数据分析:文本分类


本章节中所涉及的知识点偏向于机器学习的范畴,那么机器学习和数据分析有什么区别呢。简单来讲,数据分析是少量数据采样分析而机器学习是海量数据全部分析。比较好的理解一点是,数据分析会总结过去已经发生的事情,而机器学习是为了预测未来发生的事情。这两者也是有相辅相成的关系。我们可以通过机器学习预测的结果,进行数据分析,得到一个相对准确的结论,辅助人们进行决策判断等等。
本节中所学习的文本分类,也是为了提供为数据分析使用的素材。我们将完成文本分类的工作流程的各个步骤,包括特征提取、分类器、模型评估,最后我们将这些内容整合到一起,建立一个真实数据的文本分类系统。
一(1)、初识文本分类
文本分类也称为文本归类。这里文本数据可以是任何的短语、句子、段落或者文章等,这些数据从语料库、博客论坛或者互联网上的任何地方获取。文本分类最常用的应用是新闻分类、垃圾邮件分类、评价分类、客服问题分类、情感分析、评论挖掘、信息检索、Web文档自动分类、数字图书馆、自动文摘、文本过滤以及文档的组织和管理等等场景,我们后面实战中所涉及的内容也是基于网络数据进行分类。
目前文本分类的应用领域已经非常广泛,而且技术也日渐成熟。我们很多时候会遇见这样一个场景,就是在某些APP,尤其是银行类、通信运营商的这样用户群体覆盖面很广,通常用户有问题发给客服时候,会根据用户发送的问题,细化到某一个分类,然后对话机器人会自动回复,猜你想问,并且附带着这些的回答链接。
如果这些问题并没有解决你的问题,那么会提供人工客服的入口。这样可以通过自助式的回复,大大减少了人工客服的工作量,相应的本来需要10名客服才能完成的工作量,现在5名客服就可以完成,也减少了企业的用工成本。不同语言在文本分类的处理上也是不同的,本章将以中文分类为例讲解和实例演示。
中文分类一般过程如下:
1.文本预处理
文本预处理主要包括训练集、测试集获取。互联网上有很多可以直接用来作为文本分类的资源,比较经典的有搜狗实验室(http://www.sogou.com/labs/resource/list_pingce.php)新闻数据。主要内容包含了来自若干新闻站点2012年6月—7月期间国内,国际、体育、社会、娱乐等18个频道的新闻数据,提供URL和正文信息。这些就是很好的入门学习的分类数据,可以直接拿来使用。
如果是自行在互联网上爬取,那么需要考虑文本清洗和停用词处理的问题,要根据抓取的数据质量进行处理,这个步骤也包含在文本预处理中。
2.中文分词
中文分词的内容在8.1.2中已经提及,分词完成将对内容进行结构化表示。
3.特征提取(结构化表示)
统计文本词频,生成文本的词向量空间
4.模型训练(分类器)
通过各种分类算法进行训练、评估、调优分类器,提高性能
5.评价
根据准确率、召回率、F1 source等指标评价模型性能
步骤1、2其实已经在上一节中讲到,本章的重点说明特征提取和模型的训练。虽然本书的重点内容是讲解如何实际使用,并不会特别讲解每一个分类算法的实现细节,但是为了更方便读者理解,后面将进行简单的讲解和实例演示。
一(2)、自动文本分类
我们已经对文本分类的概念和范围等有所了解,也知道了文本分类所使用的场景。当需要分类的文档是十几个或者几十个的时候,我们可以通过人工手动分类,这样的分类的准确且方便。但是一旦需要分类的文本成千上万甚至数十万、到百万的时候,那么人工手动分类的方法就很难以完成这些任务。为了使文本分类更加高效快捷,我们需要考虑将这些任务自动化,这就是自动文本分类。
在自动文本分类的问题解决上,目前采用的最多的是机器学习的技术,而机器学习会根据实际场景通常有两种方式:有监督机器学习和无监督机器学习。
无监督学习(unsupervised learning)是机器学习的一种方法,没有给定事先标记过的训练示例,自动对输入的资料进行分类或分群。无监督学习的主要运用包含:聚类分析(cluster analysis)、关系规则(association rule)、维度缩减(dimensionality reduce)。它是监督式学习和强化学习等策略之外的一种选择。一个常见的无监督学习是数据聚类。[1]
有监督学习(Supervised learning),可以由训练资料中学到或建立一个模式(函数 / learning model),并依此模式推测新的实例。训练资料是由输入(通常是向量)和预期输出所组成。函数的输出可以是一个连续的值(称为回归分析)或是预测一个分类标签(称作分类)。[2]
两者相比较有如下区别:
