Linux crash分析简明参考
原创
Linux crash分析简明参考
原创
dinghailong
发布于 2023-12-03 22:14:32
发布于 2023-12-03 22:14:32
1 背景
Linux操作系统在作为服务器的场景下应用最为广泛,但是在使用过程中也会遇到莫名崩溃的情况.这时我们就希望能对崩溃前一刻内存中的数据进行分析,从而找到崩溃的原因.本文将对整个过程所涉及到的技术做一个简单但是全面的介绍,包括:如何安装kdump,如何设置系统参数来捕获崩溃前的内存;如何使用crash做简单的分析;并且介绍如何使用更加简便的工具PyKdump来做crash文件的分析.通过了解这些知识, 可以帮助Linux运维人员更快更方便地排查问题.
2 基本步骤
要捕捉到Linux在崩溃前一刻的内存,我们需要安装kdump工具在生产系统上,并进行相应的参数配置.这样当生产系统上发生crash的时候, 操作系统控制权将会转换到kdump上,并由其将崩溃前一刻的内存镜像保存到本地或者远程文件中(根据设置的不同).我们拿到这个文件后,可以将其拷贝到分析机上.分析机的环境包括操作系统的版本,可以与生产系统不同.但是在分析机上,我们要安装上与vmcore所对应的OS版本相同的调试信息文件,也即debuginfo,并安装crash工具来分析vmcore.为了简化分析,我们这里引入了PyKdump插件.整体步骤如下图所示:
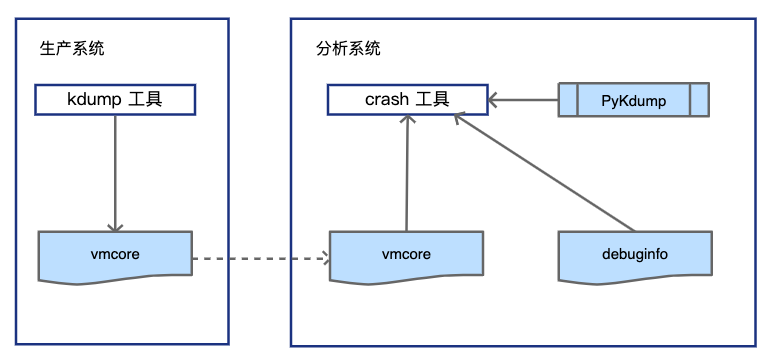
crash基本分析步骤
3 配置kdump工具
kdump的配置是在生产系统的Linux环境中配置的.下面根据操作系统的不同,简单介绍一下如何安装kdump.
3.1 Centos/RHEL/Tlinux 环境下的安装
首先确认当前系统中是否已经安装过kdump.可以运行如下命令确认kdump服务是否已进有了:systemctl status kdump.service.如果没有,则按照如下步骤安装:
1) 安装kexec-tools
执行如下命令:
yum install kexec-tools
2) 设置crashkernel预留内存大小
vim /etc/default/grub
找到“GRUB_CMDLINE_LINUX”这一行,对其中的“crashkernel=256M”进行修改.注意对于内存较大的情况下可以适当增大该值.crash保留的内存OS中将看不到,所以设置一个合理的值即可,通常为128的整数倍.
3) 重新生成grub配置文件
grub2-mkconfig -o /boot/grub2/grub.cfg
4) 重启系统
reboot
5) 修改kdump默认配置
vim /etc/kdump.conf
打开后可以看到主要的配置项如下所示
#指定coredump文件存储位置
path /var/crash
#增加-c参数,代表压缩coredump文件
core_collector makedumpfile -c -l --message-level 1 -d 31
#生成coredump后,重启系统,
default reboot
6) 开启kdump服务
systemctl start kdump.service //启动kdump
systemctl enable kdump.service //设置开机启动
7) 检查kdump是否开启成功
service kdump status
8) 验证kdump功能
注意下面的命令将触发OS重启,并在/var/crash目录下(根据kdump.conf配置)生成一个带有时间的目录,目录下会生成vmcore文件.测试命令如下:
echo 1 > /proc/sys/kernel/sysrq; echo c > /proc/sysrq-trigger
3.2 Ubuntu环境下的安装
Ubuntu从16.04版本开始缺省是安装了kdump的.可以运行如下命令查看是否安装了: kdump-config show.如果没有安装,可以参考如下步骤:
1) 安装kdump工具
sudo apt install linux-crashdump
安装过程中会有一些选项要你确认.
