点内部指针成员prev直接找到尾节点的上一个节点结构体指针last指向。 断开尾节点tail与头结点、last节点的链接,建立last节点与头结点的链接; 最后手动释放free()尾节点tail指向的空间。
11. 头删数据
void DListPopFront(DLTNode* phead) {
assert(phead);
assert(!DListEmpty(phead));
DLTNode* first = phead->next;
DLTNode* second = first->next;
phead->next = second;
second->prev = phead;
free(first);
//first = NULL;
}已知本链表至少有一个头节点
哨兵头,所以传入的头指针副本phead一定不为空NULL; 头删数据,链表至少有一个储存有效数据的节点,所以需要先判断链表是否为空NULL; 需要注意的是:删除的不是头节点哨兵头,而是头节点的下一个节点。 通过头指针phead找到头节点,然后通过头节点内部指针成员next找到头节点的下一个节点借助结构体指针first指向;再通过first节点内部指针成员next找到first的下一个节点借助结构体指针second记录。 删除first节点,即断开first节点与头节点、second节点的链接,然后使头节点与second节点相链接。
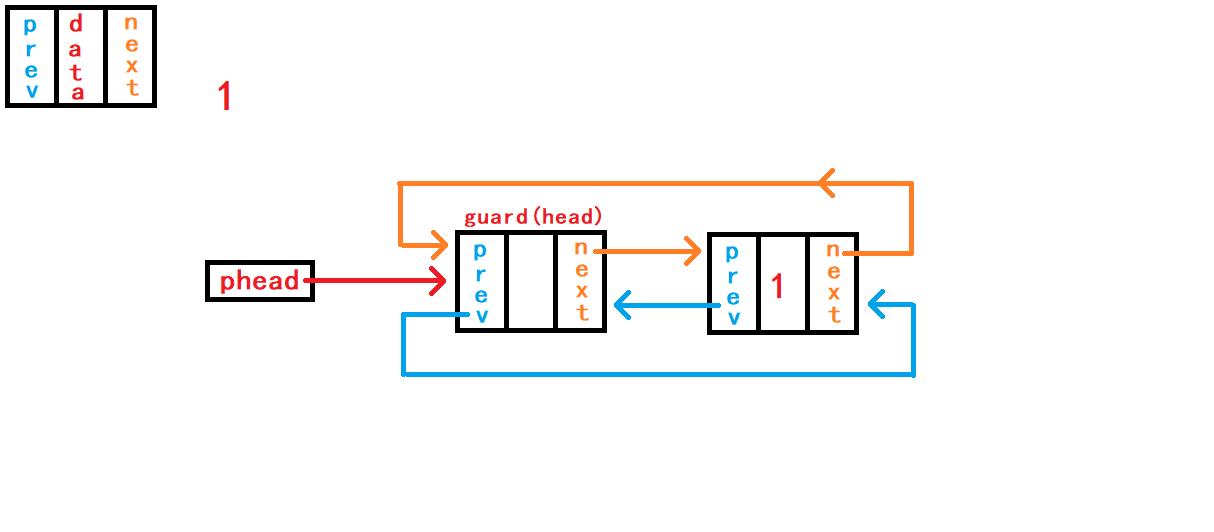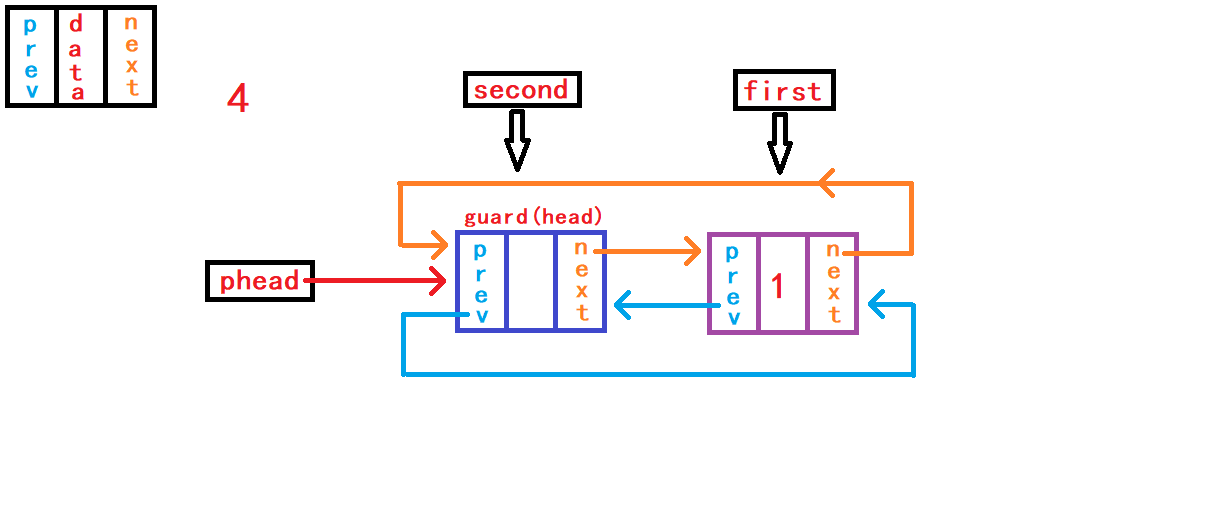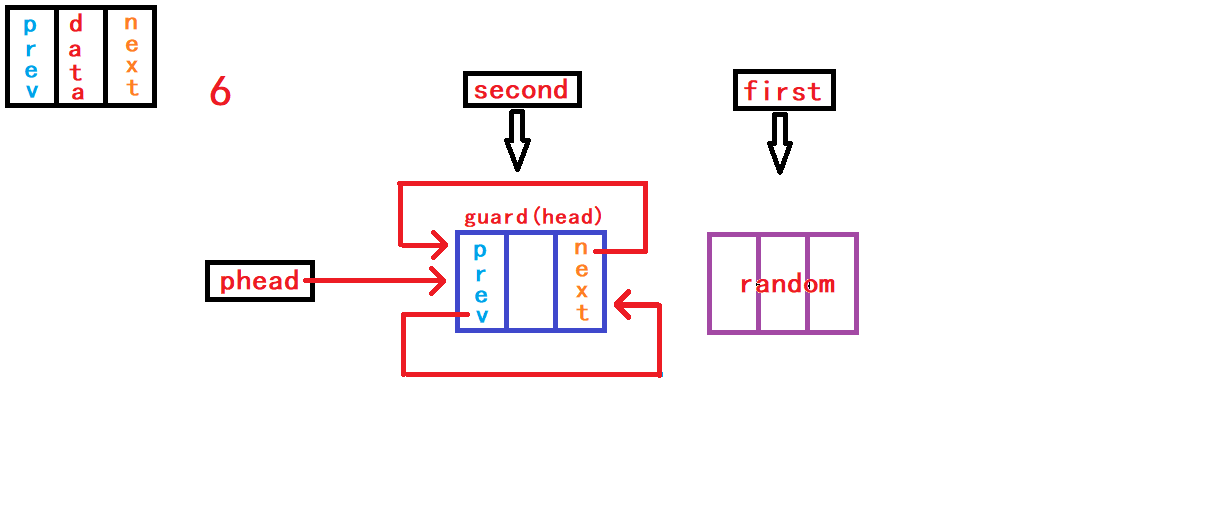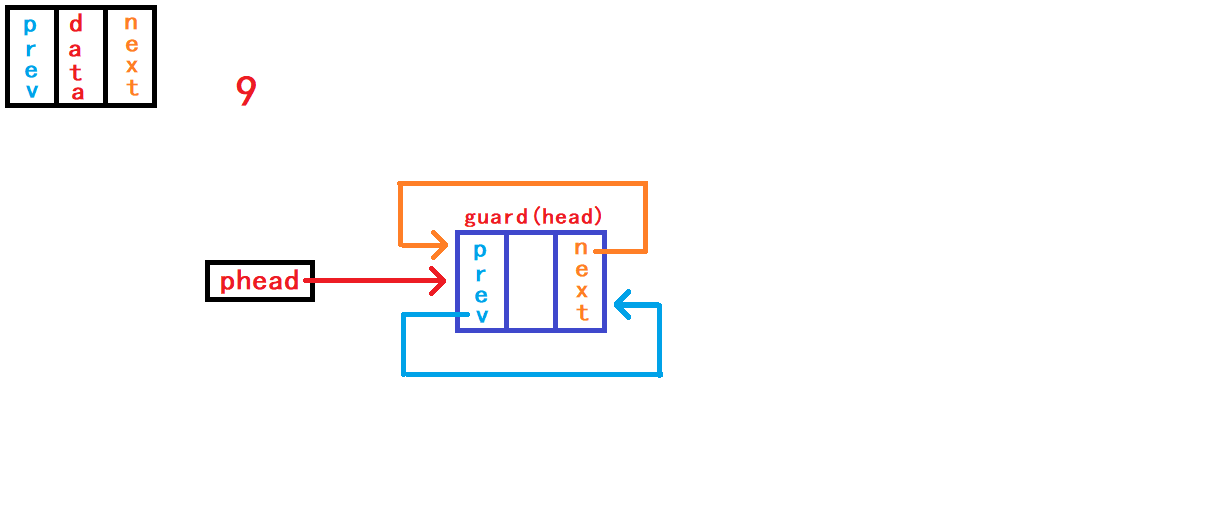
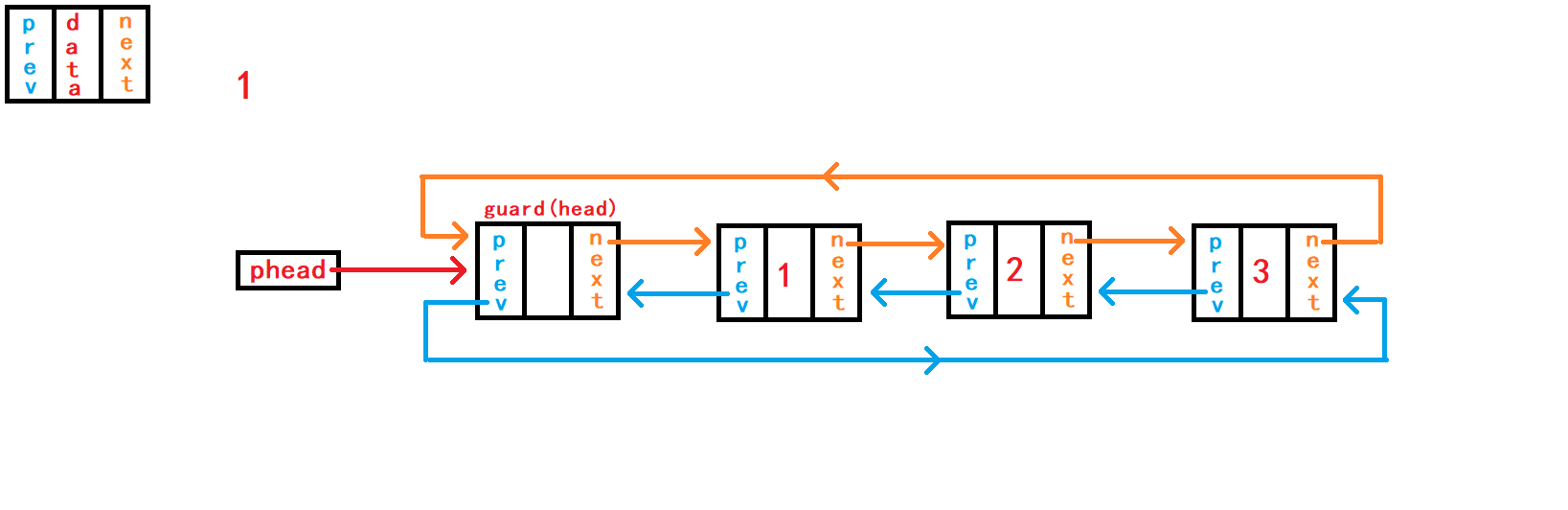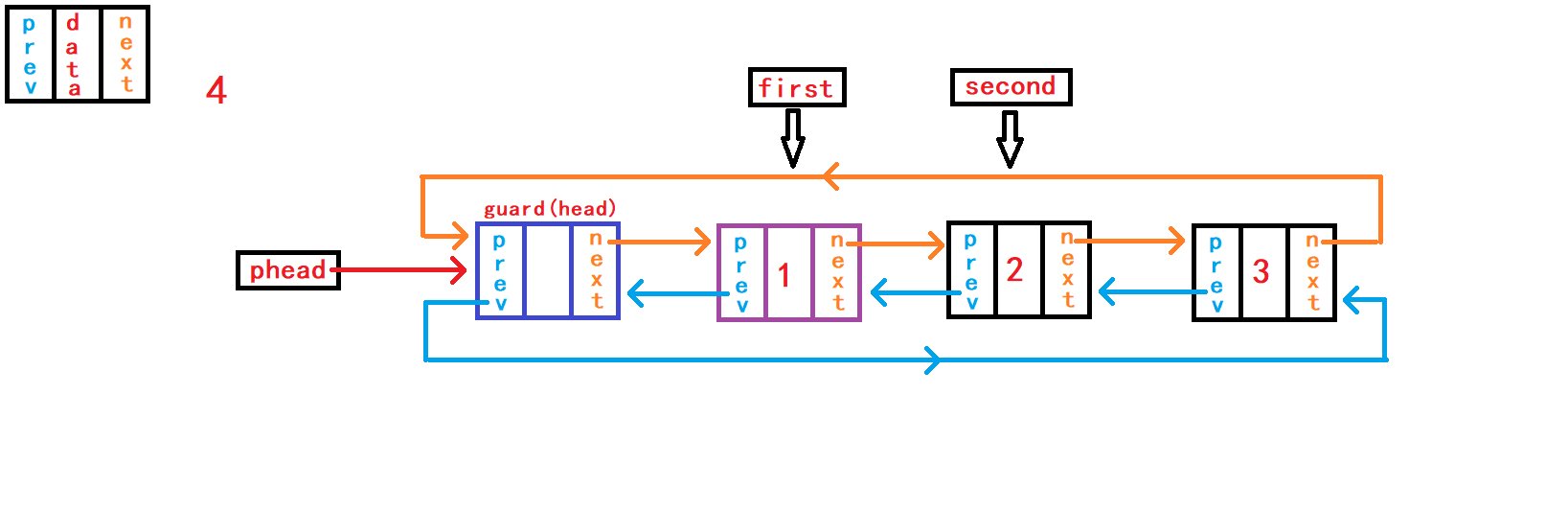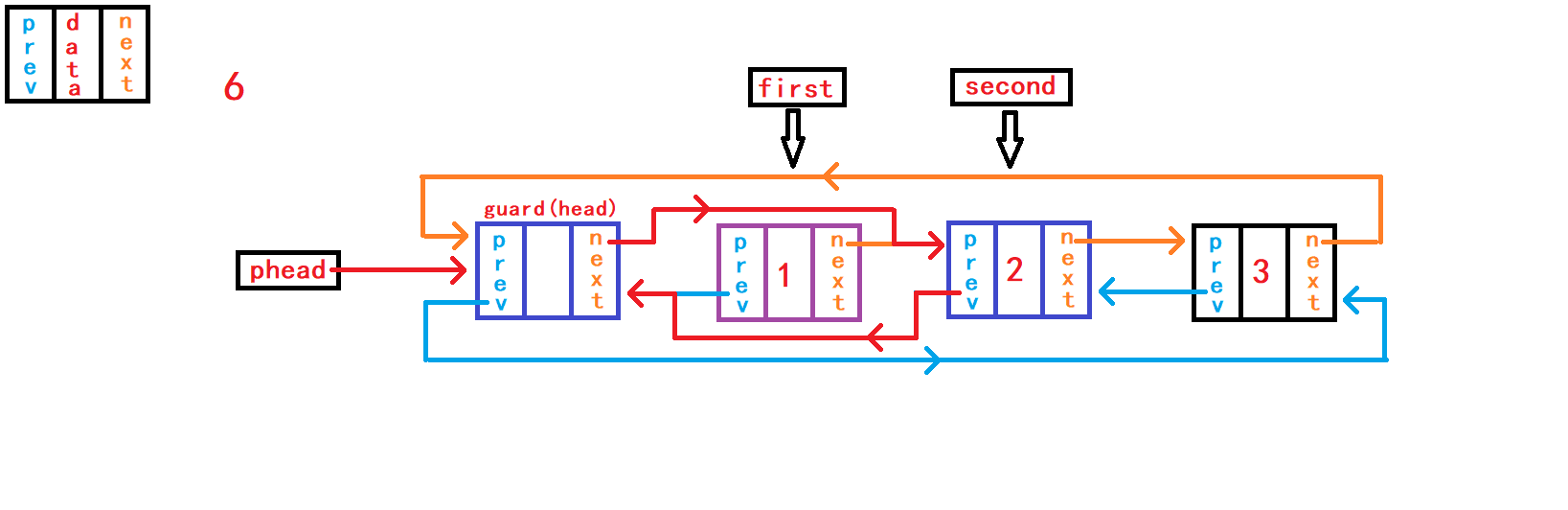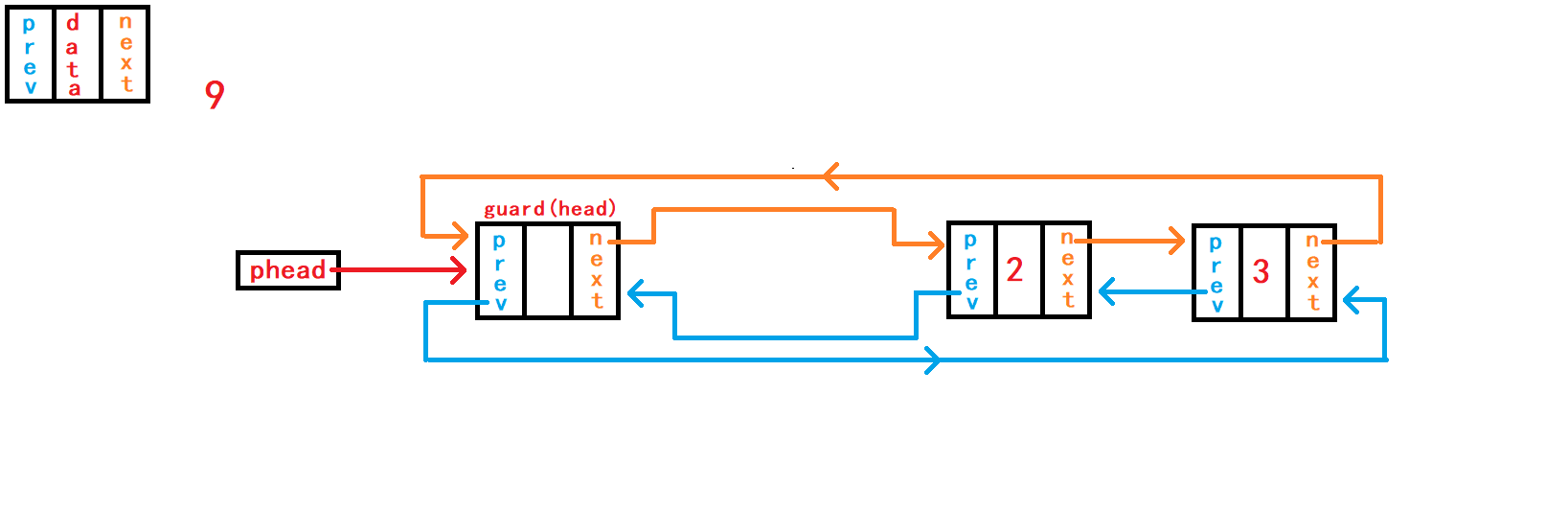
12. 查找数据并返回节点地址
从头节点的的下一个节点开始遍历
(使用while循环)链表中的所有存放数据的节点,直到头节点为止。
