83. 三维重建18-立体匹配14,端到端立体匹配深度学习网络之特征计算

83. 三维重建18-立体匹配14,端到端立体匹配深度学习网络之特征计算

HawkWang
发布于 2023-09-01 10:06:37
发布于 2023-09-01 10:06:37
我在上两篇文章81. 三维重建16-立体匹配12,深度学习立体匹配之 MC-CNN和82. 三维重建17-立体匹配13,深度学习立体匹配的基本网络结构和变种中,给大家介绍了人们从传统立体匹配算法,初次进入深度学习的世界时,所构建的一系列基础的深度学习立体匹配算法。这些算法的共同之处都是从传统算法管线中吸取经验,将某一个或多个模块用深度学习方法来替代,比如很多算法把特征提取这一块用深度学习来取代,取得了不错的效果。但通常它们都并非是端到端的,有一些重要的模块还需要用传统算法来实现,例如得到代价立方体后需要进行代价立方体的正则化优化时,很多算法采用传统的MRF、或扫描线优化等方式来实现。由于这些算法脱胎自传统算法,所以如果你学过我之前讲过的传统立体匹配算法的流程,你会很容易理解它们。
但是,这样的算法缺点也很明显。它们只是替换了整个立体匹配流程中的一部分,其它部分依旧是传统算法。这就导致它们即便相比纯传统算法的效果有所提升,但提升程度也有上限。一些传统立体匹配算法固有的问题,例如弱纹理、重复纹理区域的匹配问题,视差遮挡时的匹配问题等等,这些算法依然不会有很好的结果。而且,由于没有全链路端到端的计算,也就使得很难利用深度学习时代各种优化手段去提升运算性能,这就使得这些算法在计算速度上也有短板。
所以,人们自然而然的就想到,是否可以用端到端的方式,用深度学习网络来完成整个立体匹配算法呢?这也就是我今天开始的几篇文章要给大家介绍的内容。今天的文章大量参考引用了参考文献[1],再次对作者表示敬意!
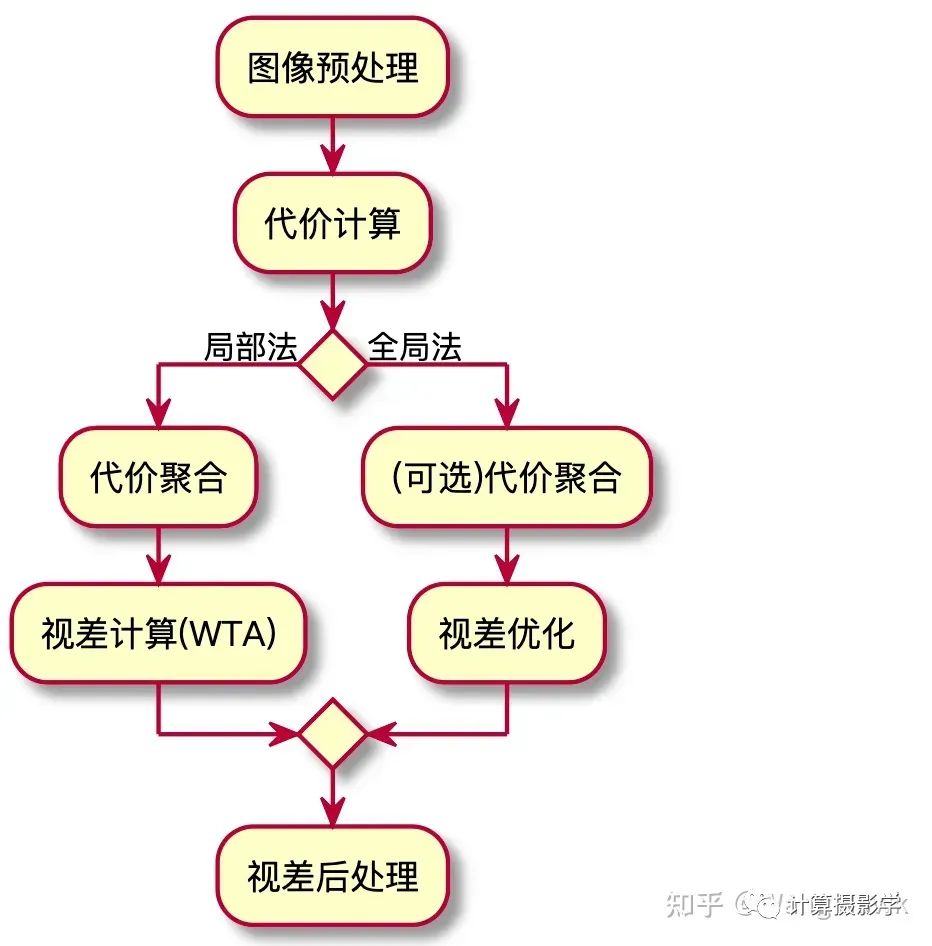
