「Deep Learning」PyTorch初步认识


终于跑通了自己第一个基于PyTorch的深度学习模型!!!
PyTorch的安装、CUDA环境的配置以及Tensor的基本操作请查看「深度学习」PyTorch笔记-01-基础知识。
Tensor基本操作
创建
直接输入值创建Tensor:
import torch
torch.Tensor([[1, 2], [3, 4]])
Out[3]:
tensor([[1., 2.],
[3., 4.]])打印Tensor类型:
a = torch.Tensor([[1, 2], [3, 4]])
a.type(), type(a)
Out[5]: ('torch.FloatTensor', torch.Tensor)创建全为1的Tensor:
torch.ones(2, 3)
Out[11]:
tensor([[1., 1., 1.],
[1., 1., 1.]])创建一个与指定Tensor形状相同且全1的Tensor:
torch.ones_like(a)
Out[12]:
tensor([[1., 1.],
[1., 1.]])创建全为0的Tensor:
torch.zeros(3, 2)
Out[13]:
tensor([[0., 0.],
[0., 0.],
[0., 0.]])创建一个与指定Tensor形状相同且全0的Tensor:
torch.zeros_like(a)
Out[14]:
tensor([[0., 0.],
[0., 0.]])生成一个任意shape包含0~1随机值的Tensor:
torch.rand(2, 3)
Out[15]:
tensor([[0.0535, 0.6409, 0.0688],
[0.5141, 0.4700, 0.5606]])生成随机一个符合正态分布的Tensor:
torch.normal(
mean=0,
std=torch.rand(5)
)
Out[16]: tensor([ 0.8522, -0.2326, 0.5324, -0.0838, 1.1735])可以使用:
torch.manual_seed(666)来设置随机种子。
创建等步长的Tensor:
torch.arange(0, 10, 1)
Out[17]: tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])创建等间隔的Tensor:
torch.linspace(0, 10, 5)
Out[18]: tensor([ 0.0000, 2.5000, 5.0000, 7.5000, 10.0000])生成随机乱序序号的Tensor:
torch.randperm(10)
Out[19]: tensor([2, 5, 4, 6, 9, 1, 7, 8, 3, 0])创建对角Matrix的Tensor:
torch.eye(4)
Out[20]:
tensor([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])索引与数据筛选
where
torch.where(condition, x, y): 按照条件从x和y中选出满足条件的元素组成新的tensor。
举个🌰:
a = torch.arange(1, 10, 1).reshape(3, -1)
b = torch.ones_like(a) * 5
torch.where(a < b, a, b) # 如果a<b,则输出a,否则输出b
Out[22]:
tensor([[1, 2, 3],
[4, 5, 5],
[5, 5, 5]])
torch.where(a < b, 1, 0)
Out[23]:
tensor([[1, 1, 1],
[1, 0, 0],
[0, 0, 0]])index_select
torch.index_select(input, dim, index, *, out=None): 按照指定索引输出tensor。
举个🌰:
a
Out[24]:
tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
torch.index_select(a, dim=0, index=torch.tensor([0, 2, 1])) # 在a的第0维上(按行划分),分别获取第0维上的0、2、1个元素
Out[25]:
tensor([[1, 2, 3],
[7, 8, 9],
[4, 5, 6]])
torch.index_select(a, dim=1, index=torch.tensor([0, 2])) # 在a的第1维上(按列划分),分别获取第0维上的0、2个元素
Out[26]:
tensor([[1, 3],
[4, 6],
[7, 9]])gather
torch.gather(input, dim, index, *, sparse_grad=False, out=None): 在指定维度上按照索引赋值输出tensor。
a = torch.tensor([[1,2,3], [4,5,6]])
torch.gather(input=a, dim=1, index=torch.tensor([[2,0,2,1], [1,1,0,0]]))
Out[28]:
tensor([[3, 1, 3, 2],
[5, 5, 4, 4]])

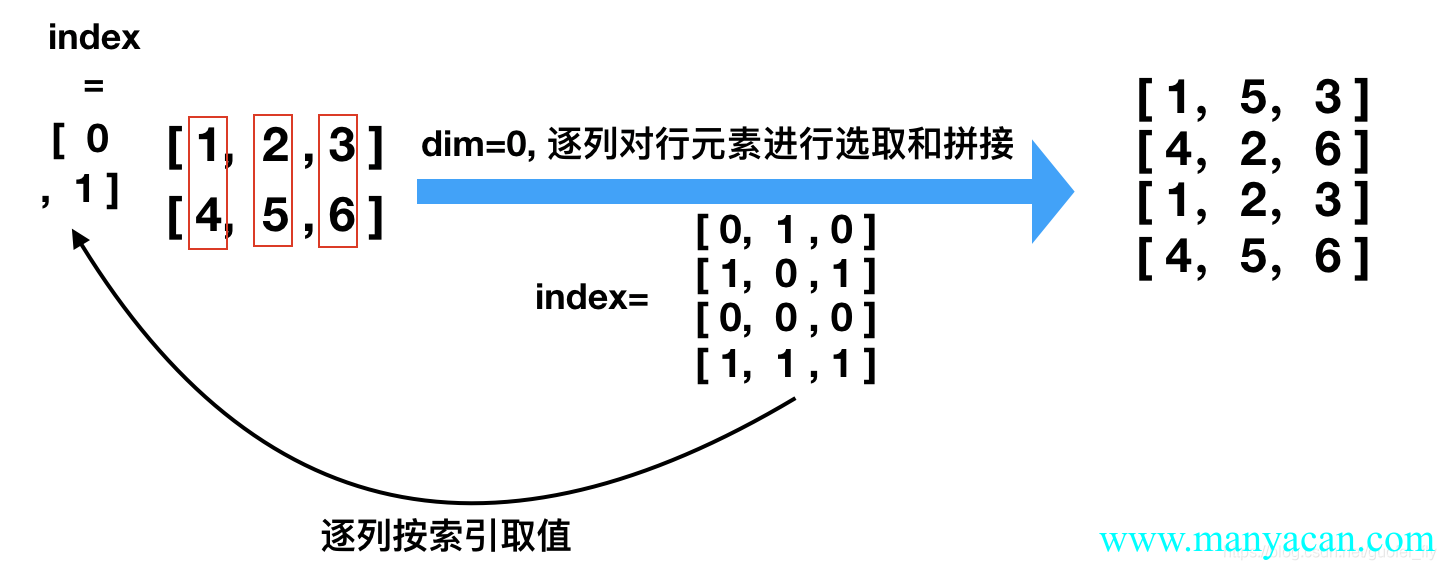
torch.gather(input=a, dim=0, index=torch.tensor([[0, 1, 0], [1,0,1], [0, 0, 0],[1,1,1]]))
Out[29]:
tensor([[1, 5, 3],
[4, 2, 6],
[1, 2, 3],
[4, 5, 6]])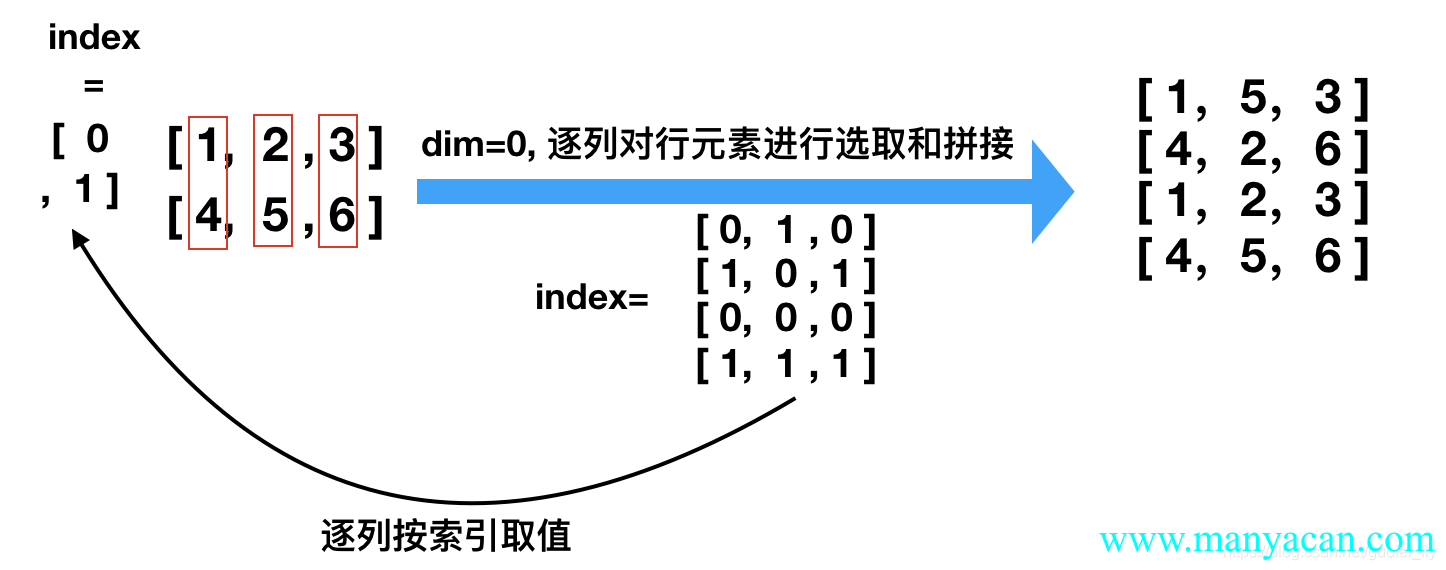
masked_select
torch.masked_select(input, mask, *, out=None): 按照mask输出tensor。
a
Out[32]:
tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
torch.gt(a, 6)
Out[33]:
tensor([[False, False, False],
[False, False, False],
[ True, True, True]])
torch.masked_select(a, torch.gt(a, 5))
Out[34]: tensor([6, 7, 8, 9])take
torch.take(input, index): 将输入看成1D Tensor,按照索引得到输出tensor。
torch.take(a, index=torch.tensor([8, 6, 3, 2, 1, 0]))
Out[35]: tensor([9, 7, 4, 3, 2, 1])nonzero
torch.nonzero(input, *, out=None, as_tuple=False): 输出非0元素的坐标。
b = torch.eye(3)
b
Out[37]:
tensor([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
torch.nonzero(b)
Out[38]:
tensor([[0, 0],
[1, 1],
[2, 2]])组合与拼接
cat
a = torch.linspace(1, 6, 6).view(2, 3)
a
Out[39]:
tensor([[1., 2., 3.],
[4., 5., 6.]])
b = torch.zeros_like(a)
b
Out[40]:
tensor([[0., 0., 0.],
[0., 0., 0.]])
torch.cat((a, b), dim=0)
Out[41]:
tensor([[1., 2., 3.],
[4., 5., 6.],
[0., 0., 0.],
[0., 0., 0.]])
