CMU 15-445 -- Query Optimization - 10

CMU 15-445 -- Query Optimization - 10

大忽悠爱学习
发布于 2023-10-11 09:04:56
发布于 2023-10-11 09:04:56
CMU 15-445 -- Query Optimization - 10
引言
本系列为 CMU 15-445 Fall 2022 Database Systems 数据库系统 [卡内基梅隆] 课程重点知识点摘录,附加个人拙见,同样借助CMU 15-445课程内容来完成MIT 6.830 lab内容。
SQL 语句让我们能够描述想要获取的数据,而 DBMS 负责来根据用户的需求来制定高效的查询计划。不同的查询计划的效率可能出现多个数量级的差别,如 Join Algorithms 一节中的 Simple Nested Loop Join 与 Hash Join 的时间对比 (1.3 hours vs. 0.45 seconds)。
Query Optimizer 第一次出现在 IBM System R,那时人们认为 DBMS 指定的查询计划永远无法比人类指定的更好。System R 的 optimizer 中的一些理念至今仍在使用。
Query Optimization Techniques
Heuristics/Rules
- Rewrite the query to remove stupid/inefficient things
- Does not require a cost model
Cost-based Search
- Use a cost model to evaluate multiple equivalent plans and pick the one with the lowest cost
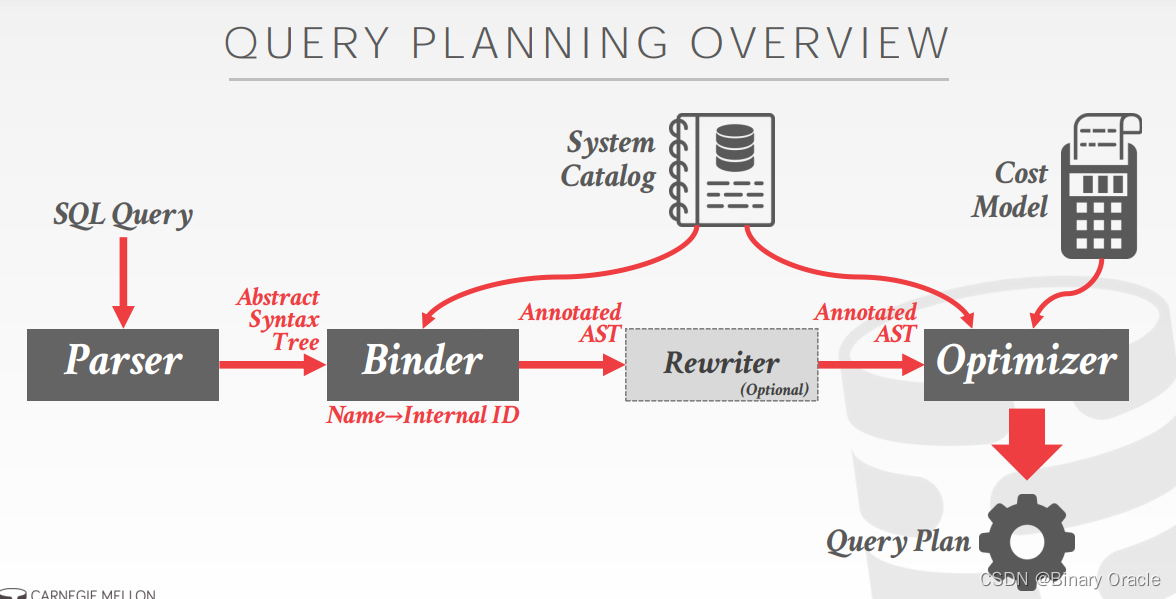
这里的 Rewriter 负责 Heuristics/Rules,Optimizer 则负责 Cost-based Search。
Query Rewriting
如果两个关系代数表达式 (Relational Algebra Expressions) 如果能产生相同的 tuple 集合,我们就称二者等价。DBMS 可以通过一些 Heuristics/Rules 来将关系几何表达式转化成成本更低的等价表达式,从而达到查询优化的目的。这些规则通常试用于所有查询,如:
- Predicate Pushdown(谓词下推): Predicate Pushdown指的是将查询中的谓词操作尽早地推送到数据源或存储引擎进行执行,以减少处理的数据量。通常,在数据库查询中,谓词操作用于筛选出满足特定条件的数据行。谓词下推的目的是在查询执行之前尽早地应用谓词,减少查询的数据集大小,从而提高查询的效率。
- 例如,如果一个查询包含多个谓词条件(如WHERE子句),谓词下推会尽可能早地将这些条件下推到存储引擎执行,以减少返回给查询引擎的数据量。这样可以减少IO和计算开销,并提高查询性能。
- Projections Pushdown (投影下推):Projections Pushdown指的是将查询中的投影操作尽早地推送到数据源或存储引擎进行执行,以减少返回给查询引擎的数据量。在数据库查询中,投影操作用于指定需要返回的列或字段。投影下推的目的是在查询执行之前尽早地应用投影操作,减少返回的数据列数量,从而降低数据传输和存储开销。
- 例如,如果一个查询只需要返回特定的列数据,而数据源可能包含更多的列,投影下推会尽早地将投影操作下推到存储引擎执行,以便只返回所需的列数据,避免传输和处理不必要的数据。
Predicate Pushdown
Predicate 通常有很高的选择性,可以过滤掉许多无用的数据。将 Predicate 推到查询计划的底部,可以在查询开始时就更多地过滤数据,举例如下:
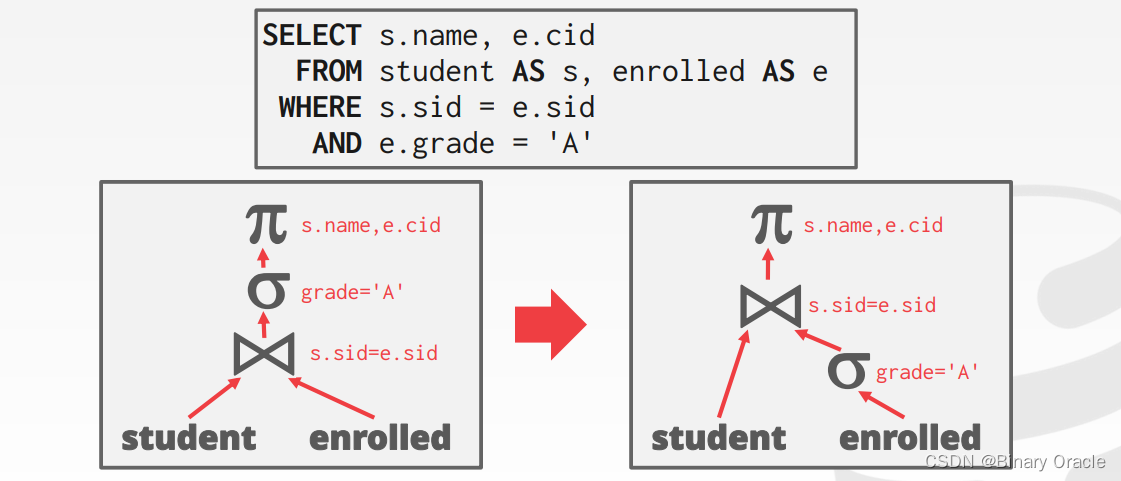

核心思想如下:
- 越早过滤越多数据越好
- 重排 predicates,使得选择性大的排前面,选择性大指的是能够更有效地筛选出所需数据行的谓词,使得DBMS能够更早地过滤掉不相关的数据,从而提高查询性能
- 将复杂的 predicate 拆分,然后往下压,如
X=Y AND Y=3可以修改成X=3 AND Y=3
Projections Pushdown
本方案对列存储数据库不适用。在行存储数据库中,越早过滤掉不用的字段越好,因此将 Projections 操作往查询计划底部推也能够缩小中间结果占用的空间大小,举例如下:
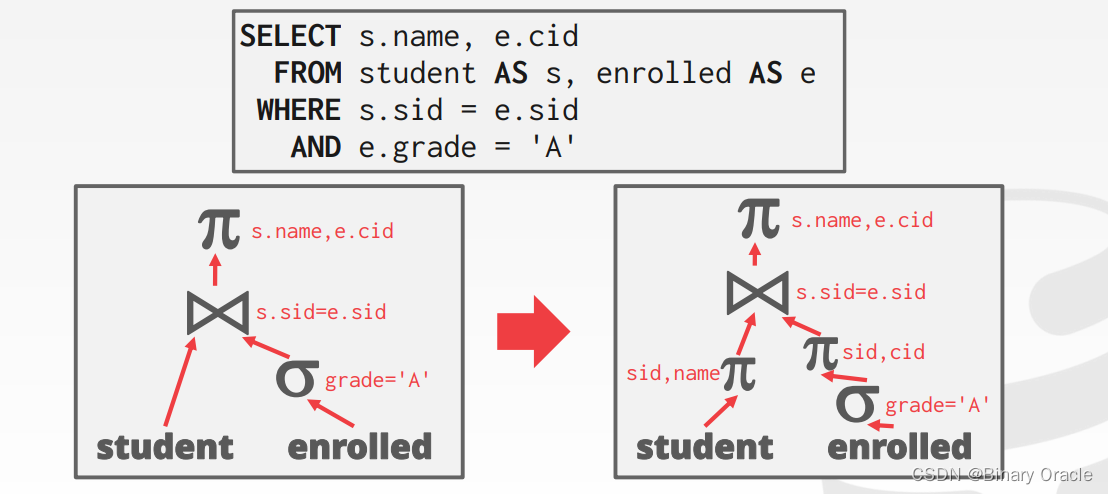
Cost-based Search
除了 Predicates 和 Projections 以外,许多操作没有通用的规则,如 Join:Join 操作既符合交换律又符合结合律,等价关系代数表达式数量庞大,这时候就需要一些成本估算技术,将过滤性大的表作为 Outer Table,小的作为 Inner Table,从而达到查询优化的目的。
Cost Estimation
一个查询需要花费多长时间,取决于许多因素
- CPU: Small cost; tough to estimate