在开始之前,让我们再度看一看我们的学习地图,看看你在哪里。如果你没有看过我之前的文章,或者已经遗忘了之前的部分,别忘了往回头看看我之前的文章哦~
一. 端到端的立体匹配算法的思想
端到端的立体匹配算法,本身也分为两大流派。第一类方法简单粗犷,首先将输入的左视图和右视图在通道上连接起来。如果输入图像是3通道彩色图像,那么我们将得到一个6维的张量。然后,这类方法通常会构造一个Encoder-Decoder结构的网络,然后再利用输入的Ground Truth视差图,直接进行硬回归。如果成功的话,就会得到一个运算效率很高的网络,因为不需要进行额外的特征提取、匹配、代价优化等过程。那么,这类网络有什么缺点呢?有经验的读者一定能看出来,这个网络结构里面有很多参数,因此就需要大量的带有Ground Truth Disparity的图像对去训练它——而这通常是很困难的。你可以参看我之前提到的几篇文章,了解立体匹配数据集的详细情况。总的来说,这类方法全靠优质的数据撑起来。
- 74. 三维重建9-立体匹配5,解析MiddleBurry立体匹配数据集
- 75. 三维重建10-立体匹配6,解析KITTI立体匹配数据集
- 76. 三维重建11-立体匹配7,解析合成数据集和工具
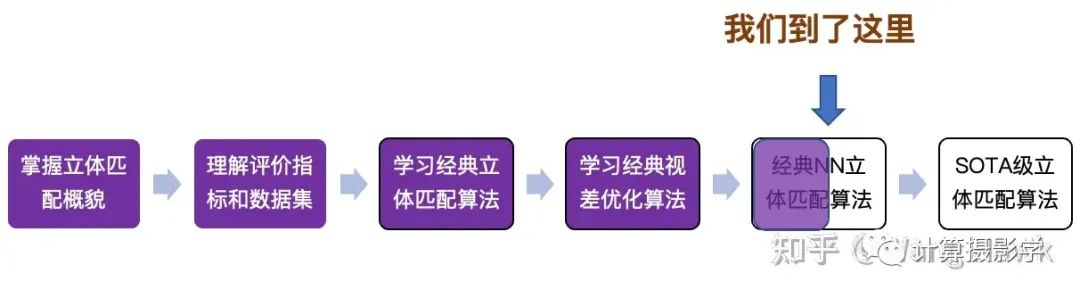
另外一类方法,也是我重点想要介绍的,则是把整个立体匹配流程依然像传统算法一样分为多个阶段。所不同的是,每一阶段都用可以微分的函数来实现,这就使得它们可以参与反向传播优化,也就使得整个立体匹配可以用端到端的深度学习网络来实现,下面就是网络经过拆解后的各个组件,而我今天重点讲解的是特征学习这个部分。
二. 端到端立体匹配网络之特征学习
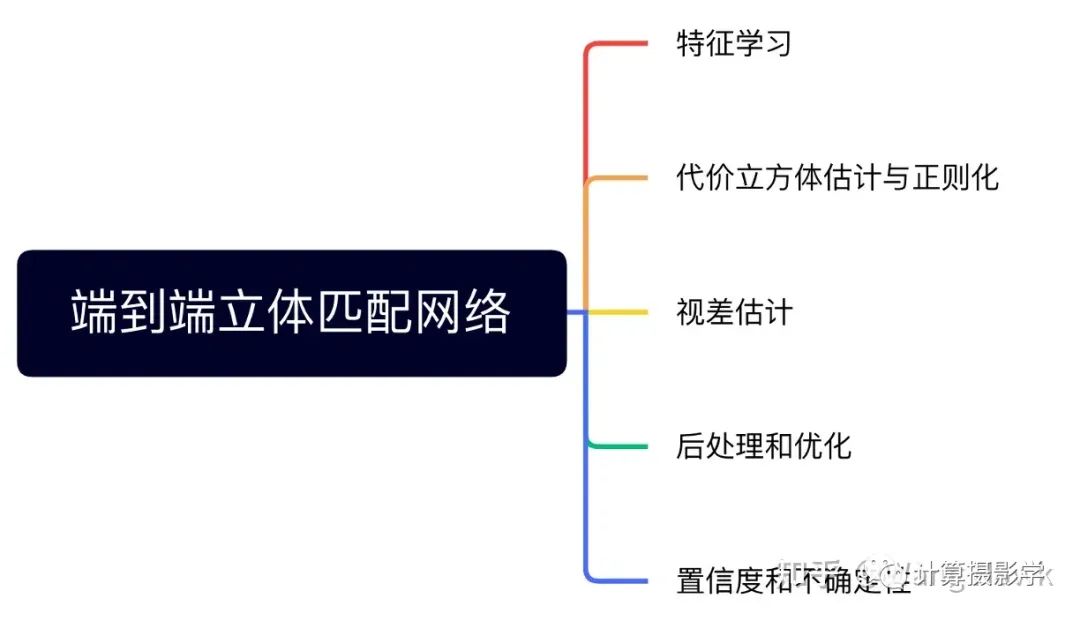
在文章82. 三维重建17-立体匹配13,深度学习立体匹配的基本网络结构和变种中,我们看到了各种各样的基础网络的变种:
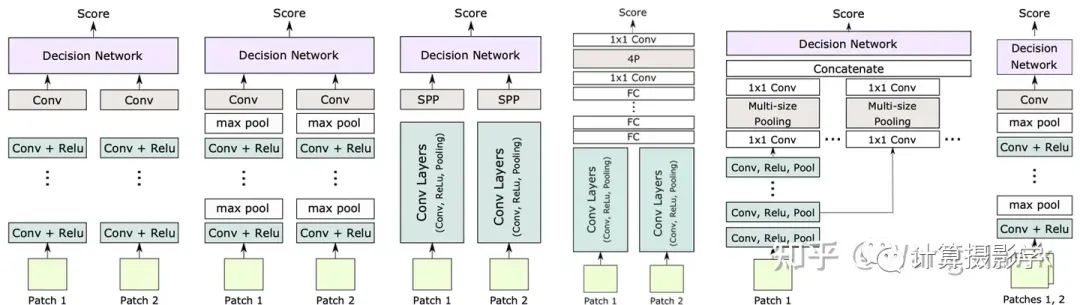
端到端的立体匹配网络的特征学习部分,也采用了非常类似的网络结构。只不过,我们之前看到的网络通常是针对一个个的Patch进行特征提取和匹配。而端到端的立体匹配网络,在特征提取时则是对整个图像进行一次前向推理,得到特征图。特征图的分辨率通常低于输入图像(也有相等的),它将会参与后面的匹配计算。
这里面,有两种策略,我们分为两节来描述。
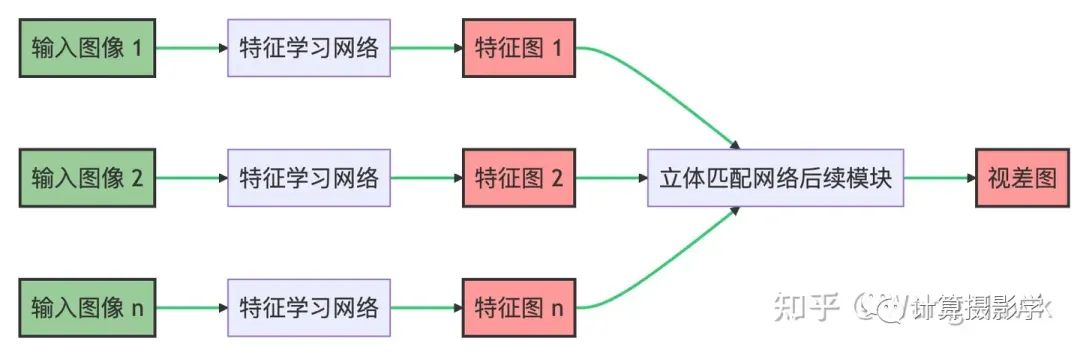
第一种:每个图像一个分支,每个分支产生对应的特征图,如下图所示。这种结构允许输入多个视角的图像进行匹配,如果是我们这里关心的双目立体匹配,那么n就是2。这些特征图整合起来送入后续的立体匹配子网络,最后输出视差图。
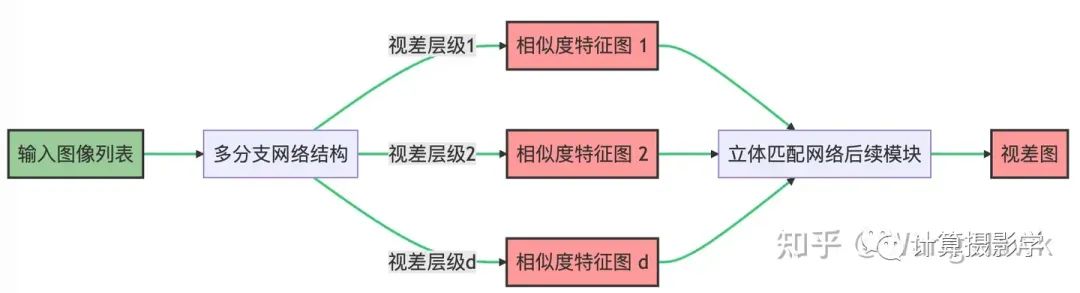
第二种:每个视差层级一个分支。对每一个分支,利用当前视差层级的信息对输入的图像做变换,并进行匹配得到相应的衡量相似度的特征图(或匹配代价特征图)。同样,这里得到的相似度特征图整合起来送入后续的立体匹配子网络,最后输出视差图,如下图所示
无论是哪种结构,特征提取网络一般都会采用常规的全卷积神经网络结构,例如VGG、ResNet等等,这在计算机视觉的其他领域也几乎都是标配,立体匹配网络也概莫能外。为了在有限的算力消耗下获取更多的全局上下文信息,还可以采用我在上一篇文章中提到过的空洞卷积和多尺度学习等方案。
让我们来看一些例子吧。
2.1 每个输入图像一个分支,每个分支产生自己的特征图
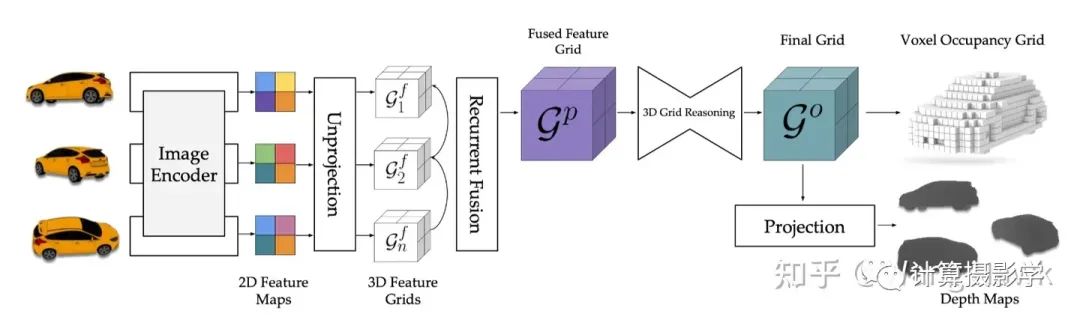