torch.cat((a, b), dim=1)
Out[42]:
tensor([[1., 2., 3., 0., 0., 0.],
[4., 5., 6., 0., 0., 0.]])stack
torch.stack((a, b), dim=0)
Out[43]:
tensor([[[1., 2., 3.],
[4., 5., 6.]],
[[0., 0., 0.],
[0., 0., 0.]]])
torch.stack((a, b), dim=0).shape
Out[44]: torch.Size([2, 2, 3])注意
torch.stack()与torch.cat()的区别,torch.cat()不增加Tensor的维数,torch.stack()增加了维数。
切片
chunk
a = torch.linspace(1, 16, 16).view(-1, 8)
a
Out[45]:
tensor([[ 1., 2., 3., 4., 5., 6., 7., 8.],
[ 9., 10., 11., 12., 13., 14., 15., 16.]])
torch.chunk(a, 2)
Out[46]:
(tensor([[1., 2., 3., 4., 5., 6., 7., 8.]]),
tensor([[ 9., 10., 11., 12., 13., 14., 15., 16.]]))
torch.chunk(a, 4, dim=1)
Out[47]:
(tensor([[ 1., 2.],
[ 9., 10.]]),
tensor([[ 3., 4.],
[11., 12.]]),
tensor([[ 5., 6.],
[13., 14.]]),
tensor([[ 7., 8.],
[15., 16.]]))split
torch.split(a, 2)
Out[48]:
(tensor([[ 1., 2., 3., 4., 5., 6., 7., 8.],
[ 9., 10., 11., 12., 13., 14., 15., 16.]]),)
torch.split(a, 4, dim=1)
Out[49]:
(tensor([[ 1., 2., 3., 4.],
[ 9., 10., 11., 12.]]),
tensor([[ 5., 6., 7., 8.],
[13., 14., 15., 16.]]))
torch.chunk(a, 4, dim=1)中的“4”代表分为4份,torch.split(a, 4, dim=1)中的4代表每组有4个。
读取数据集——Dataset
PyTorch中使用torch.utils.data.Dataset加载数据集,类具体的定义方法为:
class MyDataset(Dataset):
def __init__(self, root_dir, label):
self.root_dir = root_dir
self.label = label
self.img_path = self.get_img_path()
def __getitem__(self, idx):
data = Image.open(self.img_path[idx])
return data, self.label
def get_img_path(self):
path = os.path.join(self.root_dir, self.label)
return glob.glob(os.path.join(path, '*.jpg'))
def __len__(self):
return len(self.img_path)图片格式调整——tensorboard
使用torchvision.transforms类对图片格式进行调整,选几个常用方法进行学习:
.ToTensor()
将输入的PIL图片转化为Tensor对象:
from PIL import Image
from torchvision import transforms
img_path = r'D:\code\...\16838648_415acd9e3f.jpg'
img = Image.open(img_path)
trans_tensor = transforms.ToTensor()
img_tensor = trans_tensor(img)
img_tensor.Normalize()
传入均值和标准差,对图片Tensor进行标准化:
trans_nor = transforms.Normalize([.5, .5, .5], [.5, .5, .5])
img_nor = trans_nor(img_tensor)
img_nor.Rescale()
对图片大小进行reshape:
trans_resize = transforms.Resize((512, 512))
img_resize = trans_resize(img)
img_resize.size.Compose()
将多个transforms方法进行串联:
transformer = transforms.Compose([
transforms.RandomGrayscale(.4),
transforms.ColorJitter(.4),
transforms.Resize(512),
transforms.ToTensor()
])加载数据集——DataLoader
可视化工具——tensorboard
- 中文介绍:https://zhuanlan.zhihu.com/p/471198169
- 官方文档:https://pytorch.org/docs/stable/tensorboard.html?highlight=summarywriter#torch.utils.tensorboard.writer.SummaryWriter
引包
from torch.utils.tensorboard.writer import SummaryWriter
# 查看帮助
help(SummaryWriter)
# 创建对象
writer = SummaryWriter('logs') # 需要传入log地址写入图片
写入单张图片:
writer.add_image('demo', img_array, dataformats='HWC')写入多张图片:
writer.add_images('Test Data in Batching', imgs, i)写入折线图
# Examples
for i in range(100):
writer.add_scalar('$y=x^2+1$', i, i ** 2 + 1)如果需要在一行写入两个图像,例如:
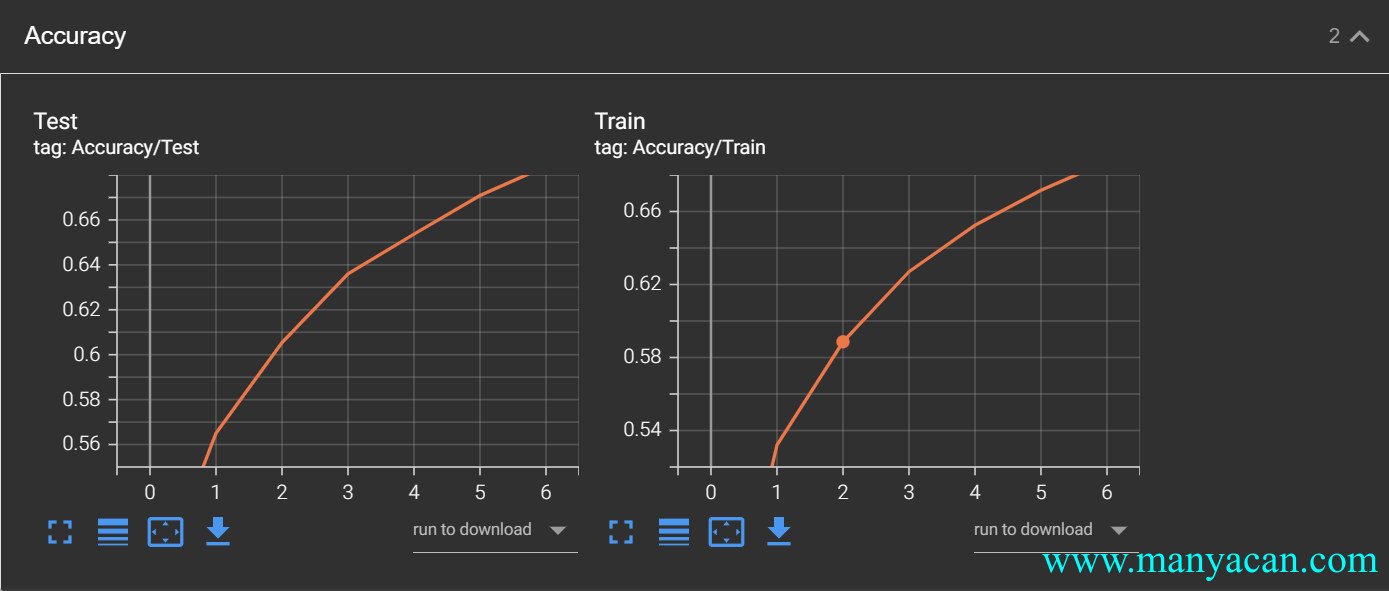
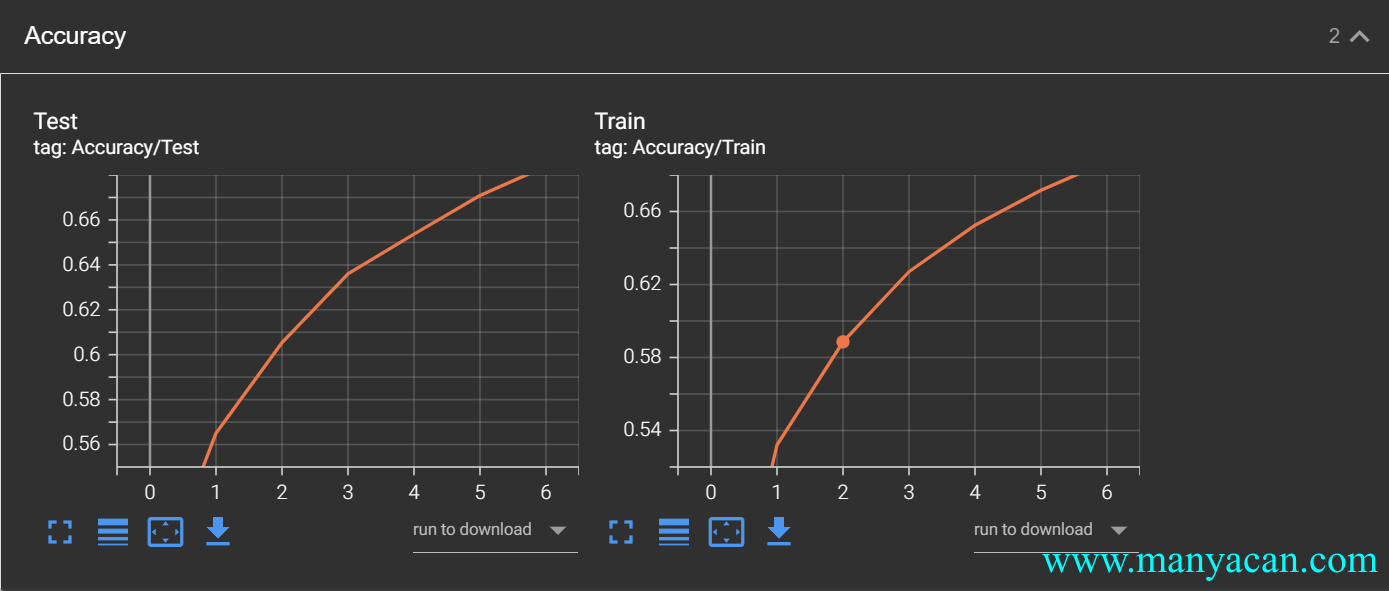
可以使用/作为图名的分隔符来操作:
writer.add_scalar('Loss/Train', epoch_train_loss.item(), epoch)
writer.add_scalar('Loss/Test', epoch_test_loss.item(), epoch)模型的可视化
writer.add_graph(module, demo_inputs)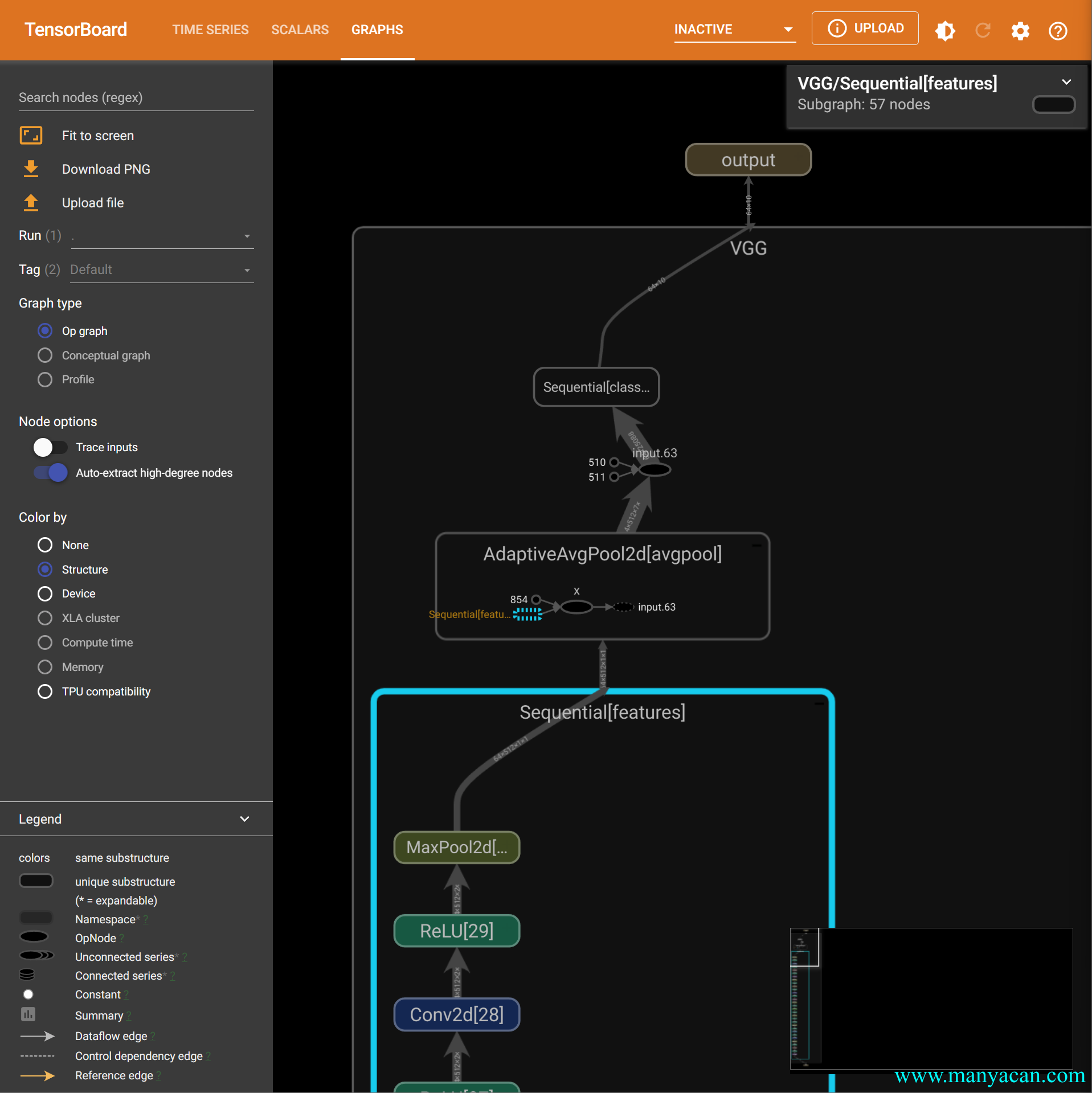
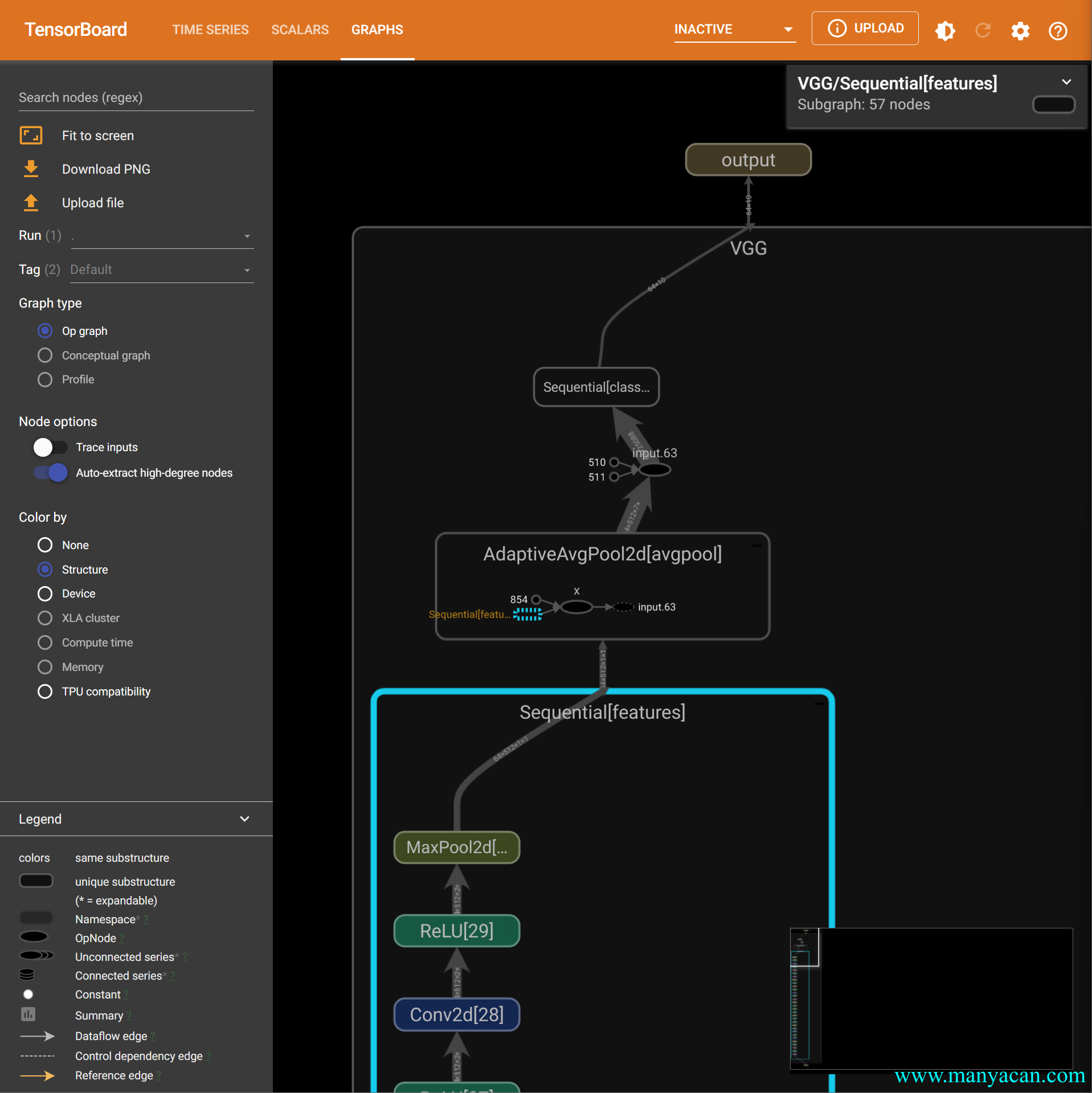
最后记得关闭对象
writer.close()一个奇奇怪怪的BUG
明明已经按照提示使用Ctrl+C结束了进程,但是点击IP地址还是可以访问到该端口:


而且这个时候,如果我再次运行别的项目的Tensorboard,浏览器端口中的内容不会实时更新。CSDN @YuQiao0303回答了在Linux端的解决方案:
- 查看占用该端口的程序;
- 强制结束该程序;
- 重新运行Tensorboard。
那我就在windows下也操作一遍:
C:\Windows\System32>netstat -aon|findstr "6006" # 查看占用6006端口程序的PID
TCP 127.0.0.1:6006 0.0.0.0:0 LISTENING 27796
C:\Windows\System32>tasklist|findstr "6006" # 查看占用6006端口的程序
C:\Windows\System32>taskkill /T /F /PID 27796 # 强制杀死该程序
SUCCESS: The process with PID 27796 (child process of PID 30540) has been terminated.然后重新运行tensorboard即可,完美解决问题。
神经网络模型的建立——torch.nn
torch.nn定义了PyTorch中的所有网络层。
基本结构
模型的基本结构:
import torch
class MyModule(torch.nn.Module):
def __init__(self):
"""
定义模型的初始化参数、方法
"""
super(MyModule, self).__init__()
def forward(self, input):
"""
向前传播
:param input:
:return:
"""
output = input + 1
return output
demo = MyModule()
x = torch.tensor(1.)
