基于RGB-D的6D目标检测算法


基于RGB-D的6D目标检测算法
本文参考了ITAIC的文章 A Review of 6D Object Pose Estimation
概览
RGB-D
这里介绍几篇经典的基于RGB-D的6D目标检测算法。
RGB-D,就是RGB + Depth,也就是彩色图像 + 深度信息。
直觉上来说,比单纯的RGB有了更多的信息,精度也会变得更加高了。
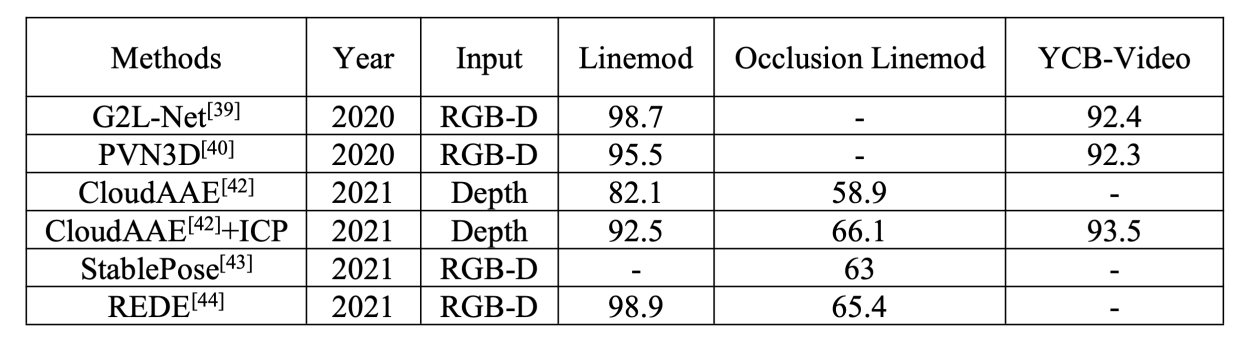
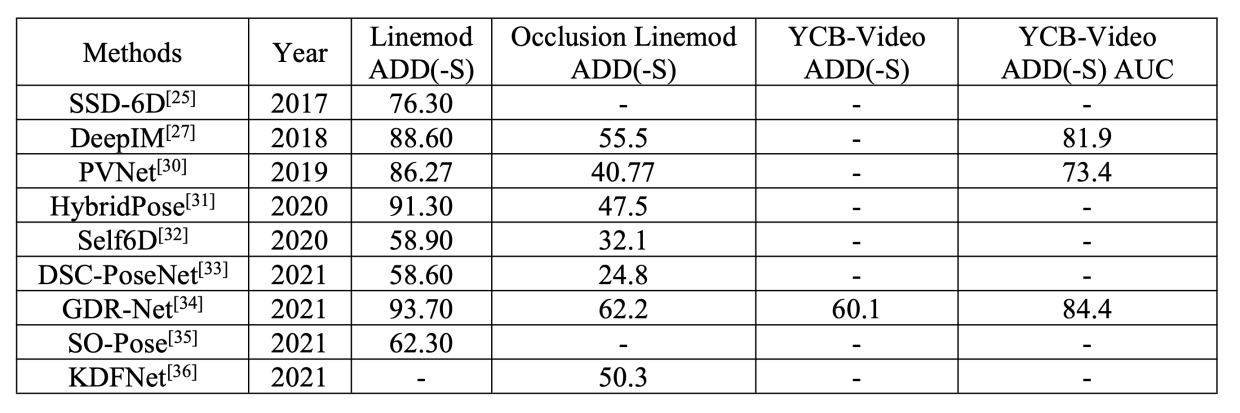
这里给出RGB部分方法的性能进行对比,RGB-D的指标是采用的ADD(-S), 所以我们就只看第3,4,5列的指标
RGB
算法REDE在Linemod、Occlusion Linemod、YCB-Video数据集上基本已经超越了所有的RGB算法。
接下来,我们主要介绍三个RGB-D算法G2LNet、PVN3D以及REDE。
G2L-Net
G2L-Net: Global to Local Network for Real-time 6D Pose Estimation with Embedding Vector Features
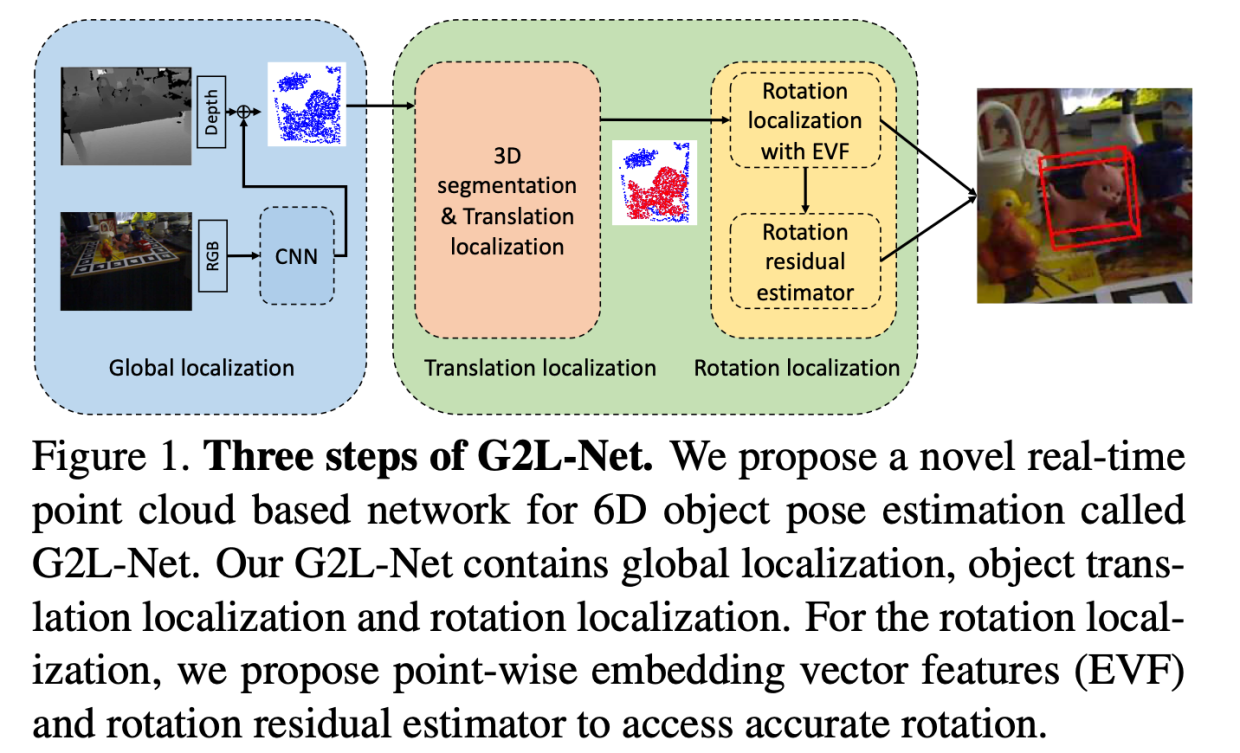
G2L-Net Overview
