数据存储:excel文件存放数据


前文中说到,数据分析就是像是做饭一样,在数据获取的内容好比收集食材,通常情况下,食材装备好后是需要有容器存放,有一些是需要立马做饭使用的,就放在盆中,还有一些今天用不上,下次需要的先放到冰箱中。同样,数据也是如此,尤其是爬虫获取的数据,通常是需要保存到本地中,方便下次直接使用。
所以数据存储也是数据分析重要的一环,通常情况下,数据量少的时候多数使用本地文件,比如csv文件,数据量多的时候通常使用数据库(超过100w)。
这介绍数据如何存放到本地文本中,在本地文件的储存中,最常用的是txt文件和csv文件,这两种通常是存数据库常用的文件方式。有时候为了方便后续使用,也经常会把数据存到EXCEL文件中,下面我们就了解下Excel文件的写入和读取。
安装好Openpyxl库
在Python基础知识的章节中,我们已经初步学习到了文本的写入,不过像这种Excel文件有操作格式,在Python中有专用的Excel的操作库,xlrd和xlwt可以用于xls文件的读取和写入,大单个sheet最大行数是65535, openpyxl可以用于xlsx文件的操作,最大行数达到1048576。逐渐地openpyxl已经成为了excel文件处理最常用的模块之一,功能也十分强大。我们本节内容就使用openpyxl来作为学习的模块。
在线安装使用pip安装,安装命令:
pip install openpyxlExcel读取
在使用openpyxl之前,先熟悉一下Excel中几个常用的概念。首先,我们所说的每一个以xlsx结尾的Excel文件都是一个工作簿。在windows系统中可以使用右键新建一个Excel人文件,这就是创建了一个工作簿,并且将其命名为“成绩单.xlsx”。
打开文件直接会看Excel表格,其实当前默认操作第一个工作表,默认名称为“Sheet1”。点击右边的“⊕”,还可以继续创建一个新的工作表,默认名称为“Sheet2”,当然可以继续创建新的,以此类推。这就是工作簿和工作表的关系。
在openpyxl中也是存在着对应的概念,工作簿是workbook对象,工作表是worksheet对象。从workbook中可以根据名字来获取worksheet。接下来就是每一个单元格,横轴使用的字母,纵轴使用的数字,这样使用字母加数字就可以定位到一个单元格,如图所示,当前定位的位置是A1单元格。

这时一个单元格就是一个cell对象,除了直接使用“A1”这种访问方式, 也可以行(row)和列(column)的方式来访问。那么“A1”单元格的位置就是第1行第1列的元素。在Sheet1中编写几个测试使用的数据,供openpyxl演示使用。
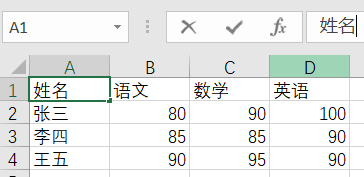
了解相关的概念后,我们可以使用openpyxl来读取Excel文件,加载到Python程序中。
# 导入openpyxl模块,读取excel文件
import openpyxl
# 获取workbook对象
wb = openpyxl.load_workbook('成绩单.xlsx')
print(wb)
# 获取worksheet对象
sheet = wb['Sheet1']
print(sheet)
# 获取cell对象
cell = sheet['A1']
print(cell)
# 打印cell对象的值
print(cell.value)代码结果:
<openpyxl.workbook.workbook.Workbook object at 0x0000018B07E3DFD0>
<Worksheet "Sheet1">
<Cell 'Sheet1'.A1>
姓名除了使用一个单元格的坐标,还可以使用切片的方式,比如从A1到C2,可以使用sheet['A1':'C2']的方式来获取,结果是一个tuple,而每一行是一个字tuple。
#A1到C2的内容
cell_range = sheet['A1':'C2']
print(cell_range)
for rows in cell_range:
#每一行的内容
print(rows)
for cell in rows:
#每一个单元格的内容
print(cell.value)代码结果:
((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>), (<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>))
(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>)
姓名
语文
数学
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>)
张三
80
90使用这种方式,我们可以根据Excel单元格的位置,把每一行数据转成每一个对象,然后存放在容器中供后面的数据分析时使用。
当然openpyxl功能很强大,不仅仅可以读取已经存在的文件,还可以创建文件。还可以对每一个单元格设置样式等等,不过这些并不是我们需要了解的重点,感兴趣的读者可以自行尝试下,探索新使用的方式,我们本书中的内容仅仅立足于数据分析的内容使用。
Excel写入
Excel写入也就是将Python内存中的数据持久化到硬盘的文件中,接下来学习使用openpyxl进行Excel文件的创建和数据写入。
# 导入openpyxl模块
import openpyxl
# 创建一个Workbook对象
wb = openpyxl.Workbook()
# 获取当前活动的工作表
ws = wb.active
#设置表头
ws.append(['姓名', '语文', '数学', '英语'])
#待保存的数据
data = [['a', 90, 90, 90], ['b', 80, 90, 80], ['c', 90, 80, 90]]
#循环写入数据
for i in data:
ws.append(i)
#保存成excel文件
wb.save("score.xlsx")代码运行后,会在当前目录下创建一个score.xlsx的文件,如果当前目录之前存在过此文件,那么文件会被覆盖掉。score.xlsx文件内容如图所示,正是我们写入的数据。

在Python中一切皆对象,不管是读取还是写入,其实都是使用的Workbook工作薄对象、WorkSheet工作表对象以及cell单元格对象的操作。
数据本地储存
在之前的章节中,已经完成了豆瓣电影数据的获取,但是在客观上还是差一个环节,就是把数据储存到某个位置,供下次使用。上一小节中已经了解了如何把数据写到Excel文件中,所以我们需要继续创建一个数据储存的方法,将爬虫功能完善,在后面增加一个数据保存的方法
#将数据保存到excel文件中
def saveData2Excel(allMovies):
wb = openpyxl.Workbook()
ws = wb.active
ws.append(['电影名称', '上映年份', '导演', '类型', '评价分数', '评价人数', '制片国家/地区', '语言'])
for movie in allMovies:
ws.append(
[movie.name, movie.year, movie.directedBy, movie.genre, movie.rating_num,
movie.rating_people, movie.area, movie.language])
wb.save("movie.xlsx")
print("电影数据储存完毕")allMovies存储是全部豆瓣电影信息对象的集合,saveData2Excel()方法是将它持久化到Excel文件中,只需要将allMovies对象作为参数传给saveData2Excel即可。
#豆瓣电影爬虫main方法
if __name__ == '__main__':
# 存放全部电影对象的容器
allMovies = []
allDetailLinks = getAllLinkList()
for detailLink in allDetailLinks:
print("当前抓取链接为:{}".format(detailLink))
allMovies.append(getMovieDetail(detailLink))
time.sleep(2)
# 方便测试,设置抓取10个链接后就结束
if len(allMovies) == 10:
break
saveData2Excel(allMovies)
print("豆瓣电影TOP250信息抓取完毕")为了方便测试,在循环中添加了次数限制,抓取10个链接后就结束,运行结果如图所示,符合我们最初的需求内容。

如果你运行上面的示例代码,可能得出来的结果跟上图并不一样,甚至每一次运行的结果都不一样,这是因为在使用BeautifulSoup获取到的详情页面链接的列表结果是无序的,元素顺序并不跟页面顺序一样,所以抓取的内容顺序并不一样是正常的看到的顺序。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-02-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号