Spark


Spark是Scala语言实现的核心数据结构是RDD的基于内存迭代计算的分布式框架。
1 Spark作业提交流程
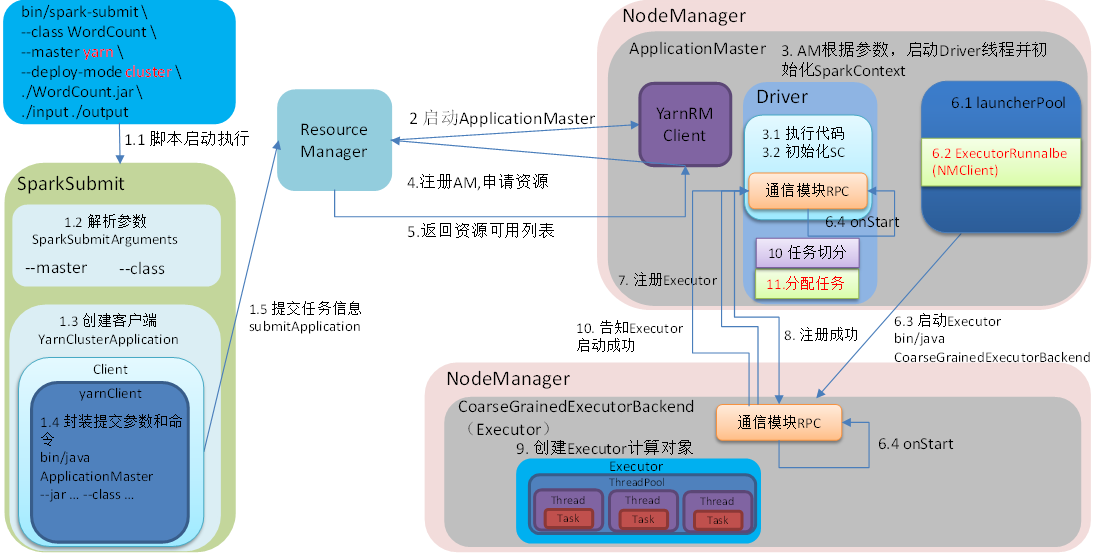
1)客户端client向ResouceManager提交Application,ResouceManager接受Application并根据集群资源状况选取一个node来启动Application的任务调度器driver(ApplicationMaster)
2)ResouceManager找到那个node,命令其该node上的nodeManager来启动一个新的JVM进程运行程序的driver(ApplicationMaster)部分,driver(ApplicationMaster)启动时会首先向ResourceManager注册,说明由自己来负责当前程序的运行。
3)driver(ApplicationMaster)开始下载相关jar包等各种资源,基于下载的jar等信息决定向ResourceManager申请具体的资源内容。
4)ResouceManager接受到driver(ApplicationMaster)提出的申请后,会最大化的满足资源分配请求,并发送资源的元数据信息给driver(ApplicationMaster);
5)driver(ApplicationMaster)收到发过来的资源元数据信息后会根据元数据信息发指令给具体机器上的NodeManager,让其启动具体的container。
6)NodeManager收到driver发来的指令,启动container,container启动后必须向driver(ApplicationMaster)注册。
7)driver(ApplicationMaster)收到container的注册,开始进行任务的调度和计算,直到任务完成。
补充:如果ResourceManager第一次没有能够满足driver(ApplicationMaster)的资源请求,后续发现有空闲的资源,会主动向driver(ApplicationMaster)发送可用资源的元数据信息以提供更多的资源用于当前程序的运行。
ApplicationMaster负责销毁使用完之后的Container。
spark on yarn Cluster 模式下,driver 位于ApplicationMaster进程中,该进程负责申请资源,还负责监控程序、资源的动态情况。
Master:
管理集群和节点,不参与计算。
Driver:
一个Spark作业运行时包括一个Driver进程,也是作业的主进程,具有main函数,并且有SparkContext的实例,是程序的入口点。
负责向集群申请资源,向master注册信息,负责了作业的调度,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
SparkContext:
控制整个application的生命周期,包括dagsheduler和task scheduler等组件。
Woker:
主要功能:管理当前节点内存,CPU的使用状况,接收master分配过来的资源指令,通过ExecutorRunner启动程序分配任务,worker就类似于包工头,管理分配新进程,做计算的服务,相当于process服务。
需要注意的是:
1)worker会不会汇报当前信息给master,worker心跳给master主要只有workid,它不会发送资源信息以心跳的方式给mater,master分配的时候就知道work,只有出现故障的时候才会发送资源。
2)worker不会运行代码,具体运行的是Executor是可以运行具体appliaction写的业务逻辑代码,操作代码的节点,它不会运行程序的代码的。
Container:
1)Container作为资源分配和调度的基本单位,其中封装了的资源如内存,CPU,磁盘,网络带宽等。 目前yarn仅仅封装内存和CPU
2)Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster
3)Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令.
2 Spark提交作业参数
1)在提交任务时的几个重要参数
executor-cores —— 每个executor使用的内核数,默认为1,官方建议2-5个
num-executors —— 启动executors的数量,默认为2
executor-memory —— executor内存大小,默认1G
driver-cores —— driver使用内核数,默认为1
driver-memory —— driver内存大小,默认512M
2)边给一个提交任务的样式
spark-submit \
--master local[5] \
--driver-cores 2 \
--driver-memory 8g \
--executor-cores 4 \
--num-executors 10 \
--executor-memory 8g \
--class PackageName.ClassName XXXX.jar \
--name "Spark Job Name" \
InputPath \
OutputPath3 RDD机制
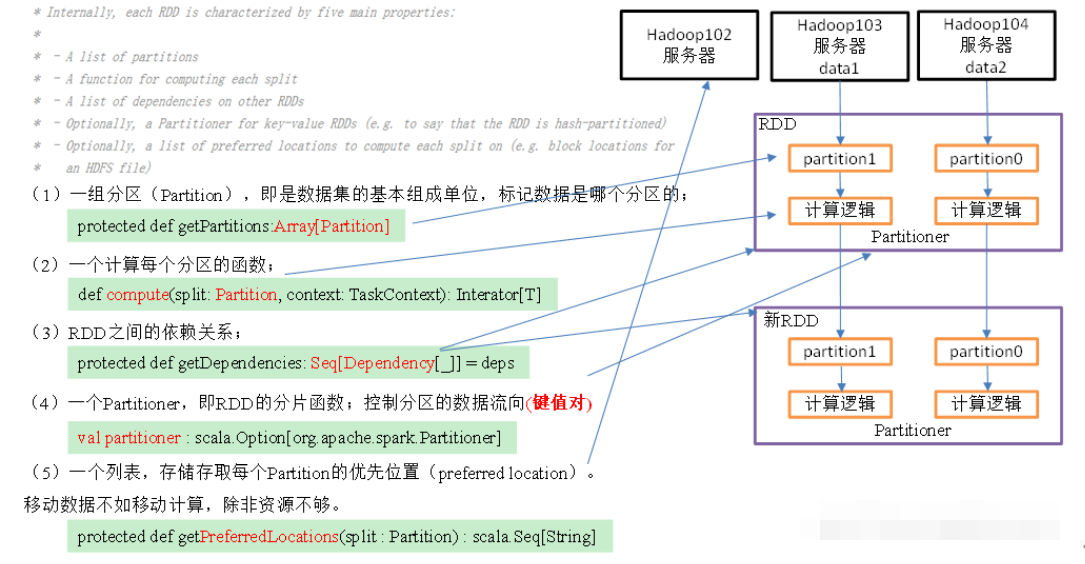
1. rdd分布式弹性数据集,简单的理解成⼀种数据结构,是spark框架上的通⽤货币。 所有算⼦都是基于rdd来执⾏的,不同的场景会有不同的rdd实现类,但是都可以进⾏互相转换。 rdd执⾏过程中会形成dag图,然后形成lineage血缘关系保证容错性等。 从物理的⾓度来看rdd存储的是block和node之间的映射。
2. RDD是spark提供的核⼼抽象,全称为弹性分布式数据集。
3. RDD在逻辑上是⼀个hdfs⽂件,在抽象上是⼀种元素集合,包含了数据。它是被分区的,**分为多个分区**,每个分区分布在集群中的不同结点上,从⽽让RDD中的数据可以被**并⾏操作**(分布式数据集) ⽐如有个RDD有90W数据, 3个partition,则每个分区上有30W数据。 RDD通常通过Hadoop上的⽂件,即HDFS或者HIVE表来创建,还可以通过应⽤程序中的集合来创建;
4. RDD最重要的特性就是容错性,可以⾃动从节点失败中恢复过来。即如果某个结点上的RDD partition因为节点故障,导致数据丢失,那么RDD可以通过⾃⼰的数据来源重新计算该partition。这⼀切对使⽤者都是透明的RDD的数据默认存放在内存中,但是当内存资源不⾜时, spark会⾃动将RDD数据写⼊磁盘。⽐如某结点内存只能处理20W数据,那么这20W数据就会放⼊内存中计算,剩下10W放到磁盘中。 RDD的弹性体现在于RDD上⾃动进⾏内存和磁盘之间权衡和切换的机制。
4 算子
4.1 Transformation
transformation 算子: 返回一个新的RDD;
所有Transformation函数都是Lazy,不会立即执行,需要Action函数触发;
1)单Value
(1)map
(2)mapPartitions
(3)mapPartitionsWithIndex
(4)flatMap
(5)glom
(6)groupBy
(7)filter
(8)sample
(9)distinct
(10)coalesce
(11)repartition
(12)sortBy
(13)pipe2)双vlaue
(1)intersection
(2)union
(3)subtract
(4)zip3)Key-Value
(1)partitionBy
(2)reduceByKey
(3)groupByKey
(4)aggregateByKey
(5)foldByKey
(6)combineByKey
(7)sortByKey
(8)mapValues
(9)join
(10)cogroup4.2 Action
Action:返回值不是RDD(无返回值或返回其他的)
可以在Action时对RDD操作形成DAG有向无环图进行Stage的划分和并行优化,这种设计让Spark更加有效率地运行。
(1)reduce
(2)collect
(3)count
(4)first
(5)take
(6)takeOrdered
(7)aggregate
(8)fold
(9)countByKey
(10)save
(11)foreach
(12)foreachPartition4.3 map和mapPartitions区别
1)map:每次处理一条数据
2)mapPartitions:每次处理一个分区数据
4.4 Repartition和Coalesce区别
