Yolov8轻量化改进:Ghostnet、G_ghost、Ghostnetv2家族大作战(二):华为Ghostnetv2,端侧小模型性能新SOTA
原创
Yolov8轻量化改进:Ghostnet、G_ghost、Ghostnetv2家族大作战(二):华为Ghostnetv2,端侧小模型性能新SOTA
原创
AI小怪兽
修改于 2023-11-02 15:05:14
修改于 2023-11-02 15:05:14
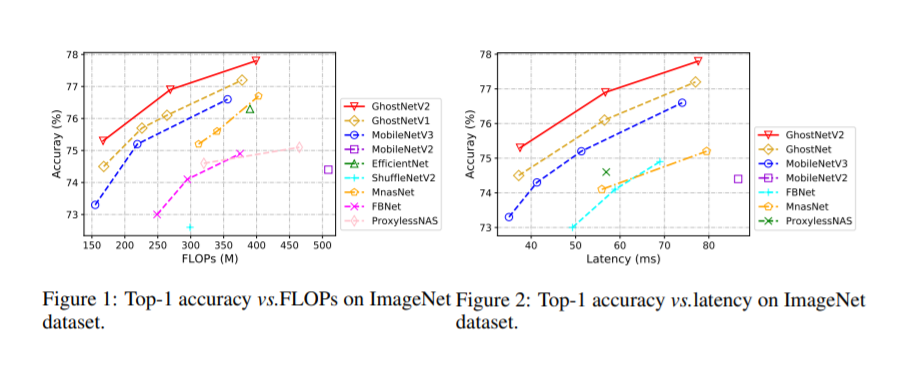
1.Ghostnet、G_ghost、Ghostnetv2性能比较
引入到yolov8,Bottleneck与c2f结合,代替backbone中的所有c2f。
layers | parameters | GFLOPs | kb | |
|---|---|---|---|---|
YOLOv8s | 168 | 11125971 | 28.4 | 21991 |
YOLOv8_C2f_GhostBottleneckV2s | 279 | 2553539 | 6.8 | 5250 |
YOLOv8_C2f_GhostBottlenecks | 267 | 2553539 | 6.8 | 5248 |
YOLOv8_C2f_g_ghostBottlenecks | 195 | 2581091 | 6.9 | 5283 |
2.Ghostnet介绍

论文:https://arxiv.org/pdf/2211.12905.pdf
尽管 Ghost 模块可以大幅度地减少计算代价,但是其特征的表征能力也因为 "卷积操作只能建模一个窗口内的局部信息" 而被削弱了。在 GhostNet 中,一半的特征的空间信息被廉价操作 (3×3 Depth-wise Convolution) 所捕获,其余的特征只是由 1×1 的 Point-wise 卷积得到的,与其他像素没有任何信息上的交流。捕捉空间信息的能力很弱,这可能会妨碍性能的进一步提高。本文介绍的工作 GhostNetV2 是 GhostNet 的增强版本,被 NeurIPS 2022 接收为 Spotlight。
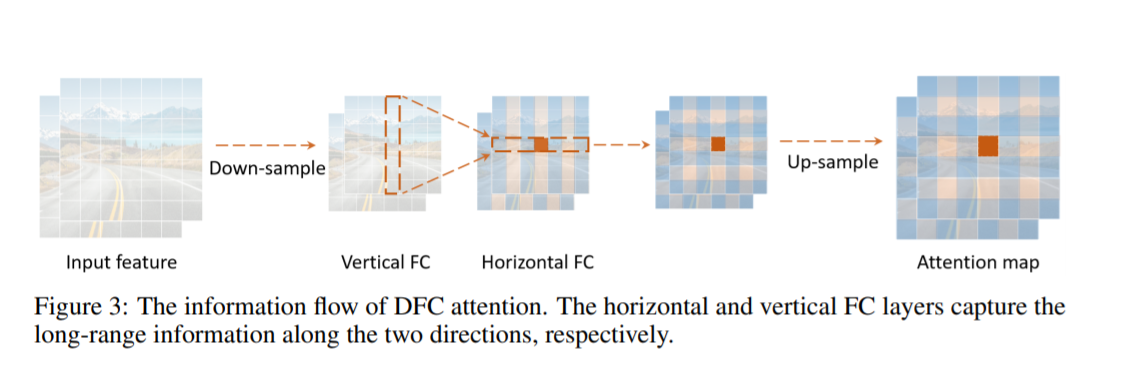
DFC Attention: 基于解耦全连接层的注意力模块
一个适用于端侧小模型的注意力模块应当满足3个条件:
- 对长距离空间信息的建模能力强。相比CNN,Transformer性能强大的一个重要原因是它能够建模全局空间信息,因此新的注意力模块也应当能捕捉空间长距离信息。
- 部署高效。注意力模块应该硬件友好,计算高效,以免拖慢推理速度,特别是不应包含硬件不友好的操作。
- 概念简单。为了保证注意力模块的泛化能力,这个模块的设计应当越简单越好。
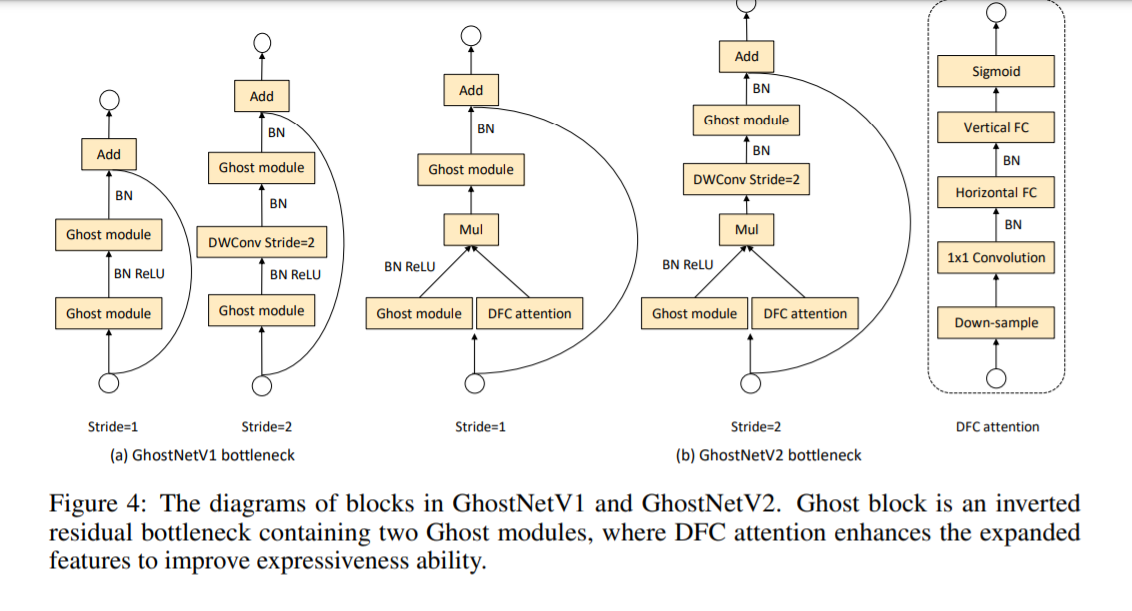
如下图4所示是 GhostV2 bottleneck 的示意图,DFC 注意力分支与第一个 Ghost 模块并行,以增强扩展的特征。然后,增强后的特征被输入到第二个 Ghost 模块,以产生输出特征。它捕捉到了不同空间位置的像素之间的长距离依赖性,增强了模型的表达能力。
3.Yolov8引入Ghostnetv2
3.1 加入ultralytics/nn/backbone/ghostnetv2.py
核心代码
class GhostModuleV2(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True, mode=None, args=None):
super(GhostModuleV2, self).__init__()
self.mode = mode
self.gate_fn = nn.Sigmoid()
if self.mode in ['original']:
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels * (ratio - 1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size // 2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
elif self.mode in ['attn']:
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels * (ratio - 1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size // 2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.short_conv = nn.Sequential(
nn.Conv2d(inp, oup, kernel_size, stride, kernel_size // 2, bias=False),
nn.BatchNorm2d(oup),
nn.Conv2d(oup, oup, kernel_size=(1, 5), stride=1, padding=(0, 2), groups=oup, bias=False),
nn.BatchNorm2d(oup),
nn.Conv2d(oup, oup, kernel_size=(5, 1), stride=1, padding=(2, 0), groups=oup, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.mode in ['original']:
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1, x2], dim=1)
return out[:, :self.oup, :, :]
elif self.mode in ['attn']:
res = self.short_conv(F.avg_pool2d(x, kernel_size=2, stride=2))
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1, x2], dim=1)
return out[:, :self.oup, :, :] * F.interpolate(self.gate_fn(res), size=(out.shape[-2], out.shape[-1]),
mode='nearest')详见:
https://cv2023.blog.csdn.net/article/details/131300994
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号