- 有监督学习是一种目的明确的学习方式,我们知道预期是什么,而无监督没有明确的目标,无法预知结果。
- 监督学习需要提前给数据打标签,无监督学习不需要给数据打标签。
- 由于无监督学习没有目标和结果,无法衡量效果。而有监督学习可以衡量效果
目前主要是的两种有监督学习算法是分类和回归。
当预期的输出是离散的类型,这类的有监督学习的过程为分类。比如新闻分类、评分分类等等。本章中的主要是涉及的中文文本分类也是属于此类。
当预期的输出是连续的数值变量时,这类的有监督学习过程称为回归。比如预测房屋价格、股票走势等等。
现在我们在数学概念上定义对自动文本分类的过程。当前有一个文档的集合并且文档上带有相应的类别。集合可以表示为TS={(,), (,) ,…(,))},其中,…是文档列表,,…是文本类型。∈C={…},c表示所有的离散的分类的集合。
现在我们选择一个合适的有监督的学习算法F,当使用算法训练数据集TS后得到一个分类器X。这个过程就是训练过程,X就是得到的模型。
这个模型可以输入一个全新的未知类型的文档D,通过X可以预测∈C,这就是预测过程。
因为算法无法直接读取文本,通常需要将通过各种模型,将文本转成词向量,然后供分类算法使用。这些算法不仅仅可以用于文本分类上,其他的数据类型包括不限于视频、音频等等,前提是需要将这些数据处理成算法可以识别的向量。
通常我们会进行多次计算,来调优模型的内部参数,使用一些性能指标(准确率、召回率)来评估模型的性能,以此来评价模型的执行的好坏程度。
基于预测类型的数量有多种文本分类。二元分类是当前离散类型的数量为2,任何预测是两者之一。当一个预测类型超过2个的时候,那就称为多元分类,预测类型是多个结果中的一个。还有一种是多标签分类,表示每个预测结果可能产生多个预测类型。
二(1)、特征提取
特征提取(Feature extraction)在机器学习、模式识别和图像处理中有很多的应用。特征提取是从一个初始测量的资料集合中开始做,然后建构出富含资讯性而且不冗余的导出值,称为特征值(feature)它可以帮助接续的学习过程和归纳的步骤,在某些情况下可以让人更容易对资料做出较好的诠释。特征提取是一个降低维度的步骤,初始的资料集合被降到更容易管理的族群(特征)以便于学习,同时保持描述原始资料集的精准性与完整性。[3]
通俗一点讲,文本是由一系列的文字组成的,这个文字分词后根据类别后形成了一个词语的集合,对于这些原始数据,机器学习算法无法直接使用,需要先将他们转成可以识别的数值特征,也就是固定长度的向量,然后再交给机器学习的算法使用。那么将原始数据转成算法可以识别的特征的过程就是特征提取,有时也称为特征工程。
把文本文档的转换与表示数字的模型,作为形成向量维度的特定词项的数字向量,称为向量空间模型也叫词向量模型。在数学上有如下定义,假设在文档向量空间VS中有一个文档D。每个文档的维度和列数量将是空间中全部文档的不同词项总数量。因此向量空间表示为VS={,,…,},其中n是全部文档中不同词的数量。现在把文档D在向量空间表示为D={, …,},其中表示文档D中第n个词语的权重。权重可以是一个数值,可以是一个出现频率,或者是TF-IDF权重。
下面介绍常见的特征提取的模型:词袋模型和TF-IDF模型。在模型提取和分类器模型的训练的时候,我们会使用scikit-learn函数库。
Scikit-learn(sklearn)是Python 编写的免费软件机器学习库。它支持包括分类,回归,降维和聚类四大机器学习算法。还包括特征提取,数据处理和模型评估的三大模块。
很多的算法并不需要我们手动去实现,sklearn已经具备,所以后面我们会用sklearn来完成相关的特征提取和分类器的创建。
使用之前需要先安装,直接使用pip安装即可:
pip install scikit-learn二(2)、词袋模型
词袋模型是从文本中提取最简单又有效的模型。这是一个在自然语言处理和信息检索下被简化的表达模型。句子用一个袋子装着这些词的方式表现,这种表现方式不考虑语法以及词的顺序。目前词袋模型也被应用在电脑视觉(CV)领域。
词袋模型是将每个文档转化成一个向量,这个向量表示在整个文档空间中全部不同单词在该文档中出现的频率。下面使用代码介绍一下词袋模型是怎么将文档转成向量。
#引入sklearn库
from sklearn.feature_extraction.text import CountVectorizer
#实例化对象
count = CountVectorizer()