1)关系:
两者都是用来改变RDD的partition数量的
repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
2)区别:
repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle
一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce
4.5 reduceByKey与groupByKey的区别
reduceByKey:具有预聚合操作
groupByKey:没有预聚合
在不影响业务逻辑的前提下,优先采用reduceByKey。
4.6 reduceByKey、foldByKey、aggregateByKey、combineByKey区别
ReduceByKey | 没有初始值 | 分区内和分区间逻辑相同 |
|---|---|---|
foldByKey | 有初始值 | 分区内和分区间逻辑相同 |
aggregateByKey | 有初始值 | 分区内和分区间逻辑可以不同 |
combineByKey | 初始值可以变化结构 | 分区内和分区间逻辑不同 |
4.7 获取RDD分区数目两种方式
rdd.getNumPartitions();
rdd.partitions.length;
5 Spark任务的划分
(1)Application:初始化一个SparkContext即生成一个Application;
(2)Job:一个Action算子就会生成一个Job;
(3)Stage:Stage等于宽依赖的个数加1;
(4)Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。Spark中的Task有2种类型:
① result task类型,最后一个task;
② shuffleMapTask类型,除了最后一个task都是此类型;
6 RDD持久化
spark 非常重要的一个功能特性就是可以将 RDD 持久化在内存中。调用 cache()和 persist()方法即可。
cache后面接了其它算子之后起不到缓存应有的效果,因为会重新触发cache。
cache()和 persist()的区别在于, cache()是 persist()的一种简化方式, cache()的底层就是调用 persist()的无参版本persist(MEMORY_ONLY), 将数据持久化到内存中。如果需要从内存中清除缓存, 可以使用 unpersist()方法。 RDD 持久化是可以手动选择不同的策略的。 在调用 persist()时传入对应的 StorageLevel 即可。
(1)MEMORY_ONLY:以⾮序列化的Java对象的⽅式持久化在JVM内存中。如果内存⽆法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下⼀次需要使⽤它的时候,被重新计算。
(2)MEMORY_AND_DISK:同上,但是当某些partition⽆法存储在内存中时,会持久化到磁盘中。下次需要使⽤这些partition时,需要从磁盘上读取。
(3)MEMORY_ONLY_SER:同MEMORY_ONLY,但是会使⽤Java序列化⽅式,将Java对象序列化后进⾏持久化。可以减少内存开销,但是需要进⾏反序列化,因此会加⼤CPU开销。
(4)MEMORY_AND_DSK_SER:同MEMORY_AND_DSK,但是使⽤序列化⽅式持久化Java对象。
(5)DISK_ONLY:使⽤⾮序列化Java对象的⽅式持久化,完全存储到磁盘上。
(6)MEMORY_ONLY_2/MEMERY_AND_DISK_2:如果是尾部加了2的持久化级别,表⽰会将持久化数据复⽤⼀份,保存到其他节点,从⽽在数据丢失时,不需要再次计算,只需要使⽤备份数据即可
DataFrame的cache默认采用 MEMORY_AND_DISK
RDD 的cache默认方式采用MEMORY_ONLY
//缓存
(1)dataFrame.cache
(2)sparkSession.catalog.cacheTable(“tableName”)
//释放缓存
(1)dataFrame.unpersist
(2)sparkSession.catalog.uncacheTable(“tableName”)7 Cache和CheckPoint
7.1 CheckPoint
当spark应⽤程序特别复杂,从初始的RDD开始到最后整个应⽤程序完成有很多的步骤,⽽且整个应⽤运⾏时间特别长,这种情况下就⽐较适合使⽤checkpoint功能。对于特别复杂的Spark应⽤,会出现某个反复使⽤的RDD,即使之前持久化过但由于节点的故障导致数据丢失了,没有容错机制,所以需要重新计算⼀次数据。
Checkpoint 首先会调用 SparkContext 的 setCheckPointDIR()方法, 设置一个容错的文件系统的目录, 比如说 HDFS;然后对 RDD 调用 checkpoint()方法。之后在 RDD 所处的 job 运行结束之后, 会启动一个单独的 job, 来将checkpoint 过的 RDD 数据写入之前设置的文件系统, 进行高可用、 容错的类持久化操作。
检查点机制是我们在 spark streaming 中用来保障容错性的主要机制, 它可以使 spark streaming 阶段性的把应用数据存储到诸如 HDFS 等可靠存储系统中,以供恢复时使用。 具体来说基于以下两个目的服务:
1. 控制发生失败时需要重算的状态数。 Spark streaming 可以通过转化图的谱系图来重算状态, 检查点机制则可以控制需要在转化图中回溯多远。
2. 提供驱动器程序容错。 如果流计算应用中的驱动器程序崩溃了, 你可以重启驱动器程序并让驱动器程序从检查点恢复, 这样 spark streaming 就可以读取之前运行的程序处理数据的进度, 并从那里继续。
7.2 Cache和CheckPoint区别
1)Cache只是将数据保存在 BlockManager 中, 但是 RDD 的lineage(血缘关系, 依赖关系)是不变的。但是 checkpoint 执行完之后, rdd 已经没有之前所谓的依赖 rdd 了, 而只有一个强行为其设置的 checkpointRDD,checkpoint 之后 rdd 的 lineage 就改变了。
2)Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高。
3)建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
8 累加器
Spark累加器(Accumulators)是一种分布式计算中常用的数据聚合工具。它们提供了一种在并行处理中安全地进行计数器和求和等操作的方法。
Spark累加器分为两类:标准累加器和自定义累加器。
标准累加器是 Spark 提供的内置累加器,支持在分布式环境下对整数和浮点数进行累加操作。用户可以在任务中对累加器进行累加操作,然后在驱动器程序中读取累加器的值。
自定义累加器允许用户通过继承AccumulatorV2类来创建自定义的累加器。这使得用户可以支持更复杂的累加器操作,如列表累加器或自定义对象累加器。
累加器在 Spark 内部使用了一些技巧来确保正确性和高性能。例如,累加器只能通过驱动程序中的任务访问,而不能通过并行任务之间的共享变量访问,因此它们天然地是线程安全的。此外,Spark还会在内部使用有序序列化来确保累加器的正确性。
以下是一个使用标准累加器的简单示例:
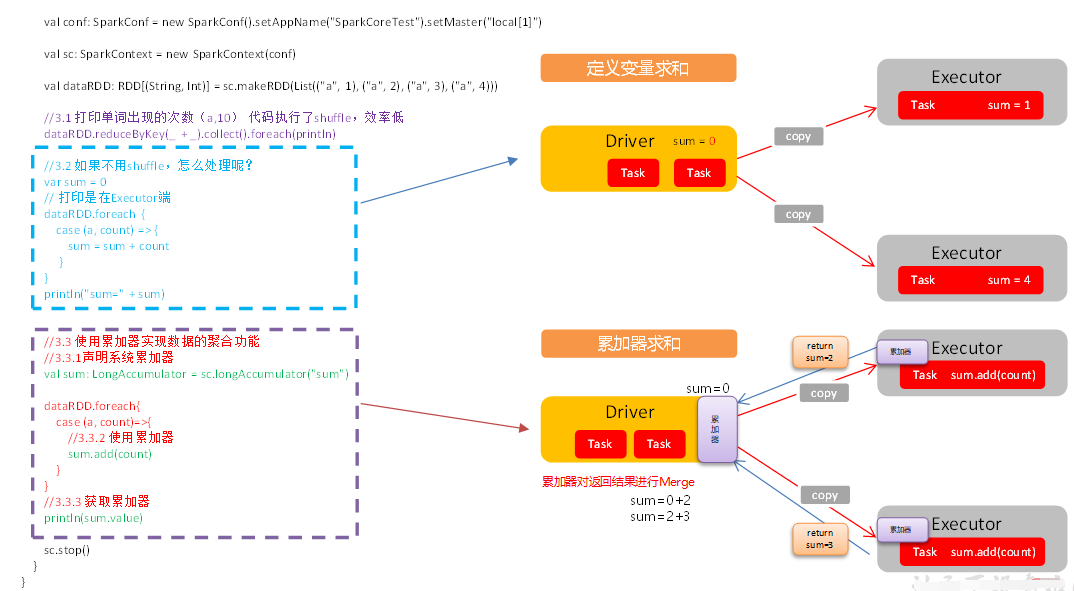
Spark累加器特点:
① 累加器在全局唯一的,只增不减,记录全局集群的唯一状态;
② 在executor中修改它,在driver读取;
③ executor级别共享的,广播变量是task级别的共享,两个application不可以共享累加器,但是同一个app不同的job可以共享。
④ 分布式计算:累加器在分布式计算中被广泛使用,可以在不同节点的计算任务中共享数据。
⑤ 只支持数值类型:Spark累加器只支持数值类型,包括整数、浮点数、长整型等等,不支持其他类型,比如字符串、布尔型等等。
⑥ 只能进行加法操作:Spark累加器只支持加法操作,不能进行其他运算操作,比如减法、乘法、除法等等。
⑦ 惰性求值:累加器的值只在Spark作业执行完成后才能得到,这是因为Spark的计算是惰性求值的。
⑧ 只能在Driver端读取:累加器的值只能在Driver端读取,不能在Executor端读取。
定义累计器之后执行累加,只有触发Action操作才能够得到结果; 如果在触发action之后,又一次触发action会发生什么现象?
