【前端面试题】我靠它拿到了大厂Offer


新的一天,加油!
每日一道笔试题,遇见不一样的自己!
第102题:请输出下列代码执行的结果
//参考:忍者秘籍第二版
console.log('script start')
let promise1 = new Promise(function (resolve) {
console.log('promise1')
resolve()
console.log('promise1 end')
}).then(function () {
console.log('promise2')
})
setTimeout(function(){
console.log('settimeout')
})
console.log('script end')解释:
输出结果:script start->promise1->promise1 end->script end->promise2->settimeout当JS主线程执行到Promise对象时,
- promise1 是
resolved或rejected: 那这个 task 就会放入当前事件循环队列的microtask queue - promise1 是
pending: 这个 task 就会放入事件循环队列的未来的某个(可能下一个)回合的microtask queue中 - setTimeout 的回调也是个 task ,它会被放入
macrotask queue,即使是 0ms 的情况
第101题:请输出下列代码执行的结果
//参考:忍者秘籍第二版
async function async1(){
console.log('async1 start');
await async2();
console.log('async1 end')
}
async function async2(){
console.log('async2')
}
console.log('script start');
async1();
console.log('script end')解释:
输出结果:script start->async1 start->async2->script end->async1 end- async 函数返回一个 Promise 对象(await通过返回一个Promise对象来实现同步的效果),当函数执行的时候,一旦遇到 await 就会先返回,等到触发的异步操作完成,再执行函数体内后面的语句。可以理解为,是让出了线程,跳出了 async 函数体。
- await的含义为等待,也就是 async 函数需要等待await后的函数执行完成并且有了返回结果(Promise对象)之后,才能继续执行下面的代码。
第100题:请解释下列三个方法在判断 是否是数组类型 时的区别:
- Object.prototype.toString.call()
- instanceof
- Array.isArray()
参考:js高级程序设计第三版解释:
- Object.prototype.toString.call()
每一个继承 Object 的对象都有
toString方法,如果toString方法没有重写的话,会返回 Object type,其中 type 为对象的类型。但是,当除了 Object 类型的对象外,其他类型直接使用 toString 方法时,会直接返回内容的字符串,所以我们需要使用call或者apply方法来改变toString方法的执行上下文。
例如:
const arr = ['abc','bca'];
arr.toString(); // "abc,bca"
Object.prototype.toString.call(arr); // "[object Array]"- 结论:这种方法对于所有基本的数据类型都能进行判断,即使是 null 和 undefined 。通常,该方法常用于判断浏览器内置对象。
instanceof
instanceof 的内部机制是通过判断对象的原型链中是不是能找到类型的 prototype。
使用 instanceof判断一个对象是否为数组,instanceof 会判断这个对象的原型链上是否会找到对应的 Array 的原型,找到返回 true,否则返回 false
[] instanceof Array; // true但 instanceof 只能用来判断对象类型,原始类型不可以。并且所有对象类型 instanceof Object 都是 true。
例如:
[] instanceof Object; // trueArray.isArray()
Array.isArray()是ES5新增的方法,当不存在 Array.isArray() ,可以用 Object.prototype.toString.call() 实现。
if (!Array.isArray) {
Array.isArray = function(arg) {
return Object.prototype.toString.call(arg) === '[object Array]';
};
}同时,Array.isArray()优于instanceof,特别是在检测Array实例时,Array.isArray可以检测出iframes下的Array实例。
例如:
let iframe = document.createElement('iframe');
document.body.appendChild(iframe);
xArray = window.frames[window.frames.length-1].Array;
let arr = new xArray(1,2,3); // [1,2,3]
Array.isArray(arr); // true
arr instanceof Array; // false第99题:实现下列功能
输入: [2,3,4,6,7,9]
输出: '2~4,6~7,9'const nums = [2,3,4,6,7,9];
function example(num) {
let result = [];
let temp = num[0]
num.forEach((value, index) => {
if (value + 1 !== num[index + 1]) {
if (temp !== value) {
result.push(`${temp}~${value}`)
} else {
result.push(`${value}`)
}
temp = num[index + 1]
}
})
return result;
}
console.log(example(nums).join(','))第98题:如何优化浏览器的Repaint和Reflow
第97题:解释下Vue是如何进行双向数据绑定的?View->Model和Model-View,原理是什么
第96题:输出下列代码执行结果
String('123') == new String('123'); //true,==时做了隐式转换,调用了toString
String('123') === new String('123');//false,两者的类型不一样,前者是string,后者是objectvar name = 'abc';
(function() {
if (typeof name == 'undefined') {
name = 'cba';
console.log(name);
} else {
console.log(name);
}
})();
1、首先进入立即执行函数作用域当中,获取name属性
2、在当前作用域没有找到name
3、通过作用域链找到最外层,得到name属性
4、执行else的内容,输出 abc第95题:输出下列代码执行结果
2 + "3";
3 * "5";
[6, 3] + [3, 6];
"b" + + "c"; //解释:
2 + "3";
加性操作符:如果只有一个操作数是字符串,则将另一个操作数转换为字符串,然后再将两个字符串拼接起来
所以值为:“23”
3 * "5";
乘性操作符:如果有一个操作数不是数值,则在后台调用 Number()将其转换为数值
[6, 3] + [3, 6];
Javascript中所有对象基本都是先调用valueOf方法,如果不是数值,再调用toString方法。
所以两个数组对象的toString方法相加,值为:"6,33,6"
"b" + + "c";
后边的“+”将作为一元操作符,如果操作数是字符串,将调用Number方法将该操作数转为数值,如果操作数无法转为数值,则为NaN。
所以值为:"bNaN"第94题:写出如下代码的打印结果
function Foo() {
Foo.a = function() {
console.log(1)
}
this.a = function() {
console.log(2)
}
}
Foo.prototype.a = function() {
console.log(3)
}
Foo.a = function() {
console.log(4)
}
Foo.a();
let obj = new Foo();
obj.a();
Foo.a();- 解析
function Foo() {
Foo.a = function() {
console.log(1)
}
this.a = function() {
console.log(2)
}
}
// 以上只是 Foo 的构建方法,没有产生实例,此刻也没有执行
Foo.prototype.a = function() {
console.log(3)
}
// 现在在 Foo 上挂载了原型方法 a ,方法输出值为 3
Foo.a = function() {
console.log(4)
}
// 现在在 Foo 上挂载了直接方法 a ,输出值为 4
Foo.a();
// 立刻执行了 Foo 上的 a 方法,也就是刚刚定义的,所以
// # 输出 4
let obj = new Foo();
/* 这里调用了 Foo 的构建方法。Foo 的构建方法主要做了两件事:
1. 将全局的 Foo 上的直接方法 a 替换为一个输出 1 的方法。
2. 在新对象上挂载直接方法 a ,输出值为 2。
*/
obj.a();
// 因为有直接方法 a ,不需要去访问原型链,所以使用的是构建方法里所定义的 this.a,
// # 输出 2
Foo.a();
// 构建方法里已经替换了全局 Foo 上的 a 方法,所以
// # 输出 1第93题:用 JavaScript 写一个函数,输入 int 型,返回整数逆序后的字符串。
如:输入整型 1234,返回字符串“4321”。要求必须使用递归函数调用,不能用全局变量,输入函数必须只有一个参数传入,必须返回字符串。
function fun(num){
let num1 = num / 10;
let num2 = num % 10;
if(num1<1){
return num;
}else{
num1 = Math.floor(num1)
return `${num2}${fun(num1)}`
}
}
var a = fun(12345)
console.log(a)第92题:写出如下代码的打印结果
function changeObjProperty(o) {
o.siteUrl = "http://www.baidu.com"
o = new Object()
o.siteUrl = "http://www.google.com"
}
let webSite = new Object();
changeObjProperty(webSite);
console.log(webSite.siteUrl);输出:www.baidu.com //原因:函数的形参是值传递的
第91题:前端加密的常见场景和方法
加密的目的,简而言之就是将明文转换为密文、甚至转换为其他的东西,用来隐藏明文内容本身,防止其他人直接获取到敏感明文信息、或者提高其他人获取到明文信息的难度。 通常我们提到加密会想到密码加密、HTTPS 等关键词
场景-密码传输
前端密码传输过程中如果不加密,在日志中就可以拿到用户的明文密码,对用户安全不太负责。
这种加密其实相对比较简单,可以使用 PlanA-前端加密、后端解密后计算密码字符串的MD5/MD6存入数据库;也可以 PlanB-直接前端使用一种稳定算法加密成唯一值、后端直接将加密结果进行MD5/MD6,全程密码明文不出现在程序中。
- PlanA 使用 Base64 / Unicode+1 等方式加密成非明文,后端解开之后再存它的 MD5/MD6
- PlanB 直接使用 MD5/MD6 之类的方式取 Hash ,让后端存 Hash 的 Hash 。
场景-数据包加密
应该大家有遇到过:打开一个正经网站,网站底下蹦出个不正经广告——比如X通的流量浮层,X信的插入式广告……(我没有针对谁)
但是这几年,我们会发现这种广告逐渐变少了,其原因就是大家都开始采用 HTTPS 了。
被人插入这种广告的方法其实很好理解:你的网页数据包被抓取->在数据包到达你手机之前被篡改->你得到了带网页广告的数据包->渲染到你手机屏幕。
而 HTTPS 进行了包加密,就解决了这个问题。严格来说我认为从手段上来看,它不算是一种前端加密场景;但是从解决问题的角度来看,这确实是前端需要知道的事情。
- Plan 全面采用 HTTPS
场景-展示成果加密
经常有人开发网页爬虫爬取大家辛辛苦苦一点一点发布的数据成果,有些会影响你的竞争力,有些会降低你的知名度,甚至有些出于恶意爬取你的公开数据后进行全量公开……比如有些食谱网站被爬掉所有食谱,站点被克隆;有些求职网站被爬掉所有职位,被拿去卖信息;甚至有些小说漫画网站赖以生存的内容也很容易被爬取。
- Plan 将文本内容进行展示层加密,利用字体的引用特点,把拿给爬虫的数据变成“乱码”。 举个栗子:正常来讲,当我们拥有一串数字“12345”并将其放在网站页面上的时候,其实网站页面上显示的并不是简单的数字,而是数字对应的字体的“12345”。这时我们打乱一下字体中图形和字码的对应关系,比如我们搞成这样:
图形:1 2 3 4 5 字码:2 3 1 5 4
这时,如果你想让用户看到“12345”,你在页面中渲染的数字就应该是“23154”。这种手段也可以算作一种加密。
具体的实现方法可以看一下《Web 端反爬虫技术方案》。
参考
第90题:模拟实现一个深拷贝,并考虑对象相互引用以及 Symbol 拷贝的情况
一个不考虑其他数据类型的公共方法,基本满足大部分场景
function deepCopy(target, cache = new Set()) {
if (typeof target !== 'object' || cache.has(target)) {
return target
}
if (Array.isArray(target)) {
target.map(t => {
cache.add(t)
return t
})
} else {
return [...Object.keys(target), ...Object.getOwnPropertySymbols(target)].reduce((res, key) => {
cache.add(target[key])
res[key] = deepCopy(target[key], cache)
return res
}, target.constructor !== Object ? Object.create(target.constructor.prototype) : {})
}
}主要问题是
symbol作为key,不会被遍历到,所以stringify和parse是不行的- 有环引用,
stringify和parse也会报错 我们另外用getOwnPropertySymbols可以获取symbol key可以解决问题1,用集合记忆曾经遍历过的对象可以解决问题2。当然,还有很多数据类型要独立去拷贝。比如拷贝一个RegExp,lodash是最全的数据类型拷贝了,有空可以研究一下
另外,如果不考虑用symbol做key,还有两种黑科技深拷贝,可以解决环引用的问题,比stringify和parse优雅强一些。
function deepCopyByHistory(target) {
const prev = history.state
history.replaceState(target, document.title)
const res = history.state
history.replaceState(prev, document.title)
return res
}
async function deepCopyByMessageChannel(target) {
return new Promise(resolve => {
const channel = new MessageChannel()
channel.port2.onmessage = ev => resolve(ev.data)
channel.port1.postMessage(target)
}).then(data => data)
}无论哪种方法,它们都有一个共性:失去了继承关系,所以剩下的需要我们手动补上去了,故有Object.create(target.constructor.prototype)的操作
第89题:vue 在 v-for 时给每项元素绑定事件需要用事件代理吗?为什么?
