【HTTP】Http协议理解


概述
关于http(中文名:超文本传输协议),你无须明白那冗长的理论解释,只需要明白3点:
1)HTTP请求方式:get\post\head…; 2)Http传输类型:均由Content-Type来标记; 3)响应(response)状态码;
概括:Http就是一种基于请求(request)、响应(response)与传输(在应用层上传输)的协议;
##为什么要理解HTTP协议—有目的性的开发
我们在开发的时候,常常会遇到性能瓶颈这个问题,这也是web开发中常见的问题。如今,前端工具(库、框架…)的风起云涌使得很多人迷失了学习方向,特别是新同学们。但是,要记住的是,在未来这些新生的库、框架…自动化工具诞生的目的都着力地偏向了“提升性能”这个方向。所以,大的方向是不变的。在今后的开发中、编码中,我们也应该着力从提升web页面性能的角度出发。
Http正是一个需要我们作为切入点的东西。理解HTTP,对性能的把握会更加清晰,做到有目的性的开发。
请求资源之URL
目前,互联网上的很多资源(图片、css、js、html…文件)的路径都是通过Http协议来定位的。即,我们要访问的很多资源都需要通过Http协议进行请求。那么,请求资源的桥梁就是通过URL这个东西。
URL的格式:http://host[“:”port][abs_path]
在URL中包含了请求这个资源的很多信息,如:
- host是资源所在的域名或IP地址;
- port 【可选】:端口号,默认为80;
- abs_path【可选】:指定请求资源的URI;
注:URI与URL的区别 例如有URL: http://image.baidu.com/sport/6660601.html 那么,URI是/sport/6660601.html ,URI是一个虚拟路径,唯一标识一个资源。
有了这个解释,你应该知道为什么在前端开发中,为什么希望在相关的资源文件上添加资源标识符(如,img/logo_8652a39.png)。(在fis3中则是使用md5戳作为文件指纹 http://fis.baidu.com/fis3/docs/beginning/release.html#%E6%96%87%E4%BB%B6%E6%8C%87%E7%BA%B9 )
HTTP请求(request)
Request由三部分构成:

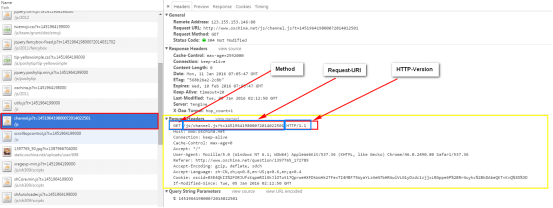
1.请求行
格式:Method Request_URI HTTP-Version CRLF
注:Method与Request_URI与HTTP-Version与CRLF之间用”空格”隔开。
解释:
- Method :请求方法,如
GET: 请求获取Request_URI所标识的资源; POST: 在Request_URI所标识的资源后面附加数据; HEAD: 请求获取由Request_URI所标识的资源的响应消息报头; PUT: 请求服务器存储一个资源,并用Request_URI作为其标识; DELETE: 请求服务器删除Request_URI所标识的资源; TRACE: 请求服务器回送收到的请求信息,主要用在测试; CONNECT:保留将来使用; OPTIONS:请求查询服务器的性能,或查询与资源相关的选项和需求;
- Request_URI:一个统一的资源标识;
- HTTP-Version:HTTP版本号;
- CRLF:回车或换行;
图示:
HTTP响应——Response
Response由三部分构成:
1. 状态行
格式:HTTP-Version Status-Code Reason-phrase CRLF
解释:
- HTTP-Version:HTTP协议版本号;
- Status-Code:响应状态码;状态码由3位数字组成,第一位数字定义响应的类别;
如: 1XX:指示信息——表示请求已接受,继续处理中; 2XX:成功接受请求; 3XX:重定向——要完成请求需要进一步的操作; 4XX:客户端错误——如语法错误,请求无法实现等; 5XX:服务器错误——服务器未能实现合法请求;
- Reason-phrase:对响应状态码的文本描述;
图示:

前面,我们只介绍了请求行与状态行,关于消息报头并没有介绍。请接着往下看。
HTTP之消息报头
消息报头有4中类型:

报头格式:
名字+”:” +空格+值 组成,名字与大小写无关。
####(1)普通报头
普通报头中,有部分是用于请求头和响应头。
如:
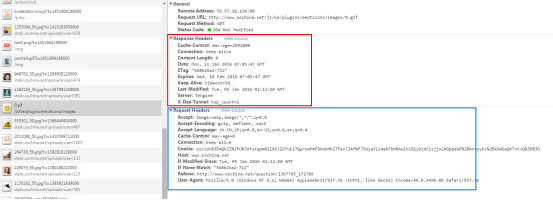
Cache-Control:缓存指令——包括 1)请求时的缓存指令: no-cache\no-store\max-age\max-stale\min-fresh\only-if-cached ; 2)响应时的缓存指令: Public\private\no-cache\no-store\no-transform\must-revalidate\proxy-revalidate \max-age\s-maxage Date:消息产生的日期和时间 Connection:允许发送指定链接的选项。
2.请求报头Request Headers
用于展示客户端向服务器端传递请求的附加信息以及客户端自身的信息。
如: (一) 、Accept
1)、Accept:指定客户端接受哪些类型的信息。如,Accept:image/webp,image/,/*;q=0.8,表示客户端希望接受有损压缩与无损压缩的图片文件格式。(注:webp是一种同时提供了有损压缩和无损压缩的图片文件格式。) 2)、Accept-Encoding:指定客户端接受的内容编码; 3)、Accept-Language:指定客户端接受的自然语言; 4)、Accept-Charset:指定客户端接受的字符集;
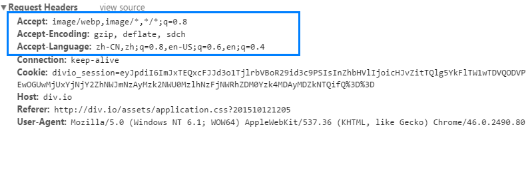
(二)、Host:主机域名或IP地址以及端口号;
(三)、User-Agent:包含客户端自身的信息,如操作系统、浏览器及其属性等;
3. 响应报头Response Headers
用户服务器端传递不能放在状态行中传递的附加信息,以及服务器端自身的信息和对Request_URI所标识的资源进行下一步访问的信息。
如:
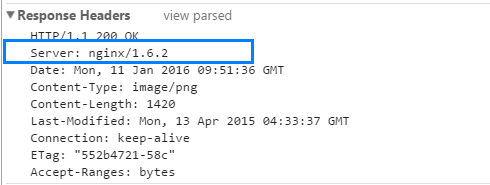
(一)、Server:有些类似请求报头中的User-Agent,Server包含了服务器端自身的信息,以及用于处理请求的软件信息。如:Server: nginx/1.6.2表示使用的服务器类型和版本号。
(二)、Location:常用在更换域名的时候,即重定向的时候。
4.实体报头
实体报头定义了关于实体正文和请求所标识的资源的元信息。(元信息,即类似标签中提供的描述HTML文档的信息,这里可以理解为描述资源的相关信息。) 如:
(一)、Content-Length:指明实体正文的长度,以”字节”为单位。 如:则表示这张图片的大小是4132字节(byte)。
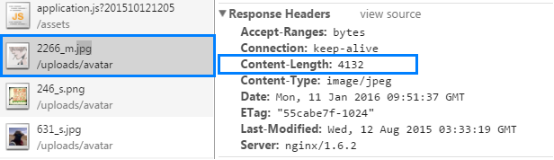
(二)、Content-Type:指明发送给接收者的实体正文的媒体类型。 如上图,Content-Type: image/jpeg 表示的是服务器端发送给接收者的实体正文类型是jpeg类型的图像文件格式。 (三)、Content-Encoding:指出已经被应用到实体正文的附加内容的编码。所以,要获得Content-Type中的媒体类型,必须采用相应的解码机制。如,Content-Encoding: gzip 表示服务器端使用gzip作为解码压缩的方式实体正文进行压缩后解压显示。
(四)、Content-Language:描述资源所使用的自然语言。
(五)、Last-Modified:指示资源最后被修改的日期和时间。如:
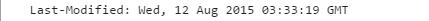
表示,最后一次该资源被修改的日期和时间是 2015年8月12日,周三,03时33分19秒, 时间采用GMT(格林尼治\世界标准时间\本初子午线时间,比北京时间晚8小时)时间格式。
(六)、Expires: 指示响应资源的过期日期和时间。可以用于缓存,在未过期的时间段内,再次访问,则从本地缓存中加载资源。如:
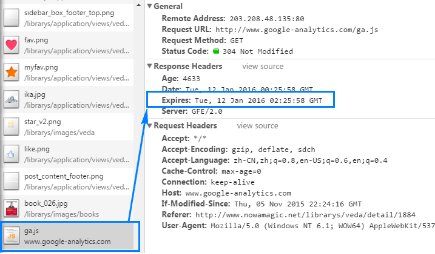
表示ga.js这个资源的过期时间是在2016年1月12日,02:25:58GMT这个时间内。 你可以稍后再访问一下,看看这个资源的过期时间有没有变化。 一段时间之后(大约2小时)我们再来看下,这个值:
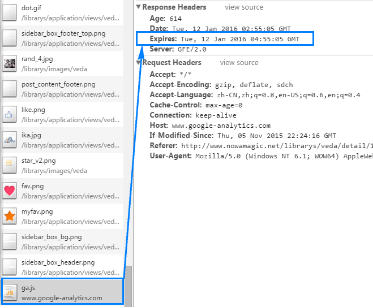
可以看出,服务器端对这个值进行了动态更新。 注:若设置Expires:0 则表示浏览器不对页面缓存;
回顾
总结
以上,我们大体上介绍了3点:
1、HTTP请求——Request
2、HTTP响应——Response
3、四类消息报头
基于以上三点我们去理解HTTP,在实际开发中观察每个会话(Session)的状态与内容。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号