数据存储:MySql数据库的基本使用


数据库,顾名思义,就是存放数据的仓库,它是按照一定的数据结构来组织、存储和管理数据的仓库,是一个长期存储在计算机硬盘中、有组织的、可共享的、统一管理的大量数据的集合。
比起本地数据文本,数据库的优势在于提供了共享性,并发性。在后面数据可视化章节中,不仅仅是一次的可视化分析,还将搭建一个web服务,进行可多人使用的可视化处理。所以为了提供更多的并发支持服务,先了解下数据库的使用,这里以轻量化的MySQL数据库为例。
MySQL简介
MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),使用最常用的数据库管理语言--结构化查询语言(Structured Query Language,简称SQL)对数据库进行管理。是最流行的开源的、可免费使用的数据库系统,功能强大,足以应付web应用。
MySQL底层是使用C和C++编写,支持包括window、Linux 在内的等多种操作系统上运行。并且支持多线程,也提供TCP/IP、ODBC和JDBC等多种数据库连接途径。
MySQL数据库也是需要安装才可以使用的,数据库安装包下载链接可以在MySQL官网中找到:https://dev.mysql.com/downloads/mysql/ 主流的操作系统都支持,如果需要在本机安装(以windows操作系统为例),可以直接下载最新的8.0.23社区版本。
不过现在很多的云服务器厂商都推出许多云数据库的相关产品,提供直接在线使用的数据库服务,方便快捷,免去了自己搭建数据库的繁琐步骤,当然是根据相应的配置付费,对于新用户体验来说,并不是一笔很大的支出,所以为了快捷的使用MySQL数据库,直接购买一个体验的云数据库使用,读者也可以自行选择一家合适的厂商产品使用,也可在本机主机中自建一个数据库。
数据库基本使用
1.数据库可视化配置
MySQL数据完成安装后,可以在CMD中使用命令在操作数据库,包括修改密码、创建用户、创建表等等都可以通过命令来完成,可是这对于初学者来说,应用成本很高,也不能快速上手。不过我们可以借助一些数据库的管理工具,帮助我们快捷的管理和查看数据库。
Navicat就是一款比较好用的数据库管理工具,Navicat并不是免费的,但是提供了30天的免费试用,我们也可以安装试用,下载地址:http://www.navicat.com.cn/products/navicat-for-mysql。
使用Navicat连接数据库,需要知道相关的链接配置,通常在完成云服务器的设置后,可以得到数据库的地址、服务端口,账户名和密码。本地安装的数据库在安装过程中也会设置这些信息,这些都是需要用户牢记。多数的云数据库厂商都会提供web页面的数据库可视化管理页面,每个厂商提供的内容会略有不同,功能上不如Navicat丰富。
通常首次创建的数据库用户都是具有最高权限的root账户。但是在一般的生产情况下,root账户只会有相应的DBA来负责,给其他开发人员会新增一些具有低权限的账号使用,避免因为误操作发生数据库被误删除的事件,从而造成企业的损失。如果仅仅作为学习使用,数据库中并没有存入内容,我们也可以直接使用root账户来操作。
安装完Navicat后并打开,点击左上角链接,新建一个数据库连接,输入主机等相关信息,如图所示,如果是云服务器可以查看云服务器的控制台中的信息。输入完成后点击左下角的测试连接,如果显示连接成功,则数据库表明已经可以正常连接使用。

注意:如果没有连接成功,那么多数情况下原因是没有开放对应访问的端口,就是说Navicat想要远程连接数据库,但是权限不够,需要将设置安全策略,开发相应的端口。
2.SQL基础
SQL在前面提到过,是结构化查询语言(Structured Query Language)的简称,所以它也是一个语言用于数据库的查询和设计。谈及历史,SQL的历史甚至超过了Python,在数据库的领域一直经久不衰。
SQL上手比较容易,但是想要达到精通还是需要有一定的研究深度,一些资深的开发工程师或者DBA一项必备的技能就是SQL优化,SQL的知识点仔细讲可以有许多章节,这里仅仅做初步的介绍,因为作为数据分析来讲,多数用到的是查询SQL,下表是常用重点SQL命令。
命令关键词 | 含义 | 示例 |
|---|---|---|
SELECT | 查询表中数据 | Select * from table;(查询全部列)Select列名称 from tablename; |
UPDATE | 更新表中数据 | update tablename SET 列名称 = 值 |
DELETE | 删除表中数据 | Delete from tablename where列名称 = 值 |