//查找数据并返回节点地址
DLTNode* DListFind(DLTNode* phead, DLTDataType x) {
assert(phead);
DLTNode* cur = phead->next;
while(cur){
if (cur->data == x) {
return cur;
}
cur = cur->next;
}
return NULL;
}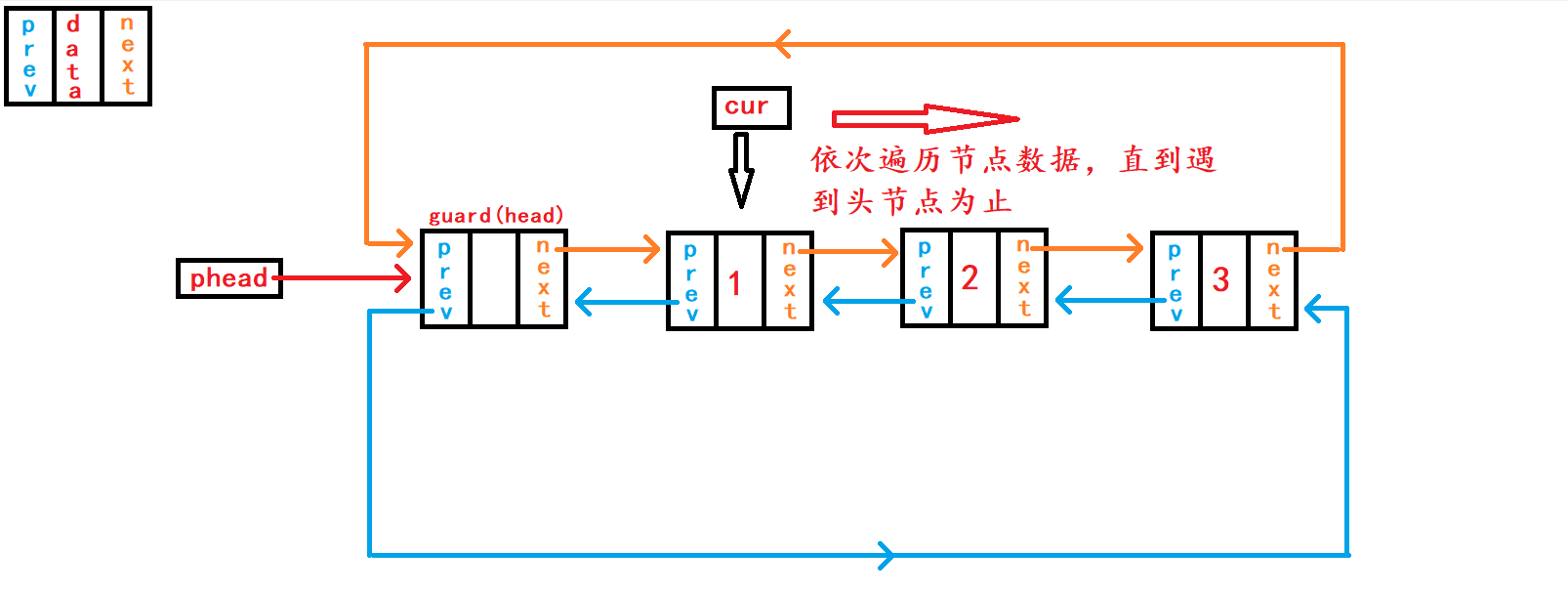
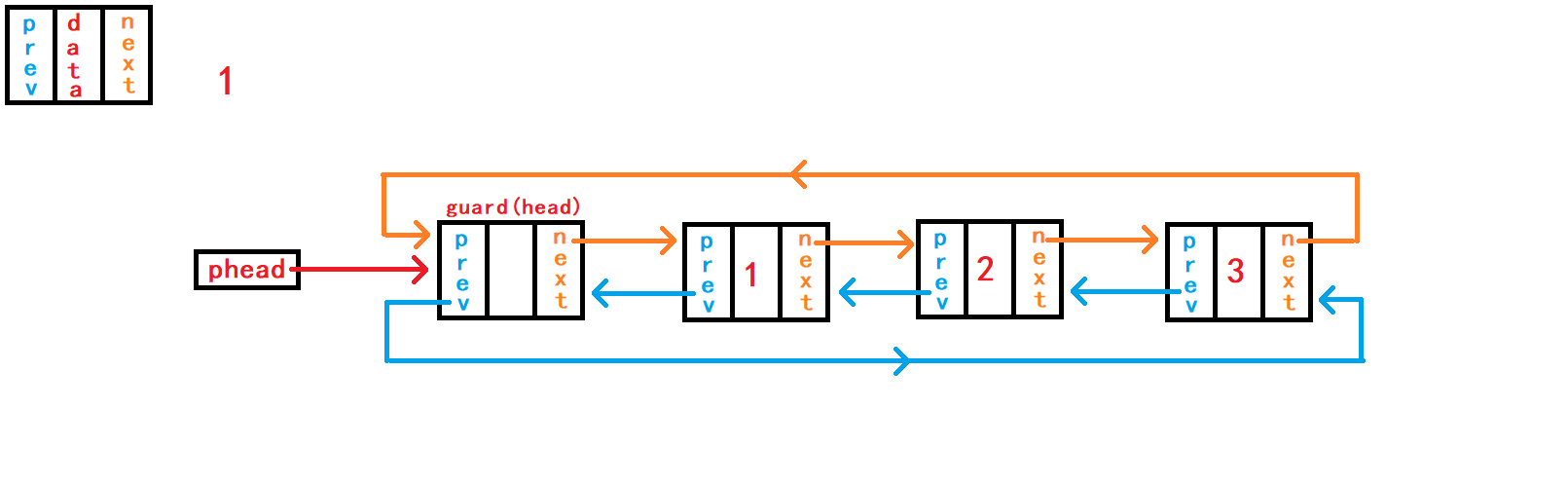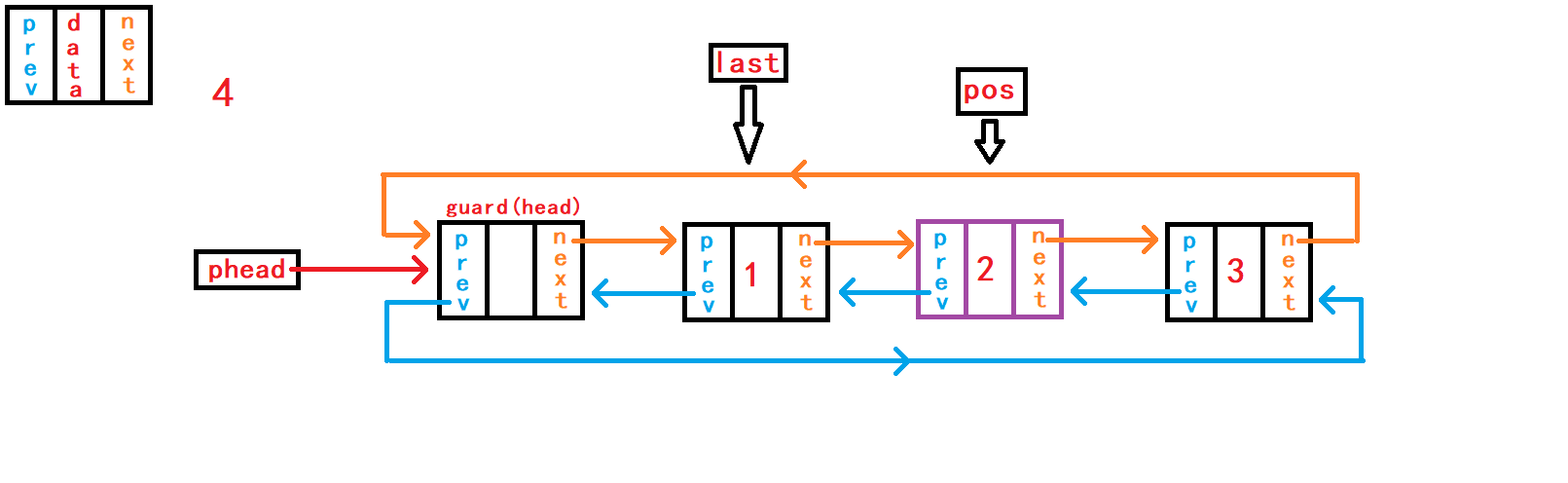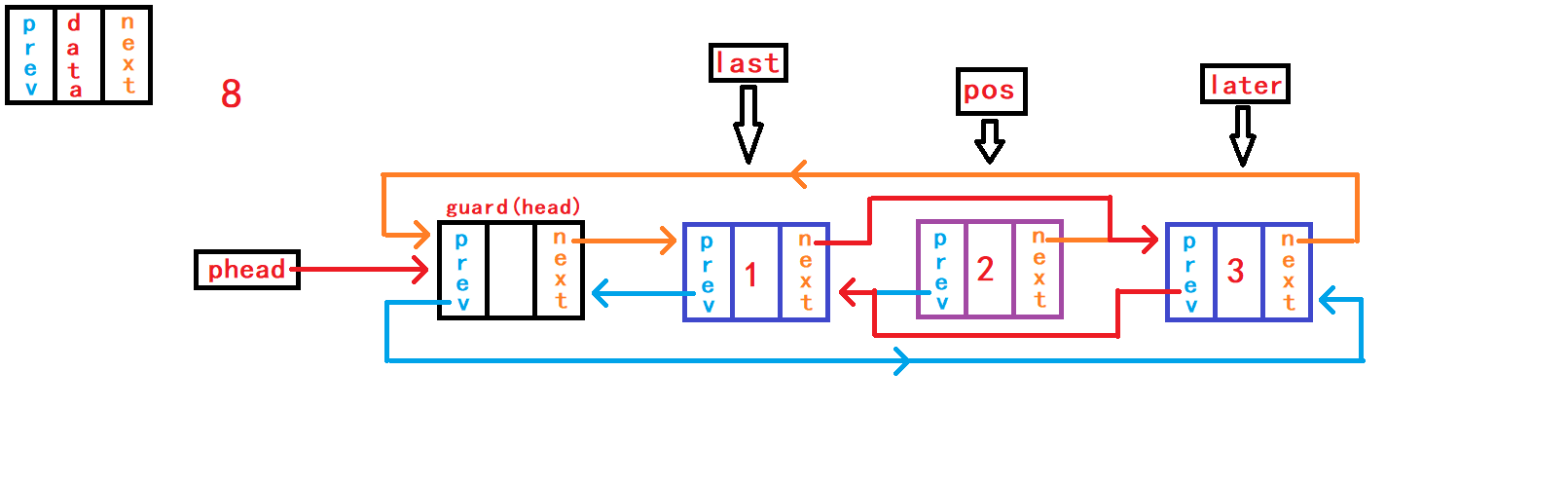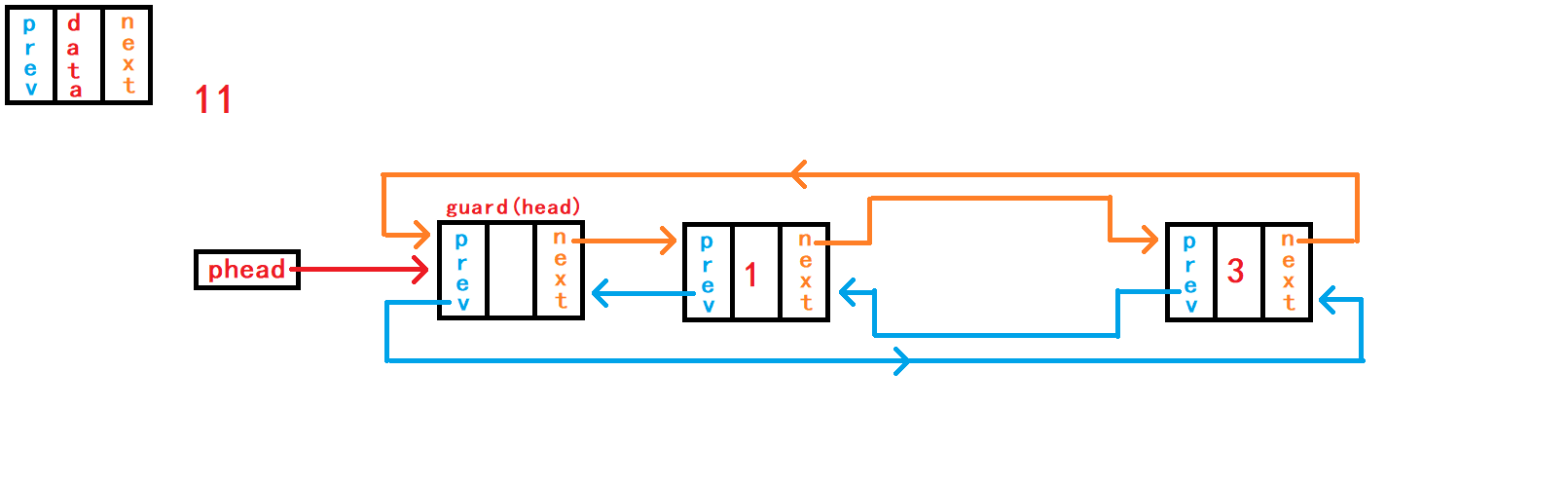
13. 在pos节点之前插入一个储存数据的节点
重点接口函数之一来了,实现该函数之后可以替换头插函数、尾插函数接口。 头插函数接口、尾插函数接口可以直接调用本函数接口实现相应功能。
//在pos节点插入一个节点
void DListInsert(DLTNode* pos, DLTDataType x){
assert(pos);
DLTNode* newnode = BuyDLTNode(x);
DLTNode* last = pos->prev;
last->next = newnode;
newnode->prev = last;
newnode->next = pos;
pos->prev = newnode;
}在函数一开始需要判断传入
节点地址副本pos是否为空,正常传入的地址不应该是NULL,并且该节点地址应该属于本链表内。 判断pos是否是空,对其进行断言暴力判断就可以;而判断其是否是本链表内的节点则需要头结点的地址来遍历链表判断,需要传入头结点的地址,但是传入的节点是否属于本链表的功能不应该是本函数的功能,应该有外部调用者判断。 在pos节点前插入节点需要得到pos节点的上一个节点的地址,以便于pos的上一个节点与newnode节点进行链接。 