事件代理作用主要是 2 个:
- 将事件处理程序代理到父节点,减少内存占用率
- 动态生成子节点时能自动绑定事件处理程序到父节点
//不使用事件代理,每个 span 节点绑定一个 click 事件,并指向同一个事件处理程序
<div>
<span
v-for="(item,index) of 100000"
:key="index"
@click="handleClick">
{{item}}
</span>
</div>
//不使用事件代理,每个 span 节点绑定一个 click 事件,并指向不同的事件处理程序
<div>
<span
v-for="(item,index) of 100000"
:key="index"
@click="function () {}">
{{item}}
</span>
</div>
// 使用事件代理
<div @click="handleClick">
<span
v-for="(item,index) of 100000"
:key="index">
{{item}}
</span>
</div>
使用事件代理无论是监听器数量和内存占用率都比前两者要少第88题:给定两个大小为m和n的有序数组nums1和nums2。 请你找出这两个有序数组的中位数,并且要求算法的时间复杂度为 O(log(m + n))
const findMidNum = function(arr1,arr2) {
for(let i=0;i<arr2.length;i++) {
arr1.push(arr2[i]);
}
arr1 = arr1.sort((a,b)=>{return b-a;})
if(arr1.length%2===0) {
return (arr1[arr1.length/2]+arr1[arr1.length/2-1])/2
}else {
return arr1[(arr1.length-1)/2]
}
}
console.log(findMidNum([1,2],[3,5,6]))第87题:已知数据格式,实现一个函数 fn 找出链条中所有的父级 id
const data = [{
id: '1',
name: 'test1',
children: [
{
id: '11',
name: 'test11',
children: [
{
id: '111',
name: 'test111'
},
{
id: '112',
name: 'test112'
}
]
},
{
id: '12',
name: 'test12',
children: [
{
id: '121',
name: 'test121'
},
{
id: '122',
name: 'test122'
}
]
}
]
}];
let res = [];
const findId = (list, value) => {
let len = list.length;
for (let i in list) {
const item = list[i];
if (item.id == value) {
return res.push(item.id), [item.id];
}
if (item.children) {
if (findId(item.children, value).length) {
res.unshift(item.id);
return res;
}
}
if (i == len - 1) {
return res;
}
}
};第86题:介绍下 HTTPS 中间人攻击
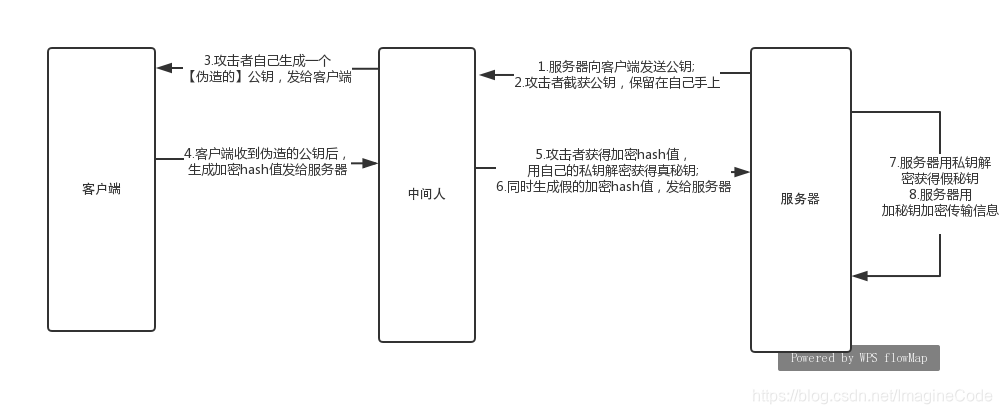
中间人攻击过程如下:
- 服务器向客户端发送公钥。
- 攻击者截获公钥,保留在自己手上。
- 然后攻击者自己生成一个【伪造的】公钥,发给客户端。
- 客户端收到伪造的公钥后,生成加密hash值发给服务器。
- 攻击者获得加密hash值,用自己的私钥解密获得真秘钥。
- 同时生成假的加密hash值,发给服务器。
- 服务器用私钥解密获得假秘钥。
- 服务器用加秘钥加密传输信息 。
防范方法:
服务端在发送浏览器的公钥中加入CA证书,浏览器可以验证CA证书的有效性
第85题:实现模糊搜索结果的关键词高亮显示
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>auto complete</title>
<style>
bdi {
color: rgb(0, 136, 255);
}
li {
list-style: none;
}
</style>
</head>
<body>
<input class="inp" type="text">
<section>
<ul class="container"></ul>
</section>
</body>
<script>
function debounce(fn, timeout = 300) {
let t;
return (...args) => {
if (t) {
clearTimeout(t);
}
t = setTimeout(() => {
fn.apply(fn, args);
}, timeout);
}
}
function memorize(fn) {
const cache = new Map();
return (name) => {
if (!name) {
container.innerHTML = '';
return;
}
if (cache.get(name)) {
container.innerHTML = cache.get(name);
return;
}
const res = fn.call(fn, name).join('');
cache.set(name, res);
container.innerHTML = res;
}
}
function handleInput(value) {
const reg = new RegExp(`\(${value}\)`);
const search = data.reduce((res, cur) => {
if (reg.test(cur)) {
const match = RegExp.$1;
res.push(`<li>${cur.replace(match, '<bdi>$&</bdi>')}</li>`);
}
return res;
}, []);
return search;
}
const data = ["上海野生动物园", "上饶野生动物园", "北京巷子", "上海中心", "上海黄埔江", "迪士尼上海", "陆家嘴上海中心"]
const container = document.querySelector('.container');
const memorizeInput = memorize(handleInput);
document.querySelector('.inp').addEventListener('input', debounce(e => {
memorizeInput(e.target.value);
}))
</script>
</html>第84题:设计并实现 Promise.race()
Promise.myrace = function(iterator) {
return new Promise ((resolve,reject) => {
try {
let it = iterator[Symbol.iterator]();
while(true) {
let res = it.next();
console.log(res);
if(res.done) break;
if(res.value instanceof Promise) {
res.value.then(resolve,reject);
} else {
resolve(res.value)
}
}
} catch (error) {
reject(error)
}
})
}第83题:实现 convert 方法,把原始 list 转换成树形结构,要求尽可能降低时间复杂度
先生成新结构map,用原先的结构与其比较,对原结构改造。
function convert(list) {
const res = []
const map = list.reduce((res, v) => (res[v.id] = v, res), {})
for (const item of list) {
if (item.parentId === 0) {
res.push(item)
continue
}
if (item.parentId in map) {
const parent = map[item.parentId]
parent.children = parent.children || []
parent.children.push(item)
}
}
return res
}
let list =[
{id:1,name:'部门A',parentId:0},
{id:2,name:'部门B',parentId:0},
{id:3,name:'部门C',parentId:1},
{id:4,name:'部门D',parentId:1},
{id:5,name:'部门E',parentId:2},
{id:6,name:'部门F',parentId:3},
{id:7,name:'部门G',parentId:2},
{id:8,name:'部门H',parentId:4}
];
const result = convert(list);
console.table(result);第82题:在输入框中如何判断输入的是一个正确的网址
主要解析http,https:
function isUrl(url) {
const a = document.createElement('a')
a.href = url
return [
/^(http|https):$/.test(a.protocol),
a.host,
a.pathname !== url,
a.pathname !== `/${url}`,
].find(x => !x) === undefined
}第81题:算法题之–两数之和
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。 你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]- 解析
(1). 直接遍历两次数组
//:时间复杂度为O(N*N)
find2Num([2,7,11,15],9);
function find2Num(arr,sum){
if(arr == '' || arr.length == 0){
return false;
}
let result = [];
for(var i = 0; i < arr.length ; i++){
for(var j = i + 1; j <arr.length; j++){
if(arr[i] + arr[j] == sum){
result.push(i);
result.push(j);
}
}
}
console.log(result);
}(2)
先将整型数组排序,排序之后定义两个指针left和right。 left指向已排序数组中的第一个元素,right指向已排序数组中的最后一个元素, 将 arrleft+arrright与 给定的元素比较,若前者大,right–;若前者小,left++; 若相等,则找到了一对整数之和为指定值的元素。
//时间复杂度为O(NlogN)
function find2Num(arr,sum){
if(arr == '' || arr.length == 0){
return false;
}
var left = 0, right = arr.length -1,result = [];
while(left < right){
if(arr[left] + arr[right] > sum){
right--;
}
else if(arr[left] + arr[right] < sum){
left++;
}
else{
console.log(arr[left] + " + " + arr[right] + " = " + sum);
result.push(left);
result.push(right);
left++;
right--;
}
}
console.log(result);
}第80题:react-router 里的 标签和 标签有什么区别
<Link>是react-router里实现路由跳转的链接,一般配合<Route>使用,react-router接管了其默认的链接跳转行为,区别于传统的页面跳转,<Link>的“跳转”行为只会触发相匹配的<Route>对应的页面内容更新,而不会刷新整个页面。
Link点击事件handleClick部分源码:
if (_this.props.onClick) _this.props.onClick(event);
if (!event.defaultPrevented && // onClick prevented default
event.button === 0 && // ignore everything but left clicks
!_this.props.target && // let browser handle "target=_blank" etc.
!isModifiedEvent(event) // ignore clicks with modifier keys
) {
event.preventDefault();
var history = _this.context.router.history;
var _this$props = _this.props,
replace = _this$props.replace,
to = _this$props.to;
if (replace) {
history.replace(to);
} else {
history.push(to);
}
}Link做了3件事情:
- 有onclick那就执行onclick
- click的时候阻止a标签默认事件(这样子点击
<a href="/abc">123</a>就不会跳转和刷新页面) - 再取得跳转
href(即是to),用history(前端路由两种方式之一,history & hash)跳转,此时只是链接变了,并没有刷新页面 - 而
<a>标签就是普通的超链接了,用于从当前页面跳转到href指向的另一个页面(非锚点情况)。
如何禁掉 <a> 标签默认事件,禁掉之后如何实现跳转
- 禁掉 a 标签的默认事件,可以在点击事件中执行
event.preventDefault(); - 禁掉默认事件的 a 标签 可以使用
history.pushState()来改变页面 url,这个方法还会触发页面的hashchange事件,Router 内部通过捕获监听这个事件来处理对应的跳转逻辑。
第79题:柯里化函数
实现一个Add函数,满足以下功能: add(1); // 1 add(1)(2); // 3 add(1)(2)(3); // 6 add(1)(2, 3); // 6 add(1, 2)(3); // 6 add(1, 2, 3); // 6
- 解析:
function add(){
let args = [...arguments];
let addfun = function(){
args.push(...arguments);
return addfun;
}
addfun.toString = function(){
return args.reduce((a,b)=>{
return a + b;
});
}
return addfun;
}参考:
第78题:给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序
const result = (arr) => arr.filter(Boolean).concat([...Array(arr.length - arr.filter(Boolean).length).fill(0)])
console.log(result([0,1,0,3,0,12,0,0]))const arr = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 3, 0, 0, 0, 1, 9, 9, 9, 0, 0, 0, 0, 1, 0, 3, 12, 0, 0, 0, 0];
const len = arr.length;
console.log(len)
for (let i = len; i >= 0; i--) {
if (arr[i] === 0) {
arr.splice(i, 1);
arr.push(0)
}
}
console.log(arr)第77题:打印出 1 - 10000 之间的所有对称数, 例如:121、1331 等
[...Array(10000).keys()].filter((x) => {
return x.toString().length > 1 && x === Number(x.toString().split('').reverse().join(''))
})
let result=[]
for(let i=1;i<10;i++){
result.push(i)
result.push(i*11)
for(let j=0;j<10;j++){
result.push(i*101+j*10)
result.push(i*1001+j*110)
}
}这个方法把1~9考虑在内:

第76题: Promise.all 的使用、原理实现及错误处理
Promise.all(iterable) 方法返回一个 Promise 实例,此实例在 iterable 参数内所有的 promise 都“完成(resolved)”或参数中不包含 promise 时回调完成(resolve);如果参数中 promise 有一个失败(rejected),此实例回调失败(reject),失败原因的是第一个失败 promise 的结果。
- 如果传入的参数是一个
空的可迭代对象,则返回一个已完成(already resolved)状态的 Promise。 - 如果传入的参数
不包含任何 promise,则返回一个异步完成(asynchronously resolved) Promise。注意:GoogleChrome 58 在这种情况下返回一个已完成(already resolved)状态的 Promise。 其它情况下返回一个处理中(pending)的Promise。这个返回的 promise 之后会在所有的 promise 都完成或有一个 promise 失败时异步地变为完成或失败。 见下方关于“Promise.all 的异步或同步”示例。返回值将会按照参数内的 promise 顺序排列,而不是由调用 promise 的完成顺序决定。- 使用:
var p1 = Promise.resolve(3);
var p2 = 1337;
var p3 = new Promise((resolve, reject) => {
setTimeout(resolve, 100, 'foo');
});
Promise.all([p1, p2, p3]).then(values => {
console.log(values); // [3, 1337, "foo"]
});- 错误处理:
var p1 = new Promise((resolve, reject) => {
setTimeout(resolve, 1000, 'one');
});
var p2 = new Promise((resolve, reject) => {
setTimeout(resolve, 2000, 'two');
});
var p3 = new Promise((resolve, reject) => {
setTimeout(resolve, 3000, 'three');
});
var p4 = new Promise((resolve, reject) => {
setTimeout(resolve, 4000, 'four');
