苹果“套娃”式扩散模型,训练步数减少七成!


克雷西 发自 凹非寺 量子位 | 公众号 QbitAI
苹果的一项最新研究,大幅提高了扩散模型在高分辨率图像上性能。
利用这种方法,同样分辨率的图像,训练步数减少了超过七成。
在1024×1024的分辨率下,图片画质直接拉满,细节都清晰可见。

苹果把这项成果命名为MDM,DM就是扩散模型(Diffusion Model)的缩写,而第一个M则代表了套娃(Matryoshka)。
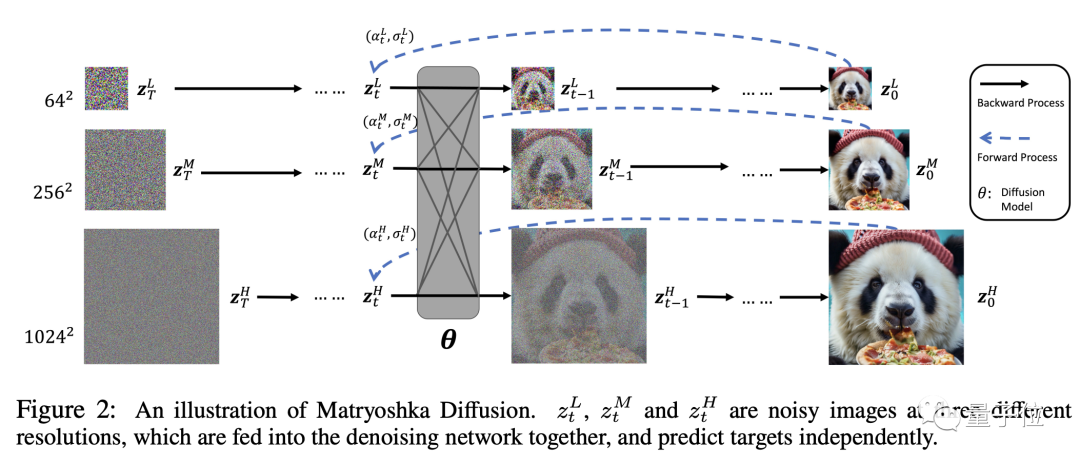
就像真的套娃一样,MDM在高分辨率过程中嵌套了低分辨率过程,而且是多层嵌套。
高低分辨率扩散过程同时进行,极大降低了传统扩散模型在高分辨率过程中的资源消耗。

对于256×256分辨率的图像,在批大小(batch size)为1024的环境下,传统扩散模型需要训练150万步,而MDM仅需39万,减少了超七成。
另外,MDM采用了端到端训练,不依赖特定数据集和预训练模型,在提速的同时依然保证了生成质量,而且使用灵活。

不仅可以画出高分辨率的图像,还能合成16×256²的视频。

有网友评论到,苹果终于把文本连接到图像中了。
那么,MDM的“套娃”技术,具体是怎么做的呢?
整体与渐进相结合
在开始训练之前,需要将数据进行预处理,高分辨率的图像会用一定算法重新采样,得到不同分辨率的版本。
然后就是利用这些不同分辨率的数据进行联合UNet建模,小UNet处理低分辨率,并嵌套进处理高分辨率的大UNet。
通过跨分辨率的连接,不同大小的UNet之间可以共用特征和参数。