不同于单向链表需要借助头节点遍历整个链表用于找到pos节点的上一个节点;带头双向循环链表则不需要头节点的帮助,因为pos节点不仅包含着下一个节点的的地址,还包含着上一个节点的地址,所以只需要pos节点就可以找到pos的上一个节点了。 借助结构体指针变量last记录pos节点的上一个节点; 分别建立节点last与newnode之间的链接和节点newnode与pos之间的链接。此情况下,这两个操作没有先后顺序,可以任意进行。
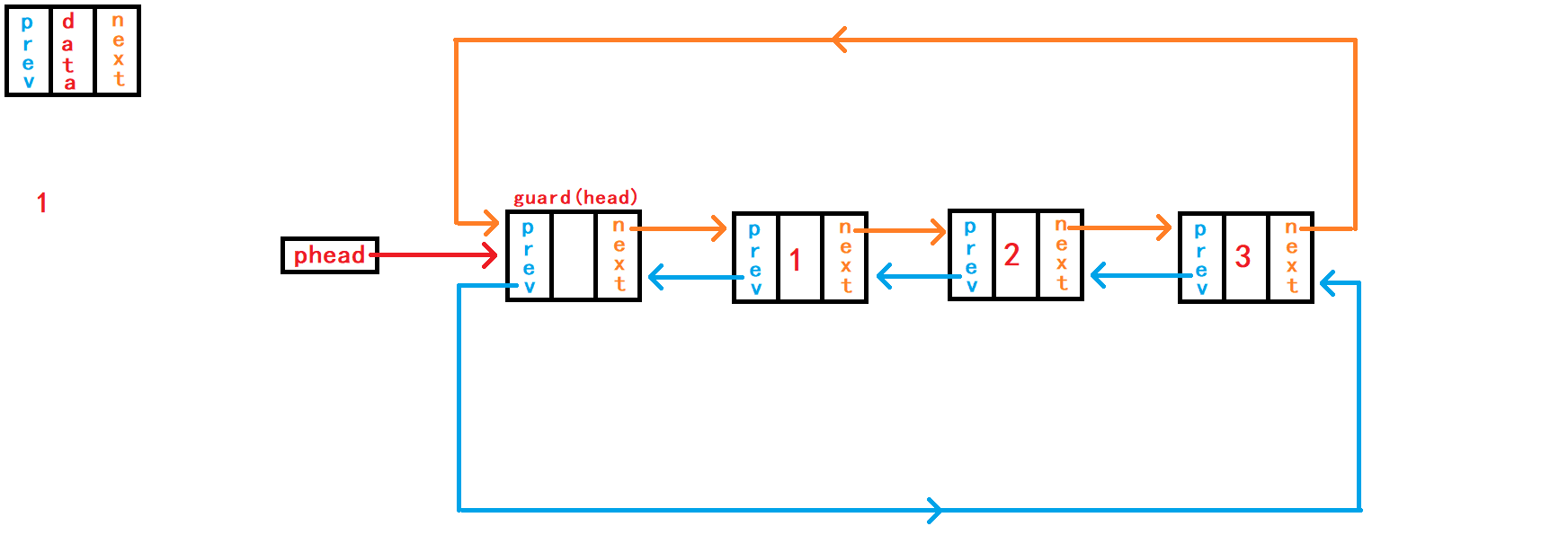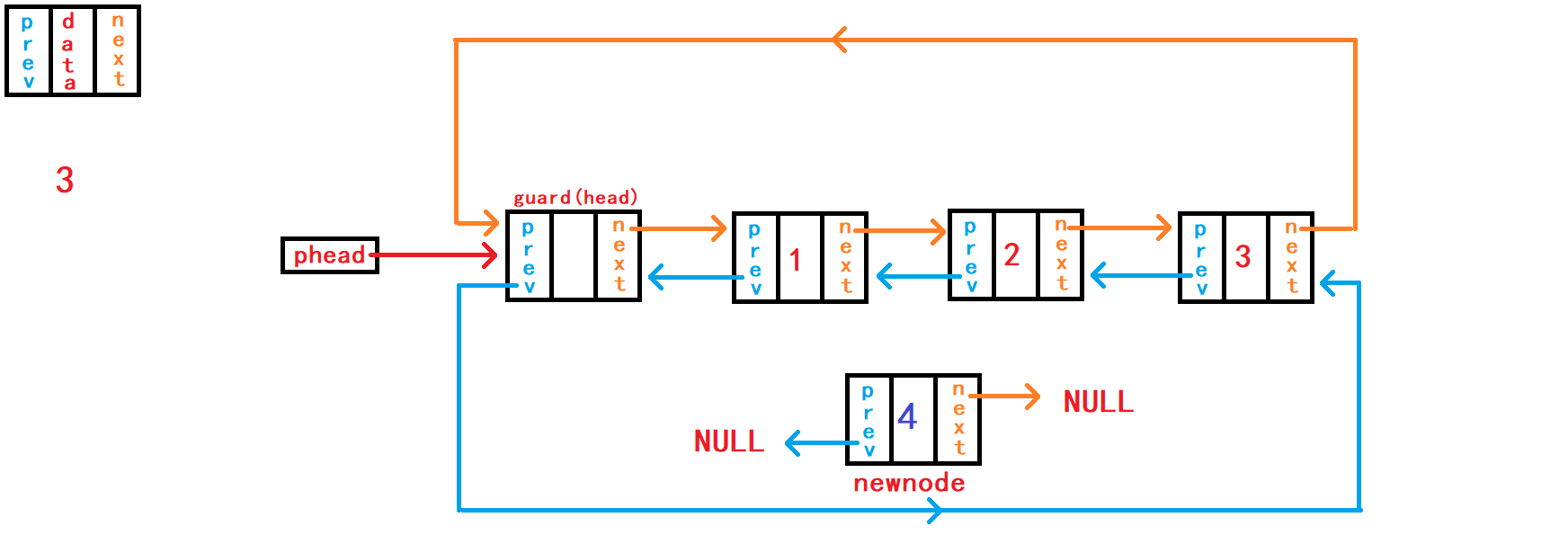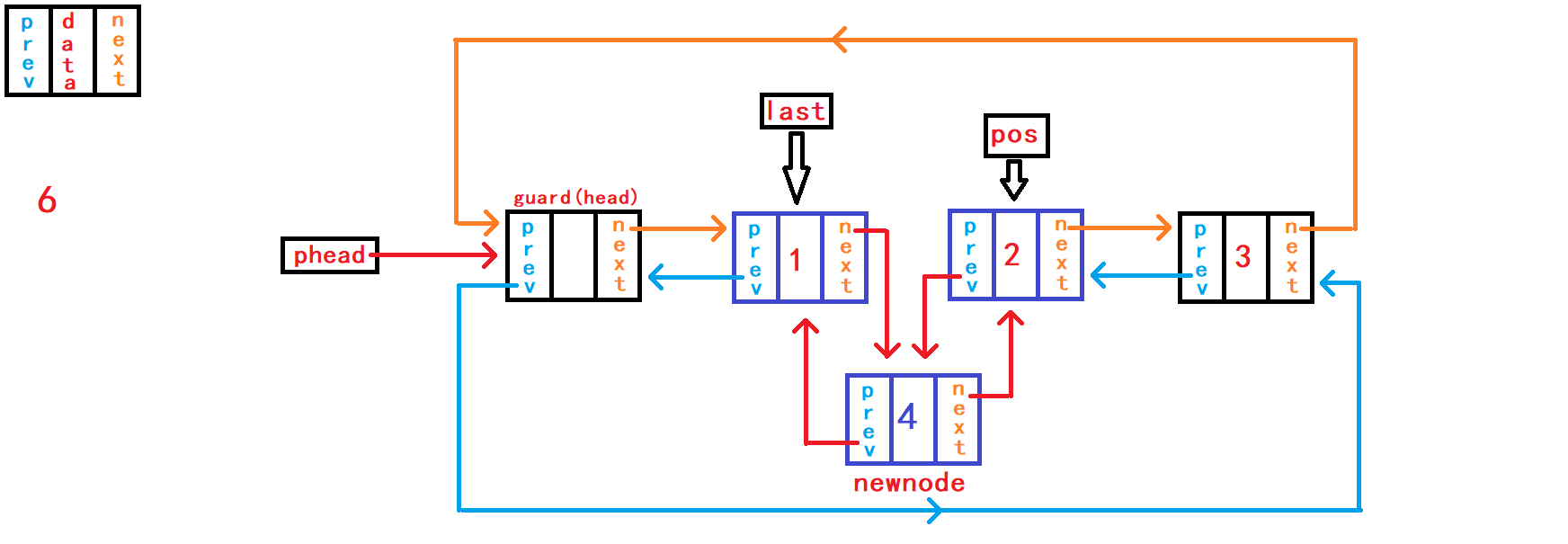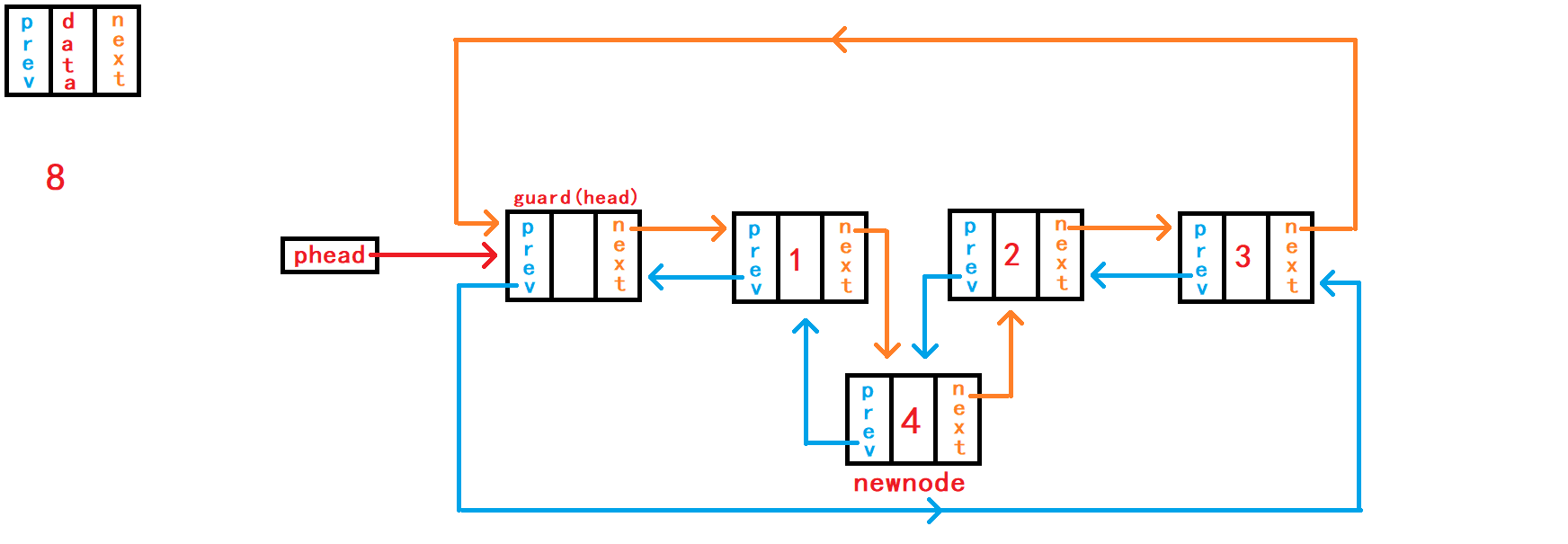
14. 删除pos节点
重点接口函数之二来了,实现该函数之后可以替换头删函数、尾删函数接口。 头删函数接口、尾删函数接口可以直接调用本函数接口实现相应功能。
//删除pos节点
void DListErase(DLTNode* pos) {
assert(pos);
DLTNode* last = pos->prev;
DLTNode* later = pos->next;
last->next = later;
later->prev = last;
free(pos);
//pos = NULL;
}在函数一开始需要判断传入
节点地址副本``pos是否为空,正常传入的地址不应该是NULL,并且该节点地址应该属于本链表内的节点。 判断pos是否是空,对其进行断言暴力判断就可以;而判断其是否是本链表内的节点则需要头结点的地址来遍历链表判断,需要传入头结点的地址,但是传入的节点是否属于本链表的功能不应该是本函数的功能,应该有外部调用者判断。 删除pos节点后需要将pos节点前一个节点和pos节点后一个节点建立链接关系。因此需要得到pos节点的上一个节点的地址。 借助结构体指针变量last记录pos节点上一个节点的地址; 借助结构体指针变量later记录pos节点下一个节点的地址。 需要建立节点last与later之间的链接关系,然后手动释放free指针pos指向的空间即可。
15. 销毁链表