累加器会多次累加;
解决方法:
使用Accumulator时,为了保证准确性,只使用一次action操作。
如果需要使用多次则使用cache或persist操作切断依赖。
9 广播变量
Spark 广播变量是一种在集群中缓存只读变量的机制,可以有效地减少数据的传输量,提高作业执行的效率。广播变量是 Spark 提供的一种只读共享变量,可以通过将变量的值广播到集群的每个节点,让每个节点都可以访问到该变量的值。 广播变量在一些分布式算法中非常有用,例如机器学习中的特征映射。
广播变量的特点包括:
只读:广播变量是只读的,不能在作业运行过程中修改变量的值。
分布式缓存:广播变量会被序列化后缓存在 Executor 的内存中,可以在 Executor 上进行反序列化,而不需要重新传输数据。
高效性:广播变量是为了减少数据的传输量,所以对于大规模数据的分布式环境中,广播变量的效率是非常高的。
使用广播变量可以避免在每个节点上都进行重复的计算,从而提高了程序的性能。
示例:

10 RDD、DataFrame、DataSet三者的转换
在Spark中,RDD、DataFrame和DataSet都是用来表示数据集的抽象。它们之间的主要区别在于它们的数据类型和执行计划。
RDD(Resilient Distributed Dataset)是一个不可变的分布式数据集合。RDD中的数据被分成一系列分区,每个分区可以在集群的不同节点上进行处理。 RDD可以通过transformations(如map、filter、groupByKey等)进行转换,最终进行actions(如count、collect等)来获取结果。RDD需要在运行时动态构建执行计划。
DataFrame是一个分布式的、带有命名的列的数据集合。 它是基于RDD的概念进行了优化,是一种更高层次的抽象,可以看做是RDD的一种特殊情况。DataFrame的优点是:支持自动的优化(如列存储、压缩、谓词下推等)、支持SQL查询和DataFrame API查询、易于使用、性能优秀。 DataFrame可以通过Spark SQL中的API进行操作,可以使用SQL语句进行查询。
DataSet是Spark 1.6版本中引入的新概念,是一种强类型的分布式数据集合。DataSet具有RDD和DataFrame的优点,它支持编译时类型安全性检查、支持Spark SQL的自动优化,同时又支持DataFrame的简洁性和优化。与DataFrame不同的是,DataSet支持编译时类型检查和更丰富的操作符,同时也支持Spark SQL中的API和SQL语句进行查询。
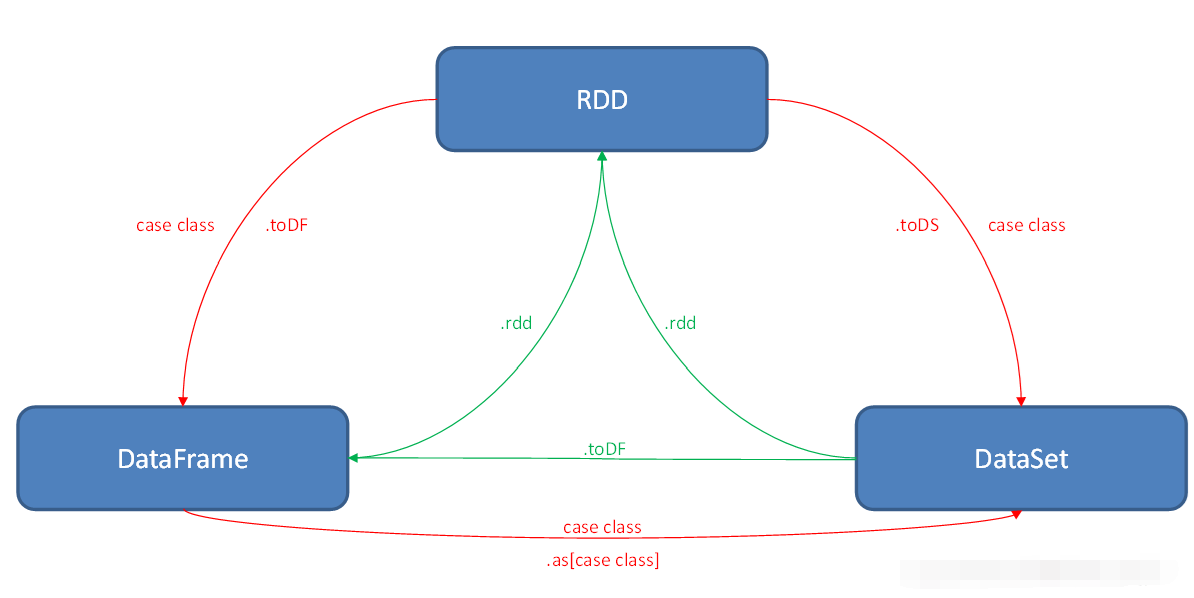
在Spark中,RDD、DataFrame和DataSet之间可以进行相互转换。其中,RDD可以通过SparkSession的createDataFrame方法转换为DataFrame;DataFrame和DataSet之间可以通过as方法进行转换,而DataFrame和RDD之间可以通过toDF和rdd方法进行转换。
11 Spark Streaming消费Kafka数据
11.1 Spark Streaming第一次运行不丢失数据
kafka参数 auto.offset.reset 设置成earliest 从最初始偏移量开始消费数据
11.2 Spark Streaming精准一次消费Kafka
在 Spark Streaming 中,可以通过使用 Direct 的方式来实现精准一次消费 Kafka 中的数据。其主要思路是在消费数据的时候,手动维护每个分区的消费偏移量,通过定时提交这些偏移量,来确保每个分区的数据只会被消费一次。
具体实现步骤如下:
① 创建一个 Kafka 消费者,并设置消费者的配置信息,包括 Kafka broker 地址、消费组名、反序列化类等等。
② 从 Kafka 中读取数据,并将每个分区的数据转换为 RDD 或 DataFrame。
③ 在处理数据时,将每个分区的消费偏移量保存下来,并在处理完每个批次后,手动提交这些偏移量。
④ 在消费数据时,通过设置参数 enable.auto.commit 为 false,禁止自动提交偏移量,以避免可能的数据重复消费。
具体代码实现可以参考以下示例:
import org.apache.kafka.common.TopicPartition
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
// 设置 Kafka 相关配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group1",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// 创建 Kafka 消费者
val consumer = new KafkaConsumer[String, String](kafkaParams)
// 订阅 Kafka 主题
consumer.subscribe(Arrays.asList("topic1"))
// 从 Kafka 中读取数据
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Array("topic1"), kafkaParams)
)
// 处理数据
stream.foreachRDD(rdd => {
// 获取每个分区的偏移量
val offsets = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// 对每个分区的数据进行处理
rdd.foreachPartition(partition => {
// 处理分区内的数据
// 手动提交偏移量
val offsetRanges = offsets.filter(_.partition == taskContext.partitionId())
val o: OffsetRange = offsetRanges(0)
val topicPartition = new TopicPartition(o.topic, o.partition)
consumer.commitSync(Map(topicPartition -> new OffsetAndMetadata(o.untilOffset)).asJava)
})
})需要注意的是,在使用精准一次消费的方式时,要确保程序在处理完每个批次后,及时提交偏移量,否则可能会出现数据重复消费的情况。另外,对于一些无法重复消费的场景,也可以考虑使用 Kafka 的事务机制来实现精准一次消费。
11.3 Spark Streaming控制每秒消费数据的速度
在 Spark Streaming 中使用 Kafka 直接消费数据时,可以通过参数 spark.streaming.kafka.maxRatePerPartition 来指定每个分区每秒钟接收的最大数据量,从而控制消费的速率。这个参数`默认值是 Long.MaxValue,即每秒钟接收最大值是 Long 类型的最大值,即无限制。
11.4 Spark Streaming背压机制
Spark Streaming中的背压机制是一种控制数据流量的机制,它可以根据系统当前的处理能力来动态地调整数据的输入速率,以避免数据积压导致的性能下降或者系统崩溃。 在Spark Streaming中,背压机制主要应用于Receiver-based方式,即基于接收器的方式,因为它是一种主动拉取数据的方式,而Direct方式是基于Spark executor的方式,不需要使用背压机制。
背压机制是通过Spark Streaming的ReceiverTracker组件实现的,它会动态地调整Receiver的接收速率,使其与系统的处理能力保持匹配。具体来说,ReceiverTracker会检测数据接收器的接收速率、缓存大小和数据处理速度,根据这些信息动态地调整接收速率,使其与系统的处理能力保持平衡。
使用背压机制可以有效地避免数据积压导致的系统性能下降或者系统崩溃。但是,在使用背压机制时需要注意以下几点:
启用背压机制会增加系统开销,降低系统处理能力,因此需要在必要时才使用。
背压机制是基于接收器的方式实现的,因此仅适用于Receiver-based方式,对于Direct方式是无效的。
背压机制需要在SparkConf中设置,具体设置方法如下:
val conf = new SparkConf().set("spark.streaming.backpressure.enabled", "true")在启用背压机制后,还需要设置背压阈值,即最大可接受的数据接收速率。可以使用以下两种方式进行设置:
在SparkConf中设置:
val conf = new SparkConf().set("spark.streaming.backpressure.initialRate", "1000")在DStream的ReceiverInputDStream中设置:
val stream = KafkaUtils.createStream(ssc, zkQuorum, group, topic, Map(topic -> 1), StorageLevel.MEMORY_ONLY_SER).repartition(5).map(_._2)
stream.foreachRDD((rdd, time) => {
rdd.sparkContext.setLocalProperty("spark.streaming.backpressure.initialRate", "1000")
...
