LLM技术探讨(1)---位置编码


1、为什么需要位置编码
这要从Transformer设计之初说起。在人类语言中,单词的位置和顺序定义了语法,也影响着语义,无法捕获单词的顺序,会导致我们很难理解一句话的含义。
在NLP任务中,对于任何神经网络架构,能够有效识别每个词的位置与词之间的顺序是十分关键的,传统的循环神经网络RNN,本身通过自回归的方式考虑了单词之间的顺序,然后Transformer架构不同于RNN,Transformer使用纯粹的自注意力来捕获词之间的联系,纯粹的自注意力具有置换不变的性质,换句话说,Transformer中的自注意力无法捕捉输入元素序列的顺序,因此我们需要一种方法将单词的顺序合并到Transformer架构中,于是位置编码应运而生。

image.png
2、关于绝对位置编码和相对位置编码
绝对位置编码的作用方式是告知Transformer架构每个元素在输入序列的位置,类似于为输入序列的每个元素打一个位置标签标明其绝对位置,而相对位置编码作用于注意力机制,告知Transformer架构两两元素之间的距离。
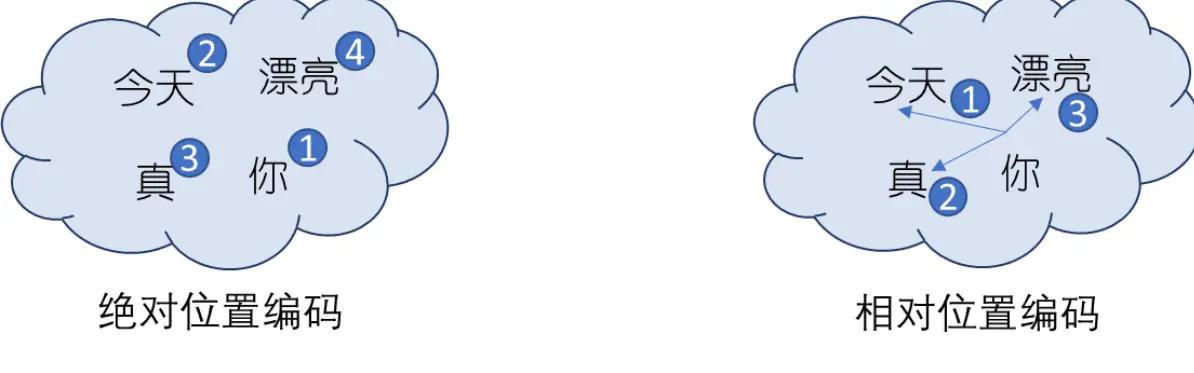
image.png
3、大语言模型中的旋转位置编码
旋转位置编码(Rotary Position Embedding,RoPE)是论文 Roformer: Enhanced Transformer With Rotray Position Embedding 提出的一种能够将相对位置信息依赖集成到 self-attention 中并提升 transformer 架构性能的位置编码方式。而目前很火的 LLaMA、GLM 模型也是采用该位置编码方式。 和相对位置编码相比,RoPE 具有更好的外推性,目前是大模型相对位置编码中应用最广的方式之一。
备注:什么是大模型外推性?
外推性是指大模型在训练时和预测时的输入长度不一致,导致模型的泛化能力下降的问题。例如,如果一个模型在训练时只使用了 512 个 token 的文本,那么在预测时如果输入超过 512 个 token,模型可能无法正确处理。这就限制了大模型在处理长文本或多轮对话等任务时的效果。本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-09-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号