如上图所示,分成三个步骤:
- 全局的定位(Global Localization)
- 平移的定位(Translation Localization)
- 旋转的定位(Rotation Localization)

步骤
全局的定位
具体而言,首先将RGB图像送到CNN中,得到三个东西:边界框,类别概率图(class probability map),类别向量
文章使用的是一个YOLOv3作为2D的目标检测器
利用2D的边界框架上深度信息,就可以构造出一个个棱台(frustum proposal),只考虑棱台中包含的空间点,便减少了所需要计算的数据规模。
这里文章引入了一种3D球的约束,将点云变得更加紧致
最终输出一系列的点云,对应2D目标检测的结果
平移的定位
利用3D的点云信息,做语义分割,得到分割后的点云,即每一个空间点有自己的类别
旋转的定位
这里将类别向量引入,以点云信息作为输入,直接输出对应的旋转
PVN3D
PVN3D: A Deep Point-Wise 3D Keypoints V oting Network for 6DoF Pose Estimation
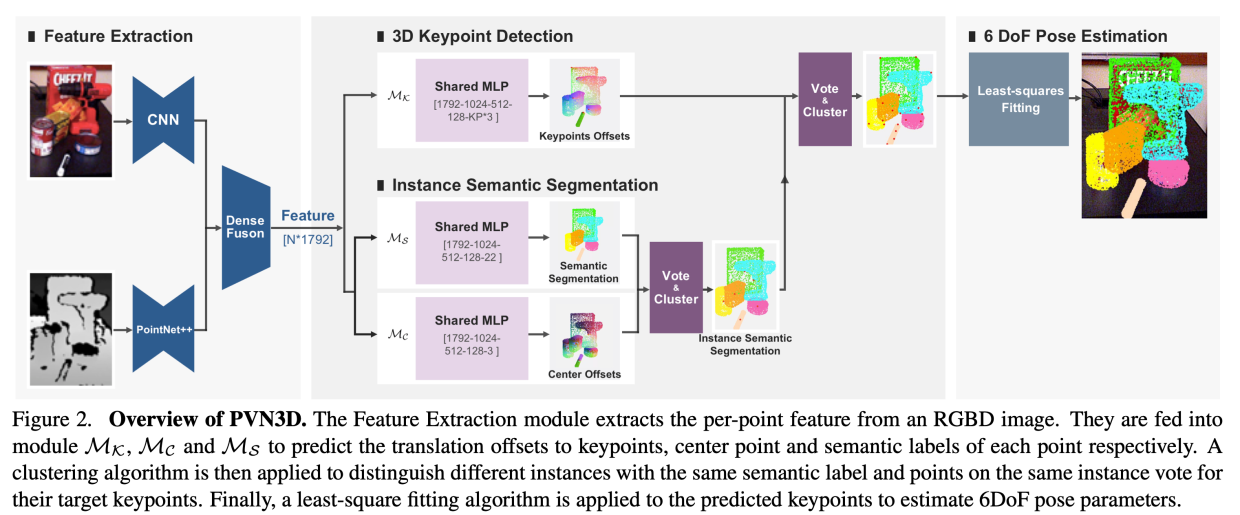
PVN3D
个人认为其主要的贡献在于结合了语义分割的技术
如上图所示,整个PVN3D可以被分成多个部分:
- 特征抽取
- 3D关键点检测