2) 修改配置文件
修改 /etc/default/kexec,设置LOAD_KEXEC=true
修改/etc/default/kdump-tools,设置USE_KDUMP=1
3) 验证kdump功能
运行如下测试命令验证,同样需要注意的是这将触发重启.
sudo sysctl -w kernel.sysrq=1; echo c > /proc/sysrq-trigger
3.3 配置参数
Kdump安装完成后,不确保每次都能生成vmcore文件,还需要检查Linux参数配置情况,这时可以用sysctl查看参数.
例如: sysctl –a | grep kernel.hung_task_panic
一般如果softlock导致的系统hung死没生成vmcore的话建议做如下配置:
echo "kernel.watchdog_thresh = 30" >>/etc/sysctl.conf
echo "kernel.softlockup_panic = 1" >>/etc/sysctl.conf
echo "kernel.watchdog = 1" >>/etc/sysctl.conf
sysctl -p
如果是D状态进程导致的机器长时间hung住而不响应,这种情况需要做如下配置:
echo "kernel.hung_task_panic = 1" >>/etc/sysctl.conf
sysctl -p
当出现hung住的情况但是没有自动重启并生成vmcore文件,这种情况建议客户保留当前状态,提单给后台.腾讯云平台软件可以通过给CVM发送命令触发panic尝试生成coredump.但是在这种情况下,需要确保sysrq配置是打开的.可以运行如下命令设置:
echo "kernel.sysrq=1" >>/etc/sysctl.conf
sysctl -p
需要说明的是,裸金属产品客户独占硬件资源,无法通过后台触发panic.
4 使用crash工具分析
4.1 安装crash工具
为了不影响生产系统的运行,通常我们会将生成的vmcore文件拷贝到用于分析的Linux系统上去分析.分析工具通常采用crash工具.CentOS下可以通过如下命令安装: yum install crash.也可以通过编译源代码安装,步骤参考如下:
首先是下载crash压缩包,地址如下:
https://github.com/crash-utility/crash/releases
解压文件:
tar -xvf ./crash-7.3.2.tar.gz
编译:
cd ./crash-7.3.2
make
make install
crash依赖于gdb,在安装的过程中会自动下载对应版本的gdb进行安装.有了crash工具后,我们要做的第一步就是确定vmcore中OS所用的内核具体的版本号.可以运行如下命令查询:
crash –osrelease ./vmcore
比如说我们这里返回了:4.18.0-305.10.2.el8_4.x86_64
这里“el8”表示OS是CentOS8, “4.18.0-305.10.2”是具体的版本号.
下面我们需要找到对应的debug信息才能解析vmcore文件.
4.2 Debug文件来源
1) CentOS
CentOS debug 文件的位置在这里:
http://debuginfo.centos.org/
其中CentOS 7的位置在这里:
http://debuginfo.centos.org/7/x86_64/
其中CentOS 8的位置在这里:
http://debuginfo.centos.org/8/x86_64/Packages/
2) Ubuntu
Ubuntu的debug文件可以从这里找到:
http://ddebs.ubuntu.com/pool/main/l/linux/
3) Tlinux
Tlinux的debug文件在这里:
https://mirrors.tencent.com/tlinux/
其中2.4版本的在这里:
https://mirrors.tencent.com/tlinux/2.4/tlinux-tkernel4/debuginfo/x86_64/RPMS/
4.0版本的在这里:
https://mirrors.tencent.com/tlinux/4.0/BaseOS/x86_64/debug/tree/Packages/
4.3 安装Debuginfo文件
以前面的例子“4.18.0-305.10.2.el8_4.x86_64”版本为例,这里需要安装2个软件包.分别为:kernel-debuginfo-common-x86_64-4.18.0-305.10.2.el8_4.x86_64.rpm和
kernel-debuginfo-4.18.0-305.10.2.el8_4.x86_64.rpm.
用rpm -ivh *.rpm的命令先安装kernel-debuginfo-common这个软件包,后安装kernel-debuginfo软件包.安装完毕后会有一个vmlinux文件,例如我们这里在如下位置可以找到:
/usr/lib/debug/usr/lib/modules/4.18.0-305.10.2.el8_4.x86_64/vmlinux
将该文件拷贝到与vmcore一起的位置,这样我们就可以解析vmcore文件了.
