基于Tesseract组件的OCR识别


背景以及介绍
欲研究C#端如何进行图像的基本OCR识别,找到一款开源的OCR识别组件。该组件当前已经已经升级到了4.0版本。和传统的版本(3.x)比,4.0时代最突出的变化就是基于LSTM神经网络。Tesseract本身是由C++进行编写,但为了同时适配不同的语言进行调用,开放调用API并产生了诸如Java、C#、Python等主流语言在内的封装版本。本次主要研究C#封装版。
项目结构
Tesseract本身由C++编写并开源在Github,在3.X版本中,Tesseract的识别模式为字符识别,该种识别方式识别能力较低,所以在后来的4.X版本中,引入了LSTM(Long short-term memory,长短期记忆神经网络),极大的提升了识别率。为了让不同的语言均能够使用Tesseract进行OCR识别,Tesseract也是开放了API并产生了诸如Java、C#、Python等主流语言在内的封装版本。而本次C#端的封装版也开源在了Github,目前已知的C#封装版已发布在nuget上,封装了对应Tesseract的版本为3.05.02。所以目前的项目结构如下:
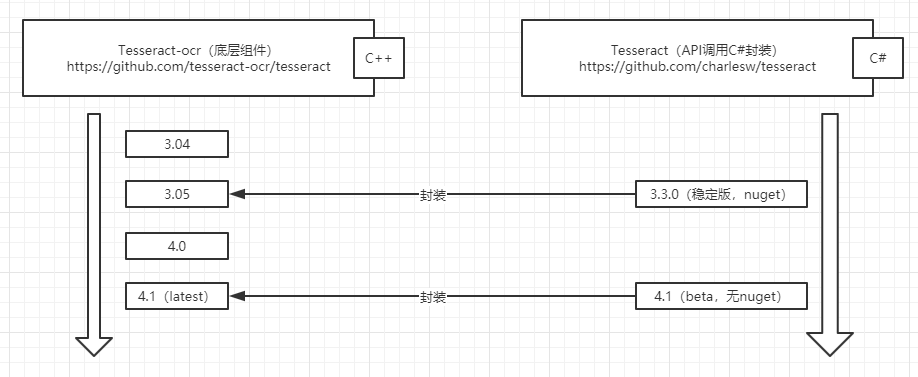
Demo实验
环境准备
文本识别数据包准备
因为图像识别本身需要文本识别数据进行匹配,所以我们需要下载对应Tesseract官方的文本数据包: https://tesseract-ocr.github.io/tessdoc/Data-Files 注意,针对不同版本的Tesseract-OCR(3.X和4.X底层的实现方式不同,所以文本识别数据包是不同的),我们需要找到对应的不同的文本训练数据包,官网为了更好的兼容性,4.X版本的文本数据包是兼容了3.X版本的。
the third set in tessdata is the only one that supports the legacy recognizer. The 4.00 files from November 2016 have both legacy and older LSTM models. The current set of files in tessdata have the legacy models and newer LSTM models (integer versions of 4.00.00 alpha models in tessdata_best).
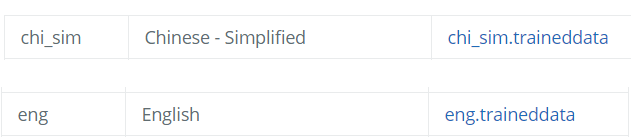
为了Demo,我下载了中文简体和英文的数据包作为实验对象
开发环境准备
为了实验并对比上面两个封装版本的识别效果,这里在同一解决方案中创建了两个项目:
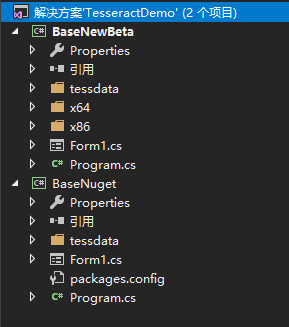