MDM的训练则是一个循序渐进的过程。
虽然建模是联合进行的,但训练过程并不会一开始就针对高分辨率进行,而是从低分辨率开始逐步扩大。
这样做可以避免庞大的运算量,还可以让低分辨率UNet的预训练可以加速高分辨率训练过程。
训练过程中会逐步将更高分辨率的训练数据加入总体过程中,让模型适应渐进增长的分辨率,平滑过渡到最终的高分辨率过程。
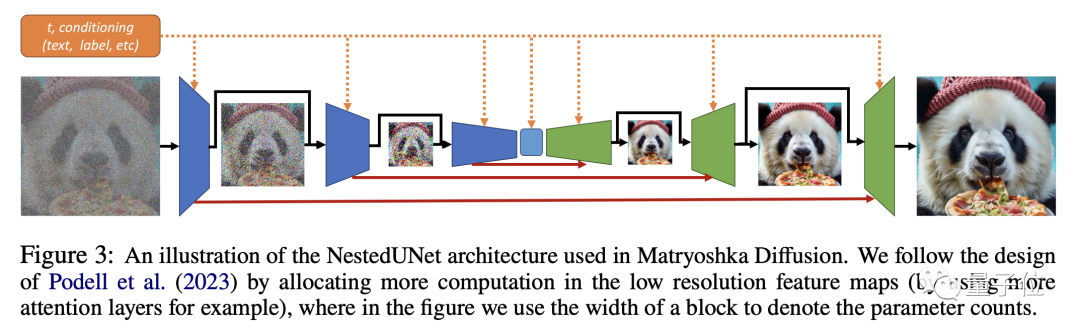
不过从整体上看,在高分辨率过程逐步加入之后,MDM的训练依旧是端到端的联合过程。
在不同分辨率的联合训练当中,多个分辨率上的损失函数一起参与参数更新,避免了多阶段训练带来的误差累积。
每个分辨率都有对应的数据项的重建损失,不同分辨率的损失被加权合并,其中为保证生成质量,低分辨率损失权重较大。
在推理阶段,MDM采用的同样是并行与渐进相结合的策略。
此外,MDM利还采用了预训练的图像分类模型(CFG)来引导生成样本向更合理的方向优化,并为低分辨率的样本添加噪声,使其更贴近高分辨率样本的分布。
那么,MDM的效果究竟如何呢?
更少参数匹敌SOTA
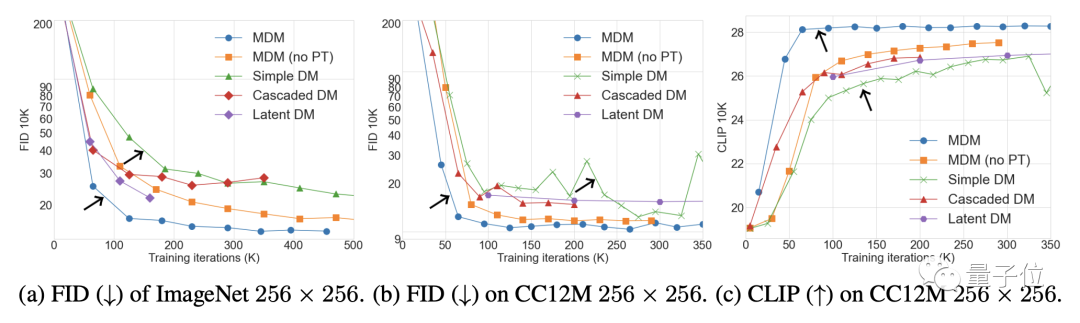
图像方面,在ImageNet和CC12M数据集上,MDM的FID(数值越低效果越好)和CLIP表现都显著优于普通扩散模型。
其中FID用于评价图像本身的质量,CLIP则说明了图像和文本指令之间的匹配程度。
和DALL E、IMAGEN等SOTA模型相比,MDM的表现也很接近,但MDM的训练参数远少于这些模型。
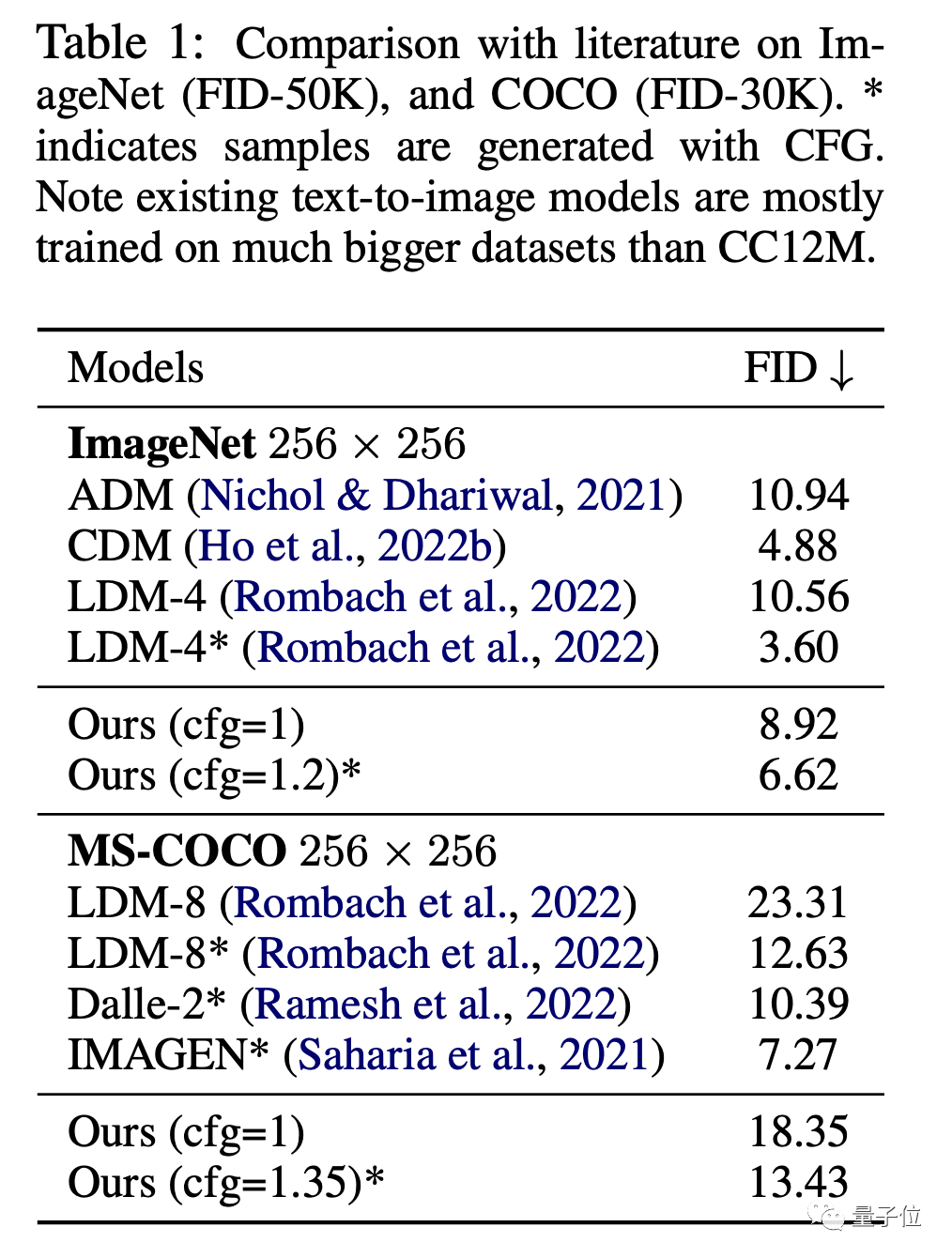
不仅是优于普通扩散模型,MDM的表现也超过了其他级联扩散模型。