- Disk: #block transfers
- Memory: Amount of DRAM used
- Network: #messages
但本质上取决于:整个查询过程需要读入和写出多少 tuples 。
因此 DBMS 需要保存每个 table 的一些统计信息,如 attributes、indexes 等信息,有助于估计查询成本。值得一提的是,不同的 DBMS 的搜集、更新统计信息的策略不同。
Statistics
通常,DBMS 对任意的 table R,都保存着以下信息:

利用上面两条数据,可以得到 selection cardinality,即 R 中 A 属性下每个值的平均记录个数:
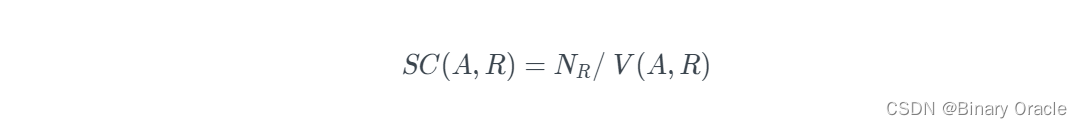
需要注意的是,这种估计假设 R 中所有数据在 A 属性下均匀分布 (data uniformity)。
利用以上信息和假设,DBMS 可以估计不同 predicates 的 selectivity:
- Equality
- Range
- Negation
- Conjunction
- Disjunction
Equality Predicate
SELECT * FROM people WHERE age = 2;
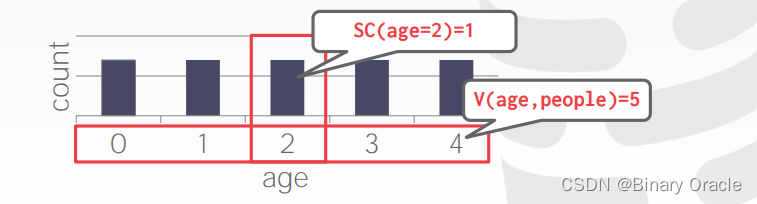
Range Predicate
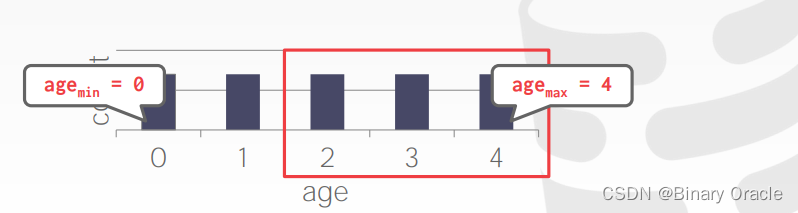
SELECT * FROM people WHERE age >= 2;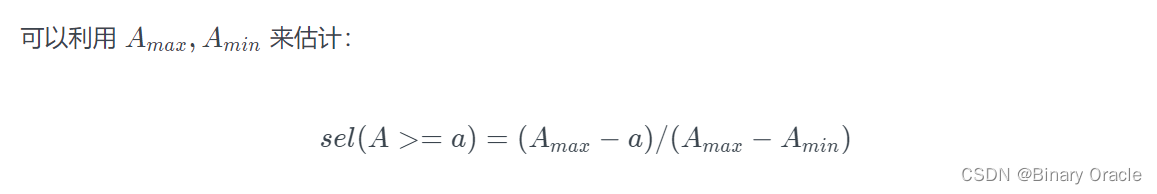
Negation Query
SELECT * FROM people WHERE age != 2;利用 equality query 可以反向推导出 negation query 的情况:
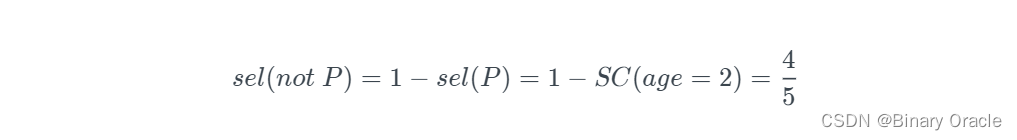
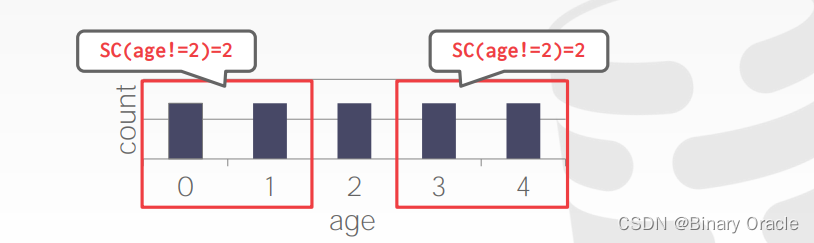
实际上这里所谓的 Selectivity 就是基于 uniformly distribution 假设下的 Probability。
Conjunction Query
SELECT * FROM people WHERE age = 2 AND name LIKE 'A%';若假设两个 predicates 之间相互独立,则可以推导出:
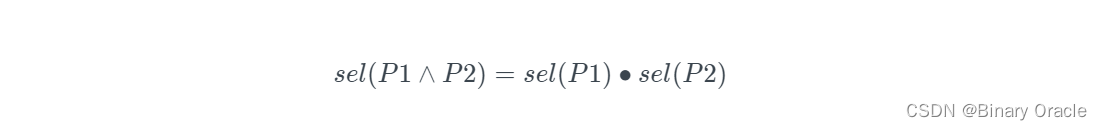
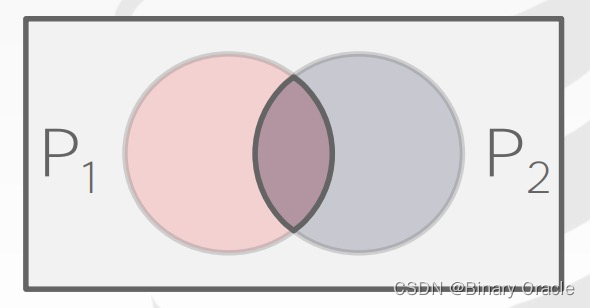