})其中,背压阈值的单位是每秒接收的记录数。
综上所述,背压机制是Spark Streaming中一种重要的数据流控制机制,可以避免数据积压导致的系统性能下降或者系统崩溃。但是,在使用背压机制时需要注意启用时会增加系统开销,仅适用于Receiver-based方式,需要设置背压阈值。
11.5 Spark Streaming消费Kafka数据默认分区个数
在基于Receiver的方式中,每个Kafka Partition都由一个Receiver负责接收并处理。每个Receiver都会启动一个Task进行数据接收,并且每个Task都会创建一个RDD Partition,因此,Kafka的Partition数量就决定了创建的RDD Partition数量。如果Kafka的Partition数量很少,就会出现Task过少的情况,这样会影响Spark Streaming的并发度,导致性能瓶颈。因此,在使用基于Receiver的方式时,需要设置合适的Receiver数量和Executor数量,以保证处理Kafka数据的高并发度和高吞吐量。
需要注意的是,基于Direct方式消费Kafka数据时,Kafka Partition和RDD Partition没有直接关系,因为Direct方式会将Kafka Partition映射为RDD的分区,因此Spark Streaming使用Direct方式消费Kafka数据时,可以通过调整RDD分区数来控制并发度。
11.6 SparkStreaming有哪几种方式消费Kafka中的数据?它们之间的区别是什么?
一、基于Receiver的方式
这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的(如果突然数据暴增,大量batch堆积,很容易出现内存溢出的问题),然后Spark Streaming启动的job会去处理那些数据。
然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
二、基于Direct的方式
这种新的不基于Receiver的直接方式,是在Spark 1.3中引入的,从而能够确保更加健壮的机制。替代掉使用Receiver来接收数据后,这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
优点如下:
简化并行读取:如果要读取多个partition,不需要创建多个输入DStream然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
高性能:如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复制一份到WAL中。而基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。
一次且仅一次的事务机制。
三、对比:
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
在实际生产环境中大都用Direct方式
11.7 基于receiver的方式Kafka的Partition与Spark中RDD的Partition有关系吗?
Kafka的Partition与Spark中RDD的Partition没有关系,Kafka的Partition数量只会增加Receiver读取Partiton的线程数量,不会增加Spark处理数据的并行度。
在基于 receiver 的方式下,Spark Streaming 会使用 Kafka 的高级消费者 API 来消费 Kafka 的数据,这种方式下的 Partition 是由 Kafka 的分区决定的,与 Spark 中 RDD 的 Partition 没有直接关系。
Kafka 中的 Partition 是 Kafka 用来进行分布式存储和处理消息的一个概念,每个 Partition 都是一个有序的消息队列,消息被均匀地分布到各个 Partition 中。当 Spark Streaming 使用 receiver 方式从 Kafka 中消费数据时,每个 Kafka Partition 对应一个 receiver,并且每个 receiver 将会在 Spark Streaming 应用程序中创建一个输入流(input stream),该输入流对应的 DStream 会对应一个 RDD Partition。
因此,每个 Kafka Partition 会产生一个对应的 DStream,而且一个 Kafka Partition 对应的 DStream 的 RDD Partition 的数量是由 Spark Streaming 应用程序中的配置参数来决定的,这个参数通常是由 spark.streaming.kafka.maxRatePerPartition 来控制的,这个参数的值可以根据实际情况进行调整,以达到更好的性能。当然,这种方式是基于 receiver 的,随着 Spark Streaming 的版本不断更新,receiver 的方式已经不再推荐使用,更推荐使用基于 direct 的方式来消费 Kafka 中的数据。
12 Spark Streaming优雅关闭
把spark.streaming.stopGracefullyOnShutdown参数设置成ture,Spark会在JVM关闭时正常关闭StreamingContext,而不是立马关闭。
13 Spark性能调优

14 宽窄依赖
对于窄依赖:
窄依赖的多个分区可以并行计算,窄依赖的一个分区的数据如果丢失只需要重新计算对应的分区的数据就可以了。
父 RDD 的一个分区只会被子 RDD 的一个分区依赖;
对于宽依赖:
划分 Stage(阶段)的依据:对于宽依赖,必须等到上一阶段计算完成才能计算下一阶段。
父 RDD 的一个分区会被子 RDD 的多个分区依赖(涉及到 shuffle)。
DAG 划分为 Stage 的算法:
核心算法: 回溯算法
从后往前回溯/反向解析, 遇到窄依赖加入本 Stage, 遇见宽依赖进行 Stage 切分。Spark 内核会从触发 Action 操作的那个 RDD 开始从后往前推, 首先会为最后一个 RDD 创建一个 Stage, 然后继续倒推, 如果发现对某个 RDD 是宽依赖, 那么就会将宽依赖的那个 RDD 创建一个新的 Stage, 那个 RDD 就是新的 Stage的最后一个 RDD。 然后依次类推, 继续倒推, 根据窄依赖或者宽依赖进行 Stage的划分, 直到所有的 RDD 全部遍历完成为止。
15 Spark 主备切换机制原理
Master 实际上可以配置两个, Spark 原生的 standalone 模式是支持 Master主备切换的。 当 Active Master 节点挂掉以后, 我们可以将 Standby Master 切换为 Active Master。
Spark Master 主备切换可以基于两种机制, 一种是基于文件系统的, 一种是基于 ZooKeeper 的。
基于文件系统的主备切换机制, 需要在 Active Master 挂掉之后手动切换到Standby Master 上;
而基于 Zookeeper 的主备切换机制, 可以实现自动切换 Master。
注: Master 切换需要注意 2 点:
1、 在 Master 切换的过程中, 所有的已经在运行的程序皆正常运行! 因为 SparkApplication 在运行前就已经通过Cluster Manager 获得了计算资源, 所以在运行时 Job 本身的 调度和处理和 Master 是没有任何关系。
2、 在 Master 的切换过程中唯一的影响是不能提交新的 Job: 一方面不能够提交新的应用程序给集群, 因为只有 Active Master 才能接受新的程序的提交请求; 另外一方面, 已经运行的程序中也不能够因 Action 操作触发新的 Job 的提交请求。
Tips: Spark Master 使用 Zookeeper 进行 HA, 有哪些源数据保存到Zookeeper 里面?
spark 通过这个参数 spark.deploy.zookeeper.dir 指定 master 元数据在zookeeper 中保存的位置, 包括 Worker, Driver 和 Application 以及Executors。 standby 节点要从 zk 中, 获得元数据信息, 恢复集群运行状态,才能对外继续提供服务, 作业提交资源申请等, 在恢复前是不能接受请求的。
16 如何保证数据不丢失?
