数据获取:认识Scrapy


本节介绍一个普通流程的爬虫框架——Scrapy,它提供了一个通用性的开发规范,帮助开发者做好了通用性的功能,只需要自定义发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容。在最后的实战项目中,我们将会使用Scrapy来做数据采集并进行深度的数据分析和可视化。
在Scrapy的官网上对它的介绍是:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。Scrapy官网:https://scrapy.org/,这里可以查阅原始的官网文档。
学习一个框架,先了解框架的架构。在Scrapy官网给出了一张各个组件的数据流程图,在图中包含了Scrapy的各个核心组件。
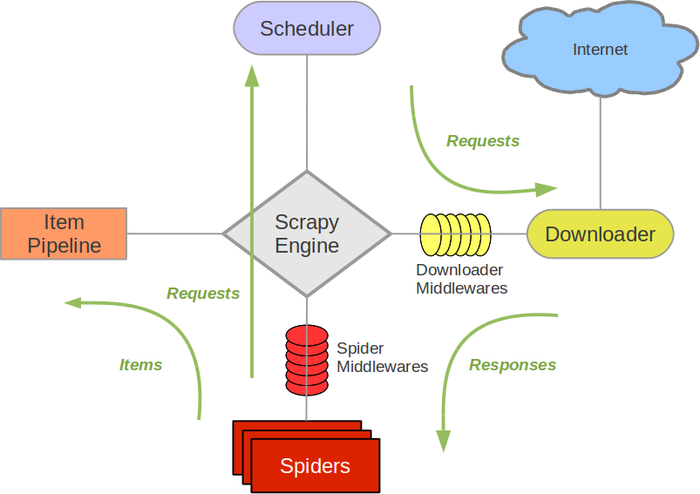
Scrapy Engine(引擎)
Scrapy引擎负责数据在不同的模块中传递和流转,并在相应动作发生时触发事件。也可以说Engine是Scrapy的大脑。
Scheduler(调度器)
调度器是存放需要待爬取的URL。
Downloader(下载器)
从调度器中传过来的页面URL,下载器将负责获取页面数据并提供给引擎,而后把数据提供给spider。
Spiders(爬虫)
Spider是需要开发者自行编写用于分析下载器返回的内容,提取item(可以理解为每个页面中需要爬取的数据对象),并且会提起新的待爬取的url给Scheduler。每个spider负责处理一个特定网站,一个Scrapy可以有多个Spider。
Item Pipeline(实体管道)
Item Pipeline负责处理Spider中获取到的Item,并进行后期处理,比如详细分析、过滤、存储等等操作。
Downloader Middlewares(下载中间件)
一个可以自定义扩展下载功能的组件,比如你需要在爬取中配置代理,那么就可以编辑这个middleware
Spider Middlewares(Spider中间件)
Spider中间件是一个可以自定扩展和操作引擎和Spider中间通信的功能组件,比如进入Spider的Responses和从Spider出去的Requests,添加请求头的过滤或者某些属性的设置等。
在以上组件中,Scrapy Engine、Scheduler和Downloader已经由Scrapy完成,Spiders和Item Pipeline是需要开发者根据需要自行编写。
Scrapy运行流程大概如下:
1.Spiders把要处理的URL发给Engine
2.引擎把URL传给调度器进行Request请求排序入队
3.引擎从调度器中取出一个URL,封装成一个Request请求传给下载器
3.下载器把资源下载下来,并封装成应答包(Response)
4.Spiders进行解析Response
5.Spiders解析出的Item,则交给实体管道进行后续处理
6.Spiders解析出的URL,则把URL传给调度器等待抓取
创建Scrapy项目
1.安装Scrapy
Scrapy也可以使用pip来安装,也推荐使用此方式安装,安装命令
pip install Scrapy默认是安装的最新版本,代码演示基于2.4.1版本,不同版本代码可能有差异,但是都大同小异。可以直接用最新版
2.创建项目
scrapy startproject mycrawler注意:这是在终端里运行的命令,不是在py脚本中,下同
运行上述命令后即可创建一个scrapy的项目,运行日志:
New Scrapy project 'mycrawler', using template directory
'd:\develop\python\python39\lib\site-packages\scrapy\templates\project', created in:
E:\PycharmProjects\pythonProject\mycrawler
You can start your first spider with:
cd mycrawler
scrapy genspider example example.com现在我们在E:\PycharmProjects\pythonProject 目录下创建了一个名叫mycrawler的scrapy项目,看看Scrapy项目下都有些什么。
scrapy.cfg: 项目的配置文件
mycrawler/: 该项目的python模块
mycrawler/items.py: 项目中的item文件,在此创建对象的容器的地方,爬取的信息分别放到不同容器里