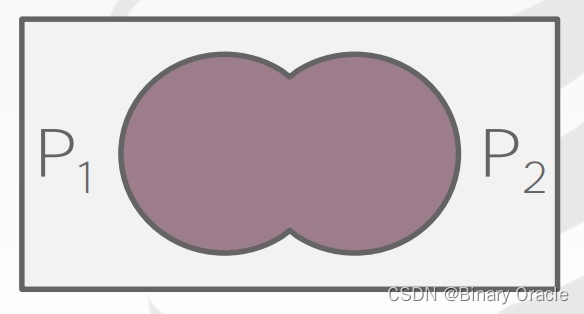
其韦恩图如下所示:
Disjunction Query
SELECT * FROM people
WHERE age = 2
OR name LIKE 'A%';若假设两个 predicates 之间相互独立,则可以推导出:
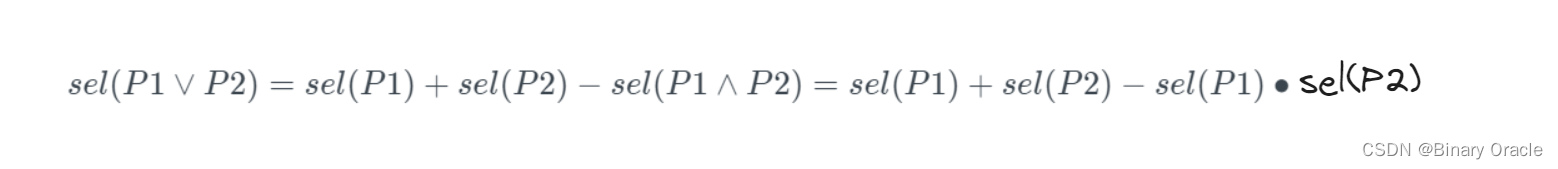
其韦恩图如下所示:
Joins

直方图
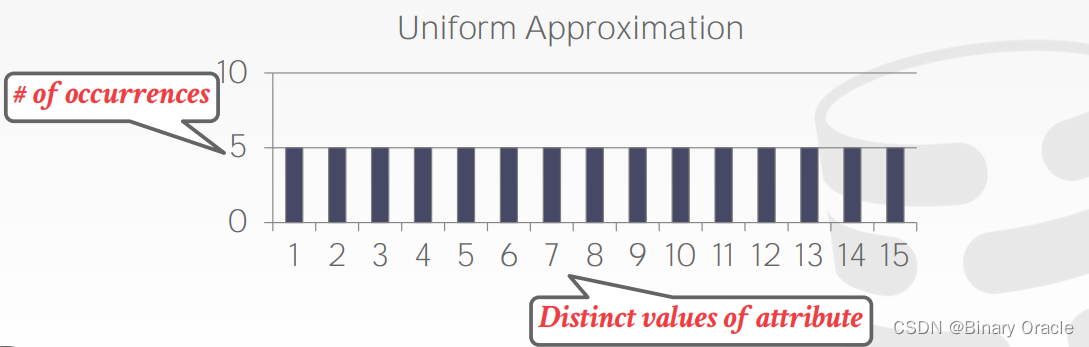
我们的公式是很好的,但是我们假设数据值是均匀分布的:
正常情况下,数据分布是不均匀的:
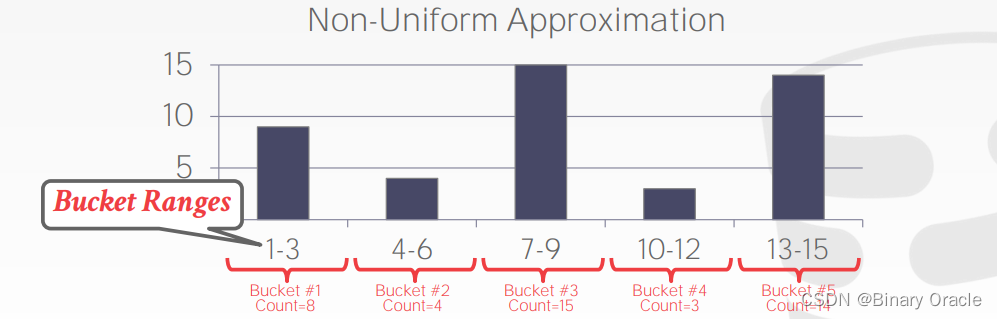
通过直方图(IntHistogram类)来计算选择性是通过以下步骤实现的:
- 数据收集:首先,需要收集统计信息来构建直方图。对于给定的列或属性,收集该列的数据值,并确定最小值和最大值。
- 桶的划分:根据收集到的最小值和最大值,将数据范围划分为多个桶(或区间)。桶的数量和大小可以根据具体需求进行调整。
- 数据分配:将数据值分配到相应的桶中。每个数据值都被映射到与其所属区间对应的桶中。
- 桶计数:在每个桶中,记录该桶中包含的数据值数量。
- 计算选择性:根据直方图中每个桶的计数值,计算选择性。选择性通常通过以下公式计算:选择性 = 1 / 桶中的数据值数量。
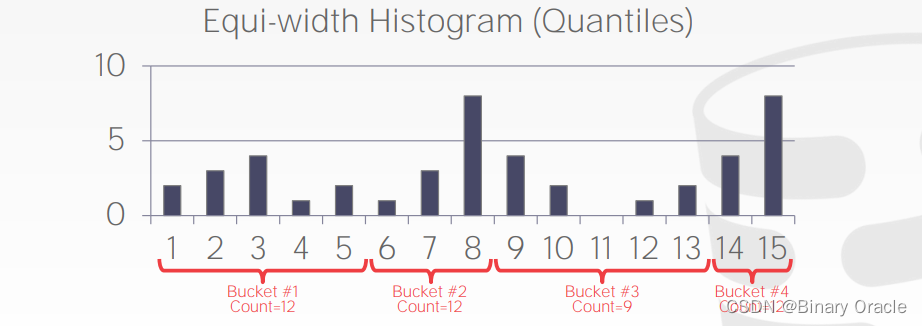
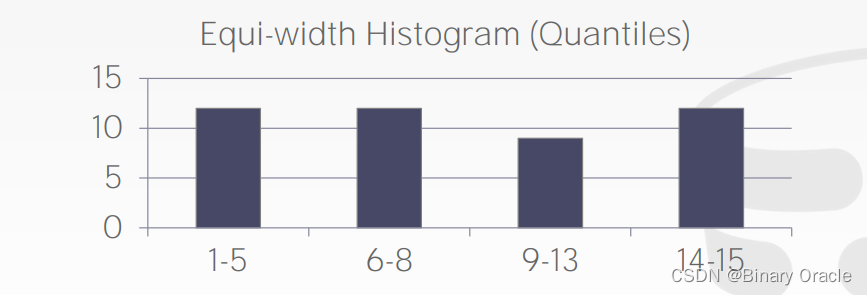
通过直方图中各个桶中的数据值数量,可以估计出特定值或谓词选择的概率。具有更多数据值的桶通常具有较低的选择性,而具有较少数据值的桶通常具有较高的选择性。
请注意,选择性估计是基于对数据分布的假设和直方图的统计信息。对于非均匀分布或包含离群值的数据集,选择性估计可能会有一定的误差。因此,在进行查询优化时,需要综合考虑其他因素和优化技术。
Samling
现代 DBMSs 也会使用采样技术来降低成本估计本身的成本,比如面对如下查询:
SELECT AVG(age)
FROM people
WHERE age > 50;我们可以等间隔从表中对数据采样:

然后再估计:
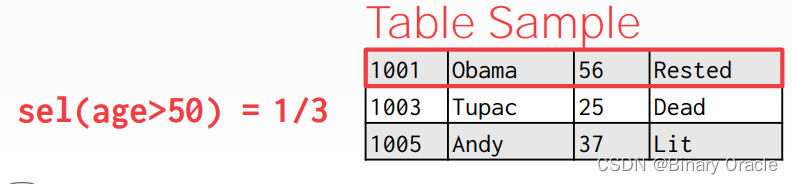
当然,为了避免重复采样,DMBS 会保存一份采样表,待 table 的变动较大时,再更新采样表。
成本估算小结
现在我们可以(大致)估计谓词的选择性,那么我们实际上可以用它们做什么呢?