});
var p5 = new Promise((resolve, reject) => {
reject('reject');
});
Promise.all([p1, p2, p3, p4, p5]).then(values => {
console.log(values);
}, reason => {
console.log(reason)
});
//From console:
//"reject"
//You can also use .catch
Promise.all([p1, p2, p3, p4, p5]).then(values => {
console.log(values);
}).catch(reason => {
console.log(reason)
});
//From console:
//"reject"Promise.all 在任意一个传入的 promise 失败时返回失败。例如,如果你传入的 promise中,有四个 promise 在一定的时间之后调用成功函数,有一个立即调用失败函数,那么 Promise.all 将立即变为失败。
参考:
第75题:input 搜索 如何处理中文输入
触发compositionstart时,文本框会填入 “虚拟文本”(待确认文本),同时触发input事件;在触发compositionend时,就是填入实际内容后(已确认文本)。例如:中文输入法输入内容时还没将中文插入到输入框就验证的问题,
为此,我们可以在中文输入完成以后才验证。即:在compositionend发生后再进行逻辑的处理:
var cpLock = true;
$('.com_search_input').on('compositionstart', function () {
cpLock = false;
// console.log("compositionstart")
});
$('.com_search_input').on('compositionend', function () {
cpLock = true;
// console.log("compositionend")
});
$(".com_search_input").on("input",function(e){
e.preventDefault();
var _this = this;
// console.log("input");
setTimeout(function(){
if (cpLock) {
//开始写逻辑
console.log("逻辑")
}
},0)
})使用延时器的原因:
因为选词结束的时候input会比compositionend先一步触发,此时cpLock还未调整为true,所以不能触发到console.log(“逻辑”),故用setTimeout将其优先级滞后。
第74题:Vue 的父组件和子组件生命周期钩子执行顺序是什么
- 加载渲染过程:
父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted - 子组件更新过程:
父beforeUpdate->子beforeUpdate->子updated->父updated - 父组件更新过程:
父beforeUpdate->父updated - 销毁过程:
父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
第73题:旋转数组
问题描述:
将包含* n* 个元素的数组向右旋转 *k *步。 例如,如果 n = 7 , k = 3,给定数组 1,2,3,4,5,6,7 ,向右旋转后的结果为 5,6,7,1,2,3,4。
解析:利用解构数组和数组的splice方法
function rotateArr(arr,k) {
return [...arr.splice(k+1),...arr];
}
rotateArr([1,2,3,4,5,6,7],3);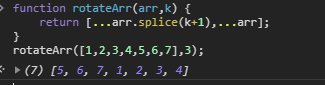
第72题:对象的键名的转换
- 对象的键名
只能是字符串和 Symbol 类型。 其他类型的键名会被转换成字符串类型。对象转字符串默认会调用 toString 方法。
考察:下列代码输出结果:
// example 1
var a={}, b='123', c=123;
a[b]='b';
a[c]='c'; // c 的键名会被转换成字符串'123',这里会把 b 覆盖掉。
console.log(a[b]); // 'c'
// example 2
var a={}, b=Symbol('123'), c=Symbol('123');
a[b]='b';// b 是 Symbol 类型,不需要转换
a[c]='c';// c 是 Symbol 类型,不需要转换。任何一个 Symbol 类型的值都是不相等的,所以不会覆盖掉 b
console.log(a[b]);//'b'
// example 3
var a={}, b={key:'123'}, c={key:'456'};
// b 不是字符串也不是 Symbol 类型,需要转换成字符串。
// 对象类型会调用 toString 方法转换成字符串 [object Object]。
a[b]='b';
// c 不是字符串也不是 Symbol 类型,需要转换成字符串。
// 对象类型会调用 toString 方法转换成字符串 [object Object]。这里会把 b 覆盖掉。
a[c]='c';
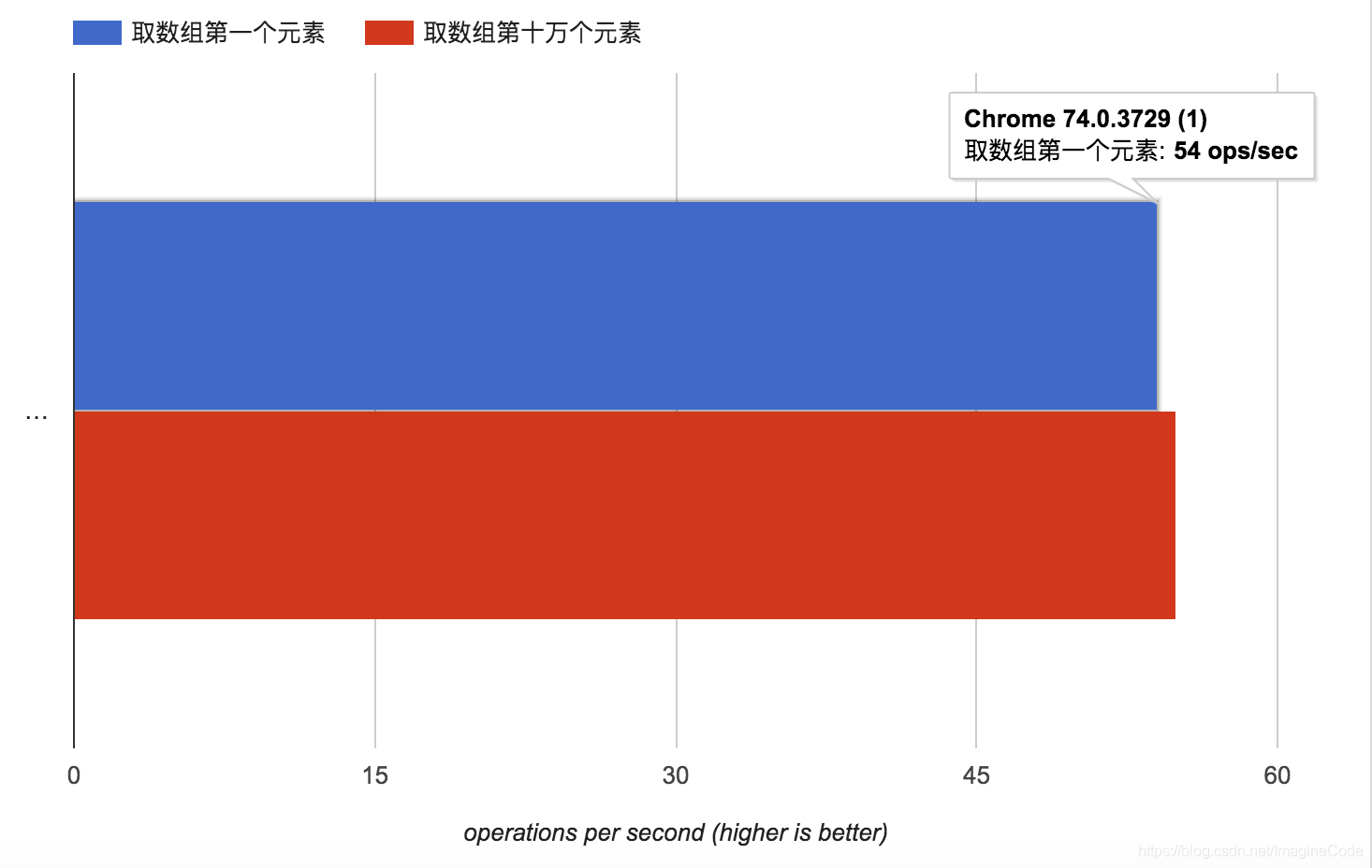
console.log(a[b]);//'c'第71题:数组里面有10万个数据,取第一个元素和第10万个元素的时间相差多少
在jsperf中进行了测试,点击查看。
第70题:用Proxys实现双向数据绑定
参考
第69题:BFC、IFC、GFC和FFC
FC的全称是:Formatting Contexts,是W3C CSS2.1规范中的一个概念。它是页面中的一块渲染区域,并且有一套渲染规则,它决定了其子元素将如何定位,以及和其他元素的关系和相互作用。
BFC
块级格式化上下文:就是页面上的一个隔离的渲染区域,容器里面的子元素不会在布局上影响到外面的元素,反之也是如此。怎样会产生BFC:
- float的值不为none。
- overflow的值不为visible。
- position的值不为relative和static。
- display的值为table-cell, table-caption, inline-block中的任何一个。
IFC
内联格式化上下文:高度由其包含行内元素中最高的实际高度计算而来(不受到竖直方向的padding/margin影响)。
IFC中的line box一般左右都贴紧整个IFC,但是会因为float元素而扰乱。float元素会位于IFC与与line box之间,使得line box宽度缩短。 同个ifc下的多个line box高度会不同。 IFC中不可能有块级元素的,当插入块级元素时(如p中插入div)会产生两个匿名块与div分隔开,即产生两个IFC,每个IFC对外表现为块级元素,与div垂直排列。
- IFC一般有什么用: 水平居中:当一个块要在环境中水平居中时,设置其为inline-block则会在外层产生IFC,通过text-align则可以使其水平居中。 垂直居中:创建一个IFC,用其中一个元素撑开父元素的高度,然后设置其vertical-align:middle,其他行内元素则可以在此父元素下垂直居中。
GFC
网格布局格式化上下文:当为一个元素设置display值为grid的时候,此元素将会获得一个独立的渲染区域,我们可以通过在网格容器(grid container)上定义网格定义行(grid definition rows)和网格定义列(grid definition columns)属性各在网格项目(grid item)上定义网格行(grid row)和网格列(grid columns)为每一个网格项目(grid item)定义位置和空间。
GridLayout会有更加丰富的属性来控制行列,控制对齐以及更为精细的渲染语义和控制。
FFC
自适应格式化上下文:display值为flex或者inline-flex的元素将会生成自适应容器(flex container),可惜这个牛逼的属性只有谷歌和火狐支持,不过在移动端也足够了,至少safari和chrome还是OK的,毕竟这俩在移动端才是王道。
Flex Box 由伸缩容器和伸缩项目组成。通过设置元素的 display 属性为 flex 或 inline-flex 可以得到一个伸缩容器。设置为 flex 的容器被渲染为一个块级元素,而设置为 inline-flex 的容器则渲染为一个行内元素。
伸缩容器中的每一个子元素都是一个伸缩项目。伸缩项目可以是任意数量的。伸缩容器外和伸缩项目内的一切元素都不受影响。简单地说,Flexbox 定义了伸缩容器内伸缩项目该如何布局。
第68题:for与forEach性能
- for 循环没有任何额外的函数调用栈和上下文;
- forEach函数签名实际上是
array.forEach(function(currentValue, index, arr), thisValue)
它不是普通的 for 循环的语法糖,还有诸多参数和上下文需要在执行的时候考虑进来,这里可能拖慢性能;
参考
第67题:在字符串中查找匹配的字符串
const findStr = (s,t) => {
let posArr = [];
let index = s.search(t);
while(index !== -1) {
posArr.push(index);
index = s.indexOf(t,index+t.length);
}
console.log(posArr);
}
findStr('sdfsdf123er123','123');//[6,11]第66题:webpack热更新原理
参考
第65题:字符串大小写操作
如何把一个字符串的大小写取反(大写变小写小写变大写),例如 ’AbC’ 变成 ‘aBc’
function trans2Case(str) {
let arr = str.split('');
arr = arr.map((item)=>{
return item === item.toUpperCase() ? item.toLowerCase() : item.toUpperCase();
});
return arr.join('');
}
console.log(trans2Case('AbC'))第64题: 随机生成一个长度为 10 的整数类型的数组,例如 2, 10, 3, 4, 5, 11, 10, 11, 20,将其排列成一个新数组,要求新数组形式如下,例如 [2, 3, 4, 5, 10, 11, 20]。
function Array2Group(len) {
//生成随机整数型数组
let arr = Array.from({length:len},(f)=>{return Math.floor(Math.random()*100)})
arr = arr.sort((a,b)=>{//升序排序
return a-b;
})
//去重
arr = arr.filter((item,index)=>{
return item !== arr[index+1];
})
//分组,将连续的放在一组
let continueArr = [], tempArr = [];
arr.map((item,index)=>{
tempArr.push(item);
if(arr[index+1] !== ++item) {
continueArr.push(tempArr);
tempArr = [];
}
})
console.log(continueArr)
}
Array2Group(9);第63题:Babe是将ES6转换为ES5的原理
Babel的功能非常纯粹,以字符串的形式将源代码传给它,它就会返回一段新的代码字符串(以及sourcemap)。他既不会运行你的代码,也不会将多个代码打包到一起,它就是个编译器,输入语言是ES6+,编译目标语言是ES5。
Babel的编译过程跟绝大多数其他语言的编译器大致同理,分为三个阶段:
- 解析:将代码字符串解析成抽象语法树
- 变换:对抽象语法树进行变换操作
- 再建:根据变换后的抽象语法树再生成代码字符串
第1步转换的过程中可以验证语法的正确性,同时由字符串变为对象结构后更有利于精准地分析以及进行代码结构调整。
第2步原理就很简单了,就是遍历这个对象所描述的抽象语法树,遇到哪里需要做一下改变,就直接在对象上进行操作,比如我把IfStatement给改成WhileStatement就达到了把条件判断改成循环的效果。在.babelrc里配置的presets和plugins都是在第2步工作的。
第3步也简单,递归遍历这颗语法树,然后生成相应的代码
- 抽象语法树是如何产生的:
- 分词:将整个代码字符串分割成 语法单元 数组
- 语义分析:在分词结果的基础之上分析 语法单元之间的关系
参考
- https://zhuanlan.zhihu.com/p/27289600
- http://www.ruanyifeng.com/blog/2016/01/babel.html
- https://moyueating.github.io/2017/07/08/%E6%B5%85%E8%B0%88babel%E5%8E%9F%E7%90%86%E4%BB%A5%E5%8F%8A%E4%BD%BF%E7%94%A8/
第62题:a.b.c.d和a‘b’‘d’,哪个性能更高
a‘b’和a.b.c,转换成AST前者的的树是含计算的,后者只是string literal,天然前者会消耗更多的计算成本,时间也更长
参考
第 61 题: 模拟实现promise的finally方法
promise.finally方法用于指定不管 Promise 对象最后状态如何,都会执行的操作。即finally方法里面的操作,应该是与状态无关的,不依赖于 Promise 的执行结果。
promise
.then(result => {···})
.catch(error => {···})
.finally(() => {···});上面代码中,不管promise最后的状态,在执行完then或catch指定的回调函数以后,都会执行finally方法指定的回调函数。
实现:
Promise.prototype.finally = function (callback) {
let P = this.constructor;
return this.then(
value => P.resolve(callback()).then(() => value),
reason => P.resolve(callback()).then(() => { throw reason })
);
};参考
- Promise.prototype.finally()
第 60 题: token加密的实现原理
1、后端生成一个secret(随机数)
2、后端利用secret和加密算法(如:HMAC-SHA256)对payload(如账号密码)生成一个字符串(token),返回前端
3、前端每次request在header中带上token
4、后端用同样的算法解密
参考
- 日常开发中的salt和token是什么?
- https://ninghao.net/blog/2834
- https://yhv5.com/token_1532.html?https://blog.csdn.net/qq_32784541/article/details/79655146
第 59 题: !important
不改变下面代码的情况下,设置width为330px
<img src="1.jpg" style="width:480px!important;”>
img {max-width:330px;}第 58 题:求两个数组的交集
- filter、include方法
ar nums1 = [1, 2, 2, 1], nums2 = [2, 2, 3, 4];
// 1.
// 有个问题, [NaN].indexOf(NaN) === -1
var newArr1 = nums1.filter(function(item) {
return nums2.indexOf(item) > -1;
});
console.log(newArr1);
// 2.
var newArr2 = nums1.filter((item) => {
return nums2.includes(item);
});
console.log(newArr2);第 57 题:箭头函数与普通函数(function)的区别是什么?构造函数(function)可以使用 new 生成实例,那么箭头函数可以吗?为什么?
箭头函数是普通函数的简写,和普通函数相比,有以下几点差异:
- 函数体内的 this 对象,就是定义时所在的对象,而不是使用时所在的对象。
- 不可以使用 arguments 对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
- 不可以使用 yield 命令,因此箭头函数不能用作 Generator 函数。
- 不可以使用 new 命令,因为没有自己的 this,无法调用 call,apply。
同时,没有 prototype 属性 ,而 new 命令在执行时需要将构造函数的 prototype 赋值给新的对象的
__proto__,new 过程大致如下:
function newFunc(father, ...rest) {
var result = {};
result.__proto__ = father.prototype;
var result2 = father.apply(result, rest);
if (
(typeof result2 === 'object' || typeof result2 === 'function') &&
result2 !== null
) {
return result2;
}
return result;
}new运算符
js中,。new运算符创建了一个继承于其运算数的原型的新对象,然后调用该运算数,把新创建的对象绑定给this。
如果你忘记使用new运算符,你得到的是一个普通的函数调用,并且this被绑定到全局对象,而不是新创建的对象。这意味着当你的函数尝试去初始化新成员属性时它将会污染全局变量。
如果你要使用new运算符,与new结合使用的函数应该以首字母大写的形式命名,并且首字母大写的形式应该只用来命名那些构造函数。
一个更好的做法是,不去使用new。第 56 题:分析比较 opacity: 0、visibility: hidden、display: none 优劣和适用场景
- 结构: display:none: 会让元素完全从渲染树中消失,渲染的时候不占据任何空间, 不能点击, visibility: hidden:不会让元素从渲染树消失,渲染元素继续占据空间,只是内容不可见,可以点击 opacity: 0: 不会让元素从渲染树消失,渲染元素继续占据空间,只是内容不可见,可以点击
- 继承: display: none和opacity: 0:是非继承属性,子孙节点消失由于元素从渲染树消失造成,通过修改子孙节点属性无法显示。 visibility: hidden:是继承属性,子孙节点消失由于继承了hidden,通过设置visibility: visible;可以让子孙节点显式。
- 性能: displaynone : 修改元素会造成文档回流,读屏器不会读取display: none元素内容,性能消耗较大 visibility:hidden: 修改元素只会造成本元素的重绘,性能消耗较少读屏器读取visibility: hidden元素内容 opacity: 0 : 修改元素会造成重绘,性能消耗较少
第55题:class设计,设计LazyMan类,实现下述功能
LazyMan('Tony');
// Hi I am Tony
LazyMan('Tony').sleep(10).eat('lunch');
// Hi I am Tony
// 等待了10秒...