#输入语料库
corpus = [
'This is the first document.',
'Document is the second document.',
'And the third one.',
'Is this the first document?'
]
#将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在第i个文本下的词频
trans = count.fit_transform(corpus)
print('特征名称:')
print(count.get_feature_names())
print('特征向量:')
print(trans.toarray())
#代码运行结果:
特征名称:
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
特征向量:
[[0 1 1 1 0 0 1 0 1]
[0 2 0 1 0 1 1 0 0]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]get_feature_names()函数获取的是corpus预料库中所有词语的,toarray()就是count对象将词语转成了词频矩阵。CountVectorizer()默认使用的就是词袋模型。
特征名称就是corpus的所有出现的不重复单词,按照字母顺序排序。[0 1 1 1 0 0 1 0 1]的含义是,'and' 在第一个文本中出现了0次。'document'在第一个文本中出现了1次,后面以此类推,数字表示出现次数,没有出现为0次,出现1次为1,出现2次是2。
现在假设有一个新的文本“one is the fourth document”,那么这个文本的向量化应该是怎么表示呢。还是对照这词典,它的向量化结果是:[0 1 0 1 1 0 1 0 0],在新文本中有添加了‘fourth’,特征提取的模型是基于训练语料库,并不会受新文档而变化。所以词袋模型比较受限于训练语料库的文档向量空间。
二(3)、TF-IDF模型
词袋模型的向量完全依赖于单词出现的绝对频率,这其中会存在一些问题,语料库中全部温文档中出现较多的词语会有较高的频率,但是这些词会影响其他一些出现不如这些词频繁但是对于文本分类更有意义的词语。为了解决这一个问题,则产生了TF-IDF模型。
TF-IDF代表的是词频-逆文档频率,TF意思是词频(Term Frequency),IDF意思是逆向文件频率(Inverse Document Frequency),因此TF-IDF其实就是TF*IDF。
词频(TF)表示词条(关键字)在文本中出现的频率。用数学公式表达如下:
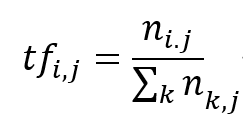
其中是该词在文件中出现的次数,分母则是文件中所有词汇出现的次数总和。

逆向文件频率 (IDF) 表示是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到。用数学公式表达如下:
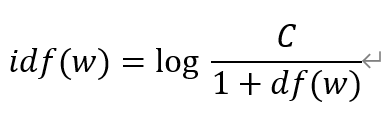
其中是词条w的idf,C表示整个语料库的文档总数。是包含w词条的文档总数。

为了避免分母为0的情况,所以分母+1。如果包含词条w的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
所以TF-IDF实际上是TF * IDF:
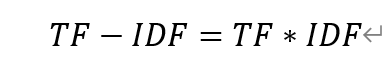
如果我们想使用TF-IDF模型来进行计算词向量,并不需要自己手动实现计算。在sklearn库中的TfidfVectorizer()函数已经实现,跟CountVectorizer()一样,它也会有很多的配置参数,不过这里我们就选择使用默认参数用代码演示一下。
#引入sklearn库
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
#实例化对象
tfidf = TfidfVectorizer()
corpus = [
'This is the first document.',
'Document is the second document.',
'And the third one.',
'Is this the first document?'