- 查询优化:利用谓词选择性的估计值,查询优化器可以选择最高效的查询执行计划。通过了解谓词的选择性,优化器可以估计中间结果的大小,并选择最佳的连接顺序、连接算法和访问方法。
- 索引选择:选择性估计有助于确定用于查询的最有效索引。通过将谓词的选择性与索引的基数进行比较,我们可以确定可能提供最佳查询性能的索引。
- 连接顺序优化:选择性估计有助于确定查询中多个表的最佳连接顺序。通过估计连接谓词的选择性,优化器可以评估不同的连接顺序排列并选择估计成本最低的一个。
- 资源分配:选择性估计可以辅助资源分配决策。例如,如果谓词的选择性很高,表示符合条件的行数较少,系统可以为处理查询的这部分分配较少的资源。
在进行基于规则的重写之后,数据库管理系统(DBMS)将为查询枚举不同的计划并估算它们的成本:
- 单个关系。
- 多个关系。
- 嵌套子查询。 在枚举所有计划或达到某个超时时间后,DBMS会选择对查询来说最佳的计划。
选择最佳的访问方法
- 顺序扫描
- 二分搜索(聚集索引)
- 索引扫描
简单的启发式方法通常足够处理这个任务。
QLTP查询计划
对于OLTP查询来说,选择最佳访问方法相对容易,因为它们是可搜索谓词(sargable):
- 可搜索谓词(Search Argument Able)
- 通常只需选择最佳索引
- 连接几乎总是在具有小基数的外键关系上进行
- 可以使用简单的启发式方法实现
多关系查询规划
多关系查询规划(Multi-Relation Query Planning)是指在执行涉及多个关系(表)的查询时进行的规划过程。这个过程包括选择适当的连接顺序、连接算法和访问方法,以生成最优的查询执行计划。
随着连接数量的增加,可供选择的备选计划数量迅速增长:
- 我们需要限制搜索空间。
System R中的基本决策:只考虑左深连接树。
- 现代数据库管理系统不再总是做出这种假设。
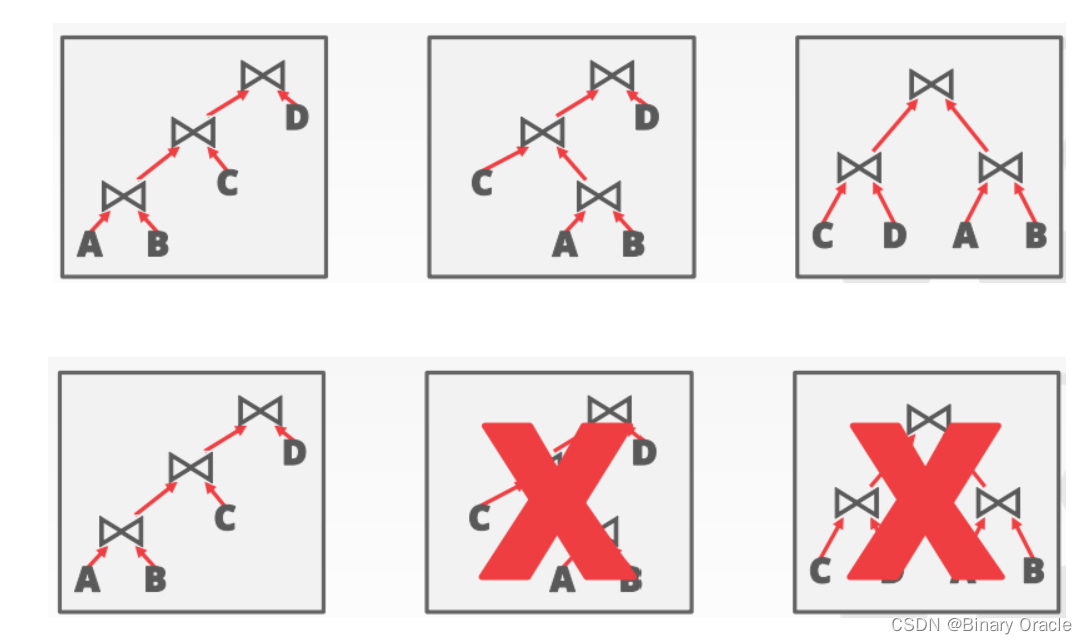
左深连接树是一种连接顺序,其中每个连接操作的右侧表是前一个连接操作的结果。这种限制连接顺序的方式有助于简化查询优化的任务,并降低了计划搜索的复杂性。
通过限制为左深连接树,查询优化器可以避免对所有可能的连接顺序进行枚举和计算,从而减少了查询优化的时间和计算成本。此外,左深连接树的特性也使得查询计划的生成和优化更加高效。
基于左深连接树的查询规划在某些情况下可以实现完全流水线化的计划,其中中间结果不需要写入临时文件:
- 并非所有左深连接树都可以实现完全流水线化。
- 某些情况下,连接操作的输入数据可能需要在中间阶段进行排序或分组,以满足连接操作的要求。这可能需要使用临时文件或临时表来存储中间结果,以便进行排序或分组操作。
动态规划在连接成本分析中的应用
对于每个表,枚举连接操作的顺序:
- 例如:左深连接树#1,左深连接树#2…
对于每个操作符,枚举计划:
- 例如:哈希连接,排序-合并连接,嵌套循环连接…
对于每个表格,枚举访问路径:
- 例如:索引#1,索引#2,顺序扫描…
在查询优化过程中,为了选择最佳的查询执行计划,需要枚举不同的连接顺序、操作符的计划和表格的访问路径。通过枚举不同的选择,可以比较它们的成本并选择最优的执行计划。
为了降低计划枚举的复杂性和避免重复的成本估计,动态规划被广泛应用于查询优化。动态规划技术可以利用之前计算过的成本估计结果,通过存储和重用中间计算结果,避免重复的计算,从而减少计算成本和时间。