- 语义分割
- 6DoF姿态估计
特征抽取
这里使用一个卷积网络CNN和一个PointNet++分别提取RGB特征以及深度特征,然后进行特征融合。
3D关键点检测、语义分割
使用MLP来分别估计关键点的平移、中心点以及每一个点的语义类别标签
可以看到,其输出的维度分别对应3、22、3,即3个平移的偏移值,22个类别,以及3个中心点偏移值。
然后使用语义标签和中心点,使用投票Vote和聚类Cluster,得到一个实例级别的语义分割
然后将这个结果结合关键点检测,就能给这些关键点分配对应的实体
6DoF姿态估计
使用最小二乘(Least-Square Fitting)实现姿态估计,输出旋转矩阵R以及平移t
REDE
REDE: End-to-End Object 6D Pose Robust Estimation Using Differentiable Outliers Elimination
我们先来看看该方法和其他方法的区别
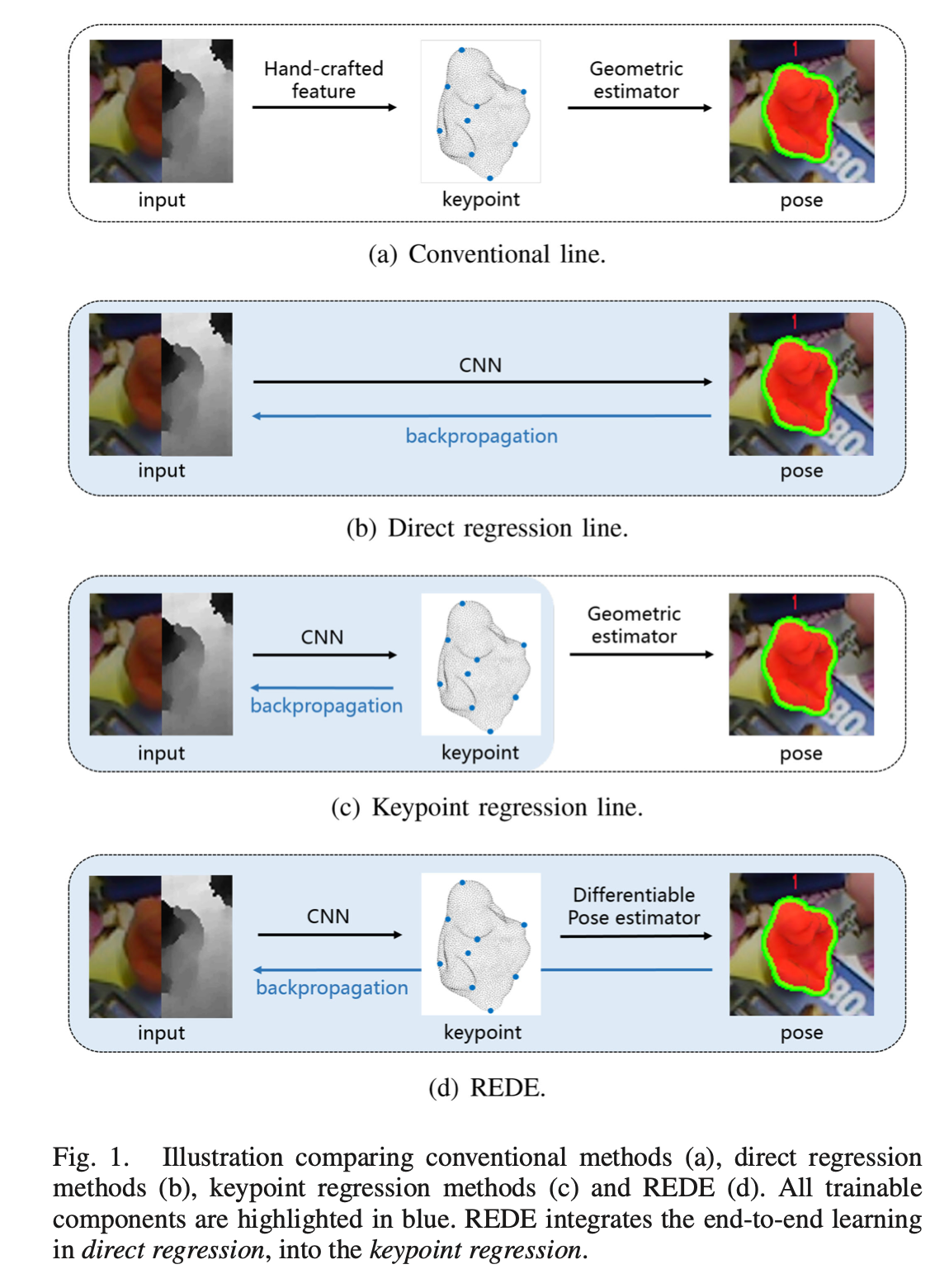
REDE
如上图所示,(c)是基于关键点回归的方法,(d)是REDE方法
可以看到,用CNN去做关键点的检测这一步,大家都是一样的,只不过在后面对姿态进行估计时,REDE是可差分的,能够直接反向传播到前面所有的可学习的参数上。
