数据库简史:多主数据库架构的由来和华为参天引擎的机遇


注:本文发表后,收到了很多后台反馈,其中关于大型机的早期成就不容省略。微调重发本文,纯属个人观点,错谬之处,仍然期待指正。
2023年10月13日,在北京举办的“2023金融业数据库技术大会"上,有一个非常重要的计划低调地发起了。这就是"北京金融信息化研究所"联合了华为、阿里巴巴、达梦、云和恩墨等企业共同启动的“金融多主数据库应用行动计划”。

“多主数据库”这么拗口的一个词,粗暴的翻译过来就是Oracle RAC集群,其典型特征是以多个计算节点、并发读写位于共享存储的集中式数据库。
这个计划,隐秘地将集中式和分布式数据库之争再次提上议题。
这个问题还有争议吗?是的,还有。而且由来已久,从未改变。
让我们简要的回顾一下数据库的历史。
【历史回眸】
话说天下大势,分久必合,合久必分,分分合合本是常态。在计算机领域、数据库领域,分分合合也自然而然。
大型机是合,小型机是分,集中式是合,分布式是分。在早期的计算机市场上,IBM的大型机(mainframe)占据主导地位,自其20世纪60年代发明后,凭借超强的计算和I/O处理能力,以及在稳定性和安全性方面的卓越表现,引领了计算机行业以及商业计算领域的发展。
由于大型机具备极高的可靠性和可用性、超强的计算能力,早期的IT系统进入了集中式处理阶段。应用系统、中间件、数据库等资源往往集中在一台服务器上。
可是大型机的昂贵价格让大多数用户望而却步,所以小型机和PC机开始次第出现。DEC是这一时期的明星企业,它快速发展成为当时仅次于IBM的计算机制造商。
当小型机和微型机出现时,单机的处理能力就显得不足起来,如何扩展数据库的能力也就成为了非常早期的挑战。
解决方案也毫不意外,就是两个方向,一个是分布式,一个是共享存储集群,一个是Scale-Out,一个是Scale-Up,和我们今天讨论的毫无二致。
1979年,美国计算机公司就在DEC计算机上就实现了世界上第一个分布式数据库系统SDD-1。随后,IBM在System R的基础上研制了分布式数据库R* ,加州大学伯克利分校开发了“分布式Ingres”等。分布式数据库从来不是一个时髦的新词汇,在数据库历史上的探索是非常早的。
但是分布式数据库的问题也非常突出,这个我们后面再讲。
另外一个方向,就是共享存储集群。在这个领域,早期操作系统起了关键作用。DEC 最早在操作系统层提供了集群解决方案,其在1983年发布的VAXcluster提供了卓越的系统级集群解决方案,这一技术通过操作系统来解决并发锁竞争等分布式系统核心问题。后来DEC推出的Rdb在集群方面也具备极大的领先性,当然后来DEC经营不善,于1994年将Rdb卖给了Oracle公司。
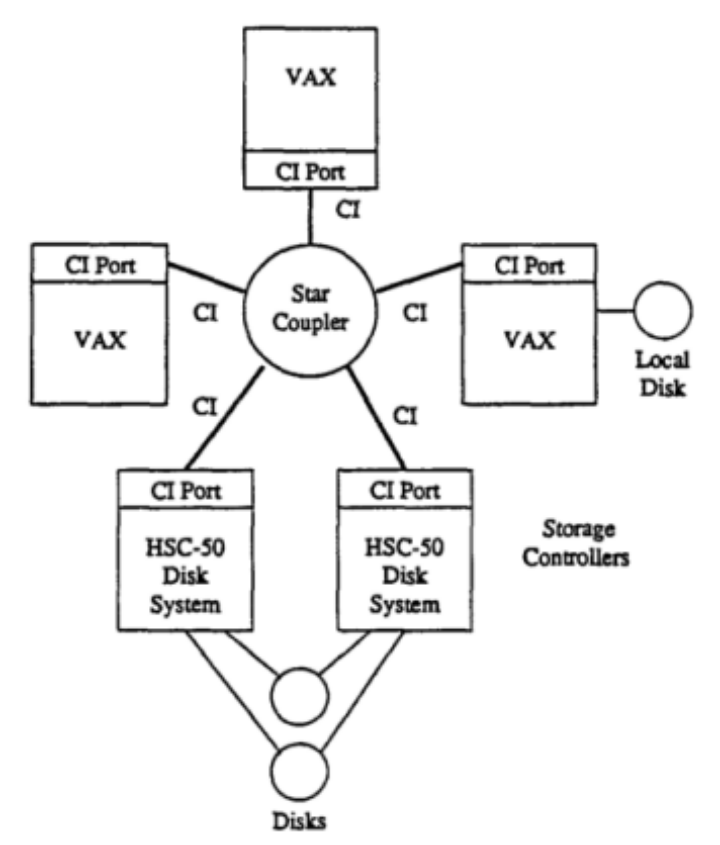