// I am eating lunch
LazyMan('Tony').eat('lunch').sleep(10).eat('dinner');
// Hi I am Tony
// I am eating lunch
// 等待了10秒...
// I am eating diner
LazyMan('Tony').eat('lunch').eat('dinner').sleepFirst(5).sleep(10).eat('junk food');
// Hi I am Tony
// 等待了5秒...
// I am eating lunch
// I am eating dinner
// 等待了10秒...
// I am eating junk food- 解析
class LazyManClass {
constructor(name) {
this.taskList = [];
this.name = name;
console.log('Hi I am',this.name);
let that = this;
setTimeout(()=>{
that.next();
},0);
}
eat(name) {
let that = this;
let fn = (function(name) {
return function() {
console.log('I am eating',name);
that.next();
}
})(name);
that.taskList.push(fn);
console.log(that.taskList)
return that;
}
sleepFirst(time) {
let that = this;
let fn = (function(time) {
return function() {
setTimeout(()=>{
console.log(`等待了${time}秒`);
that.next();
},time*1000);
}
})(time);
that.taskList.unshift(fn);
console.log(that.taskList)
return that;
}
sleep(time) {
let that = this;
let fn = (function(time){
return function() {
setTimeout(()=>{
console.log(`等待了${time}秒`);
that.next();
},time*1000);
}
})(time);
that.taskList.push(fn);
console.log(that.taskList)
return that;
}
next() {
let that = this;
let fn = that.taskList.shift();
console.log(that.taskList)
if(typeof fn ==='function')
fn && fn()
}
}
function LazyMan(name){
return new LazyManClass(name);
}
LazyMan('Tony').eat('lunch').eat('dinner').sleepFirst(5).sleep(10).eat('junk food');第 54 题:某公司 1 到 12 月份的销售额存在一个对象里面,如下:{1:222, 2:123, 5:888},请把数据处理为如下结构:[222, 123, null, null, 888, null, null, null, null, null, null, null
Array.from():方法从一个类似数组或可迭代对象中创建一个新的数组实例,例如:
console.log(Array.from([1, 2, 3], x => x + x));
// expected output: Array [2, 4, 6]- 解析问题
let obj = {1:222, 2:123, 5:888};
const result = Array.from({ length: 12 }) //先生成一个长度为12的数组,里面的值为undefined
.map((_, index) => obj[index + 1] || null); //然后对数组赋值
console.log(result)参考
第 53 题:冒泡排序如何实现,时间复杂度是多少, 如何改进?
冒泡排序这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
冒泡排序算法的原理如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
冒泡排序最好的时间复杂度为 O(n),冒泡排序的最坏时间复杂度为 O(n^2) ,冒泡排序总的平均时间复杂度为 O(n^2) ,是一种稳定排序算法。
以升序为例:
// 升序冒泡
function bubbleSort(arr){
const array = [...arr]
for(let i = 0, len = array.length; i < len - 1; i++){
for(let j = i + 1; j < len; j++) {
if (array[i] > array[j]) {
let temp = array[i]
array[i] = array[j]
array[j] = temp
}
}
}
return array
}上述这种算法不太好,因为就算你给一个已经排好序的数组,如1,2,3,4,5,6 它也会走一遍流程,白白浪费资源。
- 改进:加个标识,如果已经排好序了就直接跳出循环。
functionbubbleSort(arr){
const array = [...arr]
let isOk = true
for(let i = 0, len = array.length; i < len - 1; i++){
for(let j = i + 1; j < len; j++) {
if (array[i] > array[j]) {
let temp = array[i]
array[i] = array[j]
array[j] = temp
isOk = false
}
}
if(isOk){
break
}
}
return array
}参考
- https://baike.baidu.com/item/%E5%86%92%E6%B3%A1%E6%8E%92%E5%BA%8F/4602306?fr=aladdin
- https://www.jianshu.com/p/5d44186b5263
第 52 题:执行顺序优先级
下列代码的执行结果:
var a = {n: 1};
var b = a;
a.x = a = {n: 2};
console.log(a.x) //undefined
console.log(b.x) // {n:2}- 1、优先级。
.的优先级高于=,所以先执行a.x,堆内存中的{n: 1}就会变成{n: 1, x: undefined},改变之后相应的b.x也变化了,因为指向的是同一个对象。 - 2、
赋值操作是从右到左,所以先执行a = {n: 2},a的引用就被改变了,然后这个返回值又赋值给了a.x,需要注意的是这时候a.x是第一步中的{n: 1, x: undefined}那个对象,其实就是b.x,相当于b.x = {n: 2}
第 51 题:让一个 div 水平垂直居中
// no.1
div.parent {
display: flex;
justify-content: center;
align-items: center;
}
// no.2
div.parent {
position: relative;
}
div.child {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
//no.3
div.child {
width: 50px;
height: 10px;
position: absolute;
top: 50%;
left: 50%;
margin-left: -25px;
margin-top: -5px;
}
//no.4
div.child {
width: 50px;
height: 10px;
position: absolute;
left: 0;
top: 0;
right: 0;
bottom: 0;
margin: auto;
}
//no.5
div.parent {
display: grid;
}
div.child {
justify-self: center;
align-self: center;
}
//no.6
div.parent{
display:flex;
}
div.child{
margin:auto;
}第50题:Vue 的响应式原理中 Object.defineProperty 有什么缺陷?为什么在 Vue3.0 采用了 Proxy,抛弃了 Object.defineProperty?
Object.defineProperty无法监控到数组下标的变化,导致直接通过数组的下标给数组设置值,不能实时响应。 为了解决这个问题,经过vue内部处理后可以使用以下几种方法来监听数组:
push()
pop()
shift()
unshift()
splice()
sort()
reverse()由于只针对了以上八种方法进行了hack处理,所以其他数组的属性也是检测不到的,还是具有一定的局限性。
Object.defineProperty只能劫持对象的属性,因此我们需要对每个对象的每个属性进行遍历。Vue 2.x里,是通过 递归 + 遍历 data 对象来实现对数据的监控的,如果属性值也是对象那么需要深度遍历,显然如果能劫持一个完整的对象是才是更好的选择。
而要取代它的Proxy有以下如下优点;:
- 可以劫持整个对象,并返回一个新对象
- 有13种劫持操作
- Proxy不仅可以代理对象,还可以代理数组。还可以代理动态增加的属性。
参考
- https://www.jianshu.com/p/860418f0785c
- https://juejin.im/post/5acd0c8a6fb9a028da7cdfaf
- http://www.10tiao.com/html/780/201812/2650588659/1.html
- http://es6.ruanyifeng.com/#docs/proxy
- https://zhuanlan.zhihu.com/p/35080324
第49题:实现 (5).add(3).minus(2) 功能,例: 5 + 3 - 2,结果为 6
Number.MAX_SAFE_DIGITS = Number.MAX_SAFE_INTEGER.toString().length-2
Number.prototype.digits = function(){
let result = (this.valueOf().toString().split('.')[1] || '').length
return result > Number.MAX_SAFE_DIGITS ? Number.MAX_SAFE_DIGITS : result
}
Number.prototype.add = function(i=0){
if (typeof i !== 'number') {
throw new Error('请输入正确的数字');
}
const v = this.valueOf();
const thisDigits = this.digits();
const iDigits = i.digits();
const baseNum = Math.pow(10, Math.max(thisDigits, iDigits));
const result = (v * baseNum + i * baseNum) / baseNum;
if(result>0){ return result > Number.MAX_SAFE_INTEGER ? Number.MAX_SAFE_INTEGER : result }
else{ return result < Number.MIN_SAFE_INTEGER ? Number.MIN_SAFE_INTEGER : result }
}
Number.prototype.minus = function(i=0){
if (typeof i !== 'number') {
throw new Error('请输入正确的数字');
}
const v = this.valueOf();
const thisDigits = this.digits();
const iDigits = i.digits();
const baseNum = Math.pow(10, Math.max(thisDigits, iDigits));
const result = (v * baseNum - i * baseNum) / baseNum;
if(result>0){ return result > Number.MAX_SAFE_INTEGER ? Number.MAX_SAFE_INTEGER : result }
else{ return result < Number.MIN_SAFE_INTEGER ? Number.MIN_SAFE_INTEGER : result }
}- 大数加减:直接通过 Number 原生的安全极值来进行判断,超出则直接取安全极值
- 超级多位数的小数加减:取JS安全极值位数-2作为最高兼容小数位数
第 48 题:为什么通常在发送数据埋点请求的时候使用的是 1x1 像素的透明 gif 图片
- 避免跨域(img 天然支持跨域)
- 利用空白gif或1x1 px的img是互联网广告或网站监测方面常用的手段,简单、安全、相比PNG/JPG体积小,1px 透明图,对网页内容的影响几乎没有影响,这种请求用在很多地方,比如浏览、点击、热点、心跳、ID颁发等等,
- 图片请求不占用 Ajax 请求限额
- 不会阻塞页面加载,影响用户的体验,只要new Image对象就好了,一般情况下也不需要append到DOM中,通过它的onerror和onload事件来检测发送状态。
示例:
<script type="text/javascript">
var thisPage = location.href;
var referringPage = (document.referrer) ? document.referrer : "none";
var beacon = new Image();
beacon.src = "http://www.example.com/logger/beacon.gif?page=" + encodeURI(thisPage)
+ "&ref=" + encodeURI(referringPage);
</script>参考
- https://segmentfault.com/a/1190000015863478
- https://blog.csdn.net/zmx729618/article/details/58600620/
- https://www.zhihu.com/question/25488619?sort=created
- https://www.jishuwen.com/d/2CQv
第 47 题:call 和 apply 的区别是什么,哪个性能更好一些
- Function.prototype.apply和Function.prototype.call 的作用是一样的,区别在于传入参数的不同;
- 第一个参数都是,指定
函数体内this的指向; - 第二个参数开始不同,apply是传入
带下标的集合,数组或者类数组,apply把它传给函数作为参数,call从第二个开始传入的参数是不固定的,都会传给函数作为参数。例如:
fun.apply(thisArg, [argsArray])fun.call(thisArg, arg1, arg2, ...)- call比apply的性能要好,
平常可以多用call, call传入参数的格式正是内部所需要的格式
参考
第 46 题:双向绑定和 vuex 是否冲突
官方文档解释:https://vuex.vuejs.org/zh/guide/forms.html
第 45 题:输出以下代码执行的结果并解释为什么
var obj = {
'2': 3,
'3': 4,
'length': 2,
'splice': Array.prototype.splice,
'push': Array.prototype.push
}
obj.push(1)
obj.push(2)
console.log(obj)- 解释:我们现在控制台输入并输出,对照来看:
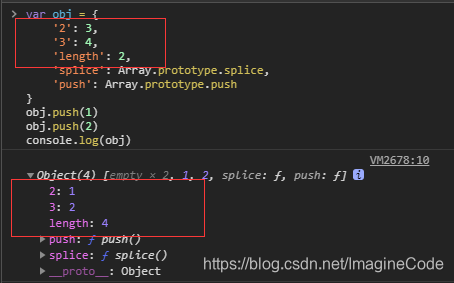
很显然,从结果上对照,obj.push(1) 访问的是对象obj的push属性,该push属性具有数组的push方法,因此,obj.push(1)和obj.push(2)会向Array中追加并返回修改后的数组。但是,问题来了!怎么追加?往哪个位置追加?
