数据可视化:认识Numpy



接着之前的Python基础知识更新,这块内容很久之前就写了一版,但是后面也没有仔细修改,现在趁着这个机会在顺一遍。
前文中,主要写了一些数据采集和数据储存内容,那么最终我们把需要把数据的内容提取出有价值的观点以及更通俗易懂的表达方式,就是最后一步的数据分析和可视化。
数据分析是对数据进行详细研究以及概括总结从而提炼出数据中的有用信息行成结论的过程。下面的这部分章节主要是简单了解下数据分析三剑客——NumPy、Pandas、Matplotlib。
这里面的部分内容涉及到一些比较专业的数学知识,不过呢,我也不是专业的,就浅浅的了解一点皮毛。在目前我在的团队中,有模型团队,主要是做一些策略研究,量化工程的内容,使用的最广泛的还是padas库,堪称神库。
不过我也让pandas坑过,就是同样的代码使用不同的版本得出来的结果不一样,这导致业务对我们系统的线上数据表示很大的怀疑,在经过各方面中间数据比对后,才发现是这个问题。下面几个三个小节,我们依次介绍下,这数据分析的三剑客。
NumPy
NumPy是一个开源的Python数据分析和科学计算库,全称为“Numerical Python”,主要用于数组计算。NumPy是作为数据分析必备库之一,是从事数据分析行业人员必要了解和学习的一个库,下面我们就来一起了解下NumPy。
NumPy,顾名思义是跟是“数”有关系。作为一个功能强大的库,它本身具有以下几个显著的特点:
- NumPy底层是使用C语言实验,所有运行速度快。
- NumPy的数组比Python内置的数据访问效率更高。
- NumPy支持大量的高维度数据和矩阵运算。
- NumPy提供了大量的函数库。
为了能有一个直观的感受,我们尝试写一个示例,实现的功能是分别用Python的内置方法和NumPy的方法实现一亿个随机数的和,实现代码如下:
# 导入相关模块
import random
import time
import numpy as np
# 随机数存放list
numList = []
for i in range(100000000):
numList.append(random.random())
# 记录当前时间戳
t1 = time.time()
# Python内置函数求和
sum1 = sum(numList)
t2 = time.time()
# numpy生成一维数组
npList = np.array(numList)
t3 = time.time()
# numpy求和
sum3 = np.sum(npList)
t4 = time.time()
# 输出运行时间
print("Python:{},NumPy:{}".format(int(round((t2 - t1) * 1000)), int(round((t4 - t3) * 1000))))
#打印输出运行结果:
Python:450,NumPy:113结果很明显,内置方法耗时约450毫秒,NumPy耗时约113毫秒,由于生成1亿个的随机数的时间比较长,整个代码运行时间会比较长,而输出的时间差仅仅是1亿个随机数相加和的耗时。从结果上看NumPy的速度约是Python内置方法的4倍。
注意:选用一亿个的参数原因是,如果数据量太少,运行时间相差不足几毫秒,不能显著比较速度差异。如果一次性数据量太大容易导致内存溢出,从而程序无法运行。
由于在代码中numpy 会使用的比较多,所以习惯上会给numpy起一个别名np。在后面中只要是np就是代表是numpy。当然你也可以给它起个其他的别名,不过在多数长江使用行为上会用np代替。
NumPy的官网为:https://numpy.org/ 在这里,你可以找到所有关于NumPy最权威的资料,包括最新版本的Api,但是官网是纯英文的,阅读难度有点大,有一定的挑战性。
ndarray对象
首先看一个例子:
#导入numpy库
import numpy as np
numList = [1, 2]
npList = np.array(numList)
#打印相关参数
print(numList)
print(npList)
print(type(numList))
print(type(npList))
#代码运行结果:
[1, 2]
[1 2]
<class 'list'>
