数据获取:网页解析之lxml


从之前的内容中,我们知道了requests请求返回的内容是网页的源代码,而且对于前端的HTML代码有一点的初步的认识,但是很多的前端的页面少则几百行,多则几千行业也经常遇见,如果从这么多的内容中去寻找需要的内容,那么效率一定是很低,这里我们就需要借助网页解析工具包lxml和BeautifulSoup。它们可以将字符串格式的HTML页面转成相应的对象,然后我们可以配置一个规则,找到我们需要的内容。
XPath语法
lxml是Python的一个解析库,支持HTML和XML的解析,支持XPath(XML Path Language)解析方式。XPath,它是一门在XML文档中查找信息的语言,具有自身的语法,是用来确定XML文档中某部分位置的语言,最初是用来搜寻XML文档的,当然也适用于HTML文档的搜索。通俗点讲就是lxml可以根据XPath表示的位置来确定HTML页面中的内容,从而实现找到我们需要的内容。
虽然XPath是需要学习相关的语法才可以知道怎么定位页面内容,不过XPath语法并不是学习的重点,现在的工具或者浏览器自带的工具可以辅助生成XPath的路径,方便快捷,大大提升了开发的效率。
XPath 使用路径表达式来选取XML文档中的节点或节点集。节点是通过路径 (path) 或者步 (steps) 来选择。这个可以这么理解,比如说我们在表达我是来自某某地方的时候,很少直接说,我在XX区,这样让别人并没有一个位置的概念,通常用中国(<html>)XX省(<body>)XX市(<div>)XX区(<p>), XPath就是根据这种路径来选准确的元素。
如果你直接想要某一些元素,好比找到地名带“州”字的,也可以不需要从头开始,直接可以从<div>元素位置查找,可以根据<div>标签中特定的属性值来定位元素,但是这种写法通常是一个结果集。
XPtah规则
下面图中是常用的XPath路径中的表达式。
表达式 | 含义 |
|---|---|
/ | 从当前节点选取子节点 |
// | 从当前节点选取子孙节点 |
. | 选取当前节点 |
.. | 选取当前节点的父节点 |
@ | 选取属性 |
*、d、+... | 通配符,XPtah中可以使用正则表达式 |
[@attribute] | 选取具有此属性的所有元素 |
[@attribute='value'] | 选取此属性值为value的所有元素 |
[tag] | 选取所有具有指定元素的直接子节点 |
安装LXML
安装库可以直接使用pip安装,安装命令:
>>>pip install lxml
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting lxml
……
lxml-4.6.2-cp39-cp39-win_amd64.whl (3.5 MB)
Installing collected packages: lxml
Successfully installed lxml-4.6.2Pip默认下载源是国外的服务器,我们可以修改成国内的下载源。在window系统中最快捷的方法是,在C盘的当前用户目录下:C:\Users\用户名,创建一个pip的文件下,在文件中编写文件pip.ini,文件中设置下载源地址,这样我们可以快速下载和安装库。
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn生成解析对象
首先创建一个简单的HTML示例的字符串:
from lxml import etree
text = '''
<html>
<head>
<title>实例HTML</title>
</head>
<body>
<div>
<h1>这是标题</h1>
</div>
<div>
<ul>
<li class="c1"><a href="link1.html" title="链接1">第一个链接</a></li>
<li class="c2"><a href="link2.html" title="链接1">第二个链接</a></li>
<li class="c3"><a href="link3.html" title="链接1">第三个链接</a></li>
</ul>
</div>
</body>
</html>
'''
# 初始化生成一个XPath解析对象
selector = etree.HTML(text)
# 对象类型
print(type(selector))
#代码结果:
<class 'lxml.etree._Element'>这样使用etree模块中的HTML()方法就可以得到一个 etree对象,而且即便是输入的HTML标签有缺失,或者直接使用<div></div>中的部分字符串,etree也可以自动补全,并不需要完整的标签对等。
解析节点
从得到的etree对象中,可以通过xpath的语法定位到相关需要的内容,这需要对XPath语法有一定的了解。
通过XPath选择class为c1的任意标签下的a标签内容
a = selector.xpath('//*[@class="c1"]/a')
print(type(a))
print(a)
#代码结果:
<class 'list'>
[<Element a at 0x21b4afc51c0>]XPath选择后得到的是一个元素的list,即便是这个list中只有一个元素。但是在实际操作过程中,我们拿到并不能到这个a标签的对象就完成了,要么是需要a标签的文本,要么就是a标签中的属性。
通过XPath选择class为c1的任意标签下的a标签中的链接和文本
link = selector.xpath('//*[@class="c1"]/a/@href')
text = selector.xpath('//*[@class="c1"]/a/text()')
print(link)
print(text)
#代码结果:
['link1.html']
['第一个链接']如果是想要获取标签内的属性值,那么用的@后跟属性名。如果想要获取标签内的内容,那么用text()。返回的结果都是字符串对象的list集合。在获取“link1.html”的语法如下:“//*[@class="c1"]/a/@href”。
第一个//是当前节点选取子孙节点,直接写表示从当前根节点中选择,*表示任何标签,[]中是对前面*选择的限制,为class属性的值为“c1”的标签才符合要求。当然在页面中可能存在多个class为“c1”的标签,所有结果都是list,即便是符合要求的标签只有一个,所以在编写的时候别忘了取list中的第一个对象。“/a”表示在上面的对象结果的子节点中选择a标签的节点。“/@href”表示选择的a标签中的href属性的值,同样,如果想要获取“title”标签中的内容,就是直接是@ title。
title= selector.xpath('//*[@class="c1"]/a/@title')
print(title)
#代码结果:
['链接1']通常情况下,我们都会把一个HTML中的某个div下的所有链接获取下来,那怎么办呢?