链表使用结束,链表中会有一个或多个节点向内存申请的空间未被释放,放着不管的就是内存泄露的情况。虽然程序运行结束时操作系统会自动回收分配给程序的空间,不会出现内存泄漏的情况。但是我们不能永远依靠着操作系统解决内存泄漏的问题,我们得自己注意。有许多程序是不会轻易停止运行的,如果这样的程序存在内存泄漏将会是一个不小的危机。
//销毁链表,一级指针或者二级指针都可以,只不过一级指针下头指针需要在外部被置空
void DListDestroy(DLTNode* phead) {
assert(phead);
DLTNode* cur = phead->next;
while (cur != phead) {
DLTNode* later = cur->next;
free(cur);
cur = later;
}
free(phead);
//phead = NULL;
//外部头指针需要调用者在外部置NULL
}同输出节点数据相似,链表节点也将通过
while循环达到节点的空间顺序释放。 我们从头节点的下一个节点开始进行,依次释放节点,直到循环走到头节点时停止循环,在循环结束之后在释放头节点的空间即可。 本函数接受的是外部头指针,得到的是外部头指针的副本phead,所以我们并不能在函数内部修改外部头指针使其置为NULL,而是需要在外部调用者手动将其置空。
16. 头插数据、尾插数据操作借助插入节点函数接口快速实现
尾插接口函数
phead的前一个节点相当于尾。
void DListPushBack(DLTNode* phead, DLTDataType x) {
assert(phead);
DListInsert(phead, x);
}头插接口函数
phead的下一个节点相当于真正意义上头。(是储存数据节点的头节点)
void DListPushFront(DLTNode* phead, DLTDataType x) {
assert(phead);
DListInsert(phead->next, x);
}17. 头删数据、尾删数据操作借助删除节点函数快速实现
尾删接口函数
phead的前一个节点相当于尾。
void DListPopBack(DLTNode* phead) {
assert(phead);
DListErase(phead->prev);
}头删接口函数
phead的下一个节点相当于真正意义上头。(是储存数据节点的头节点)