mycrawler/middlewares.py:项目的middlewares文件,比如在这里可以设置请求代理
mycrawler/pipelines.py: 项目中的pipelines文件,这里定义数据管道,是保存还是分析
mycrawler/settings.py: 项目的设置文件,可以在此设置请求头,运行模式等等
mycrawler/spiders/: 放置spider代码的目录,这个目录下就是放爬虫的地方
接下来我们就创建爬虫,在创建项目的日志中也给出了提示:
You can start your first spider with:
cd mycrawler
scrapy genspider example example.com
3.创建爬虫
首先需要定义爬虫名称和需要爬取的域名,这里我们还是以豆瓣电影为例子,那么需要依次执行下面命令:
cd mycrawler
scrapy genspider douban douban.com这是在mycrawler/spiders/目录下会生成一个douban.py的文件,内容如下(已经对自动生成的内容做了修改)
import scrapy
class DoubanSpider(scrapy.Spider):
# 爬虫的唯一标识,不能重复
name = 'douban'
# 限定爬取该域名下的网页
allowed_domains = ['douban.com']
# 开始爬取的链接,可以设置多个
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
# response就是返回体
print(response.status)4.运行爬虫
这时已经算是实现了一个scrapy搭建的爬虫了,不过现在好像这个爬虫什么都不能做,我们先来启动一下,看看是否能正常启动。Scrapy启动命令, 命令中“douban”必须是在DoubanSpider类的name属性值相同。
scrapy crawl douban这时候启动后,部分日志内容如下:
2023-08-09 14:09:51 [scrapy.core.engine] DEBUG: Crawled (403)
<GET https://movie.douban.com/top250> (referer: None)
2023-08-09 14:09:51 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://movie.douban.com/top250>: HTTP status co
de is not handled or not allowed
2023-08-09 14:09:51 [scrapy.core.engine] INFO: Closing spider (finished)
当前爬虫运行状态是403,权限不足,这个问题在之前小节中有遇到过,具体原因也详细讲过了,不赘述。
我们需要在请求上设置请求头参数,那么在scrapy中如何设置请求头参数呢。在这里有两种方式可以设置。
1.在settings.py中有一个USER_AGENT参数,可以通过设置这个参数给请求添加请求头。设置方式更改配置文件:
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0)Gecko/20100101 Firefox/87.0'2.在middlewares.py中间件文件中的MycrawlerDownloaderMiddleware类中有一个process_request()的方法,这里可以设置。
def process_request(self, request, spider):
request.headers["User-Agent"] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) Gecko/20100101 Firefox/87.0'如果使用方式2进行设置还需要在配置文件中声明,具体在下一小节中详细说明配置内容。这里先使用方式1修改,完成后重新运行启动命令,看到打印的部分日志如下
…..
2023-08-09 14:53:25 [scrapy.core.engine] DEBUG: Crawled (200)
<GET https://movie.douban.com/top250> (referer: None)
200
2023-08-09 14:53:25 [scrapy.core.engine] INFO: Closing spider (finished)
…..