我们看到打印输出时,obj是一个数组形式输出,但’obj instanceof Array’又不是一个真实的数组,所以这是一个类数组形式,我们给这个类数组起一个名称S_Arr。
细心的你,一定注意到empty x 2,即输出了2个空。所以,我们对此可知,在进行obj.push(1)和obj.push(2)操作时,S_Arr[2]=1,S_Arr[3]=2,可见S_Arr[0]和S_Arr[1]为empty,但这两个下标仍旧占位。现在,可以解释为什么length为4了吧。
第 44 题:HTTPS 握手过程中,客户端如何验证证书的合法性
浏览器和系统会内置默认信任的证书。
如果只劫持了站点返回自己签发的别的证书,证书因为与域名不符会验证失败。证书是没法伪造的,因为你没有证书的私钥。除非用给原证书签名的根证书重新给你签发一个同域名的证书。
rsa 加密唯一的缺点就是不能防中间人攻击。所以系统和浏览器内置了信任证书。像 ssh 连接第一次会提示指纹一样。你得先信任指纹才能继续操作,指纹发生改变后就会提示你指纹错误。
除此之外,证书颁发机构会验证域名所有权,你得证明域名的所有权在你手里:
- 你往网站根目录放置一个机构提供的特定的文件,然后机构会定时抓取这个文件,如果能抓取到说明你确实有这个网站的管理权限。注意,只支持 80 和 443 端口,8080 登端口不认。
- 机构往域名信息里的管理员邮箱发一封验证邮件,邮件里有验证链接,域名管理员要点开链接输入验证码确认。
- 要求你在域名 DNS 控制面板里添加一条特定的域名记录。
以上操作都只有域名管理员或者网站管理员才能做到,避免了他人伪造证书。
还有一点很重要的:
如果发现申请的域名包含知名品牌、知名网站域名,证书机构会人工审核,有可能会要求你提供相关证明文件。比如我想申请 www.nikeshop.com 的证书,因为包含 Nike 字样,极有可能会被拒绝。
参考
- https://www.v2ex.com/amp/t/411144
- https://www.cnblogs.com/StephenWu/p/5720954.html
- https://blog.csdn.net/love_hot_girl/article/details/81164279
第 43题:介绍 HTTPS 握手过程
建议去看看计算机网络讲解HTTP,然后再看HTTPS。
HTTPS三次握手
握手要解决的问题:
- 客户端和服务器身份的互相确认
- 协商之后通信中对称加密的秘钥
握手流程
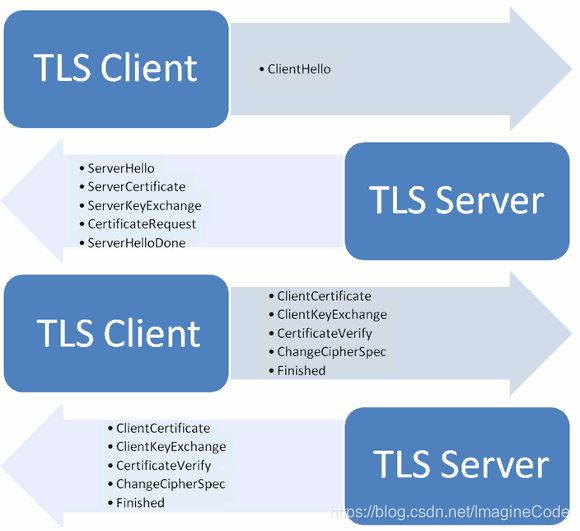
- 步骤1: 客户端发出请求(ClientHello) 首先,客户端(通常是浏览器)先向服务器发出加密通信的请求,这被叫做ClientHello请求。 在这一步,客户端主要向服务器提供以下信息。
- 客户端支持的SSL的指定版本
- 客户端产生的随机数(Client Random, 稍后用于生成"对话密钥"
- 客户端支持的加密算法
- 步骤2:服务器回应(SeverHello) 服务器收到客户端请求后,向客户端发出回应,这叫做SeverHello。服务器的回应包含以下内容。
- 确认使用的加密通信协议版本,比如TLS 1.0版本。如果浏览器与服务器支持的版本不一致,服务器关闭加密通信。
- 一个服务器生成的随机数(Server Random),稍后用于生成"对话密钥"。
- 确认使用的加密方法,比如RSA公钥加密。
- 服务器证书
除了上面这些信息,如果服务器需要确认客户端的身份,就会再包含一项请求,要求客户端提供"客户端证书"。比如,金融机构往往只允许认证客户连入自己的网络,就会向正式客户提供USB密钥,里面就包含了一张客户端证书。
第一次握手结束
- 步骤3:客户端回应
客户端收到服务器回应以后,首先验证服务器证书。如果证书不是可信机构颁布、或者证书中的域名与实际域名不一致、或者证书已经过期,就会向访问者显示一个警告,由其选择是否还要继续通信。
如果证书没有问题,客户端就会从证书中取出服务器的公钥。然后,向服务器发送下面三项信息。
- 一个随机数(pre-master key), 稍后用于生成"对话密钥"。
- 编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
- 客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供服务器校验。
上面第一项的随机数,是整个握手阶段出现的第三个随机数,又称"pre-master key"。有了它以后,客户端和服务器就同时有了三个随机数,接着双方就用事先商定的加密方法,各自生成本次会话所用的同一把"会话密钥"。
第二次握手结束
- 步骤4:服务器的最后回应 服务器收到客户端的第三个随机数pre-master key之后,计算生成本次会话所用的"会话密钥"。然后,向客户端最后发送下面信息。
- 编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
- 服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供客户端校验。
至此,整个握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的HTTP协议,只不过用"会话密钥"加密内容,也就是对称加密。
第三次握手结束
参考
- Http协议理解
- https://www.cnblogs.com/zxh930508/p/5432700.html
- 协议理解之HTTPS
- https://developers.weixin.qq.com/community/develop/article/doc/000046a5fdc7802a15f7508b556413
- https://mp.weixin.qq.com/s/1ojSrhc9LZV8zlX6YblMtA
第 42 题:使用 sort() 对数组 3, 15, 8, 29, 102, 22 进行排序,输出结果
let arr = [3, 15, 8, 29, 102, 22];
arr.sort((a,b)=>{a-b}); // 升序
arr.sort((a,b)=>{b-a}); //倒序- sort()函数解释:
如果调用该方法时没有使用参数,将按字母顺序对数组中的元素进行排序,说得更精确点,
是按照字符编码的顺序进行排序。要实现这一点,首先应把数组的元素都转换成字符串(如有必要),以便进行比较。如果想按照其他标准进行排序,就需要提供比较函数,该函数要比较两个值,然后返回一个用于说明这两个值的相对顺序的数字。比较函数应该具有两个参数 a 和 b,其返回值如下:
- 若 a 小于 b,在排序后的数组中 a 应该出现在 b 之前,则返回一个小于 0 的值。
- 若 a 等于 b,则返回 0。
- 若 a 大于b,则返回一个大于 0 的值。
第 41 题:实现一个 sleep 函数,比如 sleep(1000) 意味着等待1000毫秒,可从 Promise、Generator、Async/Await 等角度实现
分别给出4中方式:
//Promise
const sleep = time => {
return new Promise(resolve=>setTimeout(resolve,time))
}
sleep(1000).then(()=>{
console.log(1)
})
//Generator
function* sleepGenerator(time) {
yield new Promise(function(resolve,reject){
setTimeout(resolve,time);
})
}
sleepGenerator(1000).next().value.then(()=>{console.log(1)})
//async
function sleep(time) {
return new Promise(resolve=>setTimeout(resolve,time))
}
async function output() {
let out = await sleep(1000);
console.log(1);
return out;
}
output();
//ES5
function sleep(callback,time) {
if(typeof callback === 'function')
setTimeout(callback,time)
}
function output(){
console.log(1);
}
sleep(output,1000);参考
第 40 题:下面代码将打印什么?
var a = 10;
(function () {
console.log(a); //undefined
a = 5
console.log(window.a) // 10
var a = 20;
console.log(a) //20
})()原因:在内部声名var a = 20;相当于先声明var a;然后再执行赋值操作,这是在IIFE内形成的独立作用域。
B 情况:
var a = 10;
(function () {
console.log(a); //10
a = 5
console.log(window.a) // 5
//var a = 20;
console.log(a) //5
})()C情况:
var a = 10;
(function () {
console.log(a); //10
//a = 5
console.log(window.a) // 10
//var a = 20;
console.log(a) //10
})()
第 39 题:在 Vue 中,子组件为何不可以修改父组件传递的 Prop,如果修改了,Vue 是如何监控到属性的修改并给出警告的
- 子组件为何不可以修改父组件传递的 Prop:
单向数据流,易于监测数据的流动,出现了错误可以更加迅速的定位到错误发生的位置。同时,因为每当父组件属性值修改时,该值都将被覆盖;
如果要有不同的改变,可以用基于prop的data或者computed。 - Vue 是如何监控到属性的修改并给出警告的
在
initProps的时候,在defineReactive时通过判断是否在开发环境,如果是开发环境,会在触发set的时候判断是否此key是否处于updatingChildren中被修改,如果不是,说明此修改来自子组件,触发warning提示。
if (process.env.NODE_ENV !== 'production') {
var hyphenatedKey = hyphenate(key);
if (isReservedAttribute(hyphenatedKey) ||
config.isReservedAttr(hyphenatedKey)) {
warn(
("\"" + hyphenatedKey + "\" is a reserved attribute and cannot be used as component prop."),
vm
);
}
defineReactive$$1(props, key, value, function () {
if (!isRoot && !isUpdatingChildComponent) {
warn(
"Avoid mutating a prop directly since the value will be " +
"overwritten whenever the parent component re-renders. " +
"Instead, use a data or computed property based on the prop's " +
"value. Prop being mutated: \"" + key + "\"",
vm
);
}
});
}需要特别注意的是,由于值传递与地址传递的原因当你从子组件修改的prop,属于基础类型时会触发提示。 这种情况下,你是无法修改父组件的数据源的, 因为基础类型赋值时是值拷贝。你直接将另一个非基础类型(Object, array)赋值到此key时也会触发提示(但实际上不会影响父组件的数据源), 当你修改object的属性时不会触发提示,并且会修改父组件数据源的数据。(参考:https://blog.csdn.net/ImagineCode/article/details/54409272)
第 38 题:介绍下 BFC 及其应用
BFC 就是块级格式上下文,是页面盒模型布局中的一种 CSS 渲染模式,相当于一个独立的容器,里面的元素和外部的元素相互不影响。创建 BFC 的方式有:
- html 根元素
- float 浮动
- 绝对定位
- overflow 不为 visiable
- display 为表格布局或者弹性布局
BFC 主要的作用是:
- 清除浮动
- 防止同一 BFC 容器中的相邻元素间的外边距重叠问题
参考
第37题:下面代码中 a 在什么情况下会打印 1?
var a = ?;
if(a == 1 && a == 2 && a == 3){
console.log(1);
}解析
因为==会进行隐式类型转换 。
- 利用toString方式
let a = {
i: 1,
toString () {
return a.i++
}
}
if(a == 1 && a == 2 && a == 3) {
console.log('1');
}- 利用valueOf
let a = {
i: 1,
valueOf () {
return a.i++
}
}
if(a == 1 && a == 2 && a == 3) {
console.log('1');
}- 数组方式
var a = [1,2,3];
a.join = a.shift;
if(a == 1 && a == 2 && a == 3) {
console.log('1');
}- ES6的symbol
let a = {[Symbol.toPrimitive]: ((i) => () => ++i) (0)};
if(a == 1 && a == 2 && a == 3) {
console.log('1');
}参考:
- 第36题:为什么 Vuex 的 mutation 和 Redux 的 reducer 中不能做异步操作?
参考:
第35题:使用迭代的方式实现 flatten 函数
flatten函数,即扁平化函数,是使一个嵌套数组变成一维数组的方式。
例如:
function flatten(arr=[1,[2],[[3]],[[[4]]]]) {
return arr.toString().split(',')
}
alert(flatten());那么怎么使用迭代的方式实现flatten函数呢?往下看。
function flatten(arr,result=[]) {
for(let item of arr){
if(Array.isArray(item))
flatten(item,result)
else
result.push(item)
}
return result
}
var array = [[1,2,3],4,5,6,[[7]],[]];
var result = flatten(array);
console.log(result);上面我们使用迭代递归的方式,使用 result 变量存储结果,然后迭代当前数组,如果值也是数组则继续扁平化,否则将值放入 result 里。
参考:
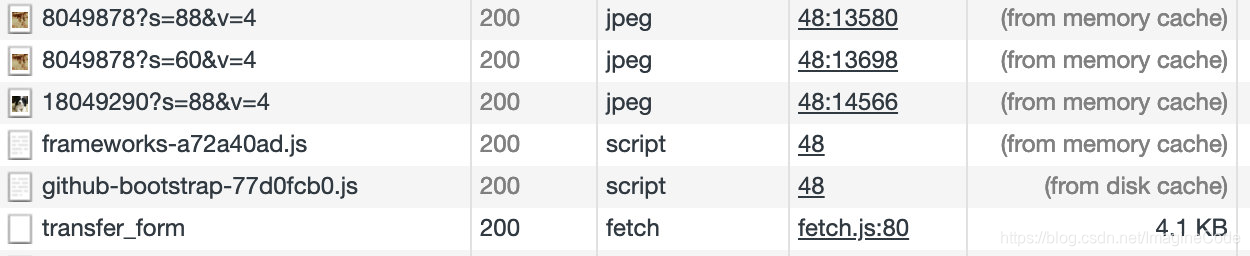
第34题:浏览器缓存可以分成 Service Worker、Memory Cache、Disk Cache 和 Push Cache,那请求的时候 from memory cache 和 from disk cache 的依据是什么,哪些数据什么时候存放在 Memory Cache 和 Disk Cache中?
参考
第33题:下面的代码打印什么内容,为什么?
var b = 10;
(function b() {
b = 20;
console.log(b)
})()- 解析: 这上面的代码中,我们知道这里面涉及到作用域和IIFE的知识。 首先我们回顾下IIFE(立即调用函数表达式),参考MDN:
IIFE
IIFE( 立即调用函数表达式)是一个在定义时就会立即执行的 JavaScript 函数。
下面这句话很重要:
第一部分是包围在 圆括号运算符() 里的一个匿名函数,这个匿名函数拥有独立的词法作用域。这不仅避免了外界访问此 IIFE 中的变量,而且又不会污染全局作用域。
第二部分再一次使用 () 创建了一个立即执行函数表达式,JavaScript 引擎到此将直接执行函数。
当函数变成立即执行的函数表达式时,表达式中的变量不能从外部访问:
(function () {
var name = "Barry";
})();
// 外部不能访问变量 name
name // undefined将 IIFE 分配给一个变量,不是存储 IIFE 本身,而是存储 IIFE 执行后返回的结果:
var result = (function () {
var name = "Barry";
return name;
})();
// IIFE 执行后返回的结果:
result; // "Barry"回头看
OK,了解完了IIFE,我们回过头来看这道题:
var b = 10;
(function b() {
b = 20;
console.log(b)
})()- b()是个IIFE具名函数,而非匿名函数。它将被立即执行。
- 在内部作用域中,
IIFE函数无法对进行赋值,有些类似于const的意思。所以b=20无效 console.log(b)中,访问变量b,首先在IIFE内部中查找已声明的变量b,结果查找到b(),于是,输出b()这个具名函数。而b=20并没有进行声明,所以,无效。
现在我们对代码进行改造,再来看看其他种情况:
var b = 10;
(function b() {
window.b = 20;
console.log(b); // [Function b]
console.log(window.b); // 20是必然的
})();分别打印20与10:
var b = 10;
(function b() {
var b = 20; // IIFE内部变量
console.log(b); // 20
console.log(window.b); // 10
})();第 32 题:Virtual DOM 真的比操作原生 DOM 快吗?