demo(x) # tensor(2.)单个卷积层演示
input = torch.tensor([ # 卷积层输入Tensor
[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]
])
kernel = torch.tensor([ # 卷积核
[1, 2, 1],
[0, 1, 0],
[2, 1, 0]
])输入矩阵与卷积核的shape改造为符合卷积神经网络输入的格式,官方文档将其定义为:input – input tensor of shape (minibatch, in_channels, iH,iW)。想想也确实是这么个理,神经网络主要应用与图像处理,对于一个512×512大小的RGB三通道图片,其形状为3×512×512。如果使用DataLoader读取文件,batch_size=64,那么其输入矩阵形状为64×3×512×512。
input = torch.reshape(input, (-1, 1, 5, 5))
kernel = torch.reshape(kernel, (-1, 1, 3, 3))
input.shape, kernel.shape # Reshape
Out[5]: (torch.Size([1, 1, 5, 5]), torch.Size([1, 1, 3, 3]))在卷积层中,滤波器(也称为卷积核或特征检测器)是一组权重数组,它以滑动窗口的方式在图像上进行扫描,计算每一步的点积,并将该点积输出到一个称为特征图的新数组中。这种滑动窗口的扫描称为卷积。让我们看一下这个过程的示例,以帮助理解正在发生的事情。
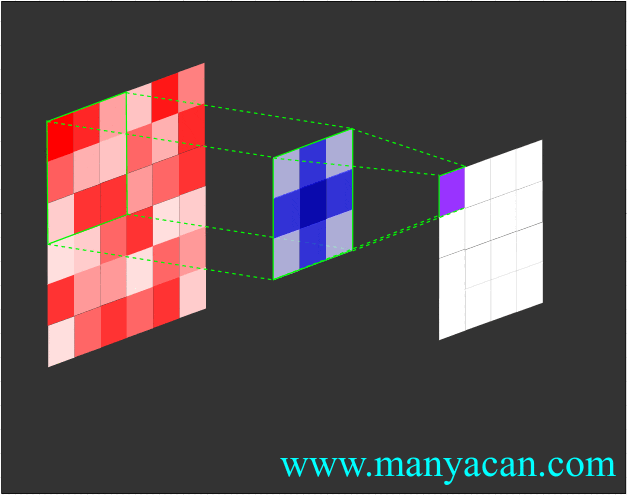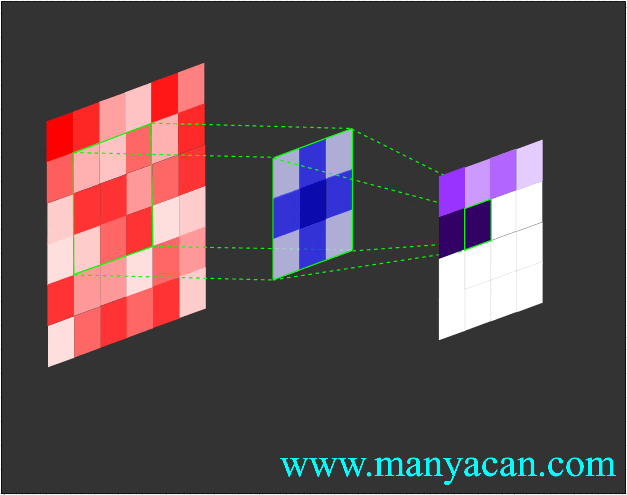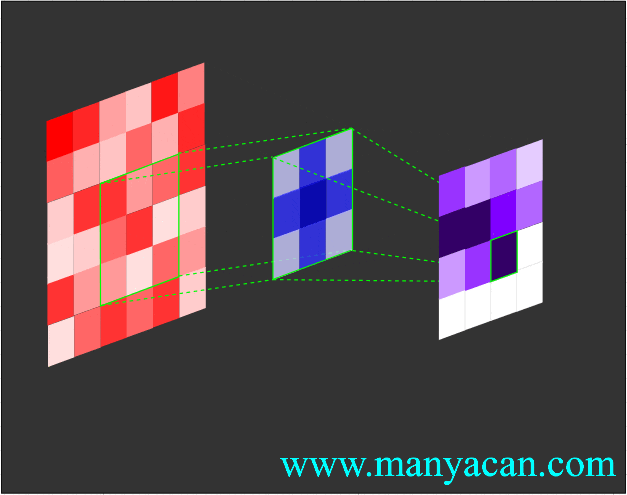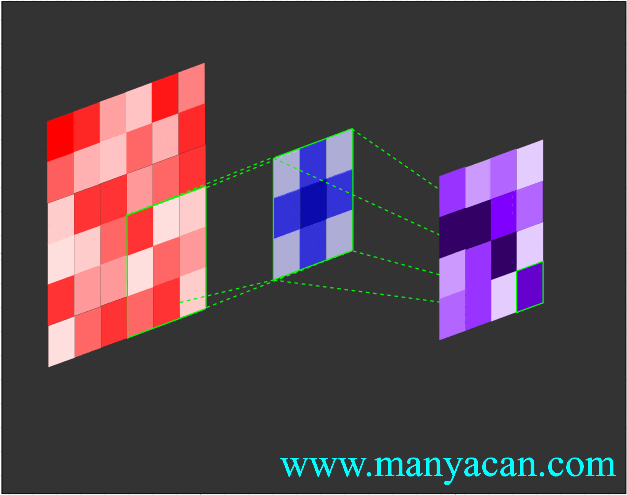
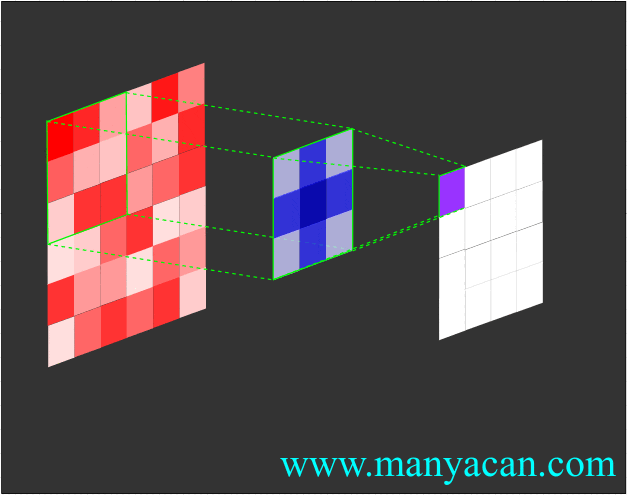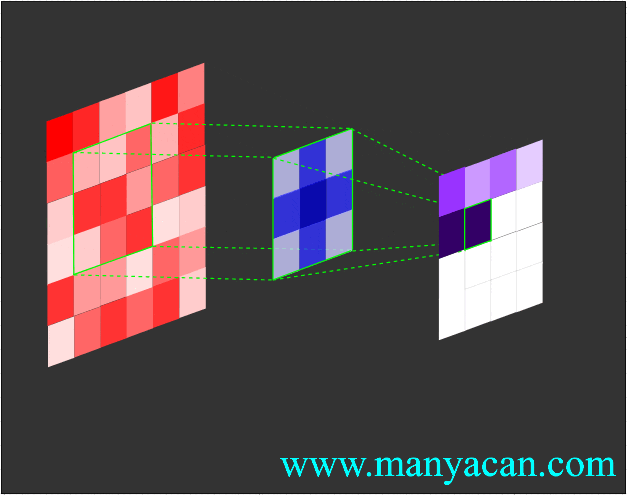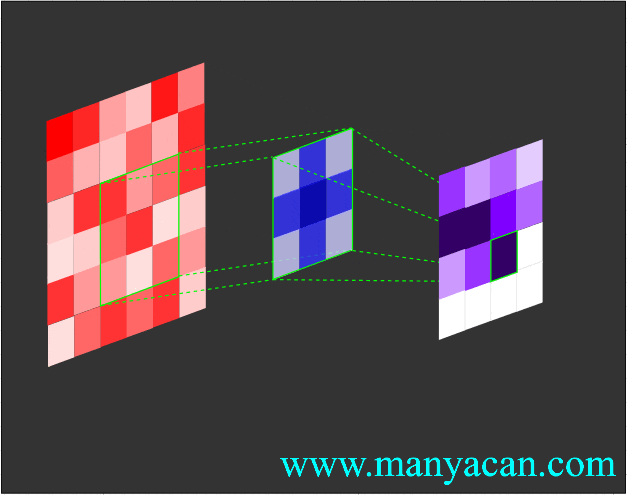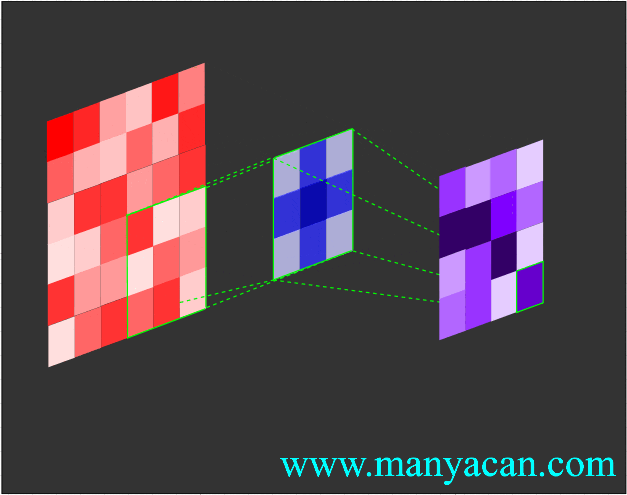
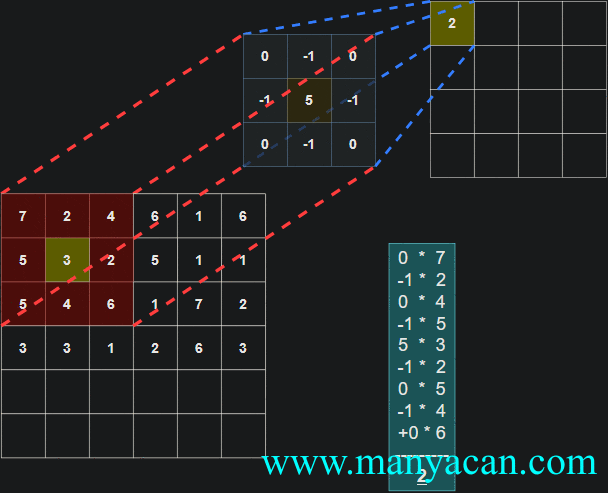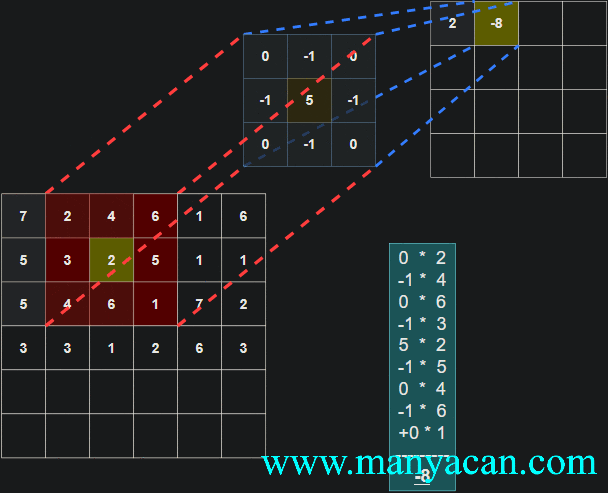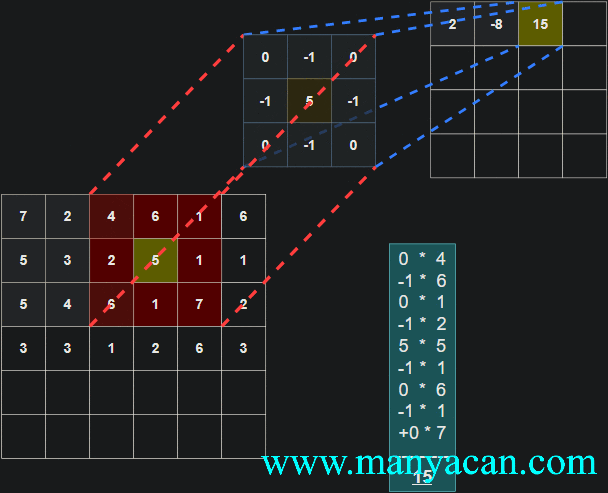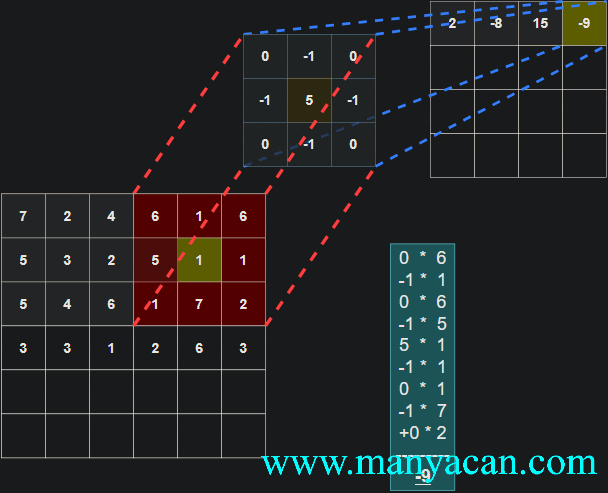
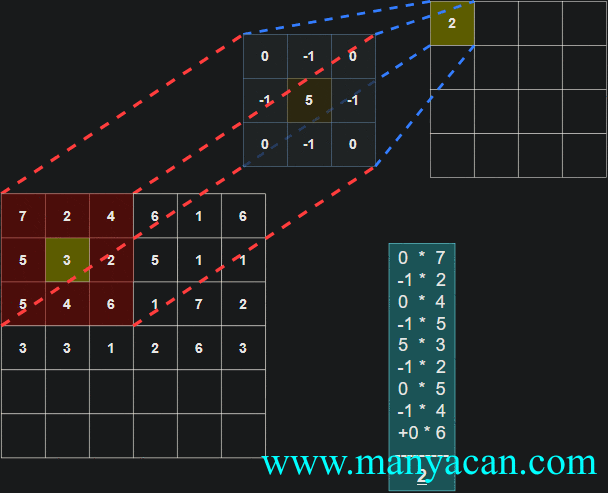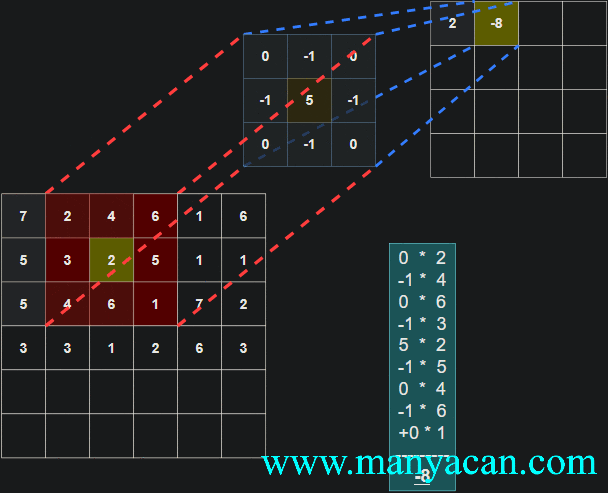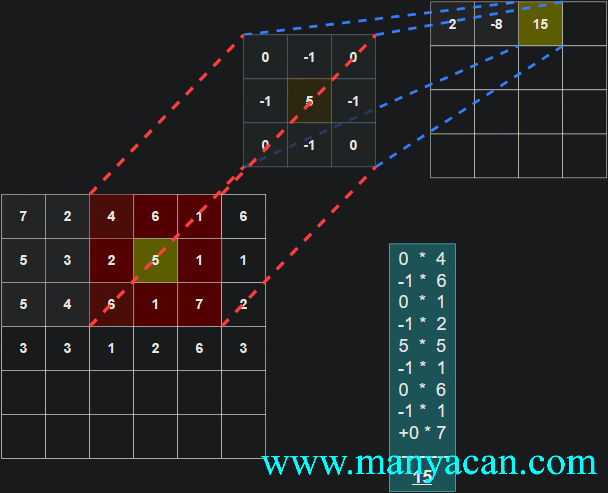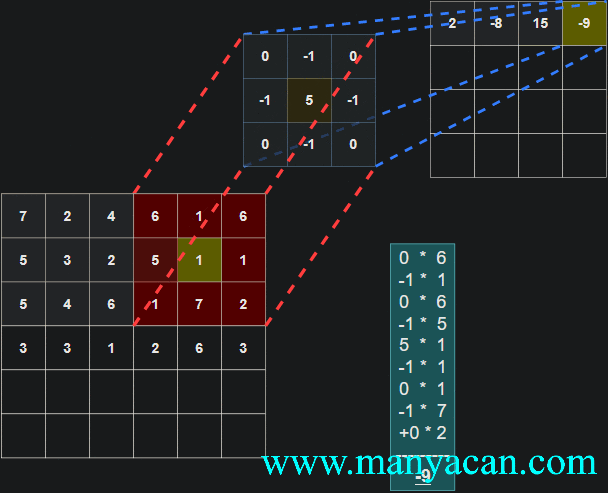
图片
卷积过程的可视化可以参考:Convolution arithmetic。
卷积过程:
import torch.nn.functional as F
F.conv2d(input, kernel)
Out[6]:
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])以卷积结果的第一行第一列的10为例:其计算过程为:
对于一个5×5的矩阵,卷积核步长stride设置为2,使用3×3的卷积核完成一次卷积后的结果是2×2:
F.conv2d(input, kernel, stride=2)
Out[7]:
tensor([[[[10, 12],
[13, 3]]]])padding=1参数为输入矩阵的上下左右周围添加了一圈为0的值,输入矩阵变成了7×7,如下面的input_pad_1所示:
F.conv2d(input, kernel, padding=1)
Out[8]:
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
input_pad_1 = torch.tensor([
[0 for i in range(7)],
[0, 1, 2, 0, 3, 1, 0],
[0, 0, 1, 2, 3, 1, 0],
[0, 1, 2, 1, 0, 0, 0],
[0, 5, 2, 3, 1, 1, 0],
[0, 2, 1, 0, 1, 1, 0],
[0 for i in range(7)]
])
input_pad_1 = torch.reshape(input_pad_1, (-1, 1, 7, 7))
F.conv2d(input_pad_1, kernel) # 与添加padding=1参数后得到了相同的结果
Out[10]:
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])最大池化——MaxPool2d()
池化层与卷积层类似,都是通过滤波器对输入数据(通常是从卷积层输出的特征图)进行卷积运算。
然而,池化层的功能不是特征检测,而是降低维度或降采样。最常用的两种池化方法是最大池化和平均池化。在最大池化中,滤波器在输入上滑动,并在每一步选择具有最大值的像素作为输出。在平均池化中,滤波器输出滤波器所经过像素的平均值。
首先来定义一个用于输入模型的Tensor:
a = torch.tensor([
[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]
], dtype=torch.float32) # 如果不使用float类型,MaxPool2d()将报错:RuntimeError: "max_pool2d" not implemented for 'Long'
a = torch.reshape(a, (-1, 1, 5, 5))
a.shape
Out[11]: torch.Size([1, 1, 5, 5])定义模型:
class MyModule(torch.nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.maxpool_00 = torch.nn.MaxPool2d(