我们先看一个例子,2017年Abhishek Kar等人发表的Learning a Multi-View Stereo Machine。作者们提出了一种基于学习的多视角立体感知系统。与现有的3D重建学习方法不同,他们通过特征在观察光线上的投影和反投影,充分利用了问题的底层3D几何性质。通过以可微的方式形式化这些操作,作者能够从头到尾学习这个系统,以进行可度量的3D重建。作者提出的网络结构如下所示,我们可以明显看到网络对每个视觉的图像都计算了对应的2D和3D的特征图,并被用作后续的计算过程中。在计算2D特征图时,作者直接采用了UNet,这使得既能提取到图像的深层特征,又能够利用浅层的特征。
2017年,Alex Kendall等人在CVPR上发表的End-to-End Learning of Geometry and Context for Deep Stereo Regression中提出了一种新的立体匹配网络,用于从校正后的立体图像对回归视差。他们利用问题的几何知识,使用深度特征表示形成一个代价立方体,并在这个代价立方体上用3D卷积来整合上下文信息,并最终回归出视差值,这使得他们能够以亚像素精度进行端到端训练,而无需任何额外的后处理或正则化,作者提出的网络结构如下图所示:
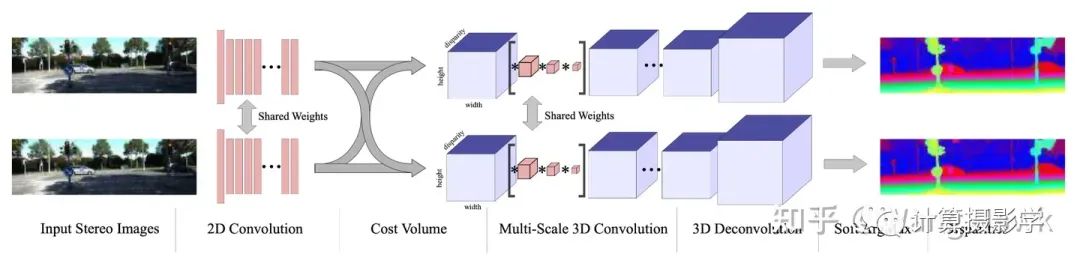
用于特征提取的网络的信息如下表所示,网络在不同的输入图像之间共享权重。

2018年,Liang Zhengfa等人在CVPR上提出了一种整合立体匹配所有步骤的网络架构。该网络首先计算多尺度共享特征,然后利用这些特征估算初始视差。接着,它测量输入图像间对应关系的正确性,对初始视差进行优化。这种方法在Scene Flow和KITTI数据集上表现优异,实现了当时最先进的性能,同时运行速度非常快。我们来看看作者们给出的网络结构。很明显,这就是符合我们所说的每个图像一个分支的网络结构,特征提取网络在每个分支之间共享权重。
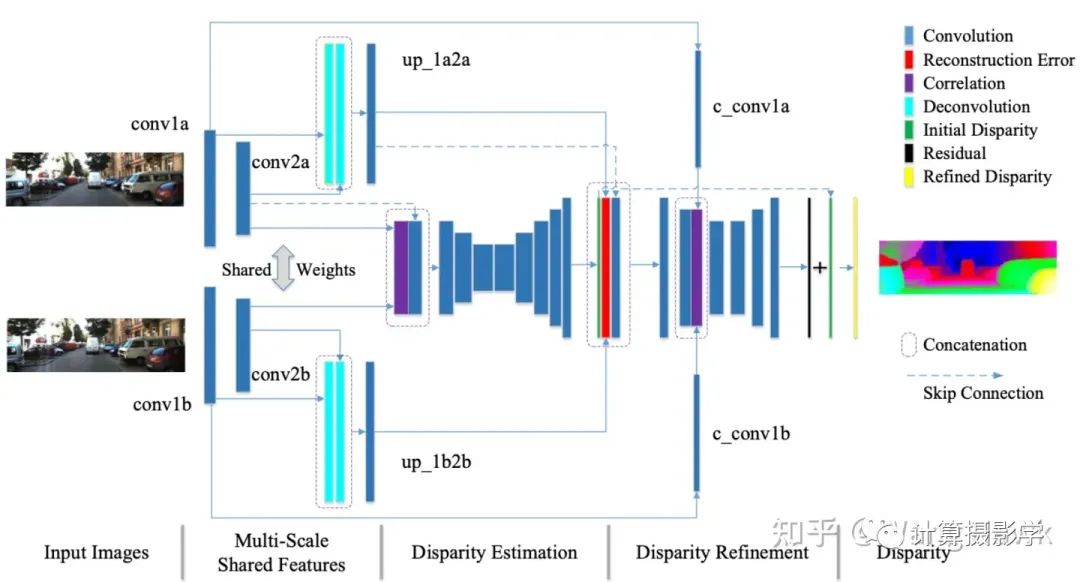
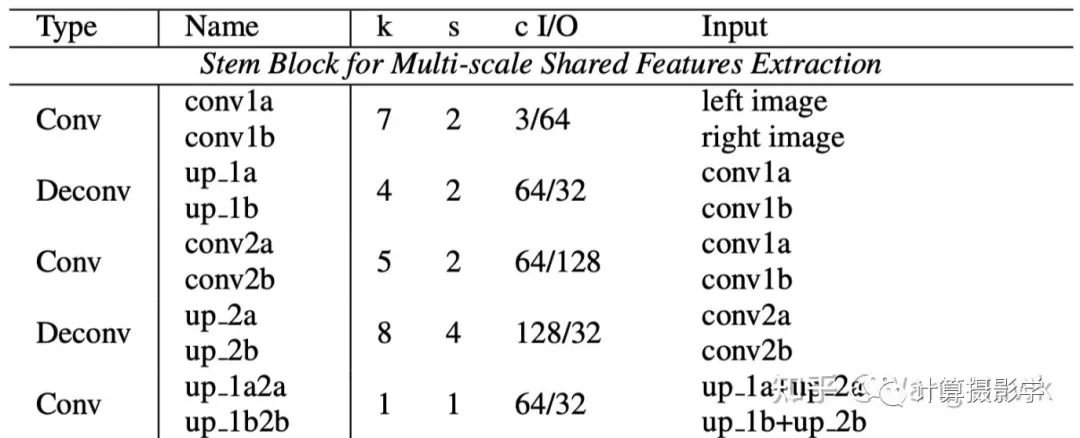