参考
第 31 题:改造下面的代码,使之输出0 - 9,写出你能想到的所有解法
for (var i = 0; i< 10; i++){
setTimeout(() => {
console.log(i);
}, 1000)
}改造
- 改造1
function fn() {
for(var i=0;i<10;i++){//可以将for循环用while循环替换
console.log(i);
clearTimeout(timer);
}
}
var timer = setTimeout(fn,1000);
或者:
for (let i = 0; i< 10; i++){
setTimeout(() => {
console.log(i);
}, 1000)
}
或者 简写:
for (var i = 0; i< 10; i++){
setTimeout(console.log, 1000, i)
}- 改造2
(function fn(i){
if(i<10){
console.log(i);
i++;
setTimeout(fn, 1000,i);
}
})(0)-改造3 - 利用闭包特性
for(var i=0;i<10;i++){
(function(i){
setTimeout(()=>{
console.log(i);
},1000);
})(i);
}
或者:
for(var i=0;i<10;i++){
(function(){
var j = i;
setTimeout(()=>{
console.log(i);
},1000);
})();
}第30题:数组合并
题目描述:请把俩个数组 ‘A1’, ‘A2’, ‘B1’, ‘B2’, ‘C1’, ‘C2’, ‘D1’, ‘D2’, ‘E1’, ‘E2’ 和 ‘A’, ‘B’, ‘C’, ‘D’,‘E’,合并为 “A1”, “A2”, “A”, “B1”, “B2”, “B”, “C1”, “C2”, “C”, “D1”, “D2”, “D”, “E1”, “E2”, “E”
解析: 观察题目,数组是有规律的!
var arr1 = ['A1', 'A2', 'B1', 'B2', 'C1', 'C2', 'D1', 'D2', 'E1', 'E2'];
var arr2 = ['A', 'B', 'C', 'D','E'];
var arr3 = [];
arr1.forEach(function(item,index){
if((index+1)%2===0) {
arr3.push(arr1[index]);
arr3.push(arr2[(index+1)/2-1]);
}else {
arr3.push(arr1[index]);
}
});
console.log(arr3);优化:
arr1.map(function(item,index){
(index+1)%2===0 ? arr3.push(arr1[index]) && arr3.push(arr2[(index+1)/2-1]) : arr3.push(arr1[index])
});第29题:Vue 的双向数据绑定,Model 如何改变 View,View 又是如何改变 Model 的?
vue 是如何实现视图与viewmodel的双向绑定的?为什么数据一变化,视图就会立即更新,视图产生用户操作,viewmodel就能马上得知?
- VUE实现双向数据绑定的原理就是利用了
Object.defineProperty()这个方法重新定义了对象获取属性值(get)和设置属性值(set)的操作来实现的。它接收三个参数:要操作的对象,要定义或修改的对象属性名,属性描述符。
重点是:属性描述符。
- 属性描述符是一个对象,主要有两种形式:数据描述符和存取描述符。这两种对象只能选择一种使用,不能混合两种描述符的属性同时使用。例如,
get和set就是属于存取描述符对象的属性。
示例:
//defineProperty的用法
var obj = { };
var name;
//第一个参数:定义属性的对象。
//第二个参数:要定义或修改的属性的名称。
//第三个参数:将被定义或修改的属性描述符。
Object.defineProperty(obj, "data", {
//获取值
get: function () {return name;},
//设置值
set: function (val) {
name = val;
console.log(val)
}
})
//赋值调用get
obj.data = 'aaa';
//取值调用set
console.log(obj.data);
//defineProperty的双向绑定
var obj={};
Object.defineProperty(obj, 'val',{
set:function (newVal) {
document.getElementById("a")
.value = newVal == undefined ? '' : newVal;
document.getElementById("b")
.innerHTML = newVal == undefined ? '' : newVal;
}
});
document.getElementById("a")
.addEventListener("keyup",function (e) {
obj.val = e.target.value;
})参考
- vue的双向绑定原理及实现
- 剖析Vue原理&实现双向绑定MVVM
第28题:cookie 和 token 都存放在 header 中,为什么不会劫持 token?
简单理解:
- cookie
相当于编号。例如,你去银行柜台办事要先“叫号”,只涉及到简单的业务,到了柜台银行工作人员只需要根据你的编号就可以给你办理。 而: - token
相当于身份证,或者唯一标识。同样一个例子,你在银行柜台办事,不仅仅要叫号给自己先编上一个编号,但是你去办理需要身份证的业务时,你需要出示证件才能给你办理。
所以,综上可知 cookie是大家都可以知道的。而,tooken是自有你自己知道的。这也就反映在为什么在进行请求验证时,需要加入token这个标识。就是为了让Server端能够证实你的身份。结合到现实生活中,大家要知道(劫持)你的叫号编号是容易的,而要知道(劫持)你的身份证是难的!
参考
第27题:关于 const 和 let 声明的变量不在 window 上
在ES5中,顶层对象的属性和全局变量是等价的,var 命令和 function 命令声明的全局变量,自然也是顶层对象。
var a = 12;
function f(){};
console.log(window.a); // 12
console.log(window.f); // f(){}但ES6规定,var 命令和 function 命令声明的全局变量,依旧是顶层对象的属性,但 let命令、const命令、class命令声明的全局变量,不属于顶层对象的属性。
let aa = 1;
const bb = 2;
console.log(window.aa); // undefined
console.log(window.bb); // undefined在哪里?通过在设置断点,看看浏览器是怎么处理的:
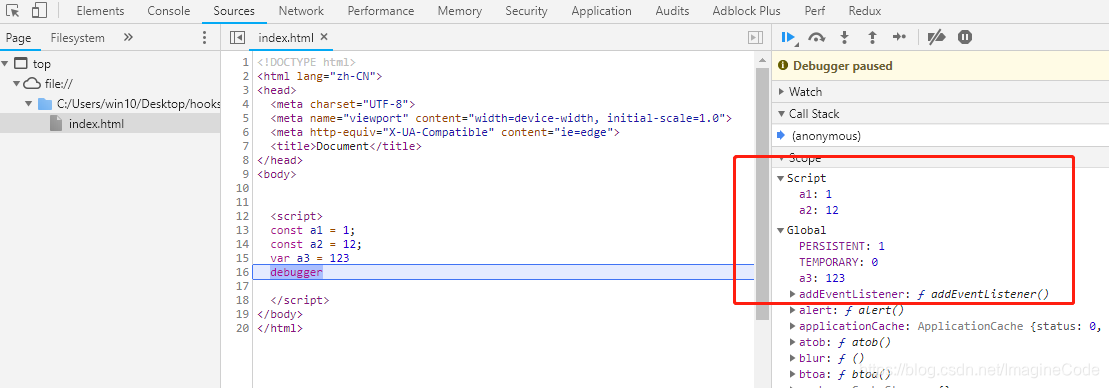
通过上图也可以看到,在全局作用域中,用 let 和 const 声明的全局变量并没有在全局对象中,只是一个块级作用域(Script)中。
怎么获取?在定义变量的块级作用域中就能获取,既然不属于顶层对象,那就不加 window(global)。
let aa = 1;
const bb = 2;
console.log(aa); // 1
console.log(bb); // 2参考
【ECMAScript6】es6 要点(一)剩余参数 | 数组方法 | 解构赋值 | 字符串模板 | 面向对象 | 模块
第 26 题:介绍模块化发展历程,可从IIFE、AMD、CMD、CommonJS、UMD、webpack(require.ensure)、ES Module、< script type=“module”>这几个角度考虑
模块化的好处就是,抽离代码,重复使用,如现在很直观的代表 npm 包。
模块化的发展历程
Long Long ago
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>So UI - A Component Library for Vue.js.</title>
</head>
<body>
<div id="app"></div>
<script src="a.js"></script>
<script src="b.js"></script>
<script src="c.js"></script>
<script src="d.js"></script>
<script src="e.js"></script>
</body>
</html>如上,引入了 a/b/c/d/e 五个文件,这五个文件如果相互之间有依赖,还要注意引入的顺序,并且还需要注意它们里面的变量名,若是重复利用到其他的项目,其他项目也需要注意到以上两点问题。为了解决这一问题,就有了模块化的规范。
CMD 与 AMD
- CMD (Common Module Definition), 是sea.js在推广过程中对模块定义的规范化产出,主要用于浏览器端。它主要特点是:
对于依赖的模块是延迟执行,依赖可以就近书写,等到需要用这个依赖的时候再引入这个依赖,应用有sea.js. - AMD规范(Asynchronous Module Definition):是 RequireJS 在推广过程中对模块定义的规范化产出,也是主要用于浏览器端。其特点是:
依赖前置,需要在定义时就写好需要的依赖,提前执行依赖,应用有require.js。它需要依次的加载模块然后去进行相应的操作,加载模块就是要引入这个文件,那么这里也还是通过动态加载 script 的方法,并通过 onload 去执行后面的回调了。
ES6 export 和 import
- export 导出你定义的模块变量
export {
one,
two
}
export default three;- import 引入一个模块变量
import { one, two } three from 'a.js'可以看到 export 可以导出一个默认的变量,也可以导出变量对象,这里引入的时候名字不要写错了。 那么 es6 的模块化通过babel 转码其实就是 umd 模块规范, 它是一个兼容 cmd 和 amd 的模块化规范, 同时还支持老式的“全局”变量规范。
示例:
(function (root, factory) {
if (typeof define === 'function' && define.amd) {
// AMD
define(['jquery'], factory);
} else if (typeof exports === 'object') {
// Node, CommonJS之类的
module.exports = factory(require('jquery'));
} else {
// 浏览器全局变量(root 即 window)
root.returnExports = factory(root.jQuery);
}
}(this, function ($) {
// 方法
function myFunc(){};
// 暴露公共方法
return myFunc;
}));浏览器是如何支持这种规范的呢?——是实现了根据这种规范定制出来的功能
例如,AMD 定义一个模块的方法是 define(id?, dependencies?, factory)
define = function (name, deps, callback) {
var node, context;
//Allow for anonymous modules
if (typeof name !== 'string') {
//Adjust args appropriately
callback = deps;
deps = name;
name = null;
}
//This module may not have dependencies
if (!isArray(deps)) {
callback = deps;
deps = null;
}
//If no name, and callback is a function, then figure out if it a
//CommonJS thing with dependencies.
if (!deps && isFunction(callback)) {
deps = [];
//移除注释
//查找 require 语句,收集依赖到 deps 里面
// but only if there are function args.
if (callback.length) {
callback
.toString()
.replace(commentRegExp, commentReplace)
.replace(cjsRequireRegExp, function (match, dep) {
deps.push(dep);
});
//May be a CommonJS thing even without require calls, but still
//could use exports, and module. Avoid doing exports and module
//work though if it just needs require.
//REQUIRES the function to expect the CommonJS variables in the
//order listed below.
deps = (callback.length === 1 ? ['require'] : ['require', 'exports', 'module']).concat(deps);
}
}
//If in IE 6-8 and hit an anonymous define() call, do the interactive
//work.
if (useInteractive) {
node = currentlyAddingScript || getInteractiveScript();
if (node) {
if (!name) {
name = node.getAttribute('data-requiremodule');
}
context = contexts[node.getAttribute('data-requirecontext')];
}
}
//Always save off evaluating the def call until the script onload handler.
//This allows multiple modules to be in a file without prematurely
//tracing dependencies, and allows for anonymous module support,
//where the module name is not known until the script onload event
//occurs. If no context, use the global queue, and get it processed
//in the onscript load callback.
if (context) {
context.defQueue.push([name, deps, callback]);
context.defQueueMap[name] = true;
} else {
globalDefQueue.push([name, deps, callback]);
}
};
define.amd = {
jQuery: true
};
req.exec = function (text) {
/*jslint evil: true */
return eval(text);
};
//Set up with config info.
req(cfg);这一段代码是解析定义是模块所需的依赖放置 context 的模块定义队列中。然后我们就要通过 req 去执行加载依赖,我们来看看 req 的定义。
req = requirejs = function (deps, callback, errback, optional) {
//Find the right context, use default
var context, config,
contextName = defContextName;
// Determine if have config object in the call.
if (!isArray(deps) && typeof deps !== 'string') {
// deps is a config object
config = deps;
if (isArray(callback)) {
// Adjust args if there are dependencies
deps = callback;
callback = errback;
errback = optional;
} else {
deps = [];
}
}
if (config && config.context) {
contextName = config.context;
}
if (config) {
context.configure(config); // 完善配置
}
return context.require(deps, callback, errback); 这里的代码把 依赖,回调, 错误处理和配置项都传进来了,进行了配置上的处理之后,我们可以看到最后再去根据配置加载。
我们再来看 context.require 方法:
makeRequire: function (relMap, options) {
options = options || {};
function localRequire(deps, callback, errback) {
.... 当前 require 的转换
return localRequire;
}
completeLoad: function (moduleName) {
判断 context 的依赖队列,是继续加载还是执行回调
}
nameToUrl: function (moduleName, ext, skipExt) {
根据模块名和配置得到加载的路径
}
load: function (id, url) {
req.load(context, id, url);
},
execCb: function (name, callback, args, exports) {
return callback.apply(exports, args);
},
onScriptLoad: function (evt) {
脚本加载完成后得到数据,执行 context.completeLoad(data.id);
}
onScriptError: function (evt) {
加载错误执行错误处理
}
};
context.require = context.makeRequire();以上原文转载自:https://blog.csdn.net/dadadeganhuo/article/details/86777249
第 25 题:说说浏览器和 Node 事件循环(Event Loop)的区别
浏览器的event loop 和nodejs的event loop 在处理异步事件的顺序是不同的。
nodejs中有micro event;其中Promise属于micro event 该异步事件的处理顺序就和浏览器不同.
nodejs V11.0以上 这两者之间的顺序就相同了。
浏览器
关于微任务和宏任务在浏览器的执行顺序是这样的:
- 执行一只task(宏任务)
- 执行完micro-task队列 (微任务)
如此循环往复下去。
- 常见的 task(宏任务):
比如:setTimeout、setInterval、script(整体代码)、 I/O 操作、UI 渲染等。
- 常见的 micro-task :
比如: new Promise().then(回调)、MutationObserver(html5新特性) 等。
Node
Node的事件循环是libuv实现的。
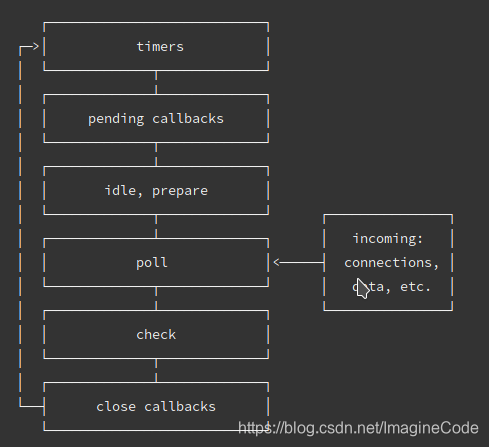
大体的task(宏任务)执行顺序是这样的:
- timers定时器:本阶段执行已经安排的 setTimeout() 和 setInterval() 的回调函数。
- pending callbacks待定回调:执行延迟到下一个循环迭代的 I/O 回调。
- idle, prepare:仅系统内部使用。
- poll 轮询:检索新的 I/O 事件;执行与 I/O 相关的回调(几乎所有情况下,除了关闭的回调函数,它们由计时器和 setImmediate() 排定的之外),其余情况 node 将在此处阻塞。
- check 检测:setImmediate() 回调函数在这里执行。
- close callbacks 关闭的回调函数:一些准备关闭的回调函数,如:socket.on(‘close’, …)。
示例:
function test () {
console.log('start')
setTimeout(() => {
console.log('children2')
Promise.resolve().then(() => {console.log('children2-1')})
}, 0)
setTimeout(() => {
console.log('children3')
Promise.resolve().then(() => {console.log('children3-1')})
}, 0)
Promise.resolve().then(() => {console.log('children1')})
console.log('end')
}
test()在**node11以下**版本的执行结果**(先执行所有的宏任务,再执行微任务)**
// start
// end
// children1
// children2
// children3
// children2-1
// children3-1在**node11+及浏览器的执行结果**(**顺序执行宏任务和微任务**)
// start
// end
// children1
// children2
// children2-1
// children3
// children3-1参考
- JavaScript 运行机制详解:再谈Event Loop
- 分享node与浏览器关于eventLoop的异同的一个小例子
- 浏览器与Node的事件循环(Event Loop)有何区别?