VAXcluster 集群在当时要依赖DEC生产的硬件,包括专用电缆和星形耦合器。下图是从历史文档中截取出来的,集群中的每个节点和存储设备都通过一对或两对CI电缆连接到中央的Star Coupler。每对电缆的传输速率为70 Mb/s,这在当时是很高的速度。VAXcluster是第一个取得商业成功的集群系统。当时对这套架构的一个负面声音是,需要专用硬件,架构复杂。
可是我们用今天的视角来看,如果将其中的Star Coupler换成一个InfiniBand 交换机,这不就是一套数据库一体机吗?
当时DEC的RDB运行在VAXcluster上,就是一套完美的架构组合,和后来的Oracle RAC集群几乎一模一样。
其实,在分布式这条路上,图灵奖获得者 Jim Gray 是一个全程参与者,他从IBM到天腾,就曾经实现了非常著名的Non-Stop SQL分布式架构,因其线性扩展能力而著称。那早在1987年。后来,Jim Gray 去了DEC,从DEC辗转到了微软,参与了SQL Server的重构。
【Oracle的抉择】
好了,问题开始摆在了Oracle创始人Larry Ellision的面前,时间已经来到了1998年,这时候Oracle 8i已经发布。并且在此之前,Oracle已经探索了一项共享存储集群技术,那时候称为并行服务器(Oracle Parallel Server,OPS)技术。这一架构能够在 DEC 的集群之上工作,但是在OLTP场景下性能并不理想。
是坚持没有先例的共享存储集群技术,还是跟随当时热门的Shared Nothing 分布式架构,2b or not 2b,这是一个问题。
事有不决问老板。Larry Ellision 开始拍脑袋。他认为,虽然看起来分布式架构是一个安全的方向、热点、大家都在跟风,但是事实证明,除了数据仓库工作负载外,无共享数据库集群从未在成熟的应用套件上成功运行过,SAP R3 和Oracle EBS等应用都无法适应新的架构,让用户从头来过无法被接受。埃里森拍板继续搞集群。这一版本在2001年Oracle版本9i中发布,埃里森将其命名为 "真正应用集群"(Real Application Cluster - RAC),意思是众人皆假,唯我独真。
当然,这一决策也不是凭空拍脑袋,当时Oracle的一个技术专家罗杰•班福德已经提出了一个突破性的设计方案- "高速缓存融合"(Cache Fusion)技术(关于这些历史故事,我在新书《数据库简史》中做了详细的介绍)。最后的事实证明,这一次开创性的冒险,Oracle是赌对了。

同志们,大家可以看一下,20多年的问题和今天是否有差别?我认为是没有的。让应用适应数据库,还是数据库适应应用?每个人心中自有答案。当然我们必须致敬华为,Meta ERP 以一己之力、行业协同,彻底解开自身在特定历史时期所面临的这一难题。
那么 Oracle 是怎么彻底解开这一 RAC 集群路线上的难题的?
