图解Spark Graphx实现顶点关联邻接顶点的collectNeighbors函数原理
原创
图解Spark Graphx实现顶点关联邻接顶点的collectNeighbors函数原理
原创
朱季谦
修改于 2023-09-02 12:05:19
修改于 2023-09-02 12:05:19

原创/朱季谦
一、场景案例
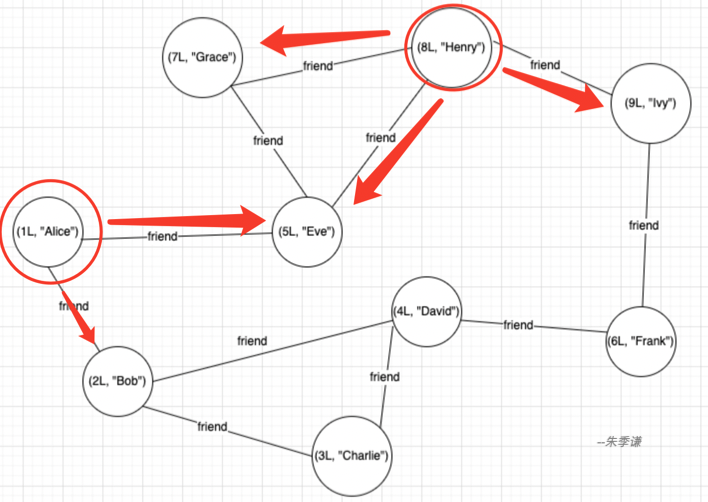
在一张社区网络里,可能需要查询出各个顶点邻接关联的顶点集合,类似查询某个人关系比较近的都有哪些人的场景。
在用Spark graphx中,通过函数collectNeighbors便可以获取到源顶点邻接顶点的数据。
下面以一个例子来说明,首先,先基于顶点集和边来创建一个Graph图。

该图的顶点集合为——
(1L, "Alice"),
(2L, "Bob"),
(3L, "Charlie"),
(4L, "David"),
(5L, "Eve"),
(6L, "Frank"),
(7L, "Grace"),
(8L, "Henry"),
(9L, "Ivy")边的集合为——
Edge(1L, 2L, "friend"),
Edge(1L, 5L, "friend"),
Edge(2L, 3L, "friend"),
Edge(2L, 4L, "friend"),
Edge(3L, 4L, "friend"),
Edge(4L, 6L, "friend"),
Edge(5L, 7L, "friend"),
Edge(5L, 8L, "friend"),
Edge(6L, 9L, "friend"),
Edge(7L, 8L, "friend"),
Edge(8L, 9L, "friend")基于以上顶点和边,分别建立一个顶点RDD 和边RDD,然后通过Graph(vertices, edges, defaultVertex)创建一个Graph图,代码如下——
val conf = new SparkConf().setMaster("local[*]").setAppName("graphx")
val ss = SparkSession.builder().config(conf).getOrCreate()
// 创建顶点RDD
val vertices = ss.sparkContext.parallelize(Seq(
(1L, "Alice"),
(2L, "Bob"),
(3L, "Charlie"),
(4L, "David"),
(5L, "Eve"),
(6L, "Frank"),
(7L, "Grace"),
(8L, "Henry"),
(9L, "Ivy")
))
// 创建边RDD
val edges = ss.sparkContext.parallelize(Seq(
Edge(1L, 2L, "friend"),
Edge(1L, 5L, "friend"),
Edge(2L, 3L, "friend"),
Edge(2L, 4L, "friend"),
Edge(3L, 4L, "friend"),
Edge(4L, 6L, "friend"),
Edge(5L, 7L, "friend"),
Edge(5L, 8L, "friend"),
Edge(6L, 9L, "friend"),
Edge(7L, 8L, "friend"),
Edge(8L, 9L, "friend")
))
val graph = Graph(vertices, edges, null)在成功创建图之后,就可以基于已有的图,通过collectNeighbors方法,分别得到每个顶点关联邻接顶点的数据——
val neighborVertexs = graph.mapVertices{
case (id,(label)) => (label)
}.collectNeighbors(EdgeDirection.Either)最终得到的neighborVertexs是一个VertexRDD[Array[(VertexId, VD)]]类型的RDD,可以通过neighborVertexs.foreach(println)打印观察一下,发现数据里,是每一个【顶点,元组】的结构,注意看,大概就能猜出来,通过neighborVertexs得到的RDD其实就是每个顶点关联了邻接顶点集合元组的数据——
(5,[Lscala.Tuple2;@bb793d7)
(8,[Lscala.Tuple2;@6d5786e6)
(1,[Lscala.Tuple2;@398cb9ea)
(9,[Lscala.Tuple2;@61c4eeb2)
(2,[Lscala.Tuple2;@d7d0256)