<class 'numpy.ndarray'>这里numList 是一个list对象,而npList是一个ndarray对象,这是一个一维数组对象,是同类型的数据集合。在list 对象中,可以存放多种数据类型,比如整数、浮点数、字符串等,但是ndarray对象中仅仅支持一种数据类型。为了达到快速运算的目的,就不能支持太多的数据类型。
Ndarray对象的创建方式只需要调用np.array()即可,np.array()的详细参数如下:
array(p_object, dtype=None, copy=True, order='K', subok=False, ndmin=0)p_object:一个数组或者嵌套数列,仅支持列表和元组的类型
dtype:数组元素的数据类型,可选
copy:是否复制对象,默认为True
order:创建数组的样式,可选, C为行方向,F为列方向,默认按照行方向创建
subok:是否返回一个与基类一样的数组,默认为True
ndmin:指定结果的最小维数
在dtype类型的具体有很多,下表中是常用的numpy数据类型:
类别 | 类型 | 值 |
|---|---|---|
布尔型 | bool_ | True 或者 False |
整型 | intc | 和 C 的 int 相同(一般为 int64 或 int32) |
int8 | 字节(-128 到 127) | |
int16 | 整数(-32768 到 32767) | |
int32 | 整数(-2147483648 到 2147483647) | |
int64 | 整数(-9223372036854775808 到 9223372036854775807) | |
uint8 | 无符号整数(0 to 255) | |
uint16 | 无符号整数(0 to 65535) | |
uint32 | 无符号整数(0 to 4294967295) | |
uint64 | 无符号整数(0 to 18446744073709551615) | |
浮点型 | float_ | float64 类型的简写 |
float16 | 半精度浮点数 | |
float32 | 单精度浮点数 | |
float64 | 双精度浮点数 | |
复数型 | complex_ | complex128 类型的简写, |
complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) | |
complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) | |
字符串 | string_ | ASCII字符串 |
unicode_ | Unicode字符串 |
如果想要更改numpy元素的数据类型,直接在创建的array方法的参数中指定即可。
import numpy as np
#创建一个整数列表
a = [1, 2, 3]
b= np.array(a)
print(b.dtype)
# int32转成int64
b = np.array(a, dtype=np.int64)
print(b.dtype)
#代码运行结果
int32
int64默认是int32的数据类型,通过dtype可以更改为int64类型,同理其他的数据类型也是一样。但是如果原类型是浮点型,转成整型,会造成数据精度缺失。
import numpy as np
a = [1.2, 2.6, 3.0]
b = np.array(a)
print(b.dtype)
#浮点型转成int64
b = np.array(a, dtype=np.int64)
print(b)
print(b.dtype)
#代码结果:
float64
[1 2 3]
int64一维数组和二维数组
先看一段代码示例:
import numpy as np
#一维数组
a = np.array([1, 2, 3, 4])
print("a数据类型:", type(a))
print("a数组元素数据类型:", a.dtype)
print("a数组元素总数:", a.size)
print("a数组形状:", a.shape)
print("a数组的维度数目", a.ndim)
print("一维数组访问:", a[1])
#二维数组
b = np.array([[1, 2, 3],
[4, 5, 6]])
print("b数据类型:", type(b))
print("b数组元素数据类型:", b.dtype)