flume 那边采用的 channel 是将数据落地到磁盘中, 保证数据源端安全性;
sparkStreaming 通过拉模式整合的时候, 使用了 FlumeUtils 这样一个类,该类是需要依赖一个额外的 jar 包( spark-streaming-flume_2.10)
要想保证数据不丢失, 数据的准确性, 可以在构建 StreamingConext 的时候, 利用 StreamingContext.getOrCreate( checkpoint, creatingFunc:() => StreamingContext) 来创建一个 StreamingContext,传入的第一个参数是 checkpoint 的存放目录, 第二参数是生成StreamingContext 对象的用户自定义函数。
如果 checkpoint 的存放目录存在, 则从这个目录中生成 StreamingContext 对象; 如果不存在, 才会调用第二个函数来生成新的 StreamingContext 对象。 在 creatingFunc函数中, 除了生成一个新的 StreamingContext 操作, 还需要完成各种操作,然后调用ssc.checkpoint(checkpointDirectory)来初始化checkpoint 功能, 最后再返回StreamingContext 对象。这样, 在StreamingContext.getOrCreate 之后, 就可以直接调用 start()函数来启动( 或者是从中断点继续运行) 流式应用了。如果有其他在启动或继续运行都要做的工作, 可以在 start()调用前执行。
17 Spark on Mesos中,什么是的粗粒度分配,什么是细粒度分配,各自的优点和缺点是什么?
1)粗粒度:启动时就分配好资源, 程序启动,后续具体使用就使用分配好的资源,不需要再分配资源;好处:作业特别多时,资源复用率高,适合粗粒度;不好:容易资源浪费,假如一个job有1000个task,完成了999个,还有一个没完成,那么使用粗粒度,999个资源就会闲置在那里,资源浪费。
2)细粒度分配:用资源的时候分配,用完了就立即回收资源,启动会麻烦一点,启动一次分配一次,会比较麻烦。
18 spark的有几种部署模式,每种模式特点?
1)本地模式
Spark不一定非要跑在hadoop集群,可以在本地,起多个线程的方式来指定。将Spark应用以多线程的方式直接运行在本地,一般都是为了方便调试,本地模式分三类
·local:只启动一个executor
·localk:启动k个executor
·local*:启动跟cpu数目相同的 executor
2)standalone模式
分布式部署集群,自带完整的服务,资源管理和任务监控是Spark自己监控,这个模式也是其他模式的基础。
3)Spark on yarn模式
分布式部署集群,资源和任务监控交给yarn管理,但是目前仅支持粗粒度资源分配方式,包含cluster和client运行模式,cluster适合生产,driver运行在集群子节点,具有容错功能,client适合调试,dirver运行在客户端
4)Spark On Mesos模式
官方推荐这种模式(当然,原因之一是血缘关系)。正是由于Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然。用户可选择两种调度模式之一运行自己的应用程序:
(1)粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task(对应多少个“slot”)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。
(2)细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。
19 Spark为什么比mapreduce快?
1)基于内存计算,减少低效的磁盘交互;
2)基于高效的DAG调度算法;
3)容错机制Lingage,主要是DAG和Lianage,及时spark不使用内存技术,也大大快于mapreduce。
20 Hadoop和Spark的shuffle相同和差异?
相同点:
从 high-level 的角度来看,两者并没有大的差别。 都是将 mapper(Spark 里是ShuffleMapTask)的输出进行 partition,不同的 partition 送到不同的 reducer(Spark 里 reducer 可能是下一个 stage 里的 ShuffleMapTask,也可能是 ResultTask)。Reducer 以内存作缓冲区,边 shuffle 边 aggregate 数据,等到数据 aggregate 好以后进行 reduce() (Spark 里可能是后续的一系列操作)。
不同点:
① MapReduce 默认是排序的,spark 默认不排序,除非使用 sortByKey 算子。
② MapReduce 可以划分成 split,map()、spill、merge、shuffle、sort、reduce()等阶段,spark 没有明显的阶段划分,只有不同的 stage 和算子操作。
③MR 落盘,Spark 不落盘,spark 可以解决 mr 落盘导致效率低下的问题。
21 spark-submit的时候如何引入外部jar包
方法一:spark-submit –jars
根据spark官网,在提交任务的时候指定–jars,用逗号分开。这样做的缺点是每次都要指定jar包,如果jar包少的话可以这么做,但是如果多的话会很麻烦。
命令:spark-submit --master yarn-client --jars ***.jar,***.jar
方法二:extraClassPath
提交时在spark-default中设定参数,将所有需要的jar包考到一个文件里,然后在参数中指定该目录就可以了,较上一个方便很多:
spark.executor.extraClassPath=/home/hadoop/wzq_workspace/lib/*
spark.driver.extraClassPath=/home/hadoop/wzq_workspace/lib/*
需要注意的是,你要在所有可能运行spark任务的机器上保证该目录存在,并且将jar包考到所有机器上。这样做的好处是提交代码的时候不用再写一长串jar了,缺点是要把所有的jar包都拷一遍。
22 RDD的弹性表现在哪几点?
1)自动的进行内存和磁盘的存储切换;
2)基于Lineage的高效容错;
3)task如果失败会自动进行特定次数的重试;
4)stage如果失败会自动进行特定次数的重试,而且只会计算失败的分片;
5)checkpoint和persist,数据计算之后持久化缓存
6)数据调度弹性,DAG TASK调度和资源无关
7)数据分片的高度弹性,a.分片很多碎片可以合并成大的,b.par
23 RDD有哪些缺陷?
1)不支持细粒度的写和更新操作(如网络爬虫),spark写数据是粗粒度的。所谓粗粒度,就是批量写入数据,为了提高效率。但是读数据是细粒度的也就是说可以一条条的读。
2)不支持增量迭代计算,Flink支持
24 Spark的数据本地性有哪几种?
① PROCESS_LOCAL:数据和计算它的代码在同⼀个JVM进程⾥⾯;
② NODE_LOCAL:数据和计算它的代码在⼀个节点上,但是不在⼀个进程中,⽐如不在同⼀个executor进程中,或者是数据在hdfs⽂件的block中;
③ NO_PREF:数据从哪⾥过来,性能都是⼀样的;
④ RACK_LOCAL:数据和计算它的代码在⼀个机架上;
⑤ ANY:数据可能在任意地⽅,⽐如其他⽹络环境内,或者其他机架上。
通常读取数据PROCESS_LOCAL>NODE_LOCAL…>ANY,尽量使数据以PROCESS_LOCAL或NODE_LOCAL方式读取。其中PROCESS_LOCAL还和cache有关,如果RDD经常用的话将该RDD cache到内存中,注意,由于cache是lazy的,所以必须通过一个action的触发,才能真正的将该RDD cache到内存中。
可以设置参数, spark.locality系列参数,来调节spark等待task可以进⾏数据本地化的时间。
saprk.locality.wait(3000ms)
spark.locality.wait.node
spark.locality.wait.process
spark.locality.wait.rack
25 Spark为什么要持久化,一般什么场景下要进行persist操作?
spark所有复杂一点的算法都会有persist身影,spark默认数据放在内存,spark很多内容都是放在内存的,非常适合高速迭代,1000个步骤,只有第一个输入数据,中间不产生临时数据,但分布式系统风险很高,所以容易出错,就要容错,rdd出错或者分片可以根据血统算出来,如果没有对父rdd进行persist 或者cache的化,就需要重头做。
以下场景会使用persist:
1)某个步骤计算非常耗时,需要进行persist持久化
2)计算链条非常长,重新恢复要算很多步骤,最好使用persist
3)checkpoint所在的rdd要持久化persist。lazy级别,框架发现有checnkpoint,checkpoint时单独触发一个job,需要重算一遍,checkpoint前,要持久化,写个rdd.cache或者rdd.persist,将结果保存起来,再写checkpoint操作,这样执行起来会非常快,不需要重新计算rdd链条了。checkpoint之前一定会进行persist。
4)shuffle之后为什么要persist,shuffle要进性网络传输,风险很大,数据丢失重来,恢复代价很大
5)shuffle之前进行persist,框架默认将数据持久化到磁盘,这个是框架自动做的。
26 parition和block有什么关联关系?
1)hdfs中的block是分布式存储的最小单元,等分,可设置冗余,这样设计有一部分磁盘空间的浪费,但是整齐的block大小,便于快速找到、读取对应的内容;
2)Spark中的partion是弹性分布式数据集RDD的最小单元,RDD是由分布在各个节点上的partion组成的。partion是指的spark在计算过程中,生成的数据在计算空间内最小单元,同一份数据(RDD)的partion大小不一,数量不定,是根据application里的算子和最初读入的数据分块数量决定;
3)block位于存储空间、partion位于计算空间,block的大小是固定的、partion大小是不固定的,是从2个不同的角度去看数据。
27 使用Spark解决分组排序问题?