links = selector.xpath('//div//a/@href')
print(links)
#代码结果:
['link1.html', 'link2.html', 'link3.html']“//div//a/@href”表示的是,在所有的div下的所有子孙节点中的a标签的href属性值。在上面的HTML文本中,div下一级标签其实是ul,但是XPath中“//”是选择的下面所有节点。所以是可以找到我们想要的结果。
XPath获取
上面的内容中,我们可以对XPath根本上是表达了在一个HTML中某一个元素的位置。如果这个页面比较简单,还可以好找,但是页面比较复杂,路径找起来还是比较麻烦,不过我们并不需要自己手写XPath路径,浏览器中有相关的内容可以直接获取某个元素的XPath值。
以豆瓣电影网页为例子,首先在浏览器中打开F12的开发者工具,tab选中【查看器】,如下图所示:
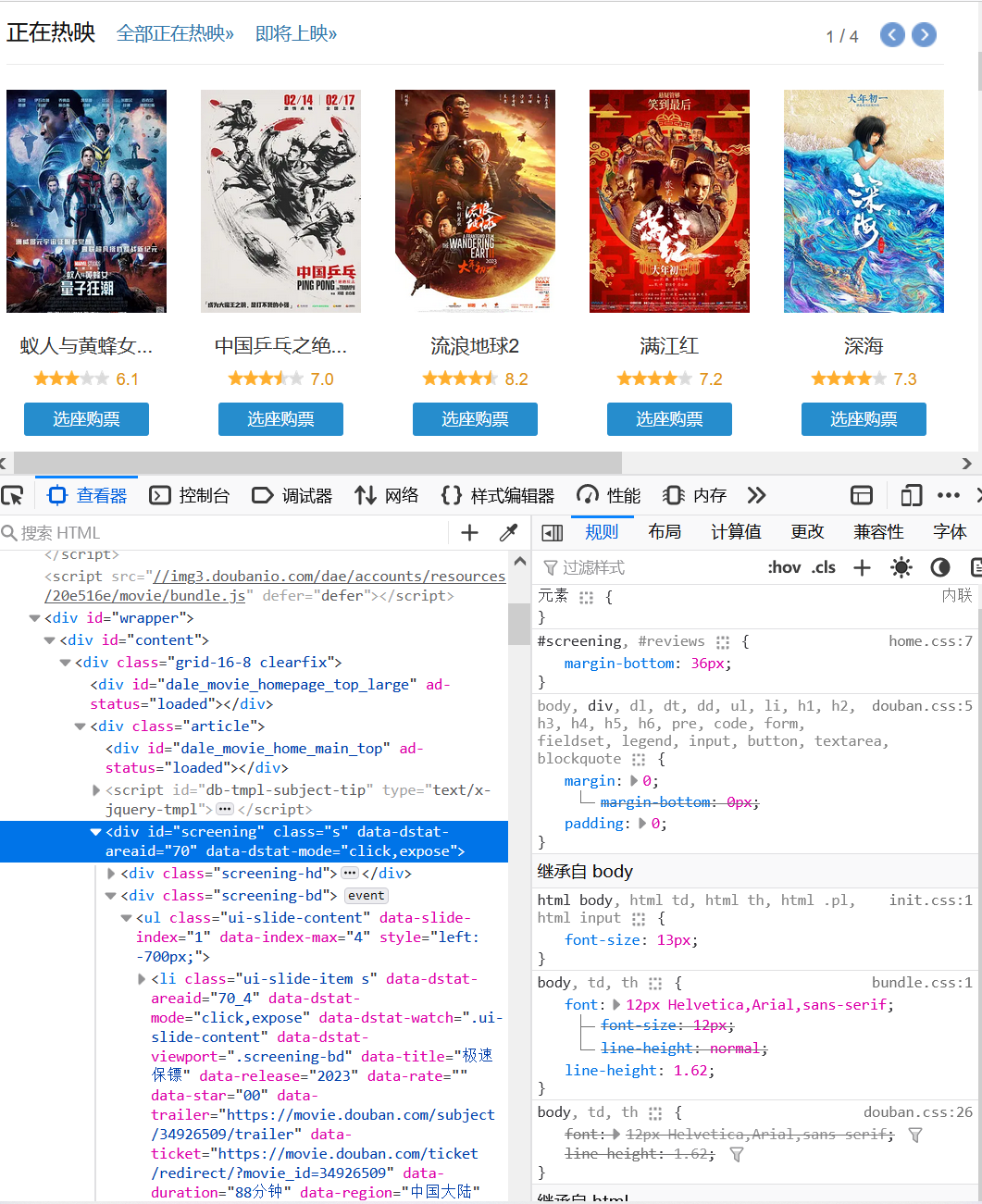
然后选中页面元素选择按钮,选中正在热映的电影的div。点击此按钮后,按钮会变为蓝色,当鼠标移动到页面时,页面会显示元素的标签和大小,并且光标所在的位置,页面会变成蓝色,如图所示,在查看器中的也会相应显示当前光标位置所在位置的代码。然后移动鼠标,位置找到当前正在热映电影的div。这个操作也可以反向操作,就是点击查看器的代码,页面会显示到当前点击的位置,所以如果在页面不好定位到那个div,可以在查看器中找一下。
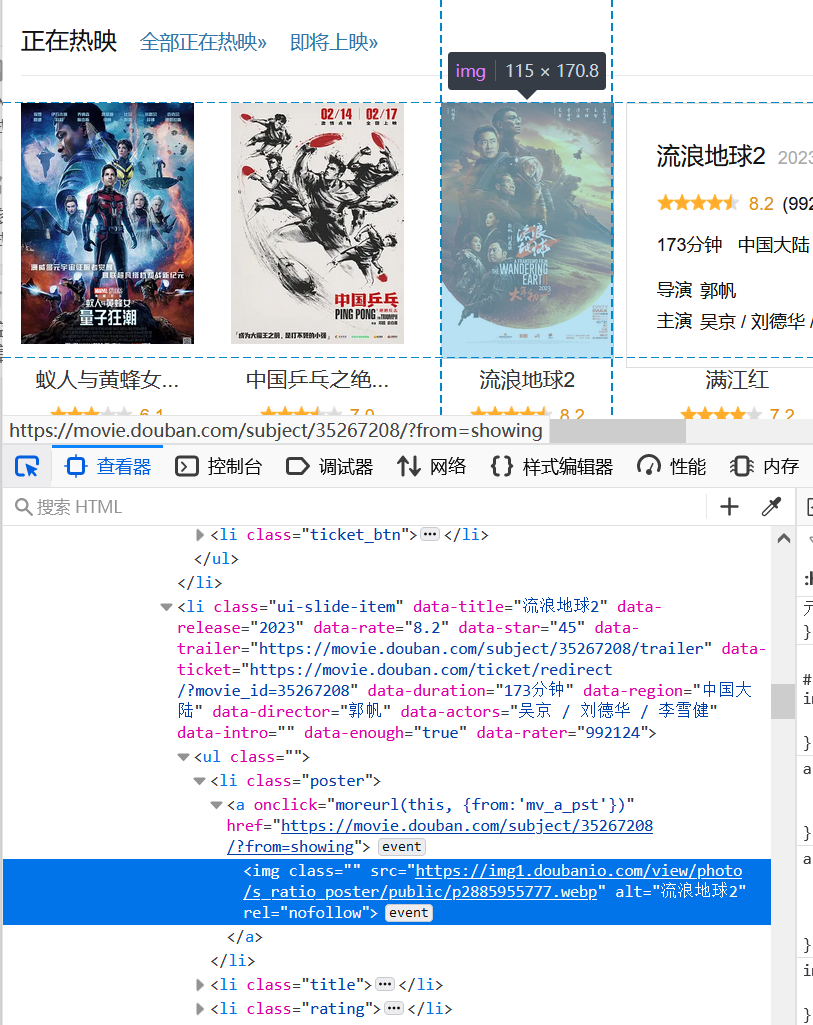
找到相应的div后,将此div选中。然后鼠标点击右键,找到【复制】在点开后选择【XPath】,如下图所示。这是XPath的路径就得到了,在IDE或文本文档,鼠标右键粘贴或者CTRL+V得到“/html/body/div[3]/div[1]/div/div[2]/div[2]/div[2]”,这个就是正在热映的div元素的XPath的路径。
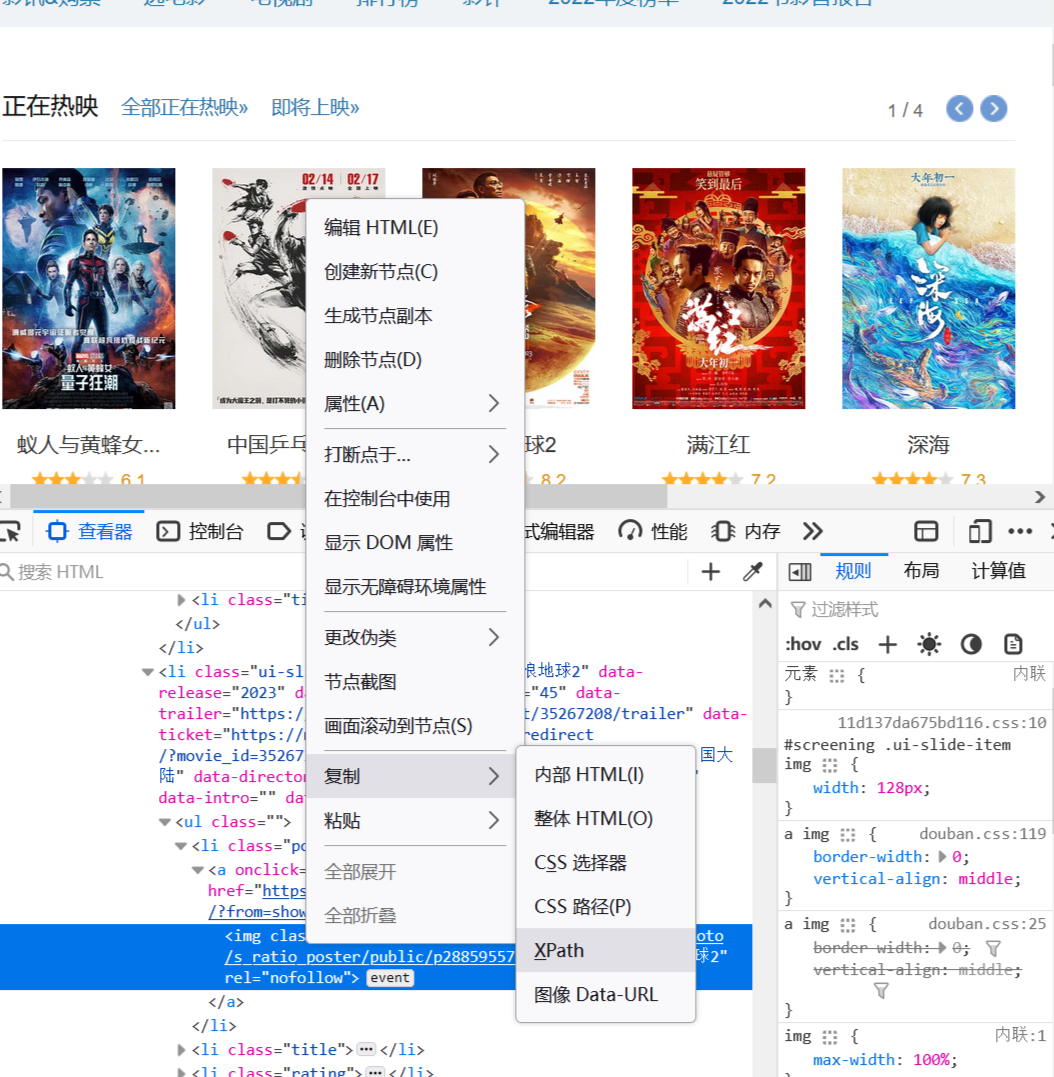