那就是将 VAXcluster 写到数据库里去。卧榻之侧,岂容他人鼾睡。
大家都知道,Oracle从 8 就开始做 DLM(分布式锁管理器),而这一技术的鼻祖是DEC。Distributed Lock Manager 最早就是 OpenVMS 集群软件中负责管理节点访问共享资源的组件。1982 年,在 VAX/VMS V3.0 中就出现了第一个用于单机系统的锁管理器,它为驻留在单个处理器上的多个进程提供同步服务,并能消除死锁。分布式锁管理器由 Steve Beckhardt 设计,于 1984 年随 VAX/VMS V4.0 一起发布。
Oracle RAC管理员非常熟悉的 Resource Manager、Lock Remastering 等都是 VAX 集群里首创的术语。以下这段VaxCluster手册中的描述放到今天的数据库手册中也毫无问题:
锁管理器的实现是为了将锁管理的开销分散到整个集群中,同时还能将执行锁服务所需的节点间流量最小化。因此,内部数据库分为两部分:资源锁描述和资源锁目录系统,这两部分都是分布式的。
每个资源都有一个主节点,负责授予该资源的锁;主节点维护一个已授予锁的列表和一个该资源的等待请求队列。对一棵树的所有操作而言,主节点就是对根节点提出锁请求的节点。当主节点维护其资源树的锁数据时,任何对另一个节点掌握的资源持有锁的节点都会维护自己的资源和锁描述副本。
资源目录系统将资源名称映射为该资源的主节点名称。目录数据库分布在愿意分担这一开销的节点之间。给定一个资源名称,节点就可以根据名称字符串和目录节点数量的函数,轻松计算出所负责的目录。
当然除了 DEC 之外,早期的 Veritas 也通过集群软件和 Oracle RAC 紧密连接,而且售价相当可观,几乎和数据库相当。
但是,当Oracle将Cluster“写入数据库”之后,这些软件和数据库的连接都被切断了,也再未对数据库产生如早期般的深远影响。
由于在数据库领域,几乎只有Oracle在坚定的走向共享存储集群的路线,第三方集群件在数据库领域从此声名不显。
说完了Oracle和DEC的故事,再来看看IBM。IBM是蓝色巨人,在所有技术栈上几乎都有多套解决方案。在集群这一方向上,IBM的大型机也形成了深厚的技术积累。
IBM 最早于1990年提出Systems Complex(也即SysPlex)概念,1994年提出Parallel Sysplex概念,并行系统耦合体是大型机最具代表性的集群技术。可以将一台或多台机器组成Sysplex,用于跨系统的通信联络,最多支持32个LPAR资源共享的读/写。同时提出的还有CF,即Coupling Facility - 耦合装置,CF是一种支持共享对象的技术。在DB2集群中,CF提供了一个集中化设备来管理锁,并且还充当脏页(dirty page)的全局共享缓冲池,从而有助于实现可伸缩性和可恢复性操作。