]
#将文本中的词语转换为TF-IDF矩阵
trans = tfidf.fit_transform(corpus)
print('特征名称:')
print(tfidf.get_feature_names())
print('特征向量:')
print(np.round(trans.toarray(), 4))
#代码运行结果:
特征名称:
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
特征向量:
[[0. 0.4181 0.5165 0.4181 0. 0. 0.3418 0. 0.5165]
[0. 0.7017 0. 0.3509 0. 0.5497 0.2869 0. 0. ]
[0.5528 0. 0. 0. 0.5528 0. 0.2885 0.5528 0. ]
[0. 0.4181 0.5165 0.4181 0. 0. 0.3418 0. 0.5165]]在词袋模型中'This is the first document.'的词向量为[0 1 1 1 0 0 1 0 1],在TF-IDF中的词向量是[0. 0.4181 0.5165 0.4181 0. 0. 0.3418 0. 0.5165]。在TF-IDF模型中,第3个和第9个的值最大,都是0.5165,对应的词条是 “first”和“this”。
可以看出“first”虽然词频少,但是最能体现文本的特征,相当于给每个词进行加权。这样更容易做到区分。
TF-IDF的优点是实现简单,相对容易理解。但是TF-IDF提取关键词的缺点也很明显,严重依赖语料库,需要选取质量较高且和所处理文本相符的语料库进行训练。
另外,对于IDF来说,它本身是一种试图抑制噪声的加权,本身倾向于文本中频率小的词,这使得TF-IDF的精度不高。此外TF-IDF还有一个缺点就是不能反映出词的位置信息,在对关键词进行提取的时候,词的位置信息,例如文本的标题、文本的首尾句等含有较重要的信息,应该赋予较高的权重。
二(3)、其他高级模型
前两个小节分别简单讲述了特征提取的两个模型:词袋模型和TF-IDF模型。当然随着NLP技术的发展,有了更优秀的特征提取模型。
在《Computer Science and Application 计算机科学与应用, 2013, 3, 64-68》中有一篇论文是《改进的 TF-IDF 关键词提取方法》中改进TF-IDF模型,提出TF-IWF (Term Frequency-Inverse Word Frequency),是一种语逆频率方式计算加权算法。TF计算方式相同IWF的计算方式做了如下改进:
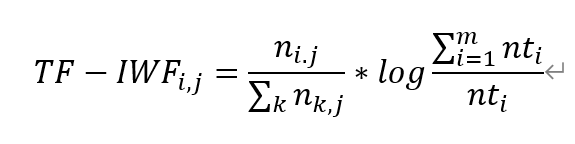
其中 TF 部分分子 ni,j表示词语 ti在文本 j 中出现的次 数,分母表示文本 j 中所有词语频词和,IWF 部分分 子表示语料库中所有词语频数之和,nti表示词语 ti在 语料库中出现的总频数。
还有一些词向量模式是使用的谷歌的word2vec(word to vector)模型。该模型由谷歌公司在2013年发布,是一个基于神经网络实现的,使用了连续词袋(Continuous Bag of Words)和skip-gram架构实现。该模型在gensim库中已经实现。
Gensim是一款开源的第三方Python工具包。它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,支持流式训练,并提供相似度计算,信息检索等一些常用的函数,感兴趣的读者可以查阅相关的资料并且尝试一下。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号