开源六轴机械臂myCobot 280末端执行器实用案例解析
原创
开源六轴机械臂myCobot 280末端执行器实用案例解析
原创
大象机器人
发布于 2023-10-16 16:45:36
发布于 2023-10-16 16:45:36
Intrduction
大家好,今天这篇文章的主要内容是讲解以及使用一些myCobot 280 的配件,来了解这些末端执行器都能够完成哪些功能,从而帮助大家能够正确的选择一款适合的配件来进行使用。
本文中主要介绍4款常用的机械臂的末端执行器。
Product
myCobot 280 M5Stack
myCobot 280 系列是世界最小最轻的六轴协作机器人,体积小巧但功能强大,具备丰富的软硬件交互方式及多样化兼容拓展接口,支持多平台的二次开发,有效帮助用户实现多场景的应用。
主要适用于人工智能相关学科,个人创意开发,商业应用探索等场景。myCobot 280的驱动库支持二次开发,搭配拼图编程,代码编程,手动拖拽应用,机器人仿真编程等多种开发控制方式,给用户提供了多种控制方式的选择。

环境准备
机械臂:myCobot 280 M5stack
编程语言:Python,myBlockly
操作系统: windows 10/11
myCobot 自适应夹爪
myCobot自适应夹爪,适用于多款消费级机型产品,使用串口通讯控制,可以自动适应夹持物体的宽度,也可以控制夹爪开合的大小,提供多种编程语言控制接口。


python编程语言控制方式
from pymycobot.mycobot import Mycobot