kernel_size=3,
ceil_mode=True # 当卷积核走到最后,发现余下的不够走一步了,是否还继续“强走”
)
def forward(self, input):
output = self.maxpool_00(input)
return output输出结果:
module = MyModule()
module(a)
Out[12]:
tensor([[[[2., 3.],
[5., 1.]]]])卷积输出结果中,第一行第一列的2是a左上角前三行前三列中的最大值。
非线性激活层
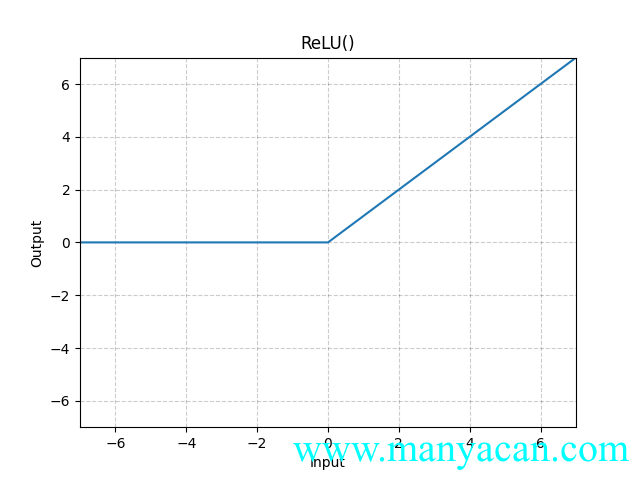
ReLU函数
Sigmoid函数
以ReLU函数为例,当输入小于0时,全部记为0;当输入大于0时,不做处理:
a = torch.tensor([
[0, -.5],
[-1, 3]
])
a = torch.reshape(a, (-1, 1, 2, 2))
a.shape
torch.nn.ReLU()(a)
Out[15]:
tensor([[[[0., 0.],
[0., 3.]]]])串联多个网络层——Sequential
实际操作的神经网络都是十分复杂的,以下面这个基于CIFAR-10数据集的神经网络模型为例:
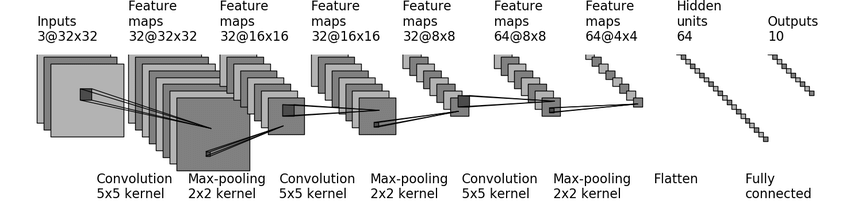
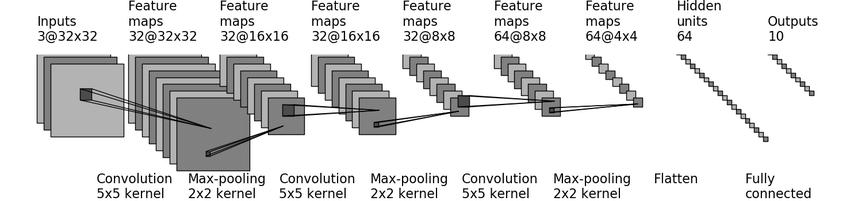
作用非常简单,就是将多个网络层串联到一起,没有使用nn.Sequential()前:
class MyModule(torch.nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.conv_00 = torch.nn.Conv2d(3, 32, 5, padding=2) # Input: 3@32×32, Output: 32@32×32
self.maxpool_00 = torch.nn.MaxPool2d(2) # Input: 32@32×32, Output: 32@16×16
self.conv_01 = torch.nn.Conv2d(32, 32, 5, padding=2) # Input: 32@16×16, Output: 32@16×16
self.maxpool_01 = torch.nn.MaxPool2d(2) # Input: 32@16×16, Output: 32@8×8
self.conv_02 = torch.nn.Conv2d(32, 64, 5, padding=2) # Input: 32@8×8, Output: 64@8×8
self.maxpool_02 = torch.nn.MaxPool2d(2) # Input: 64@8×8, Output: 64@4×4
self.flatten = torch.nn.Flatten() # Input: 64@4×4, Output: 1024
self.linear_00 = torch.nn.Linear(1024, 64) # Input: 1024, Output: 64
self.linear_01 = torch.nn.Linear(64, 10) # Input: 64, Output: 10
def forward(self, inputs):
_ = self.conv_00(inputs)
_ = self.maxpool_00(_)
_ = self.conv_01(_)
_ = self.maxpool_01(_)
_ = self.conv_02(_)
_ = self.maxpool_02(_)
_ = self.flatten(_)
_ = self.linear_00(_)
outputs = self.linear_01(_)
return outputs使用nn.Sequential()后:
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
# 使用Sequential来优化网络结构
class MyModule(torch.nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model = torch.nn.Sequential(
Conv2d(3, 32, 5, padding=2), # Input: 3@32×32, Output: 32@32×32
MaxPool2d(2), # Input: 32@32×32, Output: 32@16×16
Conv2d(32, 32, 5, padding=2), # Input: 32@16×16, Output: 32@16×16
MaxPool2d(2), # Input: 32@16×16, Output: 32@8×8
Conv2d(32, 64, 5, padding=2), # Input: 32@8×8, Output: 64@8×8
MaxPool2d(2), # Input: 64@8×8, Output: 64@4×4
Flatten(), # Input: 64@4×4, Output: 1024
Linear(1024, 64), # Input: 1024, Output: 64
Linear(64, 10) # Input: 64, Output: 10
)
def forward(self, inputs):
outputs = self.model(inputs)
return outputs损失函数
损失函数的作用有两点:
- 计算实际输出和目标之间的差距;
- 为我们更新输出提供一定的依据(反向传播)。
第一点很容易理解,既然叫做了”损失函数“,顾名思义,就是用来计算”损失“的函数,那么这个损失来自哪里呢?假设我们的真实值是y_true,在进行训练的过程中,我们会有一个预测值y_pred。损失函数就是用来描述两者之间的差异的。
以L1损失函数为例:
y_true = torch.tensor([2, 3, 4], dtype=torch.float32)
y_pred = torch.tensor([2, 1, 6], dtype=torch.float32)
torch.nn.L1Loss(reduction='sum')(y_true, y_pred) # ()
Out[18]: tensor(4.)