通过使用动态规划,查询优化器可以有效地探索不同的连接顺序、操作符计划和表格访问路径的组合,以选择最佳的执行计划,并在优化过程中降低计算成本和复杂性。
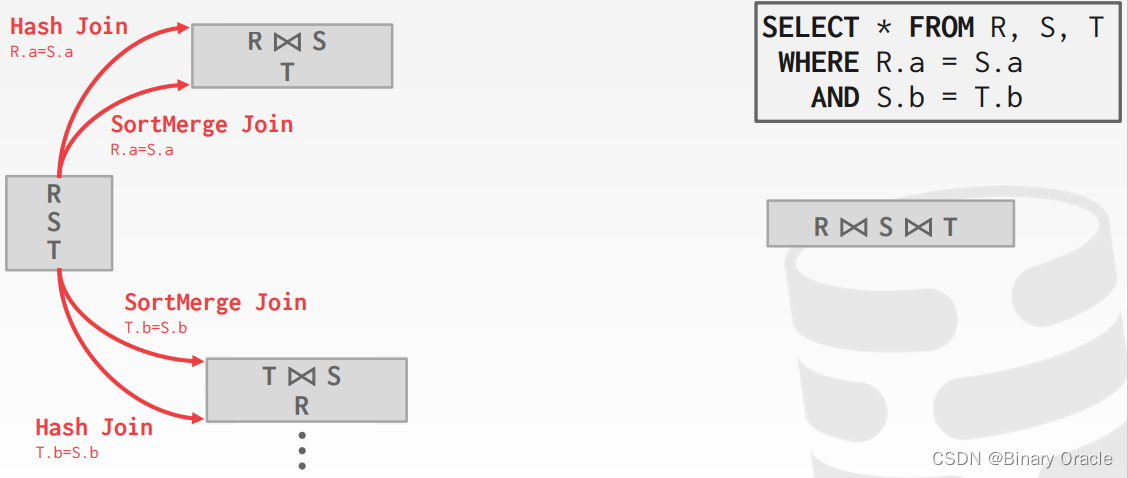

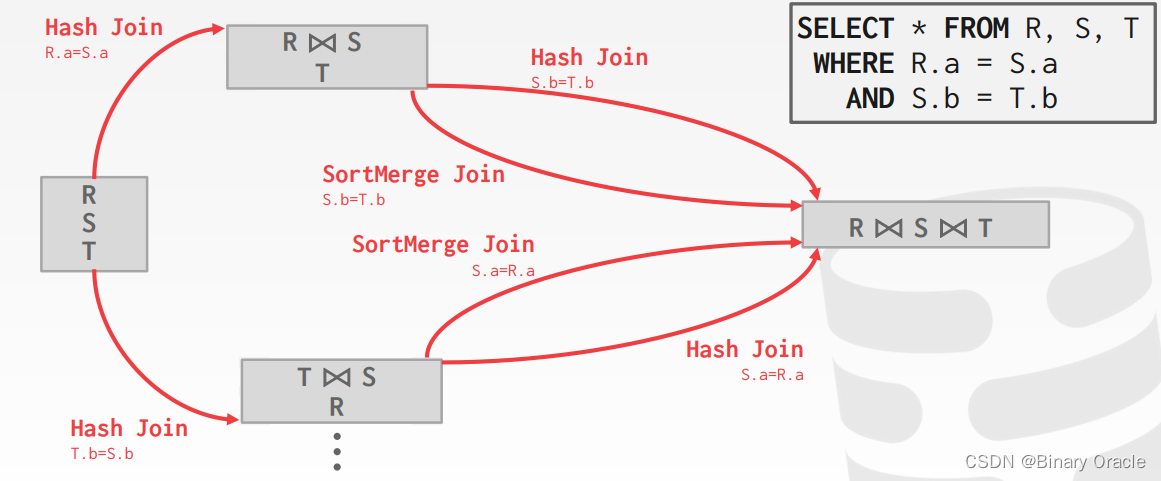
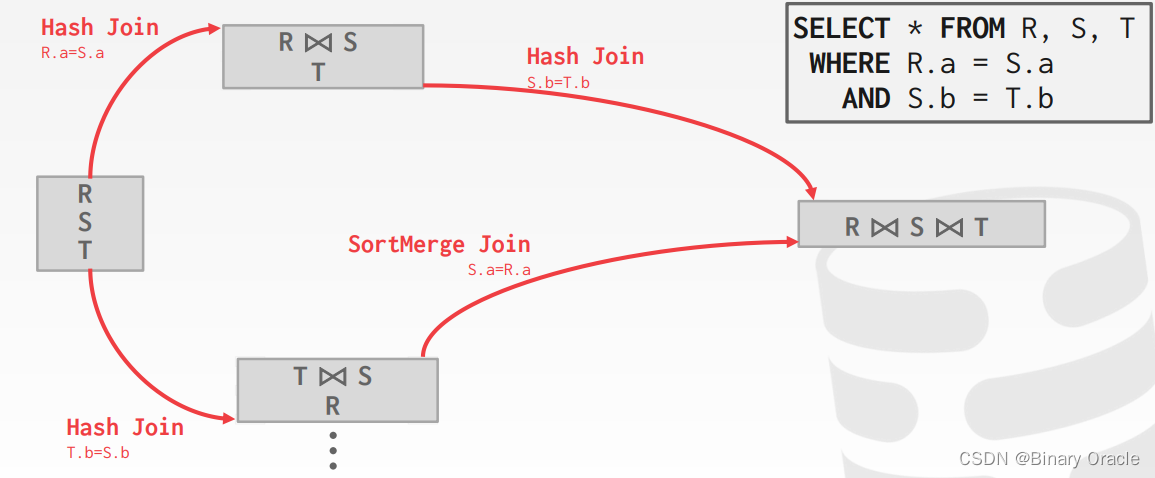
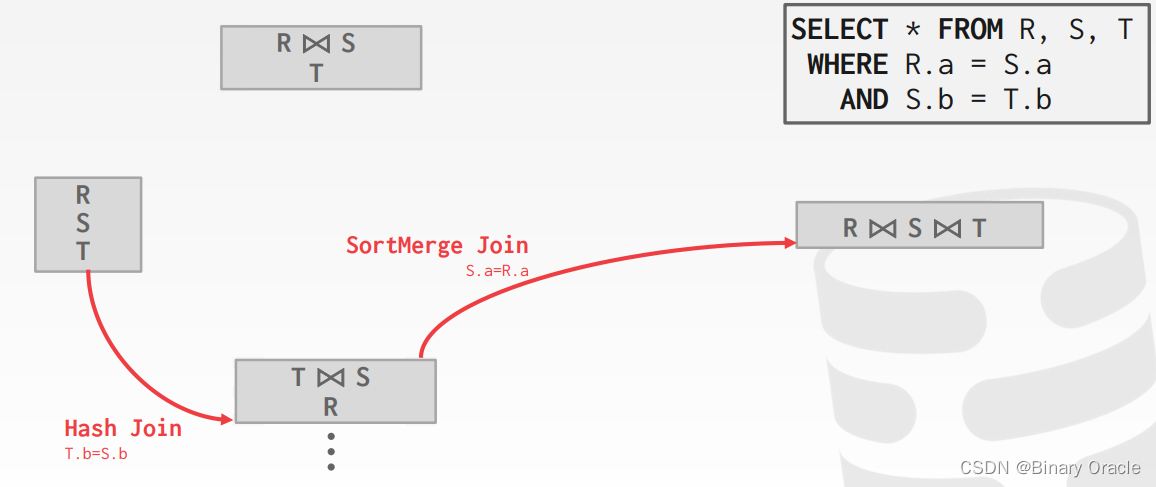
如何为查询生成执行计划
如何生成搜索算法的计划:
- 枚举关系顺序
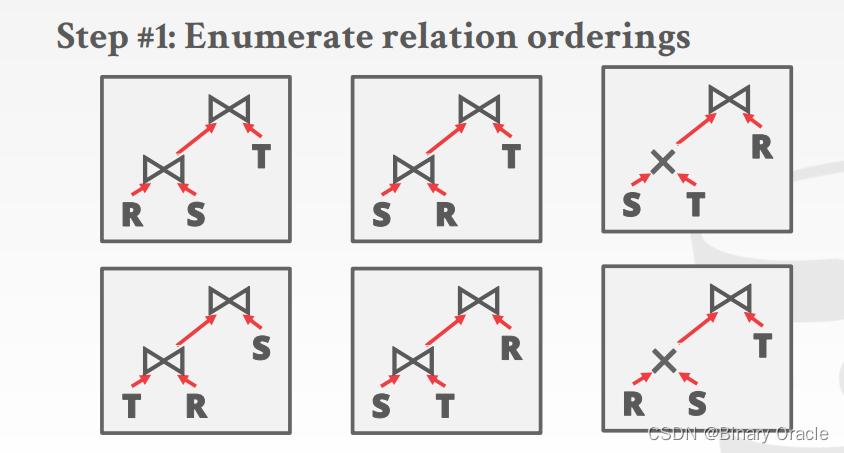
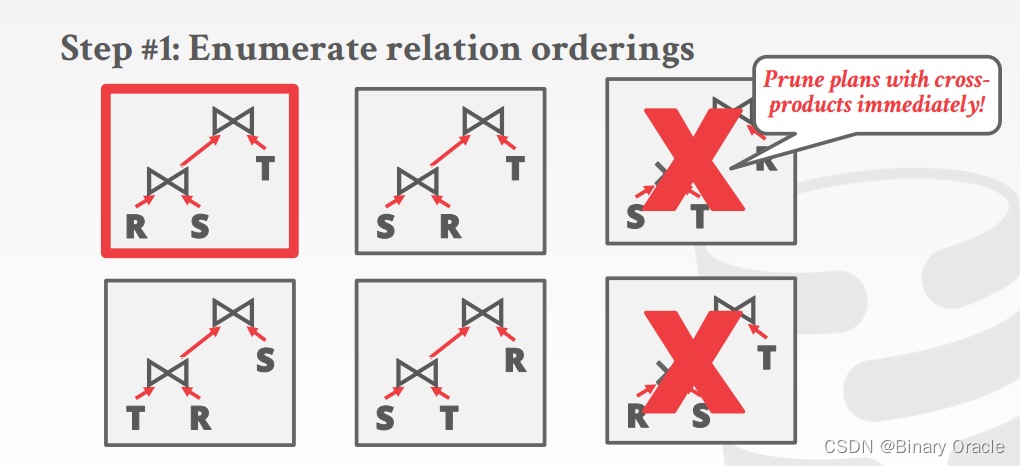
立即剪除包含交叉连接的计划!
- 枚举连接算法选择
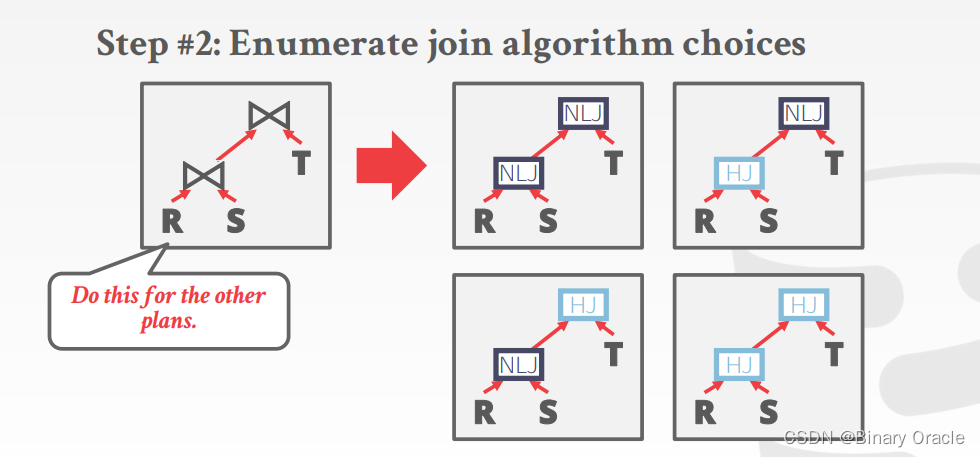
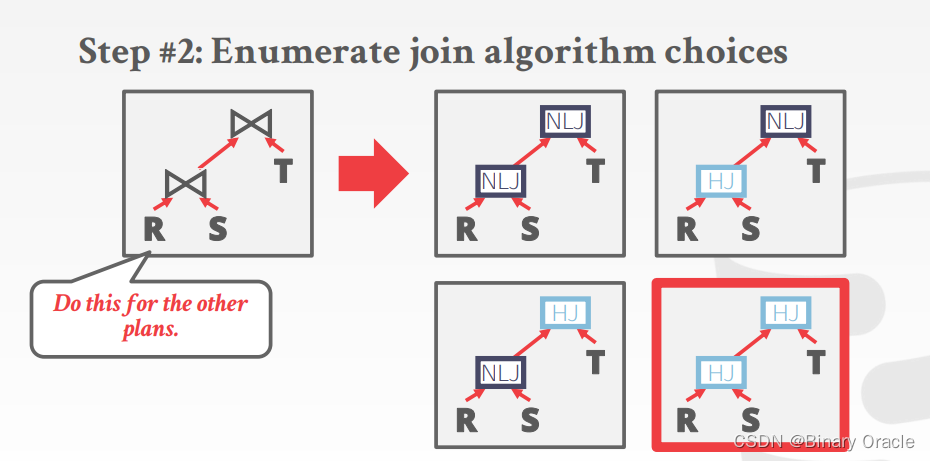
- 枚举访问方法选择
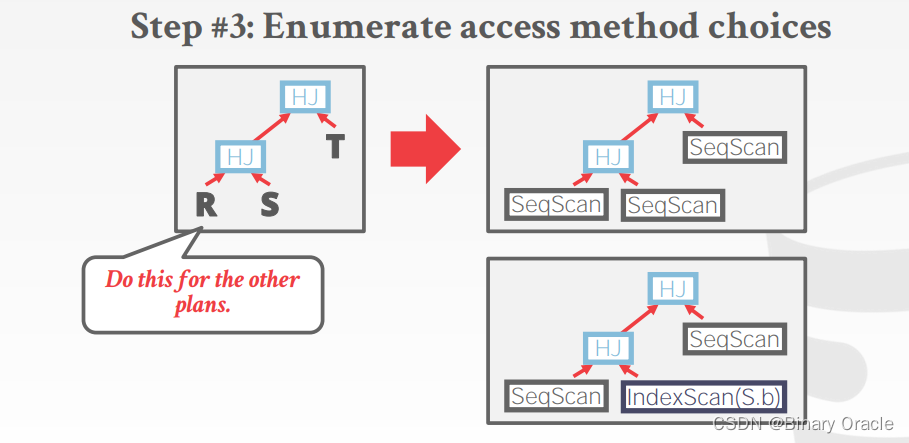
现实中的数据库管理系统并不按照这种方式进行计划生成。
实际情况更加复杂…
嵌套查询
数据库管理系统(DBMS)将嵌套子查询在WHERE子句中视为接受参数并返回单个值或一组值的函数。
有两种处理方式:
- 重写以去关联化和/或扁平化嵌套子查询
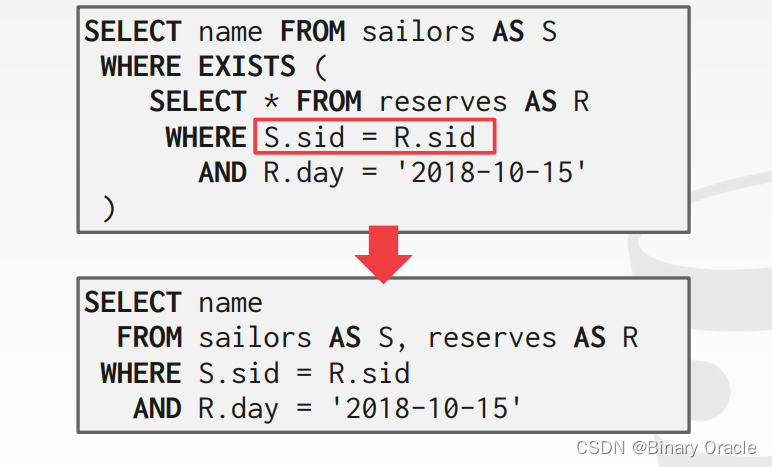
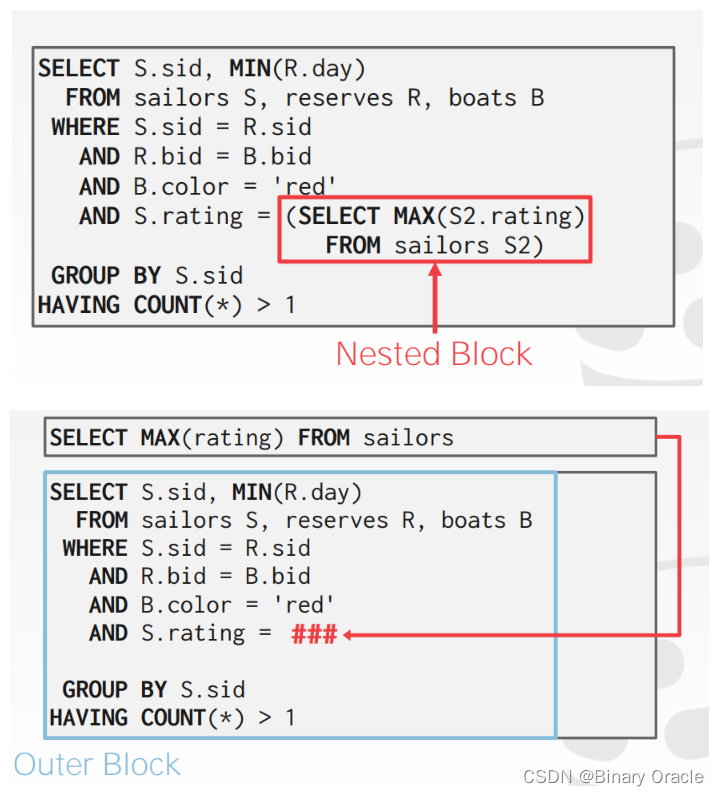
- 分解嵌套查询并将结果存储到临时表中