这时scrapy爬虫已经成功运行。
Scrapy配置详解
BOT_NAME
在settings.py文件中是Scrapy项目的全局配置,需要根据自定义设置的参数,BOT_NAME生成时自带,也就是项目名称。
BOT_NAME = 'mycrawler'
ROBOTSTXT_OBEY
每个网站都会有robots.txt文件,关于robots.txt在4.1.4中已经说明过,这个参数的设置scrapy爬虫是否遵守robots.txt协议,默认是True
ROBOTSTXT_OBEY = True
CONCURRENT_REQUESTS
配置Scrapy最大并发请求数,默认是16。如果是大批量爬取数据,可以设置高并发数。在settings.py文件中是注释掉的,如果修改默认值,则需要解除注释,使之生效。
CONCURRENT_REQUESTS = 32
DOWNLOAD_DELAY
设置下载等待的时间,即下载同一个网站之前每个请求之前是否添加延迟,默认是0,单位是秒。
DOWNLOAD_DELAY = 3
打开此配置后Scrapy对联系同一个网站的请求之间添加3秒的延迟。
COOKIES_ENABLED
是否禁用cookie,默认是启用
DEFAULT_REQUEST_HEADERS
设置自定义请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
SPIDER_MIDDLEWARES
启用或者禁用SPIDER中间件,启动则需要添加到下面参数值字典中
SPIDER_MIDDLEWARES = {
'mycrawler.middlewares.MycrawlerSpiderMiddleware': 543,
}
字典的key是中间件的类名,value是优先级或者说执行顺序。如果有多个执行顺序如图所示。Middleware1的value是100,Middleware2的value是200,请求从Engine到Spiders的时候,是先执行Middleware1的input(),在执行Middleware2的input(),返回的时候先执行Middleware2的output(),再执行Middleware1的output()。

DOWNLOADER_MIDDLEWARES
启用或者禁用下载中间件,启动则需要添加到下面参数值字典中。在上一小节中,如果使用中间件配置请求头,那么需要在这里设置开启,否则中间件将不生效。
DOWNLOADER_MIDDLEWARES = {
'mycrawler.middlewares.MycrawlerDownloaderMiddleware': 543,
}
ITEM_PIPELINES
配置项目管道,主要是用于后续清理、分析和保存数据。如果开启某些PIPELINES,需要在此进行声明配置。
ITEM_PIPELINES = {
'mycrawler.pipelines.MycrawlerPipeline': 300,
}
Scrapy保存数据
编写Item
在mycrawler目录下有一个items.py文件,item的定义为用于装载爬取到的数据的容器,这里需要给保存的对象以定义,用于储存爬虫抓取到的内容。在4.6.5小节中,我们已经定义了一个doubanMovie的类,这里可以直接复用doubanMovie类的属性,但是在Scrapy中与Python类的创建还有一点差别,详细参数如下。
import scrapy
class MycrawlerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 电影名称
name = scrapy.Field()
# 上映年份
year = scrapy.Field()
# 导演
directedBy = scrapy.Field()
# 类型
genre = scrapy.Field()
# 评价分数
rating_num = scrapy.Field()
# 评价人数
rating_people = scrapy.Field()
# 制片国家/地区
area = scrapy.Field()
# 电影语言
language = scrapy.Field()
MycrawlerItem类的属性为什么都设置为scrapy.Field()。Field对象 指明每个字段的元数据,对于接受的值没有任何限制。设置Field对象的主要目的是在一个地方定义好所有的元数据。打开源码查看下,发现Field类仅是内置字典类(dict)的一个别名,并没有提供额外的方法和属性。
class Field(dict):
"""Container of field metadata"""
完善DoubanSpider
在前面已经自动生成了的douban.py中创建了一个名为DoubanSpider的爬虫,现在我们根据之前写过的豆瓣电影的爬虫方法改造下,重写下DoubanSpider 类。
在Parse()方法中,主要是完成了两个操作:1.提取目标数据2.获取新的url。
import re
import scrapy
from bs4 import BeautifulSoup
from mycrawler.items import MycrawlerItem
class DoubanSpider(scrapy.Spider):
# 爬虫的唯一标识,不能重复
name = 'douban'
# 限定爬取该域名下的网页
allowed_domains = ['douban.com']
# 开始爬取的链接,可以设置多个
start_urls = ['']
def parse(self, response):
# response就是返回体
for link in self.getDetailLinks(response):
print(response.status)
yield scrapy.Request(url=link, callback=self.getMovieDetail)
def getDetailLinks(self, response):
# 添加headers参数
# 生成一个BeautifulSoup对象
soup = BeautifulSoup(response.text, 'html.parser')
# 搜索符合要求的标签
links = soup.find_all('a', href=re.compile("^https://movie.douban.com/subject/"))
linkList = set()
for link in links:
linkList.add(link['href'])
linkList = list(linkList)
return linkList
# 爬取详情链接中信息,并且返回一个对象
def getMovieDetail(self, response):