mc = Mycobot('com3',115200)
#夹爪灵位校准
mc.set_gripper_calibration()
# 夹爪的打开和关闭
0 is close,1 is open;int speed : 1~100
mc.set_gripper_state(0/1,speed)
# 夹爪开合大小的控制
int degree:0~100;int speed : 1~100
mc.set_gripper_value(degree,speed)
Example:
mc.set_gripper_value(100,80)
time.sleep(1)
mc.set_gripper_value(50,80)
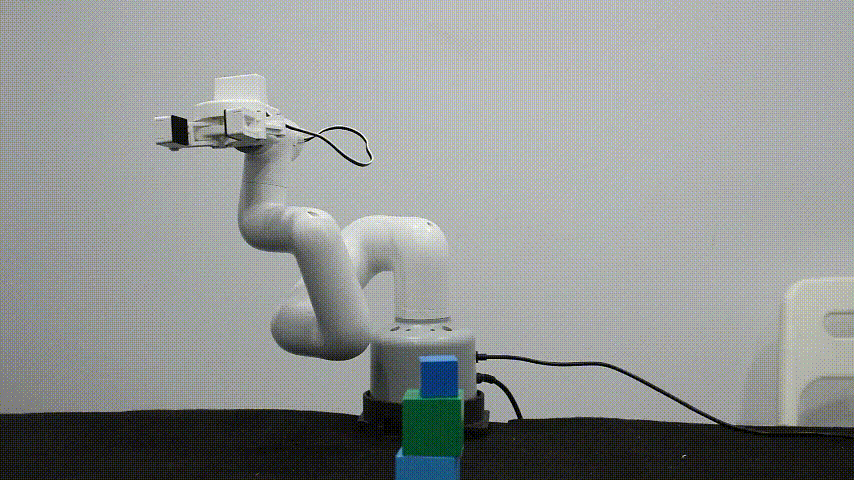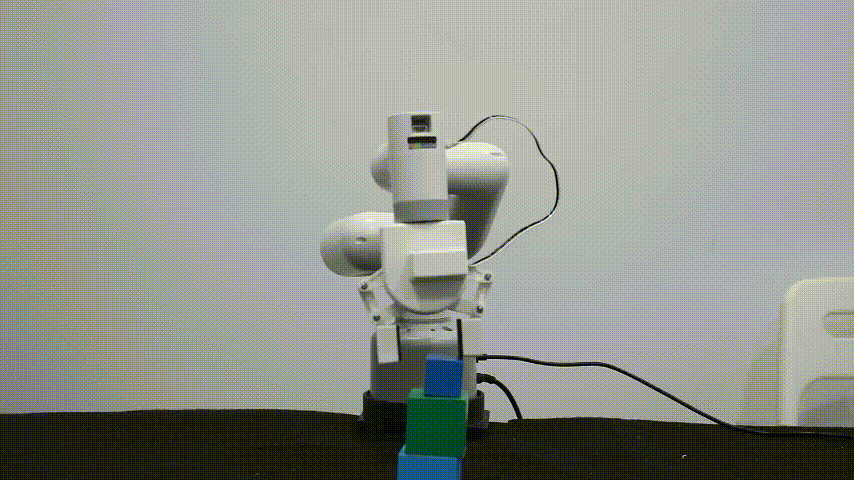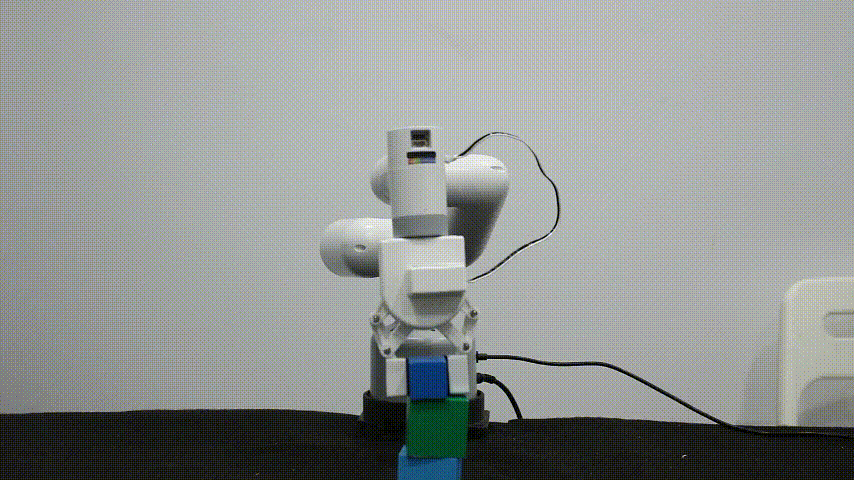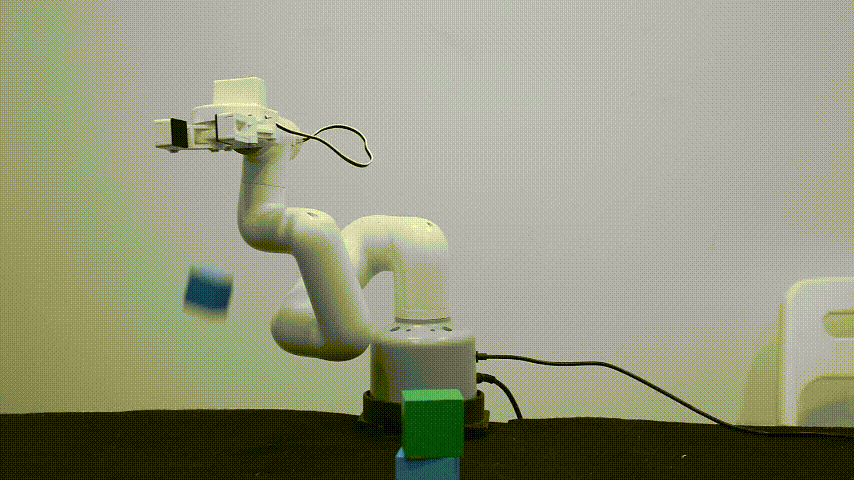
主要适用于以下场景:
待抓取物体在宽度在25~45mm之间
克重不能超过150g(机械臂最大的末端负载250g)
物体的材质尽量得足够坚硬,避免变形。
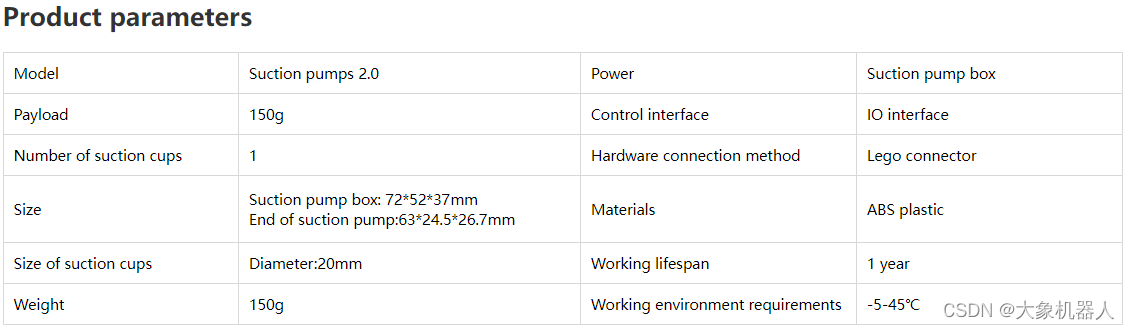
myCobot 垂直吸泵V2.0
myCobot垂直吸泵通过大气压的原理(真空吸附原理),当吸盘附着于物体表面,将吸盘内部的空气抽走,形成一个压力差就可以将物体牢牢吸住,当压力差越大吸附力就越强。提供标准3.3V IO控 制,可广泛搭载于各种嵌入式设备开发使用。