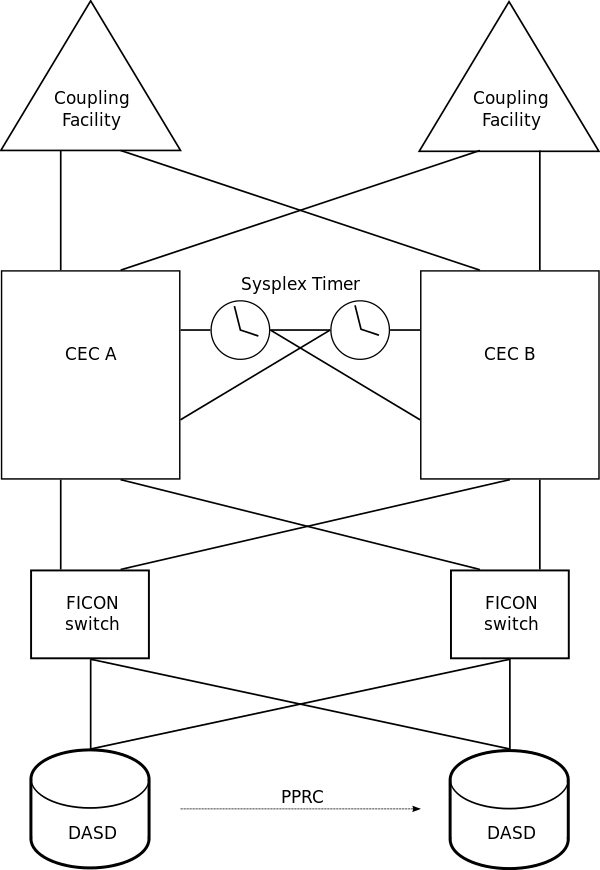
C.Mohan 等人在1997年发表的论文中,详细的介绍了IBM基于共享数据的集群设计,以及Coupling Facility在其中所发挥的关键作用。

这些技术后来被下放到小型机中,2009年,DB2推出了基于小型机的pureScale集群,但是没有取得像Oracle RAC那样的成功。
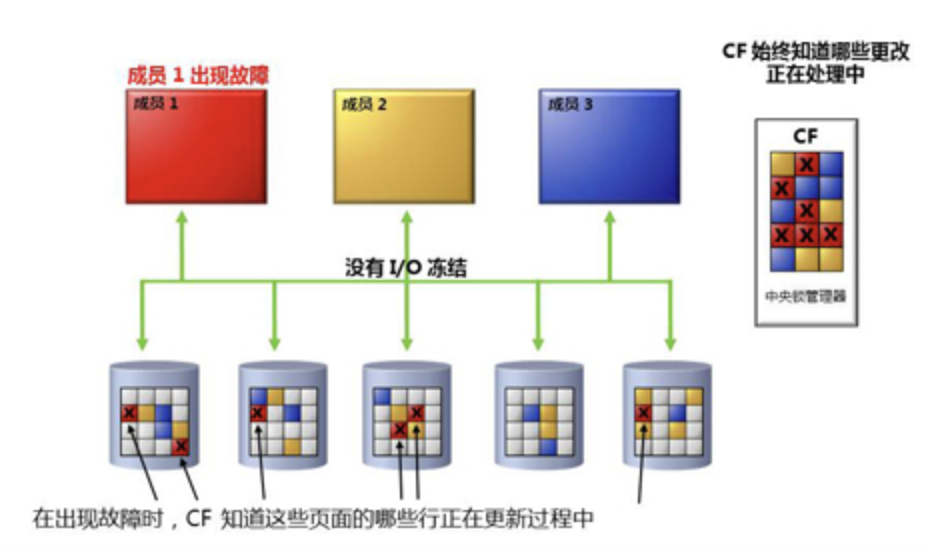
在pureScale的架构下,因为CF(被重新释意为Caching Facility)的存在,在集群成员节点故障时,不需要进行资源目录的冻结,这是优势;但是CF存在单点,也需要进行高可用保护,客观上也增加了集群的复杂性。
【上下求索】
前面的数据库历程,我们见证了系统软件的集群时代,数据库一体化的时代,最后,Oracle RAC集群占据了主流,并囊括了集群件的全部能力。
可是历史总在轮回,数据库的问题,不一定都要在数据库中解决。在中国数据库,尤其是分布式蓬勃发展的过程中,我们注意到,在数据库外部,有两大解决方案体系逐渐形成。
一者,是在数据库上部,通过数据库中间件解决分布式问题,二者,在数据库底层,通过共享存储集群件,提供数据库共享存储集群能力。
分布式中间件领域,Sharding-Sphere 和 MyCat 都是不同时期典型的代表。例如 MogDB 结合 Sharding-Sphere也能打造数千万 tpmC的分布式架构。以下这个架构被称为 MogDB Clowder。

可是中国数据库行业呈现出的另外一个趋势是:将“Sharding-Sphere"写到数据库里。历史再次重演了,当分库分表、路由、中间件等能力,被数据库一体化集成进去,这些产品将在企业级应用消失了,开源领域还会在,但是商业价值的探索将更加困难。
我们再来看看多主数据库的核心 - 共享存储集群件。在这个领域,中国此前没有探索者。一个是因为技术难度较大,一个是因为数据库领域没有需求。中国数据库厂商将注意力聚焦在分布式架构上。
然而峰回路转,涛声依旧。在“金融业数据库技术大会”上成立的“金融多主数据库应用行动计划”证明,金融客户对多主集群仍然存在强烈的需求。
那么答案在哪里呢?