torch.nn.L1Loss()(y_true, y_pred)
Out[19]: tensor(1.3333)当设置参数reduction='sum'时,相当于:
torch.sum(torch.abs(y_pred - y_true))
Out[20]: tensor(4.)参数为空时,相当于:
torch.sum(torch.abs(y_pred - y_true)) / len(y_true)优化器——optim
优化器的作用是配合Loss函数的输出,进行反向传播,优化模型参数。
optim = torch.optim.SGD(module.parameters(), lr=0.01) # 定义优化器时候,需要传入优化参数与学习率如果出现每一轮训练后,Loss不降反增的情况,请尝试减小学习率。至于为什么会出现这种情况,请参考「Machine Learning」梯度下降。
优化器配合Loss函数进行反向传播优化:
for epoch in range(20):
epoch_loss = 0 # 对每一轮的loss进行累加,观察经过多轮学习后,loss是否有下降
for i, data in enumerate(test_loader):
imgs, targets = data
outputs = module(imgs)
res_loss = loss(outputs, targets)
optim.zero_grad() # 每一次训练前,都需要将上一步的梯度归零
res_loss.backward() # Loss函数反向传播
optim.step() # 优化器更新参数
epoch_loss += res_loss
print(f'第{epoch}轮中的第{i}批数据训练Loss值为:{res_loss.item()}.')
print(f'第{epoch}轮的累积Loss值为:{epoch_loss.item()}.')修改定义好的模型
加载预训练模型
以vgg16模型为例,如何对包内置模型进行修改使用:
import torch
import torchvision
vgg_pretrained = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights.IMAGENET1K_V1)
vgg = torchvision.models.vgg16()vgg_pretrained模型是导入了训练好参数的模型。
vgg_pretrained
Out[4]:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
...
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
...
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)修改模型输出参数
观察模型网络结构可以发现,vgg模型的输出out_features=1000,说明其是针对1000个target进行分类的。
而我们的任务是针对10个target进行分类,因此可以在vgg_pretrained模型的最后再添加一层新的线性层:
vgg_pretrained.add_module('Linear', torch.nn.Linear(1000, 10))
vgg_pretrained
Out[9]:
VGG(
(features): Sequential(
...
)
(avgpool): ...
(classifier): Sequential(
...
)
(Linear): Linear(in_features=1000, out_features=10, bias=True)
)也可以使用:
vgg_pretrained.classifier.add_module('Linear', torch.nn.Linear(1000, 10))
vgg_pretrained
Out[12]:
VGG(
(features): Sequential(
...
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
...
(Linear): Linear(in_features=1000, out_features=10, bias=True)
)
)观察两种添加方式有何不同。
除此之外,我们还可以对最后一层输出的进行修改,将最后一个线性层的out_features=1000改为out_features=10:
vgg.classifier[6] = torch.nn.Linear(4096, 10)
vgg
Out[13]:
VGG(
(features): Sequential(
...
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
...
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)至此,就完成了对VGG16模型的修改,已经可以在我们自己的数据集上面使用。
训练结果展示
一次完美的训练过程:Loss逐渐下降、准确度逐渐上升。
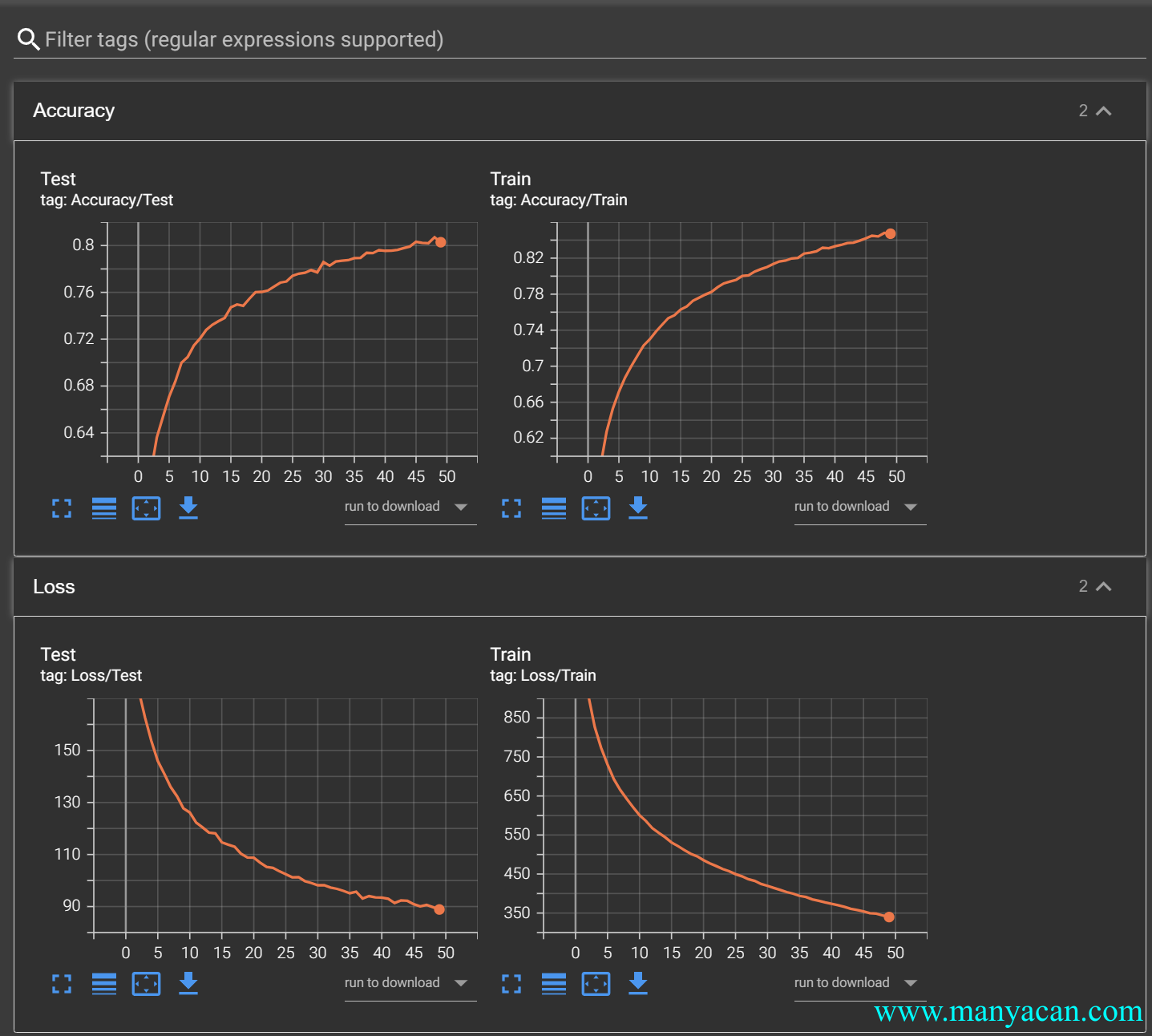
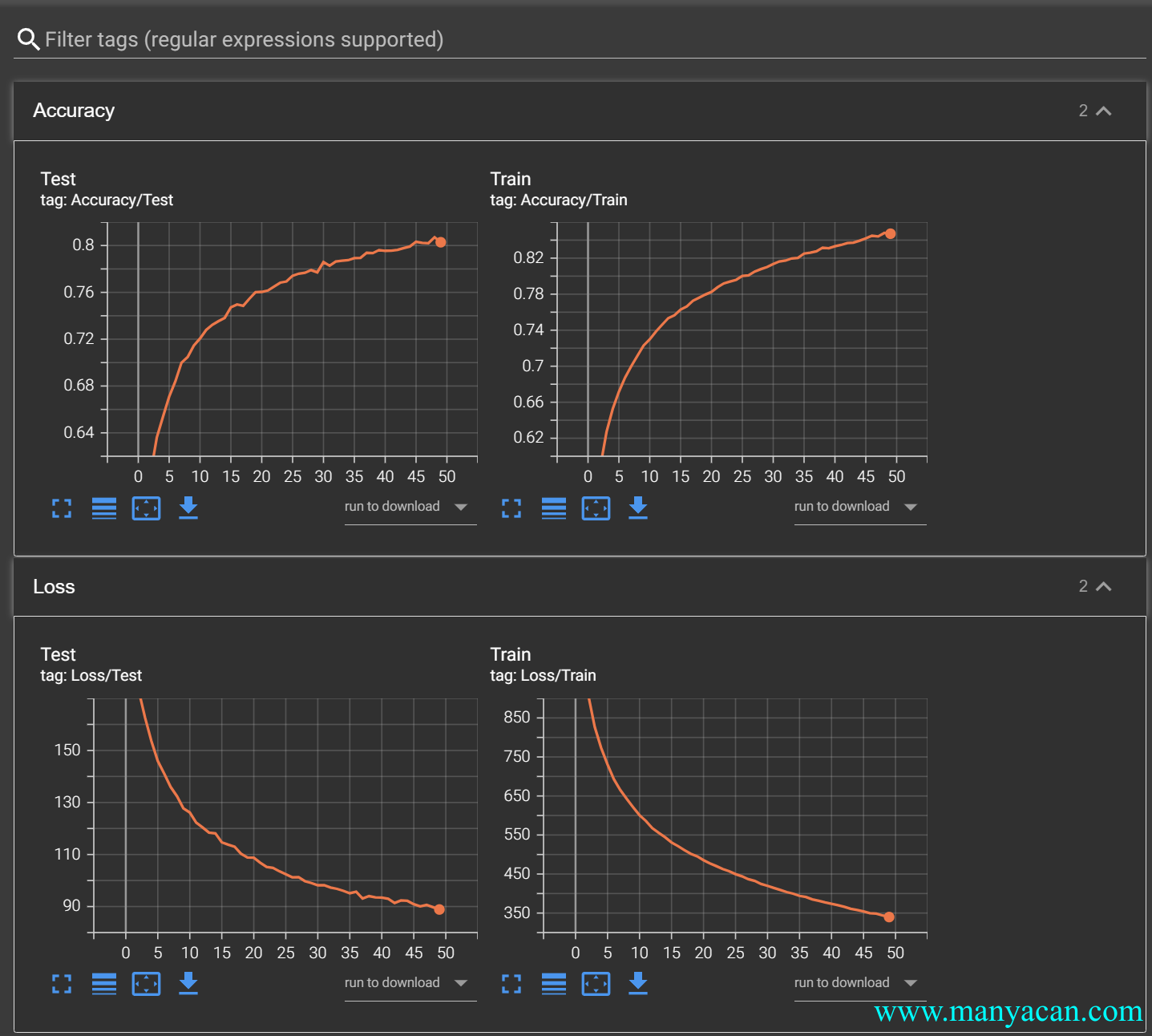
模型的保存与加载
保存模型结构+模型参数
torch.save(vgg_pretrained,'SavedModule.pth')模型的加载:
# 模型的加载
model = torch.load('./SavedModule.pth')只保留模型参数
torch.save(vgg_pretrained.state_dict(), 'SavedStateDict.pth')模型的加载:
model = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights.IMAGENET1K_V1)
model.classifier.add_module('Linear', torch.nn.Linear(1000, 10))
model.load_state_dict(torch.load('SavedStateDict.pth'))
model注意:这种保存方式是官方所推荐的,可以显著减小模型文件的体积。但是加载模型的时候,需要先引入模型,如果模型的结构有所修改,也要进行修改后才可以传入保存的模型参数。
使用GPU进行训练
CUDA的安装
PyTorch必须要借助于CUDA才可以使用Nvidia显卡对模型进行训练,因此必须先安装CUDA,具体的安装过程参考:「深度学习」PyTorch笔记-01-基础知识。
数据转移到GPU
使用GPU完成训练过程,必须将模型、损失函数、输入数据转移到GPU中。
第一种转移方式
模型的转移:
# 创建网络模型
module = MyModule()
# 在GPU上训练模型
if torch.cuda.is_available():
print('GPU is available in this computer.')