(6,[Lscala.Tuple2;@538f0156)
(7,[Lscala.Tuple2;@77a17e3d)
(3,[Lscala.Tuple2;@1be2a4fb)
(4,[Lscala.Tuple2;@1e0153f9)可以进一步验证,将元组里的数据进行展开打印,通过以下代码进行验证——先通过coalesce(1)将分区设置为一个分区,多个分区打印难以确定打印顺序。然后再通过foreach遍历RDD里每一个元素,这里的元素结构如(5,[Lscala.Tuple2;@bb793d7),x._1表示是顶点5,x._2表示[Lscala.Tuple2;@bb793d7,既然是元组,那就可以进一步进行遍历打印,即 x._2.foreach(y => {...})——
neighborVertexs.coalesce(1).foreach(x => {
print("顶点:" + x._1 + "关联的邻居顶点集合->{" )
var str = "";
x._2.foreach(y => {
str += y + ","})
print(str.substring(0, str.length - 1 ) +"}")
println()
})可以观察一下最后打印结果——
顶点:8关联的邻居顶点集合->{(5,Eve),(7,Grace),(9,Ivy)}
顶点:1关联的邻居顶点集合->{(2,Bob),(5,Eve)}
顶点:9关联的邻居顶点集合->{(6,Frank),(8,Henry)}
顶点:2关联的邻居顶点集合->{(1,Alice),(3,Charlie),(4,David)}
顶点:3关联的邻居顶点集合->{(2,Bob),(4,David)}
顶点:4关联的邻居顶点集合->{(2,Bob),(3,Charlie),(6,Frank)}
顶点:5关联的邻居顶点集合->{(1,Alice),(7,Grace),(8,Henry)}
顶点:6关联的邻居顶点集合->{(4,David),(9,Ivy)}
顶点:7关联的邻居顶点集合->{(5,Eve),(8,Henry)}结合文章开始的那一个图验证一下,顶点1关联的邻接顶点是(2,Bob),(5,Eve),正确;顶点8关联的邻接顶点是(5,Eve),(7,Grace),(9,Ivy),正确。其他验证都与下图情况符合。可见,通过collectNeighbors(EdgeDirection.Either)确实可以获取网络里每个顶点关联邻接顶点的数据。
二、函数代码原理解析
以上就是顶点关联邻接顶点的用法案例,接下来,让我们分析一下collectNeighbors(EdgeDirection.Either)源码,该函数实现了收集顶点邻居顶点的信息——
def collectNeighbors(edgeDirection: EdgeDirection): VertexRDD[Array[(VertexId, VD)]] = {
val nbrs = edgeDirection match {
//聚合本顶点出度指向的邻居顶点和入度指向本顶点的邻居顶点
case EdgeDirection.Either =>
graph.aggregateMessages[Array[(VertexId, VD)]](
ctx => {
ctx.sendToSrc(Array((ctx.dstId, ctx.dstAttr)))
ctx.sendToDst(Array((ctx.srcId, ctx.srcAttr)))
},
(a, b) => a ++ b, TripletFields.All)
//聚合本顶点出度指向的邻居顶点
case EdgeDirection.In =>
graph.aggregateMessages[Array[(VertexId, VD)]](
ctx => ctx.sendToDst(Array((ctx.srcId, ctx.srcAttr))),
(a, b) => a ++ b, TripletFields.Src)
//聚合入度指向本顶点的邻居顶点
case EdgeDirection.Out =>
graph.aggregateMessages[Array[(VertexId, VD)]](
ctx => ctx.sendToSrc(Array((ctx.dstId, ctx.dstAttr))),
(a, b) => a ++ b, TripletFields.Dst)
case EdgeDirection.Both =>
throw new SparkException("collectEdges does not support EdgeDirection.Both. Use" +
"EdgeDirection.Either instead.")