华为公司近期开源了一个产品:Cantian引擎。取义要扎根深远,长成参天大树之意。
参天起到的作用就是将过去中国数据库领域缺少的一环补齐,通过系统级的集群能力,可以帮助以单机性能见长的数据库,形成共享集群解决方案,同时将可靠性和性能久经验证的企业级存储产品 OceanStor Dorado 引入作为共享存储。
可以一举解决金融行业数据库国产化替代难的症结。当前,云和恩墨 MogDB 和 openGauss 都在加速适配参天存储引擎,这次过程数据库厂商参与建立的同盟,就是在这一方向上共识的体现。

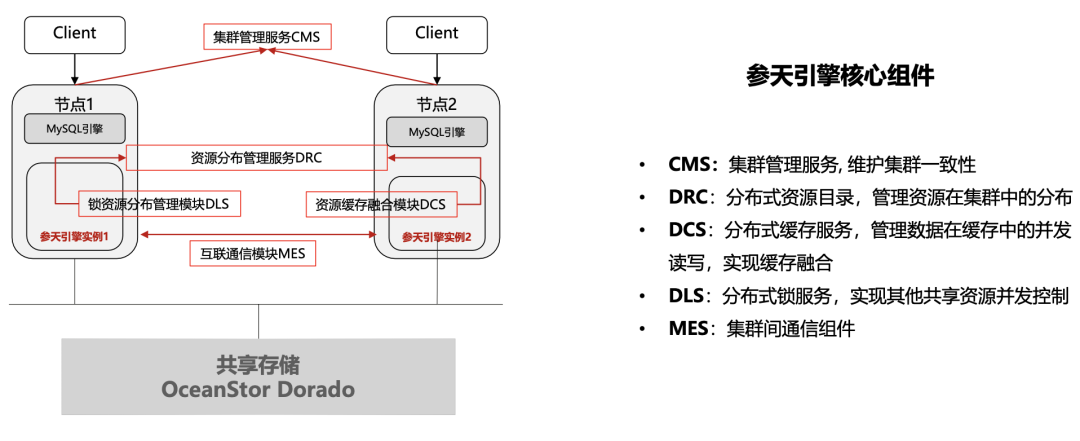
参天引擎包含五大核心组件,分别是 CMS,负责集群管理服务,维护集群一致性;DRC,分布式资源目录,管理资源在集群中的分布;DCS,分布式缓存服务;DLS,分布式锁服务;MES,集群间通信服务。
通过有限的资料,可以看到,参天读写的Cache Fusion行为和Oracle基本保持一致。在下图展示的流程中(数据页位于内存中),如果在双实例中,实际上产生了一次 GC CR Block 2-way 的Cache Fusion读请求。

被数据库吞噬的,还可以再独立出来。今天参天的尝试,通过开源,将成果行业共享,这样能够实现社会价值最大化,更能够助力中国数据库集体向前跃迁一大步。
参天引擎已经在 openEuler 社区开源,从个人角度,我期待看到更多的中国数据库和参天适配,重新探索“共享存储集群”在中国数据库产业中应有的地位,更好的支撑企业级用户对数据库的多样化架构需求。
云和恩墨已经投身其中,也期待对此有兴趣的客户,和我们一起探讨 MogDB 和 openGauss 的共享存储集群解决方案!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号