上面示例中,使用的火狐浏览器作为演示,其他的Chrome或者360浏览器中都具有此功能,但是不同的浏览器获取的XPath可能不一样,这个是没有问题的,因为在页面中的同一个位置有多种表达的方式,只要最后获得的正确的结果就没问题,同样的上面的操作如果在Chrome浏览器中得到的结果是“//*[@id="screening"]/div[2]”。下面需要验证下浏览器给出的XPath是不是我们想要得到的结果,要注意浏览器给出的结果并不是完全正确的。
XPath验证
刚才我们通过浏览器获取到了正在热映的div,现在我们想要获取div中的电影名,要得到具体的信息,需要先分析下响应的HTML代码,确定出来从哪个标签中获取信息是最全的。同样的方法在查看器中选择一个电影的内部HTML,如下图所示。
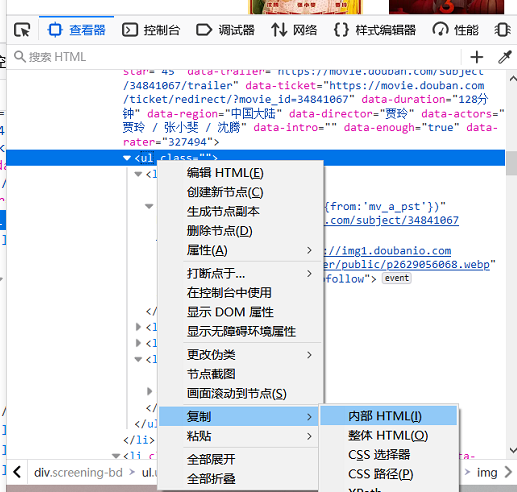
得到的内部HTML的文本复制出来:
<li class="ui-slide-item" data-title="流浪地球2" data-release="2023" data-rate="8.2" data-star="45" data-trailer="https://movie.douban.com/subject/35267208/trailer" data-ticket="https://movie.douban.com/ticket/redirect/?movie_id=35267208" data-duration="173分钟" data-region="中国大陆" data-director="郭帆" data-actors="吴京 / 刘德华 / 李雪健" data-intro="" data-enough="true" data-rater="992124">
<ul class="">
<li class="poster">
<a onclick="moreurl(this, {from:'mv_a_pst'})" href="https://movie.douban.com/subject/35267208/?from=showing">