INSERT | 表中插入数据 | Insert into tablename values (值1, 值2,…) |
SELECT DISTINCT | 去重查询 | Select distinct * from tablename; |
WHERE | 带条件查询表中数据 | Select* from tablename where 列名1 运算符 值1 and 列名2 运算符 值2 |
在SQL使用上,并不区分大小,在SQL眼中,SELECT和select是一样的。下面的这些运算符可在 WHERE 子句中使用:
运算符 | 含义 |
|---|---|
= | 等于 |
!= / <> | 不等于 |
> | 大于 |
< | 小于 |
>= | 大于等于 |
<= | 小于等于 |
like | 模糊搜索,搭配%使用 |
举个例子,在250部高分电影数据中,查询出2000年以后(包含)上映的影片信息的SQL:
Select * from movies where year >=2000;在Navicat中新建一个数据查询窗口,运行上面的语句,即可查询出数据。
3. Python操作数据库
在Python3版本上,操作数据库使用的模块是PyMySQL,它是完全遵循 Python 数据库 API v2.0 规范。在使用之前依旧是需要安装库,使用pip安装命令为:
pip install PyMySQL
在使用PyMySQL连接数据库之前,需要先创建库、创建表,不然链接到数据库后无法进行后续操作。可以通过数据库可视化工具navicat来创建一个库,打开已经添加数据库链接上右键——选择【新建数据库…】

在数据库新建页面中输入一个“datatest”的数据库名,这个名字会在后面连接中用得到。字符集选择使用utf8mb4,比utf8兼容度更高的字符集。可以避免因为emoji表情出现的问题,排序规则选择在比较和排序的时候更快的更常用的utf8mb4_general_ci。

点击确定后,崭新的数据库就创建好,这里面没有任何的内容,接下来还需要创建一个测试表user,并且在测试表中插入两条数据。
测试表创建也可以使用navicat快捷创建,不过同样也可以使用SQL语句进行创建。这里选择使用SQL语句创建表进行演示,也可以更多的接触和使用SQL。
-- 建表 ddl
create table user (
id int(11) NOT NULL AUTO_INCREMENT COMMENT '用户id',
name varchar(100) DEFAULT NULL COMMENT '用户名称',
age int(11) DEFAULT NULL COMMENT '用户年龄',
PRIMARY KEY (`id`)
)在SQL语句中,注释要使用-- 开头,并且需要--后面加一个空格。NOT NULL 表示该字段不为空,DEFAULT NULL 表示该字段默认为空。AUTO_INCREMENT表示该字段自动递增,常用为物理id,COMMENT是为该字段添加注释。PRIMARY KEY是为该表指定主键。主键的值在该表中是唯一不重复的值。
当然还可以给创建的表中指定存储引擎,字符编码,排序等等,如果不指定则默认跟数据库值相同。
在navicat中打开一个新的查询窗口,将刚刚写好的建表语句复制到输入框中,点击运行。在下方的结果区域,可以看到“OK”和运行时间。表示user表已经创建好了。
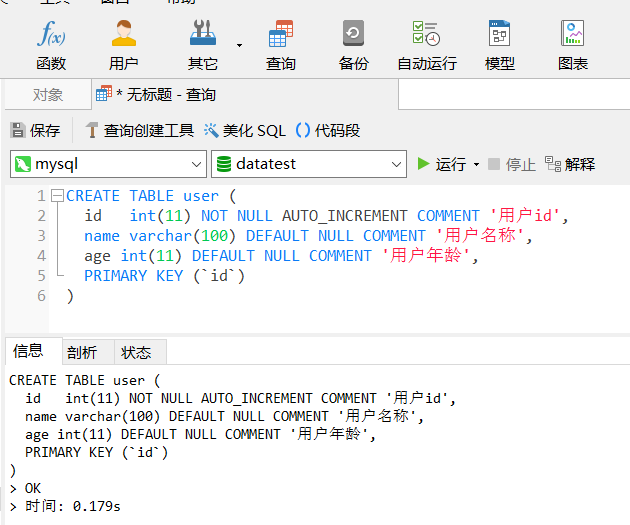
新创建的表当然是空的,现在给表中添加两条数据,使用上一个小节中讲到的insert语句插入数据:
-- 新添加一条 名字为a 年龄为 20 的数据
insert into user VALUES(1,'a',20) ;
-- 新添加一条 名字为b 年龄为 22 的数据
insert into user(name,age) VALUES('b',22) ;insert into 语句如果不指定id,则id也是会自动添加上。前提是设置了自动增长的属性,会根据当前表中id的最大值+1,可以不需要指定。
如果insert 语句中,values后面的记录数据跟字段个数不相等,那么需要在user后面罗列新增的是那些字段值,并且与values一一对应,不然的话,数据库不知道你存入的数据是哪个字段的,会报错:1136 - Column count doesn't match value count at row 1
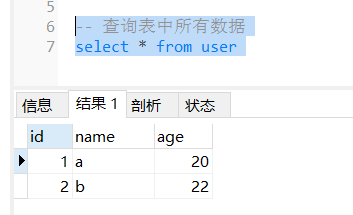
现在我们使用select语句查询刚才存入的数据:
-- 查询表中所有数据