作者提出的多尺度共享特征提取子网络的信息如下, 看起来是比较简洁的
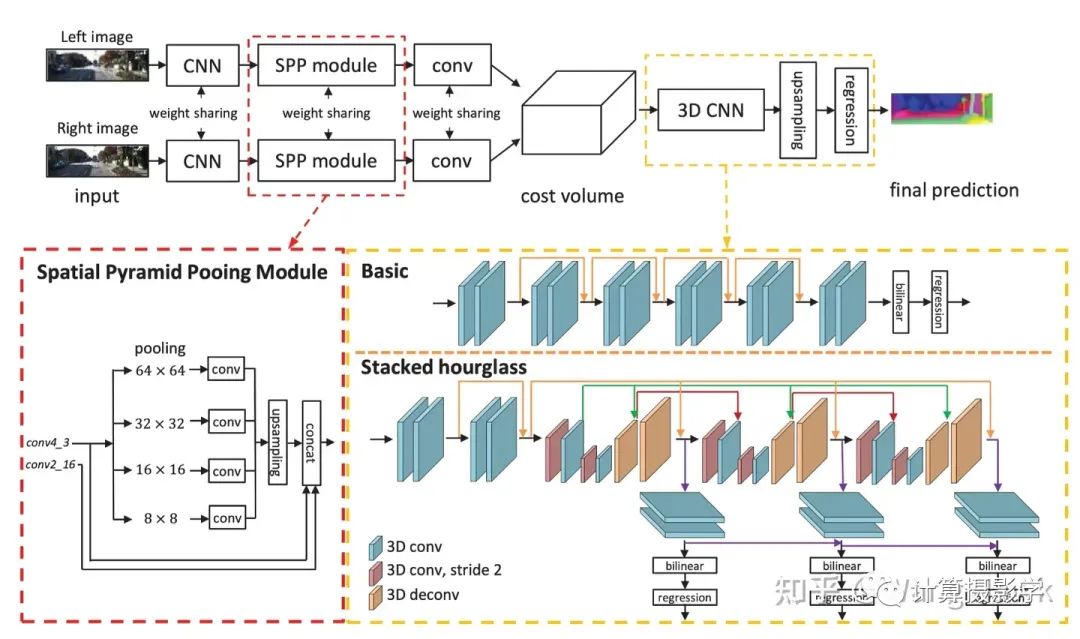
2018年时,Chang Jia-Ren等在CVPR上发表的文章Pyramid Stereo Matching Network提出了一种使用空间金字塔池化和3D CNN两个主要模块的金字塔立体匹配网络。PSMNet的架构总览如下,这里面左右输入的图像被输入到两个权重共享的分支中,每个分支包含一个用于计算特征图的CNN,一个通过拼接不同大小子区域信息的SPP模块用于收集特征,以及一个用于特征融合的卷积层。然后,这些特征被用来形成一个4D的代价体,这个代价体被送入一个3D CNN子网络中,进行代价体的的正则化,并最终回归计算出特征。这里我们也能从图上清晰的看出,每个输入图对应着自己的特征图。
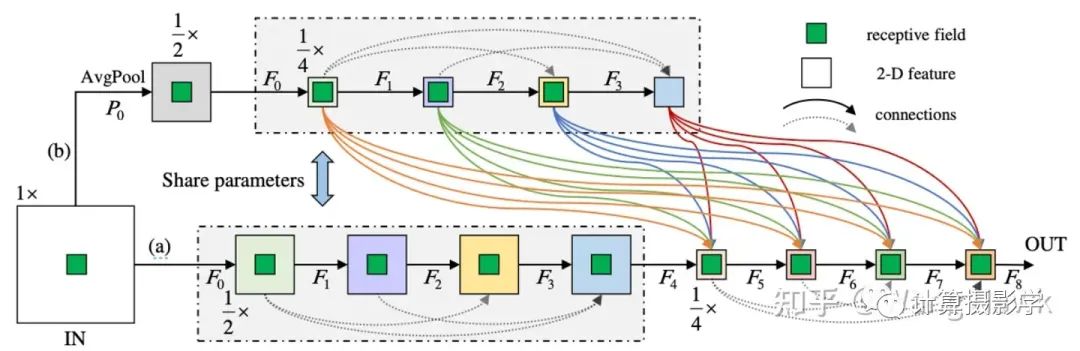
2019年,Nie Guang-Yu等人在CVPR上的文章Multi-Level Context Ultra-Aggregation for Stereo Matching发展金字塔立体匹配网络的思想。他们发展了一种新的技术,名为多级上下文超聚合(MCUA),它可以将来自不同层次的信息合并起来,形成一个更强大、更有区分性的特征描述。MCUA被添加到Cheng Jia-Ren等人提出的PSM-Net中,能够把更多的上下文信息考虑进来,使得立体匹配的精度得到了显著的提高。这种方法在多个测试中都表现出色,比当时的最先进的方法都有更好的性能。我们来看看网络结构:
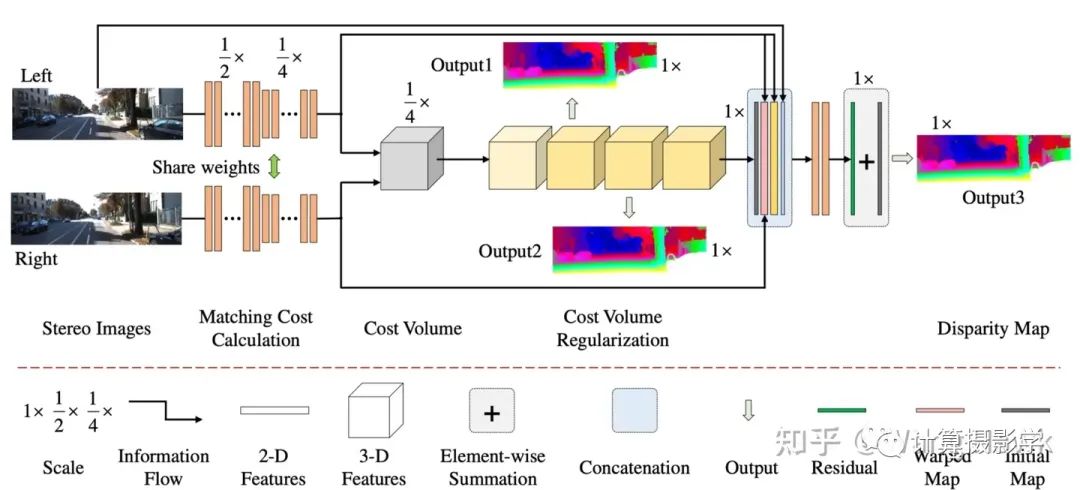
这种方法将所有的卷积特征通过内部和间级特征的组合,封装成一个更具区分性的表示。通过简单的浅层跳跃连接,它将最浅最小规模的特征与更深更大规模的特征相结合。这比PSM-Net有更好的性能,但并未显著增加网络中的参数数量。