消融实验结果表明,低分辨率训练的步数越多,MDM效果增强就越明显;另一方面,嵌套层级越多,取得相同的CLIP得分需要的训练步数就越少。
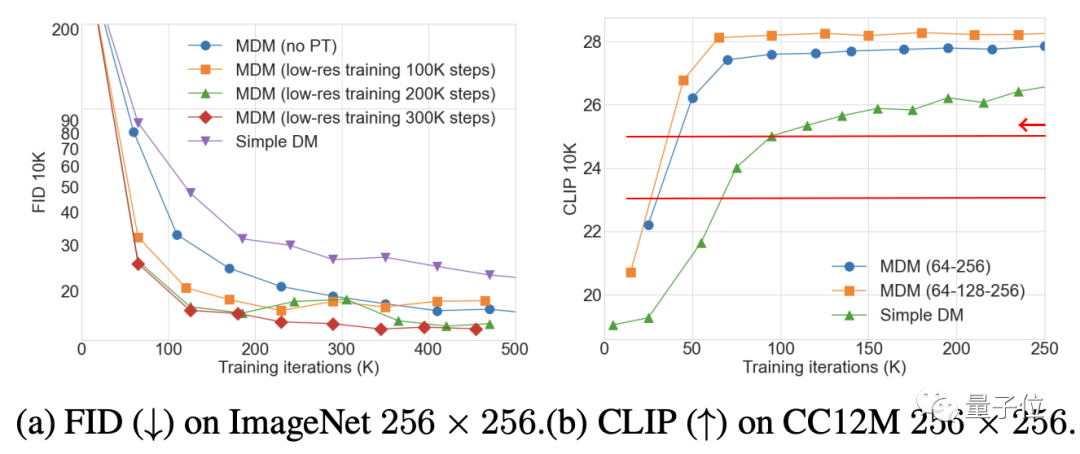
而关于CFG参数的选择,则是一个多次测试后再FID和CLIP之间权衡的结果(CLIP得分高相对于CFG强度增大)。

论文地址: https://arxiv.org/abs/2310.15111
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号