- html#event-loops
- Node.js 事件循环,定时器和 process.nextTick()
第 24 题:聊聊 Redux 和 Vuex 的设计思想
状态管理对于前端单页应用的管理思想的精髓:
- Web应用是一个状态机,视图与状态是一一对应的。 一旦认同这种模式并在项目组使用了状态管理,就要严格的在整个应用中都采用这种模式。因此,基于这种特性,我们需要一种机制或者框架:使得我们能够管理状态,感知变化,并将状态映射为页面表现。
VUEX是吸收了Redux的经验,放弃了一些特性并做了一些优化,代价就是VUEX只能和VUE配合。
而Redux则是一个纯粹的状态管理系统,React利用React-Redux将它与React框架结合起来。但是,它们必然在都具备常规的状态管理的功能之外,针对性地对各自所对应的框架还会有一些更优的特性,并且React-Redux还有一些衍生项目。例如:dva.js
Redux
一个单纯的状态管理者。它提供一个全局的对象store,store中包含state对象用以包含所有应用数据,并且store提供了一些reducer方法。这些方法可以自定义,使用调用者得以改变state的值。state的值仅为只读,如果需要更改则必须只能通过reducer。
React-Redux,简单来说,它提供了一些接口,用于Redux的状态和React的组件展示结合起来,以用于实现状态与视图的一一对应。
DVA,则是对React-Redux进行了封装,并结合了Redux-Saga等中间件,而且使用了model概念,也相当于在React-Redux的基础上针对web应用开发做了优化。
DVA数据流向图
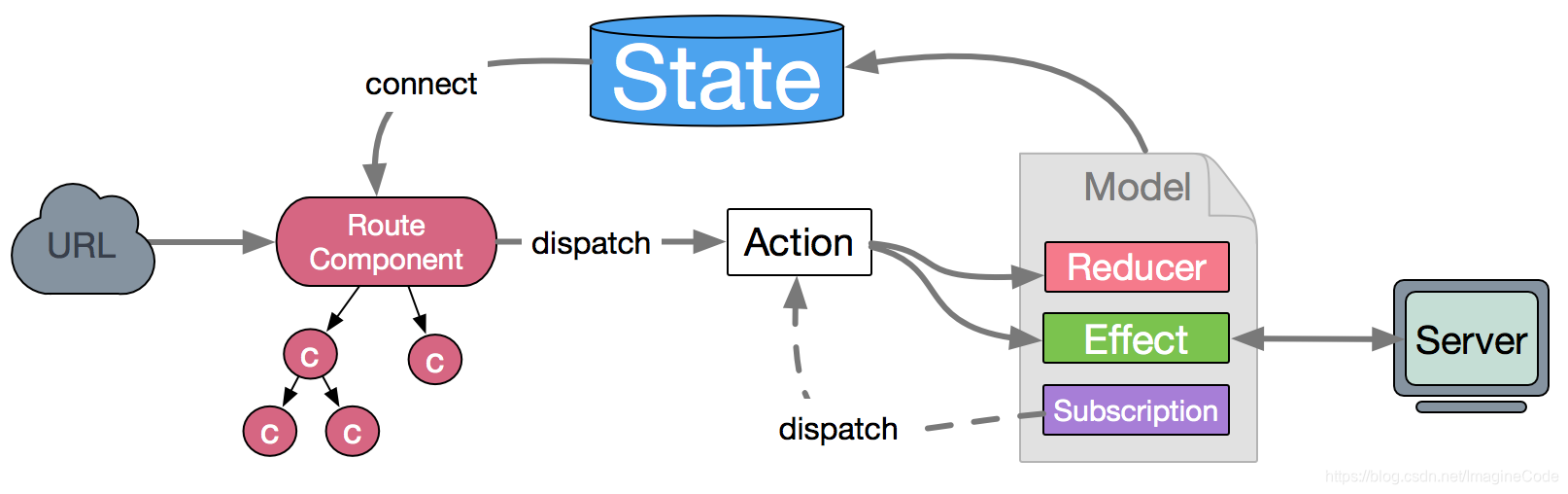
Vuex
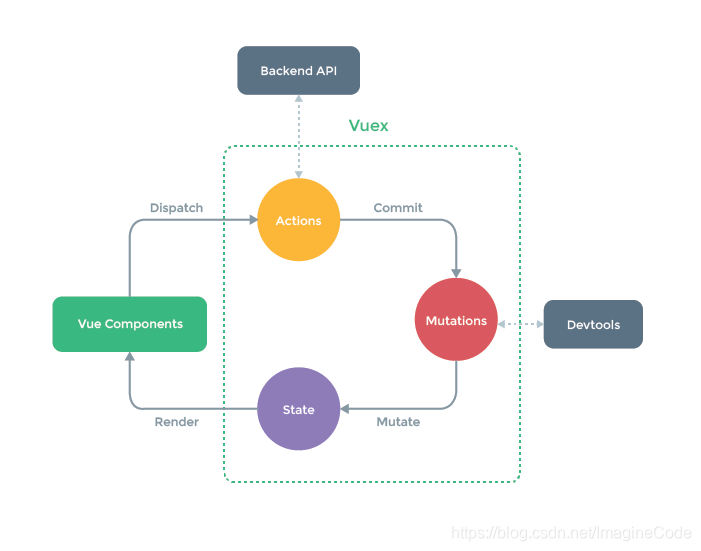
Redux与Vuex对比
Redux
- 核心对象:store
- 数据存储:state
- 状态更新提交接口:dispatch
- 状态更新提交参数:带type和payload的Action
- 状态更新计算:reducer
- 限制:reducer必须是纯函数,不支持异步
- 特性:支持中间件
VUEX
- 核心对象:store
- 数据存储:state
- 状态更新提交接口:commit
- 状态更新提交参数:带type和payload的mutation提交对象/参数
- 状态更新计算:mutation handler
- 限制:mutation handler必须是非异步方法
- 特性:支持带缓存的getter,用于获取state经过某些计算后的值
store和state是最基本的概念,VUEX没有做出改变。其实VUEX对整个框架思想并没有任何改变,只是某些内容变化了名称或者叫法,通过改名,以图在一些细节概念上有所区分。
- VUEX弱化了dispatch的存在感。VUEX认为状态变更的触发是一次“提交”而已,而调用方式则是框架提供一个提交的commit API接口。
- VUEX取消了Redux中Action的概念。不同于Redux认为状态变更必须是由一次"行为"触发,VUEX仅仅认为在任何时候触发状态变化只需要进行mutation即可。Redux的Action必须是一个对象,而VUEX认为只要传递必要的参数即可,形式不做要求。
- VUEX也弱化了Redux中的reducer的概念。reducer在计算机领域语义应该是"规约",在这里意思应该是根据旧的state和Action的传入参数,“规约"出新的state。在VUEX中,对应的是mutation,即"转变”,只是根据入参对旧state进行"转变"而已。
总的来说,VUEX通过弱化概念,在任何东西都没做实质性削减的基础上,使得整套框架更易于理解了。
另外VUEX支持getter,运行中是带缓存的,算是对提升性能方面做了些优化工作,言外之意也是鼓励大家多使用getter。
第 23 题:介绍下观察者模式和订阅-发布模式的区别,各自适用于什么场景
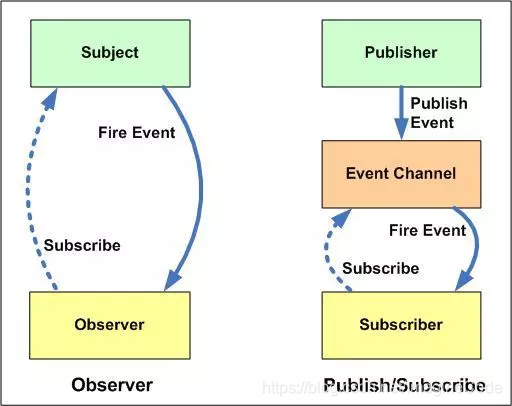
- 观察者模式中主体和观察者是互相感知的; 假设你正在找一份软件工程师的工作,对“香蕉公司”很感兴趣。所以你联系了他们的HR,给了他你的联系电话。他保证如果有任何职位空缺都会通知你。这里还有几个候选人也你一样很感兴趣。所以职位空缺大家都会知道,如果你回应了他们的通知,他们就会联系你面试。 这里的“香蕉公司”就是Subject,用来维护Observers(和你一样的候选人),为某些event(比如职位空缺)来通知(notify)观察者。
- 发布-订阅模式是借助第三方来实现调度的,发布者和订阅者之间互不感知 在发布-订阅模式,消息的发送方,叫做发布者(publishers),消息不会直接发送给特定的接收者,叫做订阅者。 意思就是发布者和订阅者不知道对方的存在。需要一个第三方组件,叫做信息中介,它将订阅者和发布者串联起来,它过滤和分配所有输入的消息。换句话说,发布-订阅模式用来处理不同系统组件的信息交流,即使这些组件不知道对方的存在。
用一张图片进行解释:
参考
第22题:介绍下重绘和回流(Repaint & Reflow),以及如何进行优化
1. 浏览器渲染机制
浏览器采用流式布局模型(Flow Based Layout)
浏览器会把HTML解析成DOM,把CSS解析成CSSOM,DOM和CSSOM合并就产生了渲染树(Render Tree)。
有了RenderTree,我们就知道了所有节点的样式,然后计算他们在页面上的大小和位置,最后把节点绘制到页面上。
由于浏览器使用流式布局,对Render Tree的计算通常只需要遍历一次就可以完成,但table及其内部元素除外,他们可能需要多次计算,通常要花3倍于同等元素的时间,这也是为什么要避免使用table布局的原因之一。
浏览器渲染过程如下:
- 解析HTML,生成DOM树,解析CSS,生成CSSOM树
- 将DOM树和CSSOM树结合,生成渲染树(Render Tree)
- Layout(回流):根据生成的渲染树,进行回流(Layout),得到节点的几何信息(位置,大小)
- Painting(重绘):根据渲染树以及回流得到的几何信息,得到节点的绝对像素
- Display:将像素发送给GPU,展示在页面上。(这一步其实还有很多内容,比如会在GPU将多个合成层合并为同一个层,并展示在页面中。而css3硬件加速的原理则是新建合成层)
为了构建渲染树,浏览器主要完成了以下工作:
从DOM树的根节点开始遍历每个可见节点。
对于每个可见的节点,找到CSSOM树中对应的规则,并应用它们。
根据每个可见节点以及其对应的样式,组合生成渲染树。
第一步中,既然说到了要遍历可见的节点,那么我们得先知道,什么节点是不可见的。
不可见的节点包括:
一些不会渲染输出的节点,比如script、meta、link等。
一些通过css进行隐藏的节点。比如display:none。注意,利用visibility和opacity隐藏的节点,还是会显示在渲染树上的。只有display:none的节点才不会显示在渲染树上。
从上面的例子来讲,我们可以看到span标签的样式有一个display:none,因此,它最终并没有在渲染树上。
注意:渲染树只包含可见的节点
2. 回流
回流是布局或者几何属性需要改变就称为回流。回流是影响浏览器性能的关键因素,因为其变化涉及到部分页面(或是整个页面)的布局更新。一个元素的回流可能会导致了其所有子元素以及DOM中紧随其后的节点、祖先节点元素的随后的回流。
通过构造渲染树,我们将可见DOM节点以及它对应的样式结合起来,可是我们还需要计算它们在设备视口(viewport)内的确切位置和大小,这个计算的阶段就是回流。
示例:
<body>
<div class="error">
<h4>我的组件</h4>
<p><strong>错误:</strong>错误的描述…</p>
<h5>错误纠正</h5>
<ol>
<li>第一步</li>
<li>第二步</li>
</ol>
</div>
</body>在上面的HTML片段中,对该段落(<p>标签)回流将会引发强烈的回流,因为它是一个子节点。这也导致了祖先的回流(div.error和body·–视浏览器而定)。此外,<h5>和<ol>也会有简单的回流,因为其在DOM中在回流元素之后。大部分的回流将导致页面的重新渲染。
回流必定会发生重绘,重绘不一定会引发回流。
何时发生回流重绘
我们前面知道了,回流这一阶段主要是计算节点的位置和几何信息,那么当页面布局和几何信息发生变化的时候,就需要回流。比如以下情况:
- 添加或删除可见的DOM元素
- 元素的位置发生变化
- 元素的尺寸发生变化(包括外边距、内边框、边框大小、高度和宽度等)
- 内容发生变化,比如文本变化或图片被另一个不同尺寸的图片所替代。
- 页面一开始渲染的时候(这肯定避免不了)
- 浏览器的窗口尺寸变化(因为回流是根据视口的大小来计算元素的位置和大小的)
3. 重绘
由于节点的几何属性发生改变或者由于样式发生改变而不会影响布局的,称为重绘,例如outline, visibility, color、background-color等,重绘的代价是高昂的,因为浏览器必须验证DOM树上其他节点元素的可见性。
我们通过构造渲染树和回流阶段,我们知道了哪些节点是可见的,以及可见节点的样式和具体的几何信息(位置、大小),那么我们就可以将渲染树的每个节点都转换为屏幕上的实际像素,这个阶段就叫做重绘节点。
4. 浏览器优化
现代浏览器大多都是通过队列机制来批量更新布局,浏览器会把修改操作放在队列中,至少一个浏览器刷新(即16.6ms)才会清空队列,但当你获取布局信息的时候,队列中可能有会影响这些属性或方法返回值的操作,即使没有,浏览器也会强制清空队列,触发回流与重绘来确保返回正确的值。
主要包括以下属性或方法:
- offsetTop、offsetLeft、offsetWidth、offsetHeight
- scrollTop、scrollLeft、scrollWidth、scrollHeight
- clientTop、clientLeft、clientWidth、clientHeight
- width、height
- getComputedStyle()
- getBoundingClientRect()
所以,我们应该避免频繁的使用上述的属性,他们都会强制渲染刷新队列。
5. 减少重绘与回流
1、 CSS
使用 transform 替代 top
使用visibility替换display:none,因为前者只会引起重绘,后者会引发回流(改变了布局)
- 避免使用table布局,可能很小的一个小改动会造成整个
table的重新布局。 - 尽可能在DOM树的最末端改变class,回流是不可避免的,但可以减少其影响。尽可能在DOM树的最末端改变class,可以限制了回流的范围,使其影响尽可能少的节点。
- 避免设置多层内联样式,CSS 选择符从右往左匹配查找,避免节点层级过多。
<div>
<a> <span></span> </a>
</div>
<style>
span {
color: red;
}
div > a > span {
color: red;
}
</style>对于第一种设置样式的方式来说,浏览器只需要找到页面中所有的span标签然后设置颜色,但是对于第二种设置样式的方式来说,浏览器首先需要找到所有的span标签,然后找到span标签上的a标签,最后再去找到div标签,然后给符合这种条件的span标签设置颜色,这样的递归过程就很复杂。所以我们应该尽可能的避免写过于具体的 CSS 选择器,然后对于 HTML 来说也尽量少的添加无意义标签,保证层级扁平。
- 将动画效果应用到position属性为absolute或fixed的元素上,避免影响其他元素的布局,这样只是一个重绘,而不是回流,同时,控制动画速度可以选择 requestAnimationFrame,详见探讨 requestAnimationFrame。
- 避免使用CSS表达式,可能会引发回流。
- 将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点,例如**will-change、video、iframe等标签,浏览器会自动将该节点变为图层。
- CSS3 硬件加速(GPU加速),使用css3硬件加速,可以让transform、opacity、filters这些动画不会引起回流重绘。但是对于动画的其它属性,比如background-color这些,还是会引起回流重绘的,不过它还是可以提升这些动画的性能。
2、JavaScript
- 避免频繁操作样式,最好一次性重写style属性,或者将样式列表定义为class并一次性更改class属性。
- 避免频繁操作DOM,创建一个documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中。
- 避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个变量缓存起来。
- 对具有复杂动画的元素使用绝对定位,使它脱离文档流,否则会引起父元素及后续元素频繁回流。
最小化重绘和重排
由于重绘和重排可能代价比较昂贵,因此最好就是可以减少它的发生次数。为了减少发生次数,我们可以合并多次对DOM和样式的修改,然后一次处理掉。考虑这个例子
const el = document.getElementById('test');
el.style.padding = '5px';
el.style.borderLeft = '1px';
el.style.borderRight = '2px';例子中,有三个样式属性被修改了,每一个都会影响元素的几何结构,引起回流。当然,大部分现代浏览器都对其做了优化,因此,只会触发一次重排。但是如果在旧版的浏览器或者在上面代码执行的时候,有其他代码访问了布局信息(上文中的会触发回流的布局信息),那么就会导致三次重排。
因此,我们可以合并所有的改变然后依次处理,比如我们可以采取以下的方式:
- 使用cssText
const el = document.getElementById('test');