}
graph.vertices.leftJoin(nbrs) { (vid, vdata, nbrsOpt) =>
nbrsOpt.getOrElse(Array.empty[(VertexId, VD)])
}
} // end of collectNeighbor该函数用match做了一个类似Java的switch匹配,匹配有四种结果,其中,最后一种EdgeDirection.Both已经不支持,故而这里就不解读了,只讲仍然有用的三种。
用一个图来说明吧,假如有以下边指向的图——
Edge(2L, 1L), Edge(2L, 4L), Edge(3L, 2L), Edge(2L, 5L),
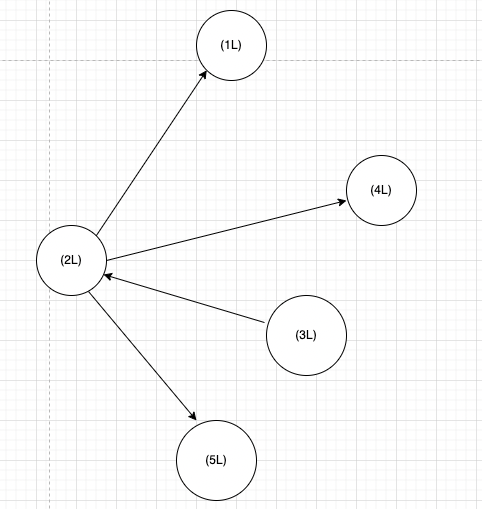
- EdgeDirection.Either表示本顶点的出度邻居和入度邻居。若本顶点为2,那么它得到邻居顶点包括(1,4,3,5),该参数表示只要与顶点2一度边关联的,都会聚集成邻居顶点。
- EdgeDirection.In表示指向本顶点的邻居,即本顶点的入度邻居。若本顶点为2,图里邻居顶点只有3是指向2的,那么顶点2得到邻居顶点包括(3)。
- EdgeDirection.Out表示本顶点的出度指向的邻居顶点。若本顶点为2,图里从顶点2指向邻居顶点的,将得到(1,4,5)。
由此可知,顶点关联邻居顶点的函数collectNeighbors(EdgeDirection.Either)里面的参数,就是可以基于该参数得到不同情况的邻居顶点。
这里以collectNeighbors(EdgeDirection.Either)说明函数核心逻辑——
graph.aggregateMessages[Array[(VertexId, VD)]](
ctx => {
ctx.sendToSrc(Array((ctx.dstId, ctx.dstAttr)))
ctx.sendToDst(Array((ctx.srcId, ctx.srcAttr)))
},
(a, b) => a ++ b, TripletFields.All)该代码做了聚合,表示会对图里的所有边做处理。
图里有一种边结构,叫三元组(Triplet),这种结构由以下三个部分组成——
- 源顶点(Source Vertex):图中的一条边的起始点或源节点。
- 目标顶点(Destination Vertex):图中的一条边的结束点或目标节点。
- 边属性(Edge Attribute):连接源顶点和目标顶点之间的边上的属性值。
在graph.aggregateMessages[Array[(VertexId, VD)]]( ctx => {......})聚合函数里,就是基于三元组去做聚合统计的。
该聚合函数有两个参数,第一个参数是一个函数(ctx) => { ... },里面定义了每个顶点如何发送消息给邻居顶点。
注意看,这里的ctx正是一个三元组对象,基于该对象,可以获取一下信息——
ctx.srcId:获取源顶点的ID。ctx.srcAttr:获取源顶点的属性。ctx.dstId:获取目标顶点的ID。ctx.dstAttr:获取目标顶点的属性。
ctx作为一个知道源顶点、目标顶点的三元组对象,就像一个邮差一样,负责给两边顶点发送消息。
1、ctx.sendToSrc(Array((ctx.dstId, ctx.dstAttr)))函数,这里顶点A是作为目标顶点,邻居节点B是源顶点,ctx对象就会将目标顶点B的顶点ID和属性组成的元组(ctx.dstId, ctx.dstAttr)当作消息传给源顶点A,A会将收到的消息保存下来,这样就知道EdgeDirection.Either无向边情况下,它有一个邻居B了。
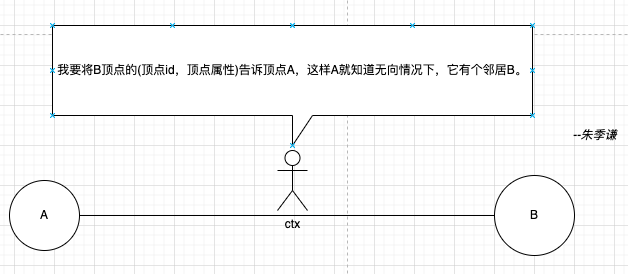
2、 ctx.sendToDst(Array((ctx.srcId, ctx.srcAttr)))函数,这时A成为了源顶点,C成为了目标顶点,ctx对象就会将源顶点A的顶点ID和属性组成的元组(ctx.dstId, ctx.dstAttr)当作消息传给源顶点B。B会将收到的消息以数组格式Array((ctx.dstId, ctx.dstAttr))保存下来,这样B以后就知道EdgeDirection.Either无向边情况下,它有一个邻居A了。

这里ctx.sendToDst()用Array((ctx.dstId, ctx.dstAttr))数组形式发送,是方便后面的(a, b) => a ++ b 合并函数操作,最后每个顶点可以将它收到的邻居顶点数组合并到一个大的数组,即所有邻居顶点聚集到一个数组里返回。