<img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2885955777.webp" alt="流浪地球2" rel="nofollow" class="">
</a>
</li>
<li class="title">
<a onclick="moreurl(this, {from:'mv_a_tl'})" href="https://movie.douban.com/subject/35267208/?from=showing" class="">流浪地球2</a>
</li>
<li class="rating">
<span class="rating-star allstar45"></span><span class="subject-rate">8.2</span>
</li>
<li class="ticket_btn"><span><a onclick="moreurl(this, {from:'mv_b_tc'})" href="https://movie.douban.com/ticket/redirect/?movie_id=35267208" target="_blank">选座购票</a></span></li>
</ul>
</li>从代码中可以看得出来,四个li标签依次是电影的海报图、电影名字、电影评分和选座购票的链接。但是我们只是想获取到电影名,其他的并不需要,对比这四条信息发现,在img标签中的alt属性就是电影名称。在第二个li标签下的子节点的a标签的内容也是名字,但是由于这个内容后面是…,可见有的名字比较长,做了部分显示,所以对于我们的需要求并不准确。
由此可以找到,之前div下的所有img标签中的alt属性值,即是我们需要的结果即是。XPath代码为“//img/@alt”,完整Python代码如下:
爬取豆瓣电影首页的信息
import requests
from lxml import etree
url = 'https://movie.douban.com/'
# 设置请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
# 添加headers参数
response = requests.get(url, headers=headers)
# 初始化生成一个XPath解析对象
selector = etree.HTML(response.text)
#火狐浏览器获取的XPath表达式
links = selector.xpath("/html/body/div[3]/div[1]/div/div[2]/div[2]/div[2]//img/@alt")
print(links)代码结果:
['蚁人与黄蜂女:量子狂潮', '中国乒乓之绝地反击', '流浪地球2', '满江红', '深海', '黑豹2', '无名', '不能流泪的悲伤', '风再起时', '熊出没·伴我“熊芯”', '交换人生', '冥绝村', '想见你', '可不可以不要离开我', '阿凡达:水之道', '极速保镖', '穿靴子的猫2', '胡杨林之恋', '六尺巷']
结果也正是我们想要的内容,2023年春节档期热映的电影名的list。可见,从火狐浏览器中得到的XPath表达式是没问题的,同样的换成Chrome试试。
Chrome浏览器获取的XPath表达式
links = selector.xpath("//*[@id='screening']/div[2]//img/@alt")
print(links)运行结果也同样成功获取到想要的内容,可见XPath是一个路径的表达方式,可以用绝对路径也可以用相对路径。不过由浏览器的工具,我们不需要完整的从零开始写,只需要根据浏览器提供的路径进行改造和加工即可的到我们想要的内容。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-02-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号