下面是所谓MCUA机制的结构图,感受一下吧
2.2 每个视差层级一个分支,每个分支产生对应的相似度特征图
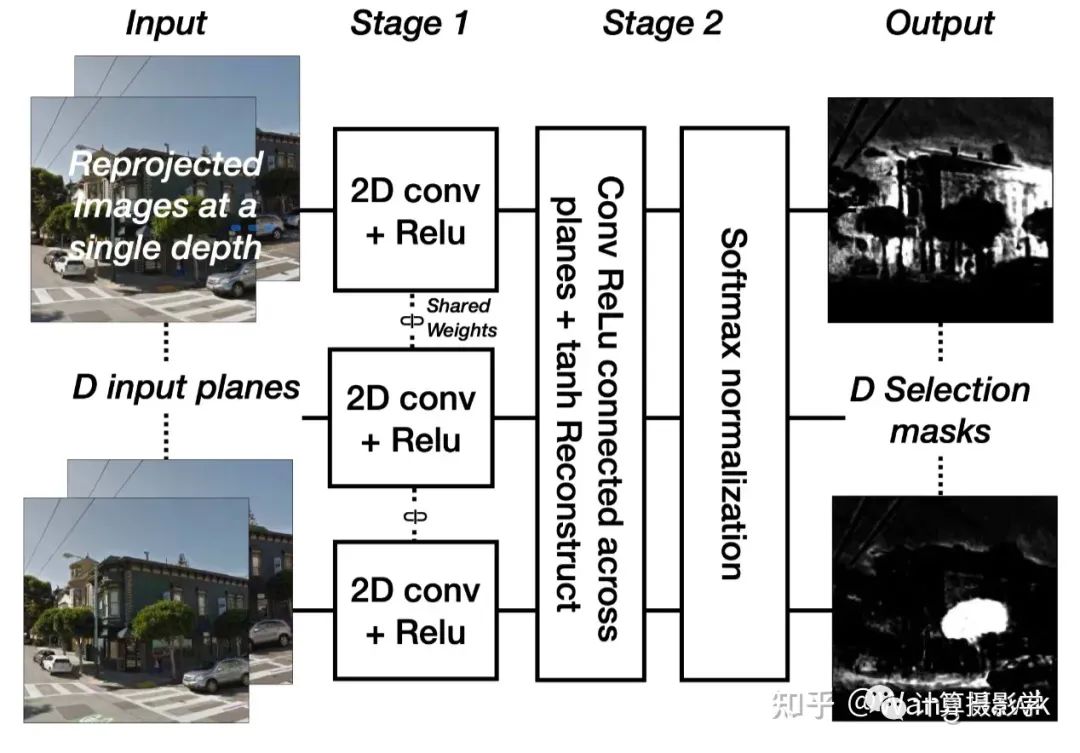
现在我们看看每个视差层级一个分支这种网络结构的例子。篇幅有限,我们就看看2016年John Flynn等人在CVPR上发表的DeepStereo: Learning to Predict New Views from the World’s Imagery吧。
我们看看作者给的图,你应该一眼就可以看到,对于不同的视差层级,算法首先会进行输入图像的重投影。再利用输入计算了对应的相似度——这非常符合我们在第二节开头时提到的原则
三. 总结和思考
在今天的讨论中,我们了解到了两种端到端的立体匹配算法:一种简单粗犷,直接将输入视图连接并进行硬回归,但因为这种方法需要大量参数,所以需要有大量带有Ground Truth视差的图像对进行训练,这是一大挑战。另一种方法,将立体匹配流程分为多个阶段,每个阶段都采用可以微分的函数进行实现,使得整个过程可以通过深度学习网络进行端到端的实现。这两种方法各有利弊。第一种方法运算效率高,但需要大量的优质数据支撑,而且模型的通用性可能较差。第二种方法将立体匹配的整个过程拆分开来进行,这种方式更接近传统立体匹配算法的思想,具有更好的灵活性和可解释性,可以更好地利用深度学习的优势,但可能会增加模型的复杂性。
我们还深入探讨了两种端到端立体匹配网络中的特征学习策略:一种是每个图像一个分支,每个分支产生对应的特征图;另一种是每个视差层级一个分支,利用当前视差层级的信息对输入的图像做变换,然后进行匹配,得到衡量相似度的特征图或匹配代价特征图。这两种策略各有特点和优势。前者的优势在于可以为每个输入图像生成对应的特征图,这种方法可以更好地提取和利用图像特征。而后者的优势在于,它可以根据不同的视差层级生成不同的特征图,从而更好地捕捉和理解图像之间的差异和联系。