print("b数组元素总数:", b.size)
print("b数组形状:", b.shape)
print("b数组的维度数目", b.ndim)
print("二维数组访问:", b[1][1])
#代码结果:
a数据类型: <class 'numpy.ndarray'>
a数组元素数据类型:int32
a数组元素总数:4
a数组形状:(4,)
a数组的维度数目 1
一维数组访问: 2
b数据类型: <class 'numpy.ndarray'>
b数组元素数据类型:int32
b数组元素总数:6
b数组形状:(2, 3)
b数组的维度数目 2
二维数组访问: 5上面示例中,ndarray对象a是一维数组,ndarray对象b是二维数组。一维数组本质上一个相同类型数据的线性集合,每个元素都只带有一个下标,而二维数组中每个元素都是一个一维数组,本质就是以数组作为数组元素的数组。每个元素会有两个下标,表示几行几列。二维数组又称为矩阵,行列数相等的矩阵称为方阵,学习过线性代数的读者对这些概念 并不会陌生。
一维数组的shape为(4,),只有一个数字,后面为空,表示一个4个元素的一维数组。而二维数组的shape是(2,3),表示两行三列的数组。二维数组除了可以使用b[1][1],同样可以写在一个[]中,使用b[1,1],两者是同样的表达意思。
注意:在二维数组中因为有行和列,表示所有的元素,但是有时候仅仅只是想对行或者对列进行操作,那么这时候会定义轴,用axis表示,axis=0表示从上往下,表示列,axis=1从左往右,表示行。在内存中的空间示意图如图所示。
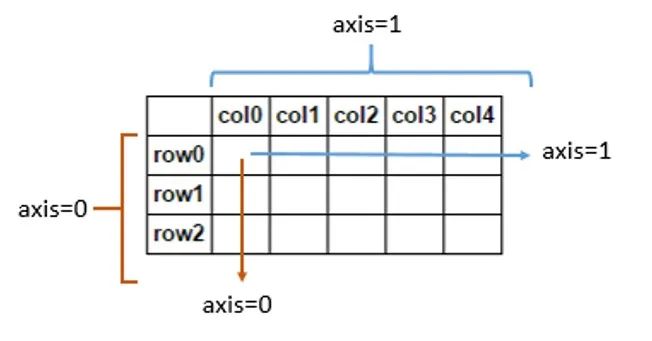
NumPy常用的array
arange(start, stop,step, dtype)
作用:创建指定数值范围内的数组
start:开始值
stop:结尾值
step:步长
dtype:数据类型,如果不指定则推断数据类型
import numpy as np
#从1到10,步长为2的数组
a = np.arange(1, 10, 2)
print(a)
#从1到10,步长为4的数组
b = np.arange(1, 10, 4)
print(b)
#运行结果:
[1 3 5 7 9]
[1 5 9]linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None,axis=0)
作用:创建等差数组
start:开始值
stop:结尾值
num:设置生成元素个数,默认值50
endpoint:是否包含结尾数值,默认包含
dtype:数据类型,如果不指定则推断数据类型
retstep:步长,设置是否返回步长。如果为True,返回一个元组,包含ndarray和步长。
axis:存储结果中的轴。仅当start或stop是数组是才有用,默认情况下为0。
1.创建1-10的4个元素的等差数组,元素类型默认float64
import numpy as np
a = np.linspace(1, 10, 4)
print(a)
#运行结果:
[ 1. 4. 7. 10.]2.创建1-10的4个元素的等差数组,并且返回步长
import numpy as np
a = np.linspace(1, 10, 4, retstep=True)
print(a)
#运行结果:
(array([ 1., 4., 7., 10.]), 3.0)3.创建1-10的4个元素的等差数组,不包含结尾值
import numpy as np
a = np.linspace(1, 10, 4, endpoint=True)
print(a)
#运行结果:
[1. 3.25 5.5 7.75]4.创建开始值为[1,1],结尾值为10的4个元素的等差数组
import numpy as np
a = np.linspace(1, 10, 4, endpoint=True)
print(a)
#运行结果:
[[ 1. 1.]
[ 4. 4.]
[ 7. 7.]
[10. 10.]]5.创建开始值为[1,1],结尾值为10的4个元素的等差数组,轴为-1
import numpy as np
a = np.linspace(1, 10, 4, endpoint=True,)
print(a)
#运行结果:
[[ 1. 4. 7. 10.]