# 生成一个BeautifulSoup对象
soup = BeautifulSoup(response.text, 'html.parser')
info = soup.select("#info")
# 电影名称
name = soup.find('span', attrs={"property": "v:itemreviewed"})
name = name.string
# 上映年份
year = soup.select('.year')
year = year[0].get_text().replace("(", "").replace(")", "")
# 导演
directedBy = soup.find('a', attrs={"rel": "v:directedBy"})
directedBy = directedBy.string
# 类型
genre = soup.find('span', attrs={"property": "v:genre"})
genre = genre.string
# 分数
rating_num = soup.find('strong', attrs={"property": "v:average"})
rating_num = rating_num.string
# 评价人数
rating_people = soup.find('span', attrs={"property": "v:votes"})
rating_people = rating_people.string
infos = info[0].get_text().split("\n")
area = ""
language = ""
for info in infos:
if info.startswith("制片国家/地区"):
area = info.replace("制片国家/地区:", "").replace(" ", "").split("/")[0]
if info.startswith("语言"):
language = info.replace("语言:", "").replace(" ", "").split("/")[0]
item = MycrawlerItem()
item['name'] = name
item['year'] = year
item['directedBy'] = directedBy
item['genre'] = genre
item['rating_num'] = rating_num
item['rating_people'] = rating_people
item['area'] = area
item['language'] = language
yield item
重写的DoubanSpider 类中getDetailLinks()和getMovieDetail()引用自之前数据获取小节中的内容。
start_urls属性值是开始爬取的url,这里是10页电影列表的url。
在parse()方法中用到了一个yield函数。scrapy框架会根据 yield 返回的实例类型来执行不同的操作。在这里通过 yield scrapy.Reques()来发起一个请求,并通过 callback 参数为这个请求添加回调函数,在请求完成之后会将响应作为参数传递给回调函数。相当于执行的操作是:从getDetailLinks()函数中获得电影详情链接,通过yield每一个详情链接发起请求,返回之后再执行callback函数。
这里的回调函数是getMovieDetail(),也是我们自定义的,用于处理电影的信息。而在这里的yield item,scrapy框架会将这个对象传递给 pipelines.py做进一步处理。
完善pipelines
在DoubanSpider类中,parse()最终会通过yield item,把每一个电影信息的对象(实际上是一个封装的字典)传递给pipelines.py中的MycrawlerPipeline类下的process_item(self, item, spider)函数进行后续处理,进行数据分析或者储存等操作。
from itemadapter import ItemAdapter
class MycrawlerPipeline:
def process_item(self, item, spider):
print(item)
saveData2MySQL(item)
return item
def saveData2MySQL(movie):
# -- coding: utf-8 --
# 导入pymysql模块
import pymysql
# 连接database
conn = pymysql.connect(
host="101.37.124.133",
port=3306,
user="root",
password="Adong@123.",
database="datatest",
)
# 得到游标
cursor = conn.cursor()
# 定义要执行的SQL语句
sql = 'insert into movies(name,year,directedBy,genre, rating_num,rating_people, area,language) values (%s,%s,%s,%s,%s,%s,%s,%s)'
value = [movie['name'], movie['year'], movie['directedBy'], movie['genre'], movie['rating_num'],
movie['rating_people'], movie['area'], movie['language']]
cursor.execute(sql, value)
# 关闭光标对象
cursor.close()
# 提交数据,否则并没有持久化到数据库
conn.commit()
# 关闭数据库连接
conn.close()
在process_item进行了一步操作就是储存到数据库中。这样在严格意义上的一个scrapy爬虫已经做好了。
再次启动scrapy爬虫,既可以进行数据抓取。
scrapy crawl douban本章主要是介绍了scrapy框架的基本知识和使用,可以看出scrapy还是比较容易上手的,它只是帮助开发者实现了通用的功能,在具体的页面(网站)的爬取上还是需要开发者自行编写。熟悉scrapy之后,我们将在实战运行中使用它。后面将会涉及在scrapy中如何配置代理以及如何使用shell脚本启动scrapy和监控scrapy的状态。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号