module.cuda()损失函数的转移:
# 损失函数
loss_fun = CrossEntropyLoss()
if torch.cuda.is_available():
# 转移到GPU上
loss_fun.cuda()训练/测试数据的转移:
# 检验当前模型在测试集上的效果
# module.eval() # 参考module.train()
with torch.no_grad(): # 在测试集上检验效果,不需要进行梯度下降优化
for i, data in enumerate(test_loader):
imgs, targets = data
# 将数据转移到GPU
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()第二种转移方式
第一种转移方式每次都需要经过if判断,不够高效。一般都使用第二种:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 将模型转移到GPU上
module.to(device)
...
# 将损失函数转移到GPU上
loss_fun.to(device)
...
# 将数据转移到GPU上
imgs = imgs.to(device)
targets = targets.to(device)使用Google colab
大厂还是大厂哇,Google colab为所有用户提供了一周30个小时免费时长高性能服务器。
首先打开Google colab,点击左上角New Notebook。
之后就会进入一个在线版的Jupyter Book。
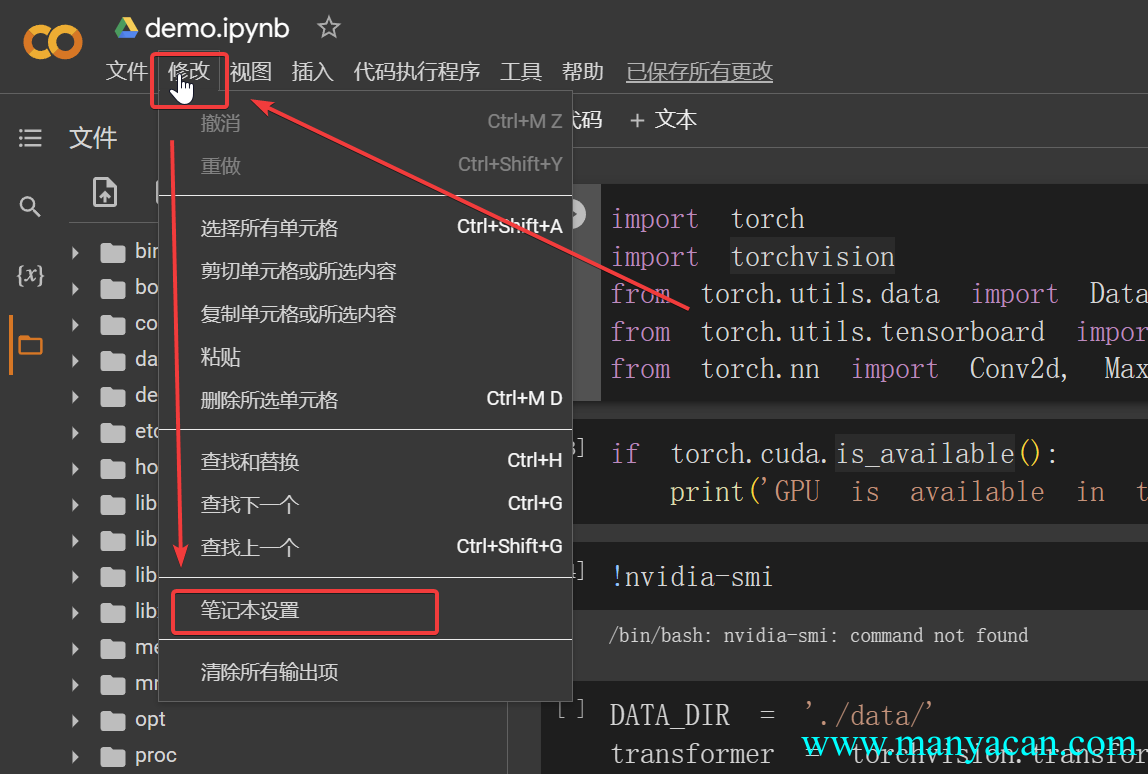
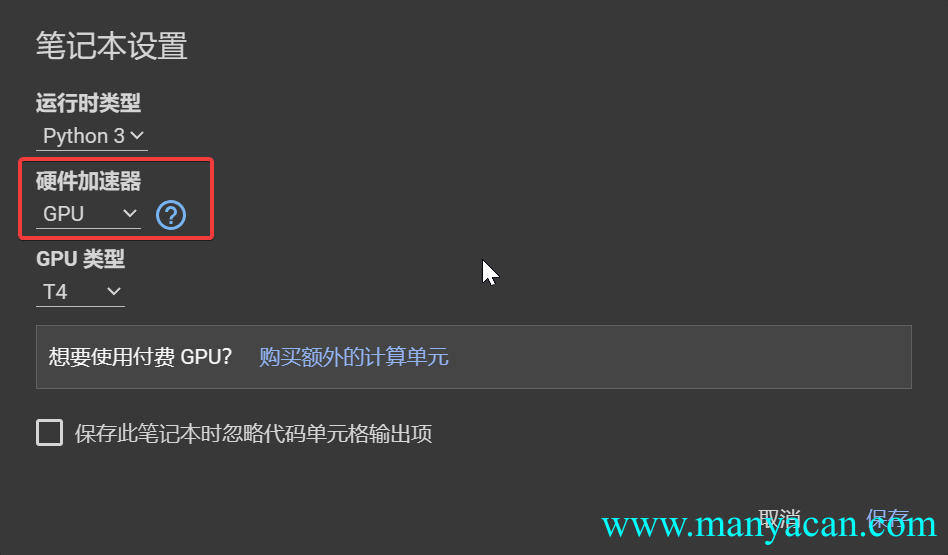
默认下是未开启GPU运算的,需要点击修改,然后点击笔记本设置。
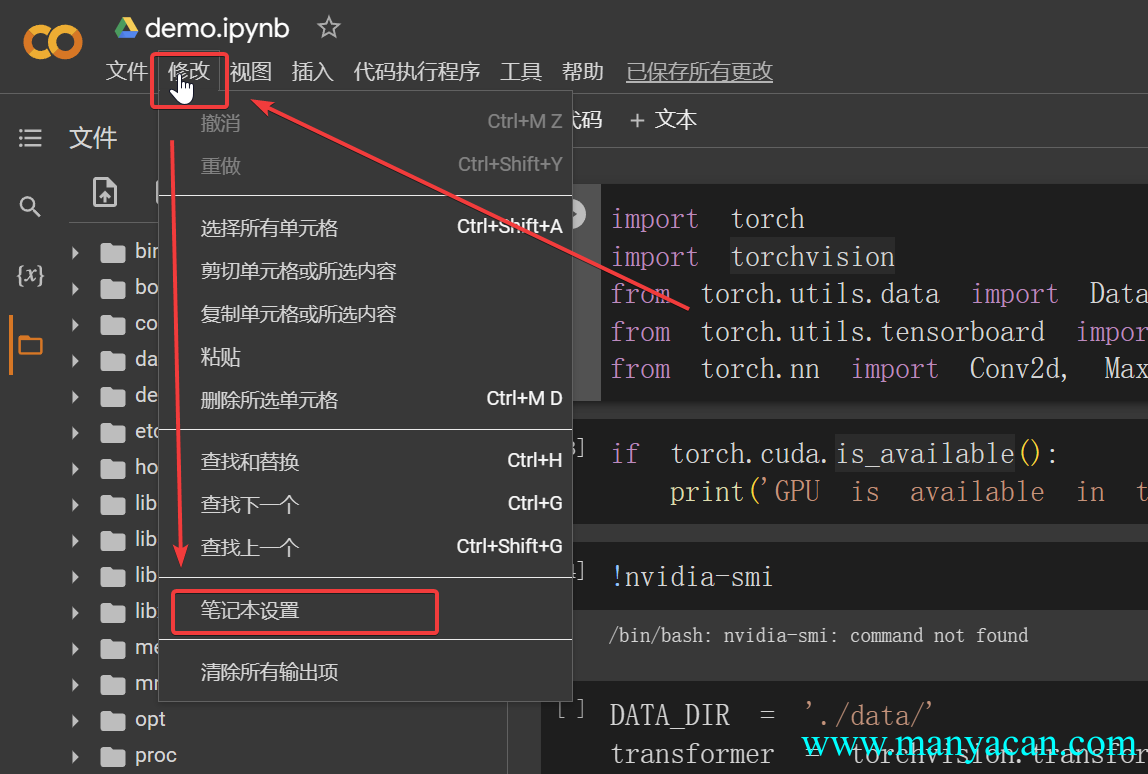
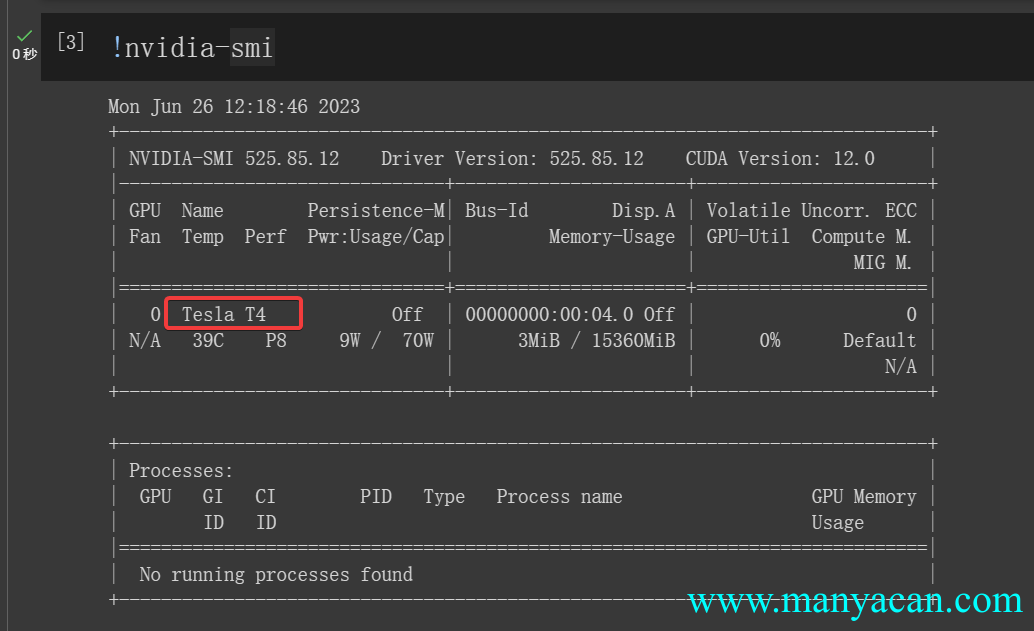
然后开启GPU加速即可。发现提供的硬件加速GPU是Tesla T4。
完整的模型训练套路
文件的读取
分别使用两张照片来测试模型效果:


dogs


plane
from PIL import Image
dog_img_path = './data/dog.png'
plane_img_path = './data/plane.png'
dog_img = Image.open(dog_img_path)
plane_img = Image.open(plane_img_path)
dog_img = dog_img.convert('RGB')
plane_img = plane_img.convert('RGB')
dog_img.show()
plane_img.show()PNG图片格式是4个通道,除了RGB三通道外,还有一个透明度通道。所以,我们调用image = image.convert('RGB')保留其颜色通道。当然,一如果图片本来就是三个颜色通道,经过此操作不变。
文件格式的转换
读取的文件格式在输入模型前,需要根据模型的input要求进行变换:
transformer = torchvision.transforms.Compose([
torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()
])
dog_img = transformer(dog_img) # 改变图片尺寸大小
plane_img = transformer(plane_img)
plane_img.shape
dog_img = torch.reshape(dog_img, (1, 3, 32, 32)) # 将图片Tensor改变为模型input的要求
plane_img = torch.reshape(plane_img, (1, 3, 32, 32)) 加载模型
model = torch.load('../14-ModifiedModule/SavedModule.pth')注意,在使用torch.load()读取训练好的模型之前,必须先导入模型的类!!!
还有个注意点,读取的模型之前是在GPU上训练好的,而现在想要传入模型的数据image则是在CPU中,如果直接传入模型进行训练,会报错:
BUGS / 报错 RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same or input should be a MKLDNN tensor and weight is a dense tensor.
这个时候有两种解决方案:
- 将模型读取到CPU中,在CPU中完成运算;
- 将想要传入模型的数据
image转入到GPU中,在GPU中完成运算。
第一张方法需要在读取模型时加入参数:
model = torch.load('../15-CompleteTrainingProcess/module/module_19.pth', map_location=torch.device('cpu'))第二种方法:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
image = image.to(device)测试数据并输出结果
预测修🐕图像的结果为5,正确!
# 测试模型效果
model.eval()
with torch.no_grad():
output = model(dog_img)
print(torch.argmax(output)) # 输出预测概率最大的target,tensor(5, device='cuda:0')预测✈的图像结果为0,正确!
# 测试模型效果
model.eval()
with torch.no_grad():
output = model(plane_img)
print(torch.argmax(output))

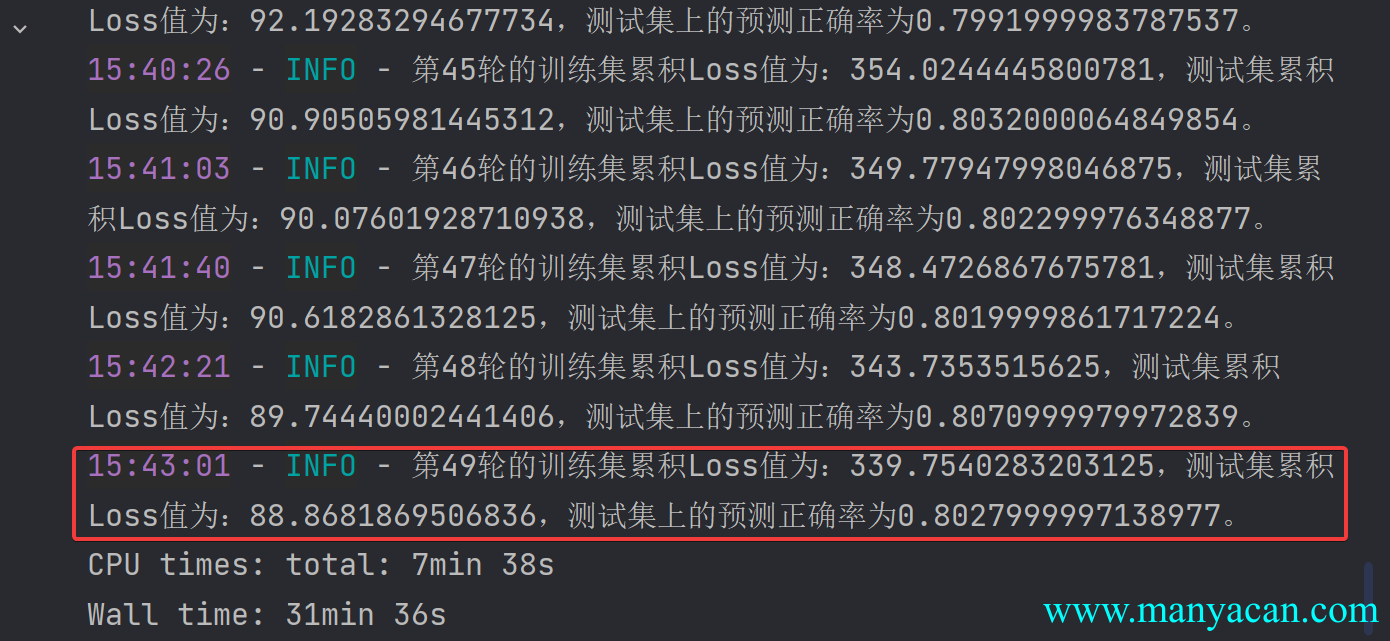
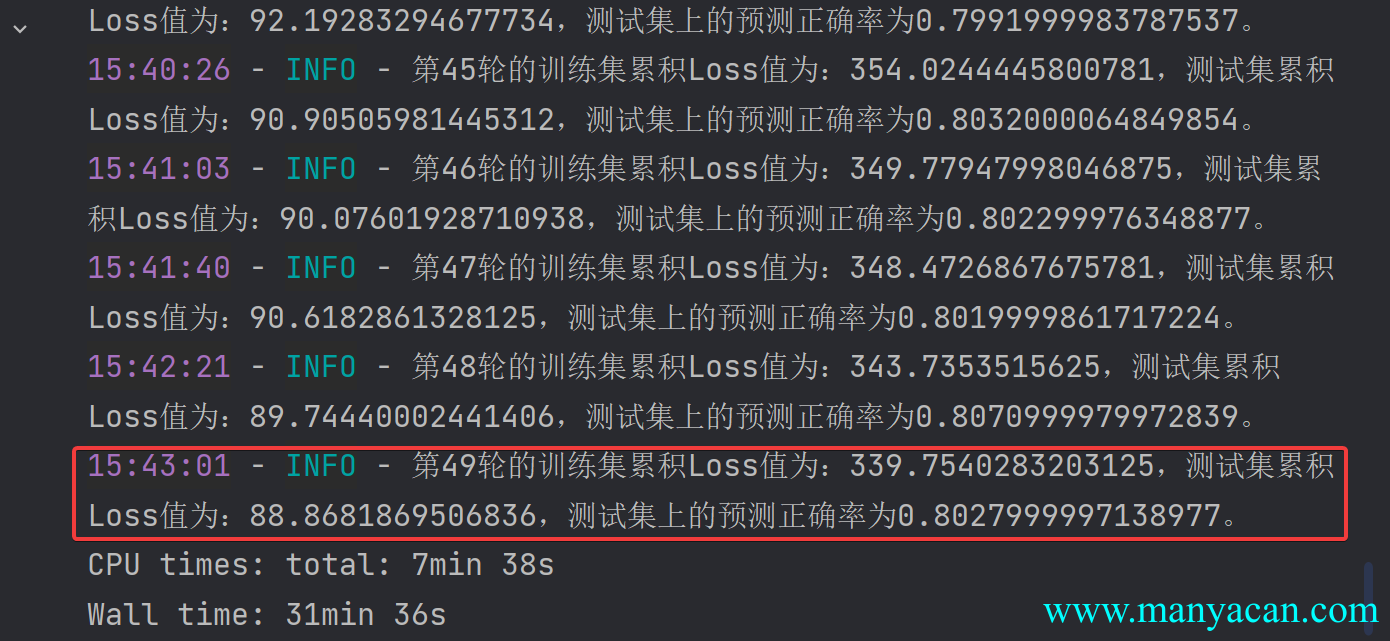
也不奇怪,之前所保存的模型经过50轮的学习后,在测试集上面的预测正确率已经可以达到80%以上。
----- END -----
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-06-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号