void DListPopFront(DLTNode* phead) {
assert(phead);
DListErase(phead->next);
}2.4 C语言实现
仍然是分文件实现: 头文件
DList.h
#pragma once
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
typedef int DLTDataType;
typedef struct DListNode {
DLTDataType data;
struct DLTDataType* next;
struct DLTDataType* prev;
}DLTNode;
//初始化
//void DListInit(DLTNode** pphead);
DLTNode* DListInit();
//遍历链表,输出数据
void DListPrint(DLTNode* phead);
//销毁链表,一级指针或者二级指针都可以,只不过一级指针下头指针需要在外部被置空
void DListDestroy(DLTNode* phead);
//头插尾插 头删尾删
void DListPushBack(DLTNode* phead, DLTDataType x);
void DListPushFront(DLTNode* phead, DLTDataType x);
void DListPopBack(DLTNode* phead);
void DListPopFront(DLTNode* phead);
//查找数据并返回节点地址
DLTNode* DListFind(DLTNode* phead, DLTDataType x);
//在pos节点插入一个节点
void DListInsert(DLTNode* pos, DLTDataType x);
//删除pos节点
void DListErase(DLTNode* pos);函数定义源文件
DList.c
#include "DList.h"
//初始化方法1:
//void DListInit(DLTNode** pphead) {
// assert(pphead);