还有一个TripletFields枚举需要了解下——
TripletFields.All表示本顶点将聚合包括源顶点以及目标顶点发送顶点消息。
TripletFields.Src表示本顶点只聚合源顶点发送过来的顶点消息。
TripletFields.Dst表示本顶点只聚合目标顶点发送过来的顶点消息。
EdgeDirection.Either参数对应的是TripletFields.All,表示需要将本顶点接收到的所有源顶点以及目标顶点发送的顶点消息进行聚合。
接下来,就是做聚合了——
整个图里会有许多类似邮差角色的ctx对象,只需要处理完这些对象,那么,每个顶点就会收到通过ctx对象传送过来的邻居顶点信息。
例如,A收到的ctx对象发过来的邻居消息如下——
Array((B,属性))
Array((C,属性))
Array((D,属性))
......
这时,就可以基于顶点A作为分组key,将组内的Array((B,属性))、Array((C,属性))、Array((D,属性))都合并到一个组里,即通过(a, b) => a ++ b将分组各个数据合并成一个大数组{(B,属性),(C,属性),(D,属性)},这个分组group的key是收到各个ctx对象发送邻居消息过来的顶点A。
各个顶点聚合完后,返回一个nbrs,该RDD的每一个元素,即(顶点,顶点属性,Array(邻居顶点))——
val nbrs = edgeDirection match {
case EdgeDirection.Either =>
graph.aggregateMessages[Array[(VertexId, VD)]](
ctx => {
ctx.sendToSrc(Array((ctx.dstId, ctx.dstAttr)))
ctx.sendToDst(Array((ctx.srcId, ctx.srcAttr)))
},
(a, b) => a ++ b, TripletFields.All)
......
}接着将原图graph的顶点vertices的rdd与聚合结果nbrs做左连接,返回一个新的 VertexRDD 对象,其中每个顶点都附带了它的邻居信息。如果某个顶点没有邻居信息(在 nbrs 中不存在对应的条目),则使用空数组来表示它的邻居。
graph.vertices.leftJoin(nbrs) { (vid, vdata, nbrsOpt) =>
nbrsOpt.getOrElse(Array.empty[(VertexId, VD)])
}最后,得到的顶点关联邻居顶点的RDD情况,就如前文打印的那样——
(5,[Lscala.Tuple2;@bb793d7) 顶点5展开邻居顶点=> 顶点:5关联的邻居顶点集合->{(1,Alice),(7,Grace),(8,Henry)} (8,[Lscala.Tuple2;@6d5786e6) 顶点8展开邻居顶点=> 顶点:8关联的邻居顶点集合->{(5,Eve),(7,Grace),(9,Ivy)} (1,[Lscala.Tuple2;@398cb9ea) 顶点1展开邻居顶点=> 顶点:1关联的邻居顶点集合->{(2,Bob),(5,Eve)} (9,[Lscala.Tuple2;@61c4eeb2) 顶点9展开邻居顶点=> 顶点:9关联的邻居顶点集合->{(6,Frank),(8,Henry)} (2,[Lscala.Tuple2;@d7d0256) 顶点2展开邻居顶点=> 顶点:2关联的邻居顶点集合->{(1,Alice),(3,Charlie),(4,David)} (6,[Lscala.Tuple2;@538f0156) 顶点6展开邻居顶点=> 顶点:6关联的邻居顶点集合->{(4,David),(9,Ivy)} (7,[Lscala.Tuple2;@77a17e3d) 顶点7展开邻居顶点=> 顶点:7关联的邻居顶点集合->{(5,Eve),(8,Henry)} (3,[Lscala.Tuple2;@1be2a4fb) 顶点3展开邻居顶点=> 顶点:3关联的邻居顶点集合->{(2,Bob),(4,David)} (4,[Lscala.Tuple2;@1e0153f9) 顶点4展开邻居顶点=> 顶点:4关联的邻居顶点集合->{(2,Bob),(3,Charlie),(6,Frank)}

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号