对于更复杂的查询,优化器将查询分解为多个块,并集中处理一个块。子查询被写入临时表中,在查询完成后临时表会被丢弃。
小结
查询优化确实是数据库管理系统中的一个具有挑战性的任务。为了实现高效的查询处理,采用了多种技术和策略。以下是其中一些技术:
- 尽早进行过滤:该策略涉及在查询执行过程中尽早应用过滤条件和谓词。通过在早期减少需要处理的行数,可以显著提高性能。
- 选择性估计:估计谓词的选择性有助于优化器确定查询的最佳执行计划。选择性指的是满足给定谓词的行的百分比。准确的选择性估计有助于选择最有效的连接顺序和访问方法。
- 均匀性:均匀性假设认为列内的数据分布是均匀的。该假设允许优化器根据数据的统计属性做出决策。
- 独立性:独立性假设认为查询中的谓词相互独立。该假设通过允许优化器单独估计选择性和评估谓词来简化优化过程。
- 直方图:直方图提供了列内数据分布的统计摘要,使优化器能够更准确地估计选择性。
- 连接选择性:连接选择性指的是连接操作产生的行数估计。它帮助优化器确定最有效的连接顺序和连接算法。
- 动态规划用于连接顺序:动态规划技术可用于探索和评估不同的连接顺序。这使得优化器能够基于成本估计找到最优的连接策略。
- 重写嵌套查询:有时可以将嵌套查询重写为更高效的等效形式。通过转换嵌套查询,优化器可以找到更好的执行计划。
查询优化是一个复杂且资源密集型的过程,涉及基于成本估计和数据的统计属性做出决策。数据库管理系统采用了各种技术来提高查询性能,但对于所有查询实现最佳性能是一项具有挑战性的任务。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-07-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号