select * from user;查询结果如所示,user表中已经存在了刚刚新插入的数据。
现在表结构和数据已经创建好,接下来就是在Python代码中使用PyMySQL来操作。使用PyMySQL来操作数据库,有其固定的顺序
- 建立连接
- 获取游标
- 执行SQL语句
- 关闭游标(连接)
先解释一下什么是游标。游标(Cursor)其实是一种数据处理方式,它可以定位到结果集中的任意一行进行操作。用刚才的表做个示例:
# 导入pymysql模块
import pymysql
# 连接database
conn = pymysql.connect(
host="101.37.124.133", #数据库地址
port=3306, #数据库使用的端口,默认3306
user="root", #用户名
password=" www.mlscoder.cn ", #密码
database="datatest", #数据库名称
)
#获取游标对象
# cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
# 要执行的SQL语句
sql = "select * from user "
# 执行SQL语句
cursor.execute(sql)
# 返回全部数据
result = cursor.fetchall()
#打印查询结果
print(result)
# 关闭光标对象
cursor.close()
# 关闭数据库连接
conn.close()#代码执行结果:
((1, 'a', 20), (2, 'b', 22))获取到结果是之前刚刚insert到表中,cursor默认的结果是元组,但是更多的时候想用字典数据,那么需要使用:
cursor =conn.cursor(cursor=pymysql.cursors.DictCursor)在获取游标的时候使用字典游标,这样查询到结果是字典数据。结果如下所示:
[{'id': 1, 'name': 'a', 'age': 20}, {'id': 2, 'name': 'b', 'age': 22}]查询结果是一个字典的list对象。PyMySQL不仅仅只能做查询这样的DML(Data Manipulation Language)语句,DDL(Data Definition Language)语句也可以执行。
我们就用之前创建的User表的语句,创建一个User_Temp表。执行代码如下:
# 导入pymysql模块
# -- coding: utf-8 --
# 导入pymysql模块
import pymysql
# 连接database
conn = pymysql.connect(
host="101.37.124.133",
port=3306,
user="root",
password="www.mlscoder.cn",
database="datatest",
)
# 得到游标
cursor = conn.cursor()
# 定义要执行的SQL语句
sql = '''
create table user_temp (
id int(11) NOT NULL AUTO_INCREMENT COMMENT '用户id',
name varchar(100) DEFAULT NULL COMMENT '用户名称',
age int(11) DEFAULT NULL COMMENT '用户年龄',
PRIMARY KEY (`id`)
)
'''
# 执行SQL语句
cursor.execute(sql)
# 关闭光标对象
cursor.close()
# 关闭数据库连接
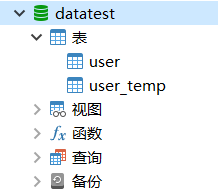
conn.close()执行代码结束后,可以直接打开navicat去查看下数据库表空间,不管是navicat还是pymysql,连接的都是同一个数据库,所以可以同时执行SQL语句。打开navicat,user_temp已经创建完成,语句执行无误。
MySQL数据库是比较基本的一款数据库,不管是做数据分析还是做程序员,都是必须掌握的内容,而且市面上的很多国产数据库,其实跟MySQL是换汤不换药,从语法上都是100%兼容的。
而且在面试中MySQL也是必问的内容,包括更加深入的锁、各种类型的索引、甚至数据结构,都是必考的内容,甚至单独的MySQL都可以写一本书,这些感兴趣的读者自行学习,不多赘述。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-04-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号