python编程语言的方式
from pymycobot.mycobot import Mycobot
mc = Mycobot('com3',115200)
#control Suction pump
IO port is the location where the suction pump is connected to the IO interface of the robot arm
state : 0 is open; 1 is close
mc.set_basic_output(IO port,state)
Example
#open the suction pump
mc.set_basic_output(5,0)
time.sleep(5)
# close the suction pump
mc.set_basic_output(5,1)
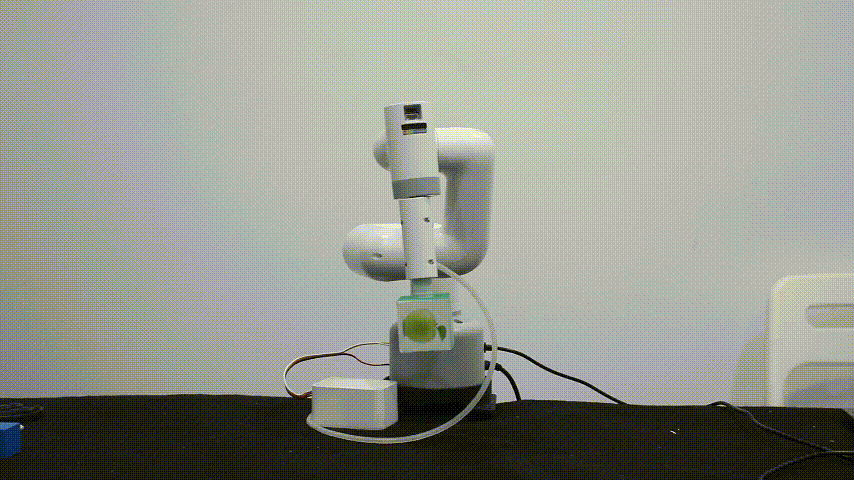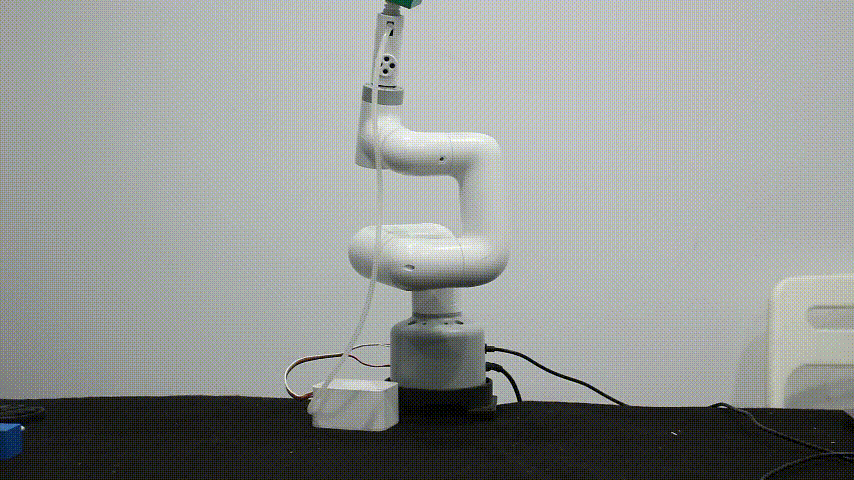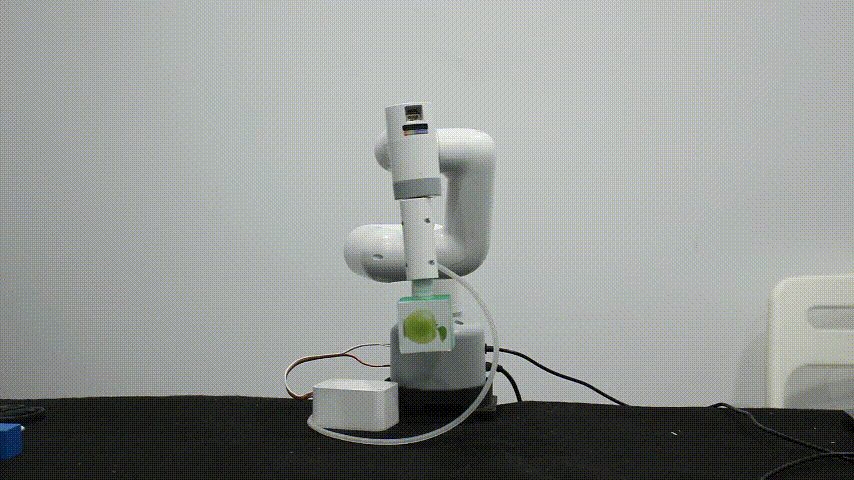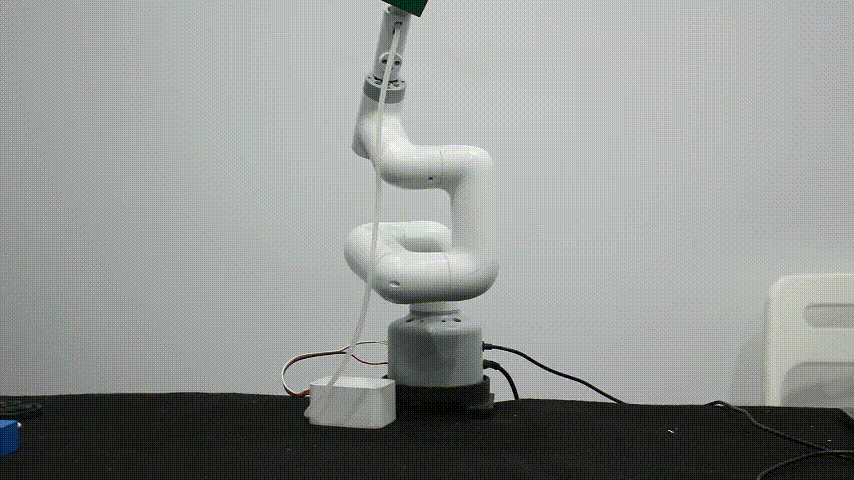
主要适用于以下物体:
物体的表面必须得是光滑的一个平面,凹凸不平的平面无法形成大气压强差的原理。
不建议吸取体积较大的物体,体积较大的物体会在机械臂运动的时候不一定能够保持稳定。
物体的重量不超过150g
接下来介绍另一款吸泵.