回想一下上面的PVN3D,在计算关键点之后,便使用最小二乘去估计姿态,估计的偏差并不会影响前面的参数,所以仍然属于(c)。
下面给出其方法的概览
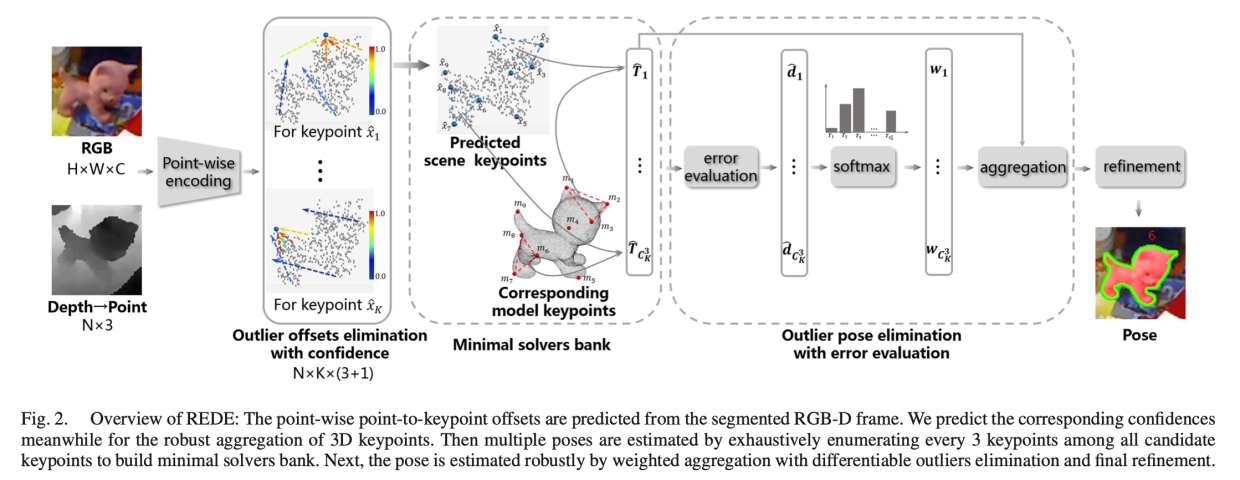
REDE
从左到右:
- 首先使用点级别的编码
- 类似PVN3D,这里也是分别进行编码,用PSPNet抽取RGB特征,用PointNet抽取深度图信息
- 最后将RGB特征和深度特征融合在一起,具体实现可以参考其仓库中的 lib/network.py
- 然后使用快速点采样 (Fast Point Sample,FPS) 得到K个关键点,用网络估计这些关键点的偏移,计算L1误差
- 这里引入一个异常偏移消除 (Outlier Offsets Elimination) 技术,对于每一个点的偏移估计,多计算一个置信度c,在计算关键点位置的时候,乘以这个置信度
- 使用一个Minimal Solvers Bank,对每三个关键点求姿态估计,这样就可以生成 C_K^3 个姿态,提高整体的鲁棒性
- 最后,对 C_K^3 个姿态,加权平均,通过2范数和F范数计算偏移和旋转的误差,实现可微分的误差计算
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-05-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号