数据组织形式:
aa | 11 |
|---|---|
bb | 11 |
cc | 34 |
aa | 22 |
bb | 67 |
cc | 29 |
aa | 36 |
bb | 33 |
cc | 30 |
aa | 42 |
bb | 44 |
cc | 49 |
需求:
1)对上述数据按key值进行分组
2)对分组后的值进行排序
3)截取分组后值得top 3位以key-value形式返回结果
val groupTopNRdd =sc.textFile("hdfs://db02:8020/user/hadoop/groupsorttop/groupsorttop.data")
groupTopNRdd
.map(_.split(" "))
.map(x => (x(0),x(1)))
.groupByKey()
.map(
x => {
val xx = x._1
val yy = x._2
(xx,yy.toList.sorted.reverse.take(3))
}).collect28 窄依赖父RDD的partition和子RDD的parition是不是都是一对一的关系?
不一定,除了一对一的窄依赖,还包含一对固定个数的窄依赖(就是对父RDD的依赖的Partition的数量不会随着RDD数量规模的改变而改变),比如join操作的每个partiion仅仅和已知的partition进行join,这个join操作是窄依赖,依赖固定数量的父rdd,因为是确定的partition关系。
29 不需要排序的hash shuffle是否一定比需要排序的sort shuffle速度快?
不一定,当数据规模小,Hash shuffle快于Sorted Shuffle数据规模大的时候;当数据量大,sorted Shuffle会比Hash shuffle快很多,因为数量大的有很多小文件,不均匀,甚至出现数据倾斜,消耗内存大,1.x之前spark使用hash,适合处理中小规模,1.x之后,增加了Sorted shuffle,Spark更能胜任大规模处理了。
30 Spark中的HashShufle的有哪些不足?
1)shuffle产生海量的小文件在磁盘上,此时会产生大量耗时的、低效的IO操作;
2)由于内存需要保存海量的文件操作句柄和临时缓存信息,如果数据处理规模比较大的化,容易出现OOM;
3)容易出现数据倾斜,导致OOM。
31 Sort-based shuffle的缺陷?
1)如果mapper中task的数量过大,依旧会产生很多小文件,此时在shuffle传递数据的过程中reducer段,reduce会需要同时大量的记录进行反序列化,导致大量的内存消耗和GC的巨大负担,造成系统缓慢甚至崩溃
2)如果需要在分片内也进行排序,此时需要进行mapper段和reducer段的两次排序
32 使用Scala代码实现WordCount?
val conf = new SparkConf()
val sc = new SparkContext(conf)
val line = sc.textFile("xxxx.txt")
line.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.collect()
.foreach(println)
sc.stop()33 hbase region多大会分区,spark读取hbase数据是如何划分partition的?
region超过了hbase.hregion.max.filesize这个参数配置的大小就会自动裂分,默认值是1G。
默认情况下,hbase有多少个region,Spark读取时就会有多少个partition
34 Kryo序列化
Kryo序列化比Java序列化更快更紧凑,但Spark默认的序列化是Java序列化并不是Spark序列化,因为Spark并不支持所有序列化类型,而且每次使用都必须进行注册。注册只针对于RDD。在DataFrames和DataSet当中自动实现了Kryo序列化。
35 如何使用Spark实现TopN的获取(描述思路或使用伪代码)(重点)
方法1:
(1)按照key对数据进行聚合(groupByKey)
(2)将value转换为数组,利用scala的sortBy或者sortWith进行排序(mapValues)数据量太大,会OOM。
方法2:
(1)取出所有的key
(2)对key进行迭代,每次取出一个key利用spark的排序算子进行排序
方法3:
(1)自定义分区器,按照key进行分区,使不同的key进到不同的分区
(2)对每个分区运用spark的排序算子进行排序
36 介绍一下 cogroup rdd 实现原理,你在什么场景下用过这个 rdd?
cogroup:对多个(2~4)RDD 中的 KV 元素,每个 RDD 中相同 key 中的元素分别聚合成一个集合。
与 reduceByKey 不同的是:reduceByKey 针对一个 RDD 中相同的 key 进行合并。而 cogroup 针对多个 RDD 中相同的 key 的元素进行合并。
cogroup 的函数实现:这个实现根据要进行合并的两个 RDD 操作,生成一个CoGroupedRDD 的实例,这个 RDD 的返回结果是把相同的 key 中两个 RDD 分别进行合并操作,最后返回的 RDD 的 value 是一个 Pair 的实例,这个实例包含两个 Iterable 的值,第一个值表示的是 RDD1 中相同 KEY 的值,第二个值表示的是 RDD2 中相同 key 的值。
由于做 cogroup 的操作,需要通过 partitioner 进行重新分区的操作,因此,执行这个流程时,需要执行一次 shuffle 的操作(如果要进行合并的两个 RDD的都已经是 shuffle 后的 rdd,同时他们对应的 partitioner 相同时,就不需要执行 shuffle)。
场景:表关联查询或者处理重复的 key。
37 DAG 是什么?
DAG(Directed Acyclic Graph 有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是 RDD 执行的流程);
原始的 RDD 通过一系列的转换操作就形成了 DAG 有向无环图,任务执行时,可以按照 DAG 的描述,执行真正的计算(数据被操作的一个过程)。
38 DAG 中为什么要划分 Stage?
并行计算。
一个复杂的业务逻辑如果有 shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照shuffle 进行划分(也就是按照宽依赖就行划分),就可以将一个 DAG 划分成多个 Stage/阶段,在同一个 Stage 中,会有多个算子操作,可以形成一个pipeline 流水线,流水线内的多个平行的分区可以并行执行。
39 Spark 中的 OOM 问题?
39.1 map 类型的算子执行中内存溢出如 flatMap,mapPatitions
原因:map 端过程产生大量对象导致内存溢出,这种溢出的原因是在单个map 中产生了大量的对象导致的。
解决方案:
① 增加堆内内存。
② 在不增加内存的情况下,可以减少每个 Task 处理数据量,使每个 Task产生大量的对象时,Executor 的内存也能够装得下。具体做法可以在会产生大量对象的 map 操作之前调用 repartition 方法,分区成更小的块传入 map。
39.2 driver 内存溢出
当 Driver 内存不足时,通常会抛出 OutOfMemoryError 异常。为了解决这个问题,可以考虑以下几种方法:
① 增加 Driver 的内存:可以通过 --driver-memory 选项或 spark.driver.memory 参数增加 Driver 的内存。可以尝试增加 Driver 内存以使其能够处理更大的数据量,但是过高的内存可能会导致内存浪费和长时间的垃圾回收。因此,需要根据具体情况进行调整。
② 优化代码逻辑:检查应用程序的代码逻辑,确保不会产生过多的数据或重复计算。可以通过使用合适的算法和数据结构、缓存计算结果、并行化操作等方式来减少内存的使用。
③ 减少 Driver 中的数据量:可以考虑将一些数据存储在外部存储系统中,比如 HDFS、S3 等,并在需要时进行读取。此外,可以通过将一些计算下推到 Executor 中来减少 Driver 中的数据量。
④ 调整 Spark 配置参数:可以通过调整 Spark 的配置参数来优化内存使用。比如可以通过增加并行度来减少每个任务处理的数据量,减小 Shuffle 内存使用,调整内存分配策略等。
⑤ 使用集群管理器:可以使用集群管理器(如 YARN、Kubernetes)来管理应用程序的资源。通过集群管理器,可以动态地分配资源,以避免 Driver 内存不足的问题。
需要注意的是,内存溢出通常是由于应用程序的代码逻辑或数据量等因素导致的,需要仔细分析问题,并根据具体情况采取相应的措施。
40 Spark 中数据的位置是被谁管理的?
每个数据分片都对应具体物理位置,数据的位置是被 blockManager 管理,无论数据是在磁盘,内存还是 tacyan,都是由blockManager 管理。
41 Spark SQL 执行的流程?
Spark SQL 是 Spark 的一个模块,提供了一种基于 SQL 的数据操作接口,并支持将 SQL 查询和 DataFrame 操作转换为 Spark 的底层计算模型,以便于执行分布式计算任务。
下面是 Spark SQL 执行的基本流程:
① 解析 SQL生成逻辑执行计划:首先,Spark SQL 会解析输入的 SQL 语句,并将其转换为一个逻辑执行计划(Logical Plan)。
② 优化逻辑执行计划:Spark SQL 接着会对逻辑执行计划进行一系列的优化,包括谓词下推、列剪枝、列裁剪、表达式下推等等,以提高查询性能。

③ 生成物理执行计划:接下来,Spark SQL 会根据优化后的逻辑执行计划生成物理执行计划(Physical Plan)。物理执行计划通常是一组 Spark RDD 转换操作,它们对应于逻辑计划中的不同操作。
④ 生成任务(Task):Spark SQL 将物理执行计划转换为一组具体的任务(Task),这些任务被分配到不同的 Executor 上并在分布式集群上运行。
⑤ 执行任务:Spark SQL 将任务发送到 Executor 上并执行它们。每个任务会读取它们所需要的数据,对数据执行一定的转换操作,并将结果写回到磁盘或内存中。
⑥ 合并结果:Spark SQL 将任务的结果合并起来,并返回给用户。
42 如何实现 Spark Streaming 读取Flume 中的数据?