[ 1. 4. 7. 10.]]logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None,axis=0)
作用:创建等比数组
start:开始值 base** start(base的start次幂)
stop:结尾值 base** stop(base的stop次幂)
base:底数,默认是10
1.创建开始值为10**0=1,结束值为10**3=1000的4个元素的等比数组,底数为10
import numpy as np
a = np.logspace(0, 3, 4)
print(a)
#运行结果:
[ 1. 10. 100. 1000.]2.创建开始值为2**0=1,结束值为2**3=8的4个元素的等比数组,底数是2
import numpy as np
a = np.logspace(0, 3, 4, base=2)
print(a)
#运行结果:
[1. 2. 4. 8.]3. 创建开始值为2**0=1,结束值为2**3=8的4个元素的等比数组,不包含endpoint
import numpy as np
a = np.logspace(0, 3, 4, base=2, endpoint=False)
print(a)
#运行结果:
[1. 1.68179283 2.82842712 4.75682846]这其实就是在开始值为1,结束值小于8的区间,创建4个元素的等比数组。所以数组的值跟开始和结尾有很大的关系,跟endpoint的取值也有很大的关系。
zeros(shape, dtype=None)
作用:根据指定形状和数据类型生成全是0的数组
shape:形状,几行几列,类型是列表或者元组
dtype:数据类型
import numpy as np
#生成2行3列的0数组
a = np.zeros([2, 3])
print(a)
#代码运行结果:
[[0. 0. 0.]
[0. 0. 0.]]
#生成1行2列的0数组,实际是一维数组
b= np.zeros((2))
print(b)
#代码运行结果:
[0. 0.]ones(shape, dtype=None)
作用:根据指定形状和数据类型生成全是1的数组,参数跟zeros相同
import numpy as np
#生成2行3列的0数组
a = np.zeros([2, 3])
print(a)
#代码运行结果:
[[1. 1. 1.]
[1. 1. 1.]]
#生成1行2列的0数组,实际是一维数组
b= np.zeros((2))
print(b)
#代码运行结果:
[1. 1.]full(shape, fill_value, dtype=None)
作用:根据指定形状和数据类型生成全是指定填充数的数组,参数比zeros和ones多了一个fill_value ,这个值就是指定的填充数。
import numpy as np
#生成2行3列的数值全为10的数组
a = np.full([2, 3], 10)
print(a)
#代码运行结果:
[[10 10 10]
[10 10 10]]
#生成1行5列的数值全为5的数组,实际是一维数组
b = np.full((5), 5)
print(b)
#代码运行结果:
[5 5 5 5 5]identity(n, dtype=None)
作用:创建单位矩阵,对角线元素为1,其余为0
n:表示数组形状
import numpy as np
#生成一个4行4列的单位矩阵
a = np.identity(4)
print(a)
#代码运行结果:
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]random.rand()
作用:根据指定的形状生成一个0-1均匀分布的随机数
import numpy as np
#生成4个随机数的一维数组
a = np.random.rand(4)
print(a)
#代码运行结果:
[0.02112632 0.87365592 0.80945496 0.29566459]
#生成2行3列随机数的二维数组
b = np.random.rand(2, 3)
print(b)
#代码运行结果:
[[0.16006514 0.33356576 0.84293238]
[0.95196988 0.7396325 0.86680162]]random. randint(low, high=None, size=None, dtype='l')
作用:生成low到high范围内size个整数
import numpy as np
#生成1个1-4的随机整数
a = np.random.randint(4)
print(a)
#代码运行结果:
2
#生成5个1-10的随机整数
b = np.random.randint(1, 10, 5)
print(b)
#代码运行结果:
[9 5 9 2 9]除此之外,Random中还有许多其他的生成各种随机数的方法,这些数组创建的方法主要是应用于数据实验、分析、对比的初始化,可以快速生成指定形状和数组类型的数组进行后续的操作。
NumPy常用操作
1.数组转置
学过线性代数的同学对这个不会很陌生,在线性代数中有矩阵转置的操作。就是行与列对调。原来第一行变成第一列,原来的第一列变成第一行,以此来推,就是转置操作。在numpy中可以直接跟矩阵转转置一样,使用T或者转置数组,同样可以使用transpose()函数来处理。
import numpy as np