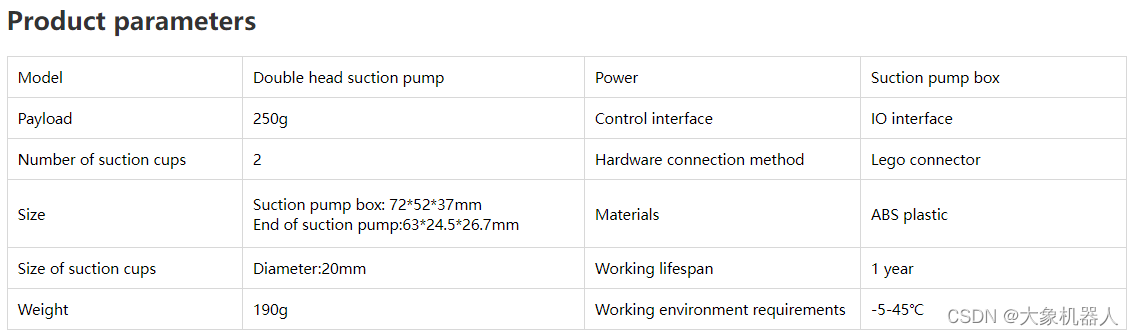
Double head suction pump
拥有两个吸泵吸头,由CNC金属件与光敏树脂构成,可以吸附体积较大的物体,双头吸泵的工作原理也跟垂直吸泵的工作原理一样,是制造大气压强差。提供标准3.3V IO控 制,可广泛搭载于各种嵌入式设备开发使用。

双头吸泵的控制方式和垂直吸泵的控制方式一样。
python编程语言的方式
from pymycobot.mycobot import Mycobot
mc = Mycobot('com3',115200)
#control Suction pump
IO port is the location where the suction pump is connected to the IO interface of the robot arm
state : 0 is open; 1 is close
mc.set_basic_output(IO port,state)
Example
#open the suction pump
mc.set_basic_output(5,0)
time.sleep(5)
# close the suction pump
mc.set_basic_output(5,1)

主要适用于一下物体:
物体的表面必须得是光滑的一个平面,凹凸不平的平面无法形成大气压强差的原理。
物体克重不建议超过150g,机械臂末端的负载最大负荷是250g
适用于物体表面积较大的,因为双头吸泵的设计适合吸取较大的物体。
吸头越多所造成的压强差就越大,所以它能够吸附的更稳定
Dexterous hand
Dexterous hand是一款新的末端执行器是模仿人类的手掌进行仿生,来实现物体的抓取,拿放等功能,主要是通过IO控制,电力控制的方式。目前这款末端执行器还在开发当中本次文中算是初步给它露个面给大家看。



主要适用于以下场景:
该灵巧手主要是对一些不规则物体的抓放。
抓取的物体的重量需要控制在100g以内。
物体的宽度控制在25mm-45mm之间。
Summary
在这篇文章中,我向大家介绍了四款出色的机械臂末端执行器。通过深入探索每一款执行器的功能和特点,我们可以看到它们在不同的应用领域中的独特优势。你在选择机械臂末端执行器的时候需要思考使用怎样的末端执行器能够满足场景的需求,做一些简单的搬运,还是想做一些酷炫的动作。
如果你们还有想要了解的末端执行器欢迎在文章的下方评论留言。你的评论和点赞是对我们最大的支持!我们下次再见。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号