sparkStreaming 整合 flume有 2 种模式,一种是拉模式,一种是推模式,实际开发中选择拉模式。
推模式:Flume 将数据 Push 推给 Spark Streaming
拉模式:Spark Streaming 从 flume 中 Poll 拉取数据
43 说说updateStateByKey
对整个实时计算的所有时间间隔内产⽣的相关数据进⾏统计。spark streaming的解决⽅案是累加器,⼯作原理是定义⼀个类似全局的可更新的变量,每个时间窗口内得到的统计值都累加到上个时间窗⼜得到的值,这样整个累加值就是跨越多个时间间隔。
updateStateByKey操作可以让我们为每个key维护⼀份state,并持续不断的更新该state。
⾸先,要定义⼀个state,可以是任意的数据类型;
其次,要定义state更新函数(指定⼀个函数如何使⽤之前的state和新值来更新state)。对于每个batch, spark都会为每个之前已经存在的key去应⽤⼀次state更新函数,⽆论这个key在batch中是否有新的数据。如果state更新函数返回none,那么key对应的state就会被删除。当然对于每个新出现的key也会执⾏state更新函数。注意updatestateBykey要求必须开启checkpoint机制。
updateStateByKey返回的都是DStream类型。根据updateFunc这个函数来更新状态。其中参数: SeqV是本次的数据类型, OptionS是前次计算结果类型,本次计算结果类型也是OptionS。计算肯定需要Partitioner。因为Hash⾼效率且不做排序,默认Partitioner是HashPartitoner。
由于cogroup会对所有数据进⾏扫描,再按key进⾏分组,所以性能上会有问题。特别是随着时间的推移,这样的计算到后⾯会越算越慢。所以数据量⼤的计算、复杂的计算,都不建议使⽤updateStateByKey。
44 spark streaming中有状态转化操作?
DStream的有状态转化操作是跨时间区间跟踪数据的操作,即⼀些先前批次的数据也被⽤来在新的批次中计算结果。 主要包括滑动窗口和updateStateByKey(),前者以⼀个时间阶段为滑动窗⼜进⾏操作,后者则⽤来跟踪每个键的状态变化。 (例如构建⼀个代表⽤户会话的对象)。
有状态转化操作需要在Streaming Context中打开检查点机制来确保容错性。
滑动窗口:基于窗口的操作会在⼀个⽐Streaming Context的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。基于窗口的操作需要两个参数,分别为窗口时长以及滑动时长,两者都必须是Streaming Context的批次间隔的整数倍。窗口时长控制每次计算最近的多少个批次的数据,滑动步长控制对新的DStream进⾏计算的间隔。
最简单的窗口操作是window(),它返回的DStream中的每个RDD会包含多个批次中的户数,可以分别进⾏其他transform()操作。在轨迹异常项⽬中, duration设置为15s,窗口函数设置为kafkadstream.windo(Durations.seconds(600),Durations.seconds(600));
updateStateByKey转化操作:需要在DStream中跨批次维护状态(例如跟踪⽤户访问⽹站的会话)。针对这种情况,⽤于键值对形式的DStream。给定⼀个由(键、事件)对构成的DStream,并传递⼀个指定根据新的事件更新每个键对应状态的函数。
举例:在⽹络服务器⽇志中,事件可能是对⽹站的访问,此时键是⽤户的ID。使⽤UpdateStateByKey()可以跟踪每个⽤户最近访问的10个页⾯。这个列表就是“状态”对象,我们会在每个事件到来时更新这个状态。
45 Spark的三种提交模式是什么?
(1)Spark内核架构,即standalone模式,基于Spark⾃⼰的Master-Worker集群;
(2)基于Yarn的yarn-cluster模式;
(3)基于Yarn的yarn-client模式。
如果你要切换到第⼆种和第三种模式,将之前提交spark应⽤程序的spark-submit脚本,加上–master参数,设置为yarncluster,或yarn-client即可。如果没设置就是standalone模式。
46 Spark yarn-cluster架构?
Yarn-cluster⽤于⽣产环境,优点在于driver运⾏在NM,没有⽹卡流量激增的问题。缺点在于调试不⽅便,本地⽤sparksubmit提交后,看不到log,只能通过yarm application-logs application_id这种命令来查看,很⿇烦。
(1)将spark程序通过spark-submit命令提交,会发送请求到RM(相当于Master),请求启动AM;
(2)在yarn集群上, RM会分配⼀个container,在某个NM上启动AM;
(3)在NM上会启动AM(相当于Driver), AM会找RM请求container,启动executor;
(4)RM会分配⼀批container⽤于启动executor;
(5)AM会连接其他NM(相当于worker),来启动executor;
(6)executor启动后,会反向注册到AM。
47 Spark yarn-client架构?
Yarn-client⽤于测试,因为driver运⾏在本地客户端,负责调度application,会与yarn集群产⽣⼤量的⽹络通信,从⽽导致⽹卡流量激增,可能会被公司的SA警告。好处在于,直接执⾏时本地可以看到所有的log,⽅便调试。
(1)将spark程序通过spark-submit命令提交,会发送请求到RM,请求启动AM;
(2)在yarn集群上, RM会分配⼀个container在某个NM上启动application;
(3)在NM上会启动application master,但是这⾥的AM其实只是⼀个ExecutorLauncher,功能很有限,只会去申请资源。 AM会找RM申请container,启动executor;
(4)RM会分配⼀批container⽤于启动executor;
(5)AM会连接其他NM(相当于worker),⽤container的资源来启动executor;
(6)executor启动后,会反向注册到本地的Driver进程。通过本地的Driver去执⾏DAGsheduler和Taskscheduler等资源调度。和Spark yarn-cluster的区别在于, cluster模式会在某⼀个NM上启动AM作为Driver。
48 spark⽀持故障恢复的⽅式?
主要包括两种⽅式:⼀种是通过⾎缘关系lineage,当发⽣故障的时候通过⾎缘关系,再执⾏⼀遍来⼀层⼀层恢复数据;另⼀种⽅式是通过checkpoint()机制,将数据存储到持久化存储中来恢复数据。
49 spark 实现⾼可⽤性: High Availability
如果有些数据丢失,或者节点挂掉;那么不能让你的实时计算程序挂了;必须做⼀些数据上的冗余副本,保证你的实时计算程序可以7 * 24⼩时的运转。
(1).updateStateByKey、 window 等有状态的操作,⾃动进⾏checkpoint,必须设置checkpoint⽬录:容错的⽂件系统的⽬录,⽐如说,常⽤的是HDFS
SparkStreaming.checkpoint("hdfs://192.168.1.105:9090/checkpoint")设置完这个基本的checkpoint⽬录之后,有些会⾃动进⾏checkpoint操作的DStream,就实现了HA⾼可⽤性; checkpoint,相当于是会把数据保留⼀份在容错的⽂件系统中,⼀旦内存中的数据丢失掉;那么就可以直接从⽂件系统中读取数据;不需要重新进⾏计算
(2).Driver⾼可⽤性
第⼀次在创建和启动StreamingContext的时候,那么将持续不断地将实时计算程序的元数据(⽐如说,有些dstream或者job执⾏到了哪个步骤),如果后⾯,不幸,因为某些原因导致driver节点挂掉了;那么可以让spark集群帮助我们⾃动重启driver,然后继续运⾏实时计算程序,并且是接着之前的作业继续执⾏;没有中断,没有数据丢失
第⼀次在创建和启动StreamingContext的时候,将元数据写⼊容错的⽂件系统(⽐如hdfs); spark-submit脚本中加⼀些参数;保证在driver挂掉之后, spark集群可以⾃⼰将driver重新启动起来;⽽且driver在启动的时候,不会重新创建⼀个streaming context,⽽是从容错⽂件系统(⽐如hdfs)中读取之前的元数据信息,包括job的执⾏进度,继续接着之前的进度,继续执⾏。
使⽤这种机制必须使⽤cluster模式提交,确保driver运⾏在某个worker上⾯;
(3).实现RDD⾼可⽤性:启动WAL预写⽇志机制
spark streaming,从原理上来说,是通过receiver来进⾏数据接收的;接收到的数据,会被划分成⼀个⼀个的block; block会被组合成⼀个batch;针对⼀个batch,会创建⼀个rdd;启动⼀个job来执⾏我们定义的算⼦操作。
receiver主要接收到数据,那么就会⽴即将数据写⼊⼀份到容错⽂件系统(⽐如hdfs)上的checkpoint⽬录中的,⼀份磁盘⽂件中去;作为数据的冗余副本。⽆论你的程序怎么挂掉,或者是数据丢失,那么数据都不肯能会永久性的丢失;因为肯定有副本。
//WAL(Write-Ahead Log)预写⽇志机制
1 spark.streaming.receiver.writeAheadLog.enable true50 DStream以及基本⼯作原理?
