Llama2.c 学习笔记5: custom tokenizer
原创
Llama2.c 学习笔记5: custom tokenizer
原创
flavorfan
发布于 2023-08-18 16:29:08
发布于 2023-08-18 16:29:08
Follow新兴热门Github repo最让人兴奋的是:看着它从幼稚朝着成熟(神奇)发展,这个发展很快肉眼可见,神奇如昙花开放,但又在你理解范围之内(当前的知识储备加上搜一搜能够理解每一个修改的目的和神奇)。与之相反的是记忆中的被支配高数课,开课还是有条不紊,捡个笔的功夫再抬头已是二世为人。
1. 自定义标记符(Custom Tokenizer)
自定义标记符()对定制的特定领域 LLM 非常有用,因为较小的词汇表大小可以使模型更小、更快,而且可能更有能力。
如果开放私有的LLM小型应用程序,最好还是训练自己的标记符。这可以让一切变得更好--使用更小的词汇表,模型参数会更少(因为标记嵌入表会小得多),推理会更快(因为需要预测的标记会更少),每个示例的平均序列长度也会变小(因为对数据的压缩会更有效)。这样做的结果也更 "安全",因为训练有素的模型不会意外地输出一些随机的汉字,并在随后的标记中迅速 "脱轨"。
2. 训练自定义标记符的步骤
1)准备
作者使用google/sentencepiece来训练,python的库可以用下列指令安装
pip install sentencepiece==0.1.99但是使用了sentencepiece的命令行工具需要编译源码
git clone https://github.com/google/sentencepiece.git
cd sentencepiece/
ll
mkdir build
cd build/
cmake ..
make -j 8
make install如果找不到链接库,还需要修改/etc/ld.so.conf,添加下列地址
/usr/local/lib642)训练标记符
python tinystories.py train_vocab --vocab_size=4096
python tinystories.py pretokenize --vocab_size=4096train_vocab 指令会调用 "train_vocab.sh "脚本,该脚本会调用 "sentencepiece "库来训练标记化器,并将其存储在新文件 "data/tok4096.model "中。它使用字节对编码算法(Byte Pair Encoding algorithm),从文本数据的原始 utf8 字节序列开始,然后迭代合并最常见的连续标记对来形成词汇。
3)使用自定义标记符训练模型
python train.py --vocab_source=custom --vocab_size=4096 --device=cpu --batch_size=32 --eval_iters=5 --compile=False资源贫瘠,用最简的参数跑起来,验证代码能够工作。
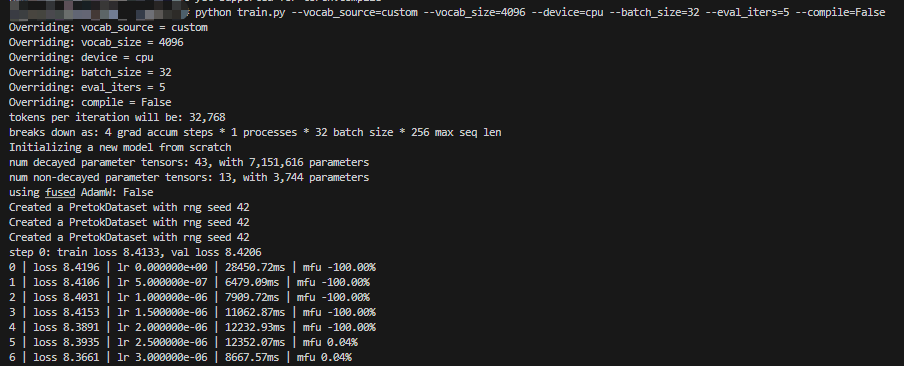
3. 模型及训练的对应修改
tokenizer修改,影响模型embedding的维度
1)run.c
添加对tokenizer的路径的参数的支持,参考笔记4: run.c分析,读取这个.bin文件初始化TransformerWeights中token_embedding_table。
-z <string> optional path to custom tokenizer2)train.py
参数方面添加了
vocab_source = "llama2" # llama2|custom; use Lllama 2 vocab from Meta, or custom trained
vocab_size = 32000 #模型参数vocab_size从固定32000改为参数配置的vocab_size
model_args = dict(
dim=dim,
n_layers=n_layers,
n_heads=n_heads,
n_kv_heads=n_heads,
vocab_size=vocab_size,
multiple_of=multiple_of,
max_seq_len=max_seq_len,
dropout=dropout,
) # start with model_args from command line4. 使用自定义标记符进行Infer
将model文件转为bin文件
python tokenizer.py --tokenizer-model=data/tok4096.model需要重新编译run.c,且使用自定义标记符运行
./run out/model.bin -z data/tok4096.bin由于缺乏算力资源,这部分验证还未进行。
其他
使用自有数据、自定义标记符是定制的窄域 LLM 非常有用的技术,技术拼图又完善了一块。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号