el.style.cssText += 'border-left: 1px; border-right: 2px; padding: 5px;';- 修改CSS的class
const el = document.getElementById('test');
el.className += ' active';批量修改DOM
当我们需要对DOM对一系列修改的时候,可以通过以下步骤减少回流重绘次数:
- 使元素脱离文档流
- 对其进行多次修改
- 将元素带回到文档中。
该过程的第一步和第三步可能会引起回流,但是经过第一步之后,对DOM的所有修改都不会引起回流重绘,因为它已经不在渲染树了。
有三种方式可以让DOM脱离文档流:
- 隐藏元素,应用修改,重新显示
- 使用文档片段(document fragment)在当前DOM之外构建一个子树,再把它拷贝回文档。
- 将原始元素拷贝到一个脱离文档的节点中,修改节点后,再替换原始的元素。
考虑我们要执行一段批量插入节点的代码:
function appendDataToElement(appendToElement, data) {
let li;
for (let i = 0; i < data.length; i++) {
li = document.createElement('li');
li.textContent = 'text';
appendToElement.appendChild(li);
}
}
const ul = document.getElementById('list');
appendDataToElement(ul, data);如果我们直接这样执行的话,由于每次循环都会插入一个新的节点,会导致浏览器回流一次。
我们可以使用这三种方式进行优化:
隐藏元素,应用修改,重新显示:
这个会在展示和隐藏节点的时候,产生两次回流
function appendDataToElement(appendToElement, data) {
let li;
for (let i = 0; i < data.length; i++) {
li = document.createElement('li');
li.textContent = 'text';
appendToElement.appendChild(li);
}
}
const ul = document.getElementById('list');
ul.style.display = 'none';
appendDataToElement(ul, data);
ul.style.display = 'block';使用文档片段(document fragment)在当前DOM之外构建一个子树,再把它拷贝回文档:
const ul = document.getElementById('list');
const fragment = document.createDocumentFragment();
appendDataToElement(fragment, data);
ul.appendChild(fragment);将原始元素拷贝到一个脱离文档的节点中,修改节点后,再替换原始的元素。
const ul = document.getElementById('list');
const clone = ul.cloneNode(true);
appendDataToElement(clone, data);
ul.parentNode.replaceChild(clone, ul);避免触发同步布局事件
当我们访问元素的一些属性的时候,会导致浏览器强制清空队列,进行强制同步布局。举个例子,比如说我们想将一个p标签数组的宽度赋值为一个元素的宽度,我们可能写出这样的代码:
function initP() {
for (let i = 0; i < paragraphs.length; i++) {
paragraphs[i].style.width = box.offsetWidth + 'px';
}在每次循环的时候,都读取了box的一个offsetWidth属性值,然后利用它来更新p标签的width属性。这就导致了每一次循环的时候,浏览器都必须先使上一次循环中的样式更新操作生效,才能响应本次循环的样式读取操作。每一次循环都会强制浏览器刷新队列。我们可以优化为:
const width = box.offsetWidth;
function initP() {
for (let i = 0; i < paragraphs.length; i++) {
paragraphs[i].style.width = width + 'px';
}
}对于复杂动画效果,使用绝对定位让其脱离文档流
对于复杂动画效果,由于会经常的引起回流重绘,因此,我们可以使用绝对定位,让它脱离文档流。否则会引起父元素以及后续元素频繁的回流。
- 使用css3硬件加速,可以让transform、opacity、filters这些动画不会引起回流重绘 。
- 对于动画的其它属性,比如background-color这些,还是会引起回流重绘的,不过它还是可以提升这些动画的性能。
常见的触发硬件加速的css属性:
- transform
- opacity
- filters
- Will-change
css3硬件加速的坑
当然,任何美好的东西都是会有对应的代价的,过犹不及。css3硬件加速还是有坑的:
- 如果你为太多元素使用css3硬件加速,会导致内存占用较大,会有性能问题。
- 在GPU渲染字体会导致抗锯齿无效。这是因为GPU和CPU的算法不同。因此如果你不在动画结束的时候关闭硬件加速,会产生字体模糊。
参考
- 渲染树构建、布局及绘制
- 书籍《高性能Javascript》
第21题:有以下 3 个判断数组的方法,请分别介绍它们之间的区别和优劣Object.prototype.toString.call() 、 instanceof 以及 Array.isArray()
- Object.prototype.toString.call()
每一个继承 Object 的对象都有 toString 方法,如果 toString 方法没有重写的话,会返回 [Object type],其中 type 为对象的类型。但当除了 Object 类型的对象外,其他类型直接使用 toString 方法时,会直接返回都是内容的字符串,所以我们需要使用call或者apply方法来改变toString方法的执行上下文。
const an = ['Hello','An'];
an.toString(); // "Hello,An"
Object.prototype.toString.call(an); // "[object Array]"这种方法对于所有基本的数据类型都能进行判断,即使是 null 和 undefined 。
更多实现可见 谈谈 Object.prototype.toString
- instanceof
instanceof 的内部机制是通过判断对象的原型链中是不是能找到类型的 prototype。
使用 instanceof判断一个对象是否为数组,instanceof 会判断这个对象的原型链上是否会找到对应的 Array 的原型,找到返回 true,否则返回 false。
[] instanceof Array; // true但 instanceof 只能用来判断对象类型,原始类型不可以。并且所有对象类型 instanceof Object 都是 true。
[] instanceof Object; // true- Array.isArray()
- 功能:用来判断对象是否为数组
- instanceof 与 isArray
当检测Array实例时,Array.isArray 优于 instanceof ,因为 Array.isArray 可以检测出 iframes
var iframe = document.createElement('iframe');
document.body.appendChild(iframe);
xArray = window.frames[window.frames.length-1].Array;
var arr = new xArray(1,2,3); // [1,2,3]
// Correctly checking for Array
Array.isArray(arr); // true
Object.prototype.toString.call(arr); // true
// Considered harmful, because doesn't work though iframes
arr instanceof Array; // falseArray.isArray()与Object.prototype.toString.call()Array.isArray()是ES5新增的方法,当不存在Array.isArray(),可以用Object.prototype.toString.call()实现。
if (!Array.isArray) {
Array.isArray = function(arg) {
return Object.prototype.toString.call(arg) === '[object Array]';
};
} Array.isArray 的性能最好,instanceof 比 toString.call 稍微好了一点点
参考
https://www.cnblogs.com/onepixel/p/5126046.html
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Array/isArray
第20题:介绍下 npm 模块安装机制,为什么输入 npm install 就可以自动安装对应的模块?
1. npm 模块安装机制:
- 发出
npm install命令 - 查询node_modules目录之中是否已经存在指定模块
- 若存在,不再重新安装- 若不存在 - npm 向 registry 查询模块压缩包的网址
- 下载压缩包,存放在根目录下的`.npm`目录里解压压缩包到当前项目的2. npm 实现原理
输入 npm install 命令并敲下回车后,会经历如下几个阶段(以 npm 5.5.1 为例):
- 执行工程自身 preinstall
当前 npm 工程如果定义了 preinstall 钩子此时会被执行。
- 确定首层依赖模块
首先需要做的是确定工程中的首层依赖,也就是 dependencies 和 devDependencies 属性中直接指定的模块(假设此时没有添加 npm install 参数)。
工程本身是整棵依赖树的根节点,每个首层依赖模块都是根节点下面的一棵子树,npm 会开启多进程从每个首层依赖模块开始逐步寻找更深层级的节点。
- 获取模块
获取模块是一个递归的过程,分为以下几步:
- 获取模块信息。在下载一个模块之前,首先要确定其版本,这是因为 package.json 中往往是 semantic version(semver,语义化版本)。此时如果版本描述文件(npm-shrinkwrap.json 或 package-lock.json)中有该模块信息直接拿即可,如果没有则从仓库获取。如 packaeg.json 中某个包的版本是 ^1.1.0,npm 就会去仓库中获取符合 1.x.x 形式的最新版本。
- 获取模块实体。上一步会获取到模块的压缩包地址(resolved 字段),npm 会用此地址检查本地缓存,缓存中有就直接拿,如果没有则从仓库下载。
- 查找该模块依赖,如果有依赖则回到第1步,如果没有则停止。
- 模块扁平化(dedupe)
上一步获取到的是一棵完整的依赖树,其中可能包含大量重复模块。比如 A 模块依赖于 loadsh,B 模块同样依赖于 lodash。在 npm3 以前会严格按照依赖树的结构进行安装,因此会造成模块冗余。
从 npm3 开始默认加入了一个 dedupe 的过程。它会遍历所有节点,逐个将模块放在根节点下面,也就是 node-modules 的第一层。当发现有重复模块时,则将其丢弃。
这里需要对重复模块进行一个定义,它指的是模块名相同且 semver 兼容。每个 semver 都对应一段版本允许范围,如果两个模块的版本允许范围存在交集,那么就可以得到一个兼容版本,而不必版本号完全一致,这可以使更多冗余模块在 dedupe 过程中被去掉。
比如 node-modules 下 foo 模块依赖 lodash@^1.0.0,bar 模块依赖 lodash@^1.1.0,则 ^1.1.0 为兼容版本。
而当 foo 依赖 lodash@^2.0.0,bar 依赖 lodash@^1.1.0,则依据 semver 的规则,二者不存在兼容版本。会将一个版本放在 node_modules 中,另一个仍保留在依赖树里。
举个例子,假设一个依赖树原本是这样:
node_modules
– foo
---- lodash@version1
– bar
---- lodash@version2
假设 version1 和 version2 是兼容版本,则经过 dedupe 会成为下面的形式:
node_modules
– foo
– bar
– lodash(保留的版本为兼容版本)
假设 version1 和 version2 为非兼容版本,则后面的版本保留在依赖树中:
node_modules
– foo
– lodash@version1
– bar
---- lodash@version2
- 安装模块
这一步将会更新工程中的 node_modules,并执行模块中的生命周期函数(按照 preinstall、install、postinstall 的顺序)。
- 执行工程自身生命周期
当前 npm 工程如果定义了钩子此时会被执行(按照 install、postinstall、prepublish、prepare 的顺序)。
最后一步是生成或更新版本描述文件,npm install 过程完成。
参考
npm 模块安装机制简介
转载参考
https://github.com/Advanced-Frontend/Daily-Interview-Question
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号