// DLTNode* guard = (DLTNode*)malloc(sizeof(DLTNode));
// if (!guard) {
// perror("DListInit");
// exit(-1);
// }
// *pphead = guard;
// guard->next = guard;
// guard->prev = guard;
//}
//初始化方法2:
DLTNode* DListInit() {
DLTNode* guard = (DLTNode*)malloc(sizeof(DLTNode));
if (!guard) {
perror("DListInit");
exit(-1);
}
guard->next = guard;
guard->prev = guard;
return guard;
}
//遍历链表,输出数据
void DListPrint(DLTNode* phead) {
assert(phead);
DLTNode* cur = phead->next;
while (cur != phead) {
printf("%d<==>", cur->data);
cur = cur->next;
}
printf("\n");
}
//销毁链表,一级指针或者二级指针都可以,只不过一级指针下头指针需要在外部被置空
void DListDestroy(DLTNode* phead) {
assert(phead);
DLTNode* cur = phead->next;
while (cur != phead) {
DLTNode* later = cur->next;
free(cur);
cur = later;
}
free(phead);
//phead = NULL;
//外部头指针需要调用者在外部置NULL
}
//申请一个新节点
DLTNode* BuyDLTNode(DLTDataType x) {
DLTNode* newnode = (DLTNode*)malloc(sizeof(DLTNode));
if (!newnode) {
perror("BuyDLTNode");
exit(-1);
}
newnode->data = x;
newnode->next = newnode->prev = NULL;