DStream是spark streaming提供的⼀种⾼级抽象,代表了⼀个持续不断的数据流。 DStream可以通过输⼊数据源来创建,⽐如Kafka、 flume等,也可以通过其他DStream的⾼阶函数来创建,⽐如map、 reduce、 join和window等。
DStream内部其实不断产⽣RDD,每个RDD包含了⼀个时间段的数据。
Spark streaming⼀定是有⼀个输⼊的DStream接收数据,按照时间划分成⼀个⼀个的batch,并转化为⼀个RDD, RDD的数据是分散在各个⼦节点的partition中。
51 Hive On Spark 和Spark On Hive的区别
Hive on Spark是一种将Hive与Spark集成在一起的方式。它允许Hive在Spark上运行,从而提供更高的性能和更好的可伸缩性。在Hive on Spark中,Spark用作Hive的执行引擎。Hive将SQL查询转换为Spark作业,并使用Spark的分布式计算能力来处理数据。 这样,Hive就可以利用Spark的内存计算和并行处理能力来提高性能。
Spark on Hive是一种在Spark上运行Hive查询的方式。在Spark on Hive中,Spark将Hive表作为DataFrame或Dataset进行处理,并使用Spark SQL执行Hive查询。这样,Spark就可以利用Hive的元数据信息和查询优化能力,而无需使用Hive自身的执行引擎。 Spark on Hive可以提供更好的性能和更好的灵活性,因为它允许使用Spark的所有功能来处理Hive数据。
总的来说,Hive on Spark 和 Spark on Hive 都是为了提高 SQL 查询的性能和扩展性。但是它们的实现方式不同,Hive on Spark 主要是利用 Spark 高效的计算引擎来执行 SQL 查询,而 Spark on Hive 主要是利用 Hive 的元数据存储和查询优化功能来优化 SQL 查询的执行计划。具体选择哪种模式,需要根据具体的场景和需求来决定。
52 Hive on spark 和Spark on hive 将sql转化成执行计划的过程
52.1 Hive on Spark
在 Hive on Spark 中,将 SQL 查询转换为执行计划的过程分为以下几步:
首先,Hive 将 SQL 查询解析成一个抽象语法树,然后解析出查询块,之后根据查询块解析出逻辑执行计划,即一个 DAG(有向无环图),其中每个节点表示一个操作(例如,选择、过滤、聚合等)。
然后,Hive 将逻辑执行计划转换为物理执行计划,即一个由 MapReduce 作业组成的 DAG。在这个过程中,Hive 会将一些操作合并起来,以减少数据的传输和存储,从而提高查询性能。
最后,Hive 将物理执行计划转换为 Spark 作业,即将每个 MapReduce 作业转换为一个 Spark 作业。在这个过程中,Hive 会将一些操作转换为 Spark 支持的操作,例如,将 MapReduce 的 Group By 操作转换为 Spark 的聚合操作。
52.2 Spark on Hive
在 Spark on Hive 中,将 SQL 查询转换为执行计划的过程分为以下几步:
首先,Spark 会将 SQL 查询解析成一个逻辑执行计划,即一个 DAG(有向无环图),其中每个节点表示一个操作(例如,选择、过滤、聚合等)。
然后,Spark 将逻辑执行计划转换为物理执行计划,即一个由 Spark 作业组成的 DAG。在这个过程中,Spark 会利用 Hive 的元数据存储和查询优化功能,来优化 SQL 查询的执行计划。例如,Spark 会使用 Hive 的表统计信息来选择最优的执行计划。
最后,Spark 执行物理执行计划,即按照 DAG 的拓扑顺序依次执行 Spark 作业。在执行过程中,Spark 会将数据加载到内存中,进行计算,并将计算结果写回到 Hive 的数据存储中。
总的来说,无论是 Hive on Spark 还是 Spark on Hive,都将 SQL 查询转换为执行计划的过程分为解析、优化和执行三个阶段。但是它们的实现方式不同,Hive on Spark 主要是将 SQL 查询转换为 Spark 作业,而 Spark on Hive 主要是利用 Hive 的元数据存储和查询优化功能来优化 SQL 查询的执行计划。
53 Spark 框架模块
Spark Core:
包含数据结构RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块
Spark SQL:
用于操作结构化数据的程序包,通过 Spark SQL,我们可以使用 SQL操作数据。
数据结构:Dataset/DataFrame = RDD + Schema;
Structured Streaming
Spark Streaming:
用于对实时数据进行流式计算的组件;
数据结构:DStream = Seq[RDD]
Spark GraphX: 图片计算引擎
Spark中用于图计算的API;
数据结构:RDD或者DataFrame
Spark MLlib : 机器学习:
机器学习(ML)功能的程序库;
数据结构:RDD或者DataFrame
54 Spark 内存管理
54.1 内存分配
总内存
预留内存(300M)当总内存非常大时,可以忽略;
可用内存:usable memory;
其他内存:用于用户自定义的数据结构以及spark的元数据存储;
统一内存:用于Storage 和 Exection 的内存;
Storage 内存:用于存放RDD 数据;
Exection内存:用于存放Shuffle时生成的临时数据;
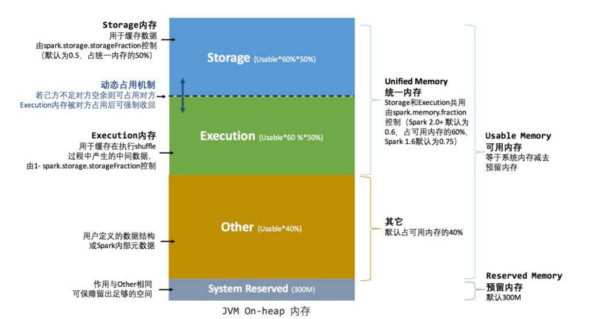
54.2 内存动态占用机制
设定基本的存储内存(storage)和执行内存(execution)区域:spark.storage.storageFraction双方的空间都不足时, 则溢写到硬盘;
若自己的空间不足,而对方有空余时,可借用对方的空间;(存储空间不足:不足存放一个完整的block)
执行空间不足时,如果有被对方占用的空间,可以让对方见该数据溢写到磁盘中,强制要回空间;
存储空间不足时,如果有被对方占用的空间,无法让对方“归还”,因为Shuffle过程复杂,优先级高;

55 简单介绍一下Spark的shuffle 机制
1. 在RDD之间出现了宽依赖的时候会出现Shuffle机制;
2. shuffle分为两个阶段 : 上游stage的writeshuffle ,下游stage的readshuffle;
3. Spark 目前使用shuffle实现方式是: byPass 、UnsafeShuffleWriter 、Sort Shuffle;
4. Sort Shuffle 实现流程(普通机制):
① 先将数据写入内存数据结构中;
② 每写一条数据进入内存数据结构,就会判断是否达到了Storage内存的临界值;
③ 如果达到临界值就会将内存数据结构中的数据溢写到磁盘中;再溢写之前需要根据key排序;(方便生成index文件查询使用)
④ 每次溢写后都会生成一个文件,最后将这些文件合并成一个大的数据文件和一个index文件;
⑤ 最后下游的stage根据index文件去读取数据文件;

56 Spark如何实现容错?
- 首先看内存中是否已经cache或persist 缓存;
- 再查看是否checkpoint值hdfs中;
- 最后根据依赖链构建血缘关系重建rdd;
57 SparkSQL中查询一列的字段的方法有几种?
df.select( ‘id’ );
df.select( col(‘id’) );
df.select( colomns(‘id’) );
df.select( 'id );#注意: 只有一个单引号
df.select( $“id” ) : 常用;
58 SparkSQL中的如何动态增加Schema?
Spark中StructedType对象就是Schema ;
Spark中StructedField对象封装每个字段的信息;
StructedType(StructedField(data,name,nullable)::Nil);
new StructedType().add(data,name,nullable).add();
spark.createDataFrame(rddData, schema)
59 SparkSQL中DSL和SQL风格差异?
DSL风格df.select;
SQL风格需要注册一张临时表或视图进行展示;
60 全局Session和局部Session的差别是什么?
全局的Session可以跨Session访问注册的临时视图或表;
局部Session只能访问当前会话中临时试图或表;
61 在微批时间跟窗口时间一致时,可以使用reduceByKey么?
可以的前提是:
窗口时间必须是微批时间的整数倍,如果做窗口计算使用reduceByKeyAndWindow算子;
但是当窗口时间 = 微批时间的时候,就相当于没有做窗口计算了。
62 整合kafka总结
62.1 消费kafka数据:
不能设置group id ;
不能设置auto.offset.reset;
不能设置key/value.deserializer/serializer;
不能设置enable.auto.commit;
不能设置interceptor.classes;
62.2 生成kafka数据:
DataFrame中必须有value 字段;
DataFrame中可选择有key, topic 字段;
option设置中必须有kafka.bootstrap.servers;
option设置中可选择有topic;
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-03-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号