BaseNewBeta使用的是封装了4.1版本Tesseract的C#封装版Tesseract.4.1.0-beta1,因为该版本还还没有上传只Nuget,所以只能从github上下载,放到本地,然后把对应的C++的底层库(leptonica-1.78.0.dll,tesseract41.dll)放置到了x86和x64文件夹下面且需要输出。
BaseNuget是已经上传至Nuget的封装了底层库3.05.20版本的C#封装版3.3.0.0,因为使用nuget进行组件安装,所以x64和x86的Tesseract组件会在编译输出时候自动输出到对应的生成目录。
核心代码
if (openFileDialog1.ShowDialog() == DialogResult.OK)
{
//PictureBox控件显示图片
pictureBox1.Load(openFileDialog1.FileName);
//获取用户选择文件的后缀名
string extension = Path.GetExtension(openFileDialog1.FileName);
//声明允许的后缀名
string[] str = new string[] { ".jpg", ".png" };
if (!str.Contains(extension))
{
MessageBox.Show("仅能上传jpg,png格式的图片!");
}
else
{
//识别图片文字
Bitmap img = new Bitmap(openFileDialog1.FileName);
// 构建识别引擎
TesseractEngine orcEngine = new TesseractEngine("./tessdata", "eng");
// 识别并获取文本数据
Page page = orcEngine.Process(img);
richTextBox1.Text = page.GetText();
}
}最终效果
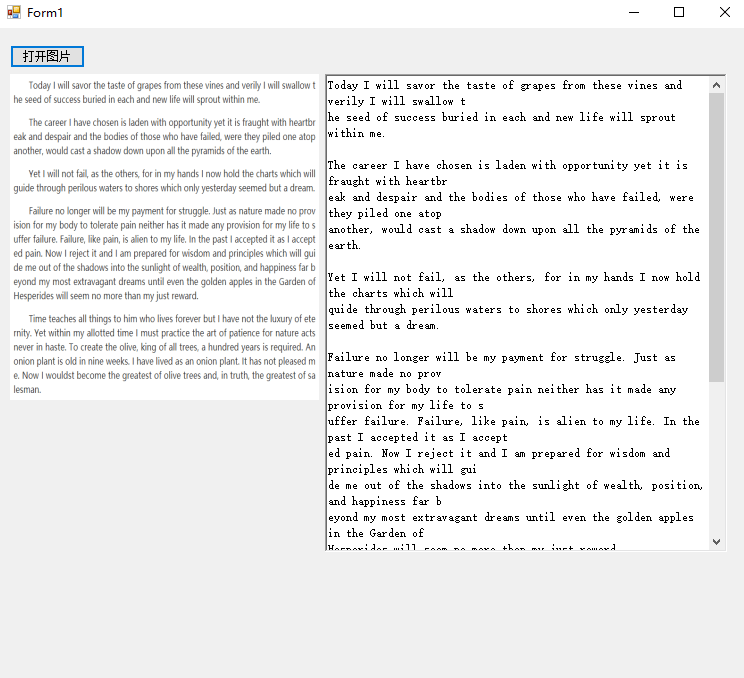
英文识别效果
先是3.X版本识别:
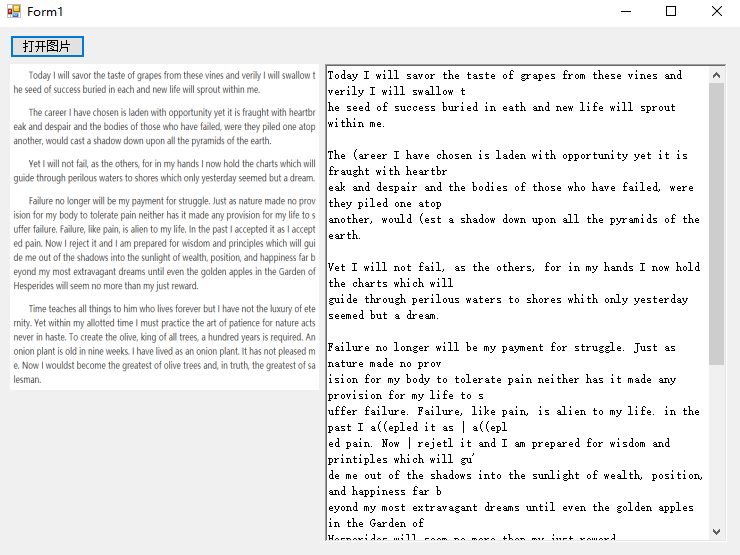
可以看到文本中还有很多识别的错误的,特别是把英文字符C识别为了括号(。 而封装了新版本的识别结果比起之前更好:
中文识别效果
先是3.X版本识别:

然后是封装的版本:
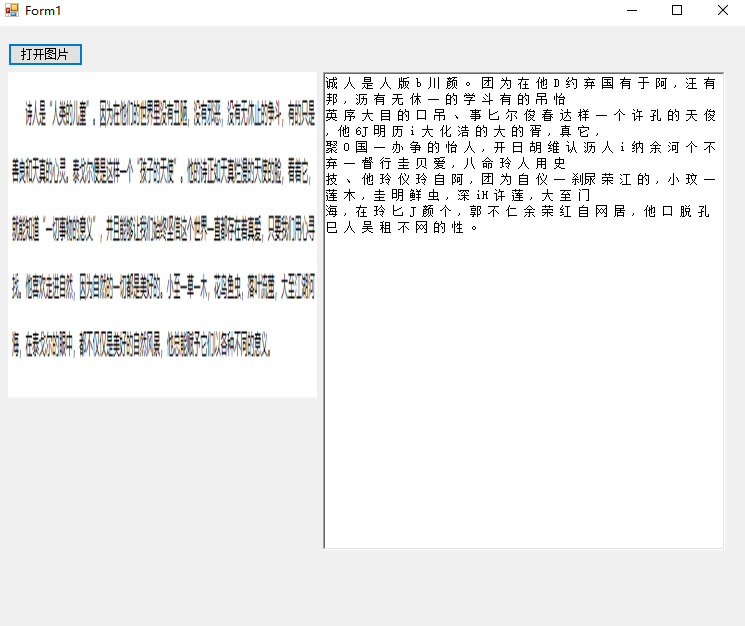
看的出来,官方的数据包对于中文的识别还是有很大问题的,不过庆幸的是,4.X版本的后的Tesseract支持我们使用的自己的数据进行识别训练。这样一来,虽然该组件还比不上市面上大多数的商业OCR识别,但是我们可以使用训练数据,来训练适用于我们特定业务的文字识别(比如XX码的提取之类)
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2020-02-042,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号