a = np.array([[1, 2, 3],
[4, 5, 6]])
# 数组转置
b = a.T
c = a.transpose()
print(b)
print(c)
print(a)
#代码运行结果:
b
[[1 4]
[2 5]
[3 6]]
c
[[1 4]
[2 5]
[3 6]]2.进行运算
我们对数进行最多的操作莫非是加减乘除,求和、平均、求最大值、求最小值,numpy中这些操作是完全可以实现的。
import numpy as np
# 一维数组加减乘除
a = np.array([1, 2])
b = np.array([3, 4])
print("a + b=")
print(a + b)
print("a - b=")
print(a - b)
print("a * b=")
print(a * b)
print("a / b=")
print(a / b)#代码运行结果:
a + b=
[4 6]
a - b=
[-2 -2]
a * b=
[3 8]
a / b=
[0.33333333 0.5 ]
# 二维数组加减乘除
c = np.array([[1, 2],
[3, 4]])
d = np.array([[5, 6],
[7, 8]])
print("c + d=")
print(c + d)
print("c - d=")
print(c - d)
print("c * d=")
print(c * d)
print("c / d=")
print(c / d)
#代码运行结果:
c + d=
[[ 6 8]
[10 12]]
c - d=
[[-4 -4]
[-4 -4]]
c * d=
[[ 5 12]
[21 32]]
c / d=
[[0.2 0.33333333]
[0.42857143 0.5 ]]可见,numpy的数据运算操作是对相同位置的数值进行运算操作。
3.求最值
import numpy as np
#一维数组
a = np.array([3, 6, 2, 7, 8, 4])
print("a的最小值:" + str(a.min()))
print("a的最大值:" + str(a.max()))
print("a的和:" + str(a.sum()))
print("a的平均值:" + str(a.mean()))
#代码运行结果:
a的最小值:2
a的最大值:8
a的和:30
a的平均值:5.0
#二维数组
b = np.array([[3, 6, 2],
[7, 8, 4],
[10, 1, 4]])
print("b的最小值:" + str(b.min()))
print("b的最大值:" + str(b.max()))
print("b的和:" + str(b.sum()))
print("b的平均值:" + str(b.mean()))
#代码运行结果:
b的最小值:1
b的最大值:10
b的和:45
b的平均值:5.0在二维数组中,如果没有指定方向,那么会根据全部的数据元素来运算,此外根据0轴还是1轴的方向来进行比较或者求值。
import numpy as np
b = np.array([[3, 6, 2],
[7, 8, 4],
[10, 1, 4]])
print("b数组0轴(每一列)最小值:")
print(b.min(axis=0))
print("b数组1轴(每一行)最小值:")
print(b.min(axis=1))
#代码运行结果:
b数组0轴(每一列)最小值:
[3 1 2]
b数组1轴(每一行)最小值:
[2 4 1]同理,求最大值、平均值、求和等操作都可以对列或者行进行操作,需要指明作用轴即可。
import numpy as np
b = np.array([[3, 6, 2],
[7, 8, 4],
[10, 1, 4]])
print("b数组0轴(每一列)最小值:")
print(b.min(axis=0))
print("b数组1轴(每一行)最小值:")
print(b.min(axis=1))
#代码运行结果:
b数组0轴(每一列)最小值:
[3 1 2]
b数组1轴(每一行)最小值:
[2 4 1]4.连接
numpy中的concatenate()函数用于连接两个或者多个数组。函数方法如下:
concatenate(arrays, axis=None, out=None)arrays:连接的两个或者多个数组axis:连接方向
import numpy as np
a = np.array([[1, 2, 3],
[4, 5, 6]])
b = np.array([[1, 2, 3],
[4, 5, 6]])
# 列连接
c = np.concatenate((a, b), axis=0)
# 行连接
d = np.concatenate((a, b), axis=1)
print("列连接")
print(c)
print("行连接")
print(d)
#代码运行结果:
列连接
[[1 2 3]
[4 5 6]
[1 2 3]
[4 5 6]]
行连接
[[1 2 3 1 2 3]
[4 5 6 4 5 6]]当axis=0时,a、b是从上往下链接,当axis=1时,a、b是从左往右链接。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-07-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号