return newnode;
}
//头插尾插 头删尾删
void DListPushBack(DLTNode* phead, DLTDataType x) {
assert(phead);
DLTNode* newnode = BuyDLTNode(x);
DLTNode* tail = phead->prev;
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
phead->prev = newnode;
//调用插入函数
//DListInsert(phead, x);
}
void DListPushFront(DLTNode* phead, DLTDataType x) {
assert(phead);
DLTNode* newnode = BuyDLTNode(x);
//方法1
newnode->next = phead->next;
phead->next->prev = newnode;
phead->next = newnode;
newnode->prev = phead;
方法二
//DLTNode* first = phead->next;
//phead->next = newnode;
//newnode->prev = phead;
//
//newnode->next = first;
//first->prev = newnode;
//方法三
//DListInsert(phead->next, x);
}
bool DListEmpty(DLTNode* phead) {
assert(phead);
return phead->next == phead;
}
void DListPopBack(DLTNode* phead) {
assert(phead);
DLTNode* tail = phead->prev;
DLTNode* last = tail->prev;
last->next = phead;
phead->prev = last;
free(tail);
//DListErase(phead->prev);
}
void DListPopFront(DLTNode* phead) {
assert(phead);
assert(!DListEmpty(phead));
DLTNode* first = phead->next;
DLTNode* second = first->next;
phead->next = second;
second->prev = phead;
free(first);
//first = NULL;
DListErase(phead->next);
}
//查找数据并返回节点地址
DLTNode* DListFind(DLTNode* phead, DLTDataType x) {
assert(phead);
DLTNode* cur = phead->next;
while(cur){
if (cur->data == x) {
return cur;
}
cur = cur->next;
}
return NULL;
}
//在pos节点插入一个节点
void DListInsert(DLTNode* pos, DLTDataType x){
assert(pos);
DLTNode* newnode = BuyDLTNode(x);
DLTNode* last = pos->prev;
last->next = newnode;
newnode->prev = last;
newnode->next = pos;
pos->prev = newnode;
}
//删除pos节点
void DListErase(DLTNode* pos) {
assert(pos);
DLTNode* last = pos->prev;
DLTNode* later = pos->next;
last->next = later;
later->prev = last;
free(pos);
//pos = NULL;
}结语
本节到这里就差不多结束了,主要内容介绍了链表的种类;其中详细介绍了带头双向循环链表的功能并完成了
C语言代码实现,希望本文的一些内容能够帮助到在看的你!!!
下次再见!
END
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2022-09-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号