特征学习是立体匹配网络中的一个重要步骤,它可以有效地提取和利用图像的特征和信息。然而,如何选择和设计特征学习的策略,以及如何更好地利用深度学习的优势来提取和利用特征,这仍是立体匹配领域的一个重要研究方向
如果你觉得我今天的文章对你有启发,别忘了给我点赞哦~ 还有疑问的话,你可以在我的知识星球“HawkWang计算摄影学”向我发起咨询
下面是我们的进度,我们又前进了一点点:
四. 参考资料
- Hamid Laga, Laurent Valentin Jospin, Farid Boussaid, and Mohammed Bennamoun. (2020). A Survey on Deep Learning Techniques for Stereo-based Depth Estimation. arXiv preprint arXiv:2006.02535. Retrieved from https://arxiv.org/abs/2006.02535
- 81. 三维重建16-立体匹配12,深度学习立体匹配之 MC-CNN
- 82. 三维重建17-立体匹配13,深度学习立体匹配的基本网络结构和变种
- A. Kar, C. Häne, and J. Malik, “Learning a multi-view stereo machine,” in NIPS, 2017, pp. 364–375.
- A. Kendall, H. Martirosyan, S. Dasgupta, P. Henry, R. Kennedy, A. Bachrach, and A. Bry, “End-to-end learning of geometry and context for deep stereo regression,” IEEE ICCV, pp. 66–75, 2017.
- J. Pang, W. Sun, J. S. Ren, C. Yang, and Q. Yan, “Cascade residual learning: A two-stage convolutional neural network for stereo matching,” in ICCV Workshops, vol. 7, no. 8, 2017.
- Z. Liang, Y. Feng, Y. G. H. L. W. Chen, and L. Q. L. Z. J. Zhang, “Learning for Disparity Estimation Through Feature Constancy,”in IEEE CVPR, 2018, pp. 2811–2820.
- J. Chang and Y. Chen, “Pyramid Stereo Matching Network,” IEEE CVPR, pp. 5410–5418, 2018.
- G.-Y. Nie, M.-M. Cheng, Y. Liu, Z. Liang, D.-P. Fan, Y. Liu, and Y. Wang, “Multi-Level Context Ultra-Aggregation for Stereo Matching,” in IEEE CVPR, 2019, pp. 3283–3291.
- J. Flynn, I. Neulander, J. Philbin, and N. Snavely, “DeepStereo: Learning to predict new views from the world's imagery,” in IEEE CVPR, 2016, pp. 5515–5524.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-05-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号