4.4 Crash常用命令
1) 载入vmcore文件
由于我们已经有了debuginfo,所以可以解析出vmcore文件中的信息.我们采用如下命令装载:
crash ./vmlinux ./vmcore
2) 查看崩溃前的日志
进入crash后,运行log命令可以查看系统崩溃前一刻的输出日志
3) 查看崩溃前堆栈
运行bt命令可以查看崩溃前的堆栈信息
4) 查看崩溃前的内存信息
运行kmem -i,可以查看崩溃前的内存信息
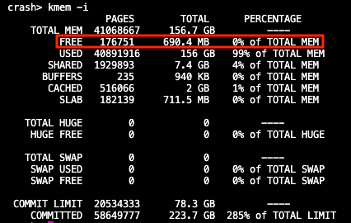
通过上述常用命令,我们可以找到很大一部分的问题,例如:是否内存不足,是否操作系统某个版本的bug等.
5 PyKdump
要用Crash工具做更深入的分析,需要做许多内存地址的转换,并且要对照Linux源代码进行分析,其门槛比较高,新手短时间内很难掌握.还好有PyKdump工具,该工具以python语言编写,集合了常用的vmcore文件分析功能,可以作为crash插件的方式运行,非常易于使用.下面的编译是在CentOS stream最新版本中编译生成.
5.1 安装PyKdump
PyKdump是基于python语言编写,需要与python3.8版本一起编译.其编译步骤如下所示:
1) 安装依赖库
执行如下命令安装编译所需的依赖库以及工具
sudo dnf upgrade
yum install gcc-c++
yum install bison
yum install ncurses-devel
dnf --enablerepo=powertools install texinfo
yum install zip unzip
yum install git
2) 编译python 3.8库
下载并解压 python 3.8
wget https://www.python.org/ftp/python/3.8.18/Python-3.8.18.tgz
tar -xvf ./Python-3.8.18.tgz
下载 pykdump
git clone git://git.code.sf.net/p/pykdump/code pykdump
配置python 3.8
cd ./Python-3.8.18/
./configure CFLAGS=-fPIC --disable-shared
将pykdump/extension下的配置文件拷贝到python目录下用于编译
cd ../pykdump/Extension/
cp ./Setup.local-3.8 ../../Python-3.8.18/Modules/Setup.local
cd ../../Python-3.8.18/
make
编译后将生成python库文件.
3) 编译crash工具
首先下载crash7的压缩包,到如下位置下载:
https://github.com/crash-utility/crash/releases
解压并编译crash
tar -xvf ./crash-7.3.2.tar.gz
cd ./crash-7.3.2
make
编译的过程中会自动下载对应版本 的gdb
4) 编译pykdump
cd ./pykdump/Extension
./configure -p /src/Python/Python-3.8.18 -c /src/crash-7.3.2
make
上述“/src/Python-3.8.18”表示python源代码所在目录;“/src/crash-7.3.2”表示crash源代码所在目录.
编译完成后将得到如下一些动态库,这些库后续可以载入crash,作为插件使用.

编译后得到的pykdump库
5.2 使用PyKdump
首先我们通过如下命令装载vmcore文件分析,命令查看如下:
crash ./vmlinux ./vmcore
打开crash后,我们通过如下命令载入前面编译的PyKdump库:
extend /path/to/lib/mpykdump.so
然后就可以方便地使用PyKdump库中的工具来快速分析vmcore了.
PyKdump有如下几个常用命令
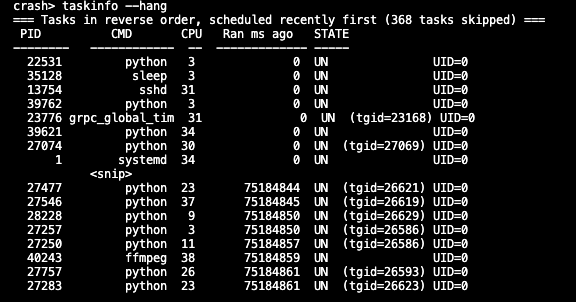
1) 找到hang进程
taskinfo --hang
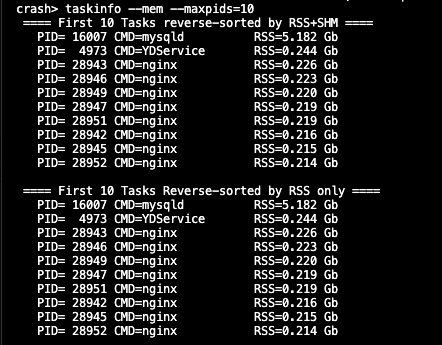
2) 找出进程的内存使用
taskinfo –mem --maxpids=x
3) 显示进程的详细信息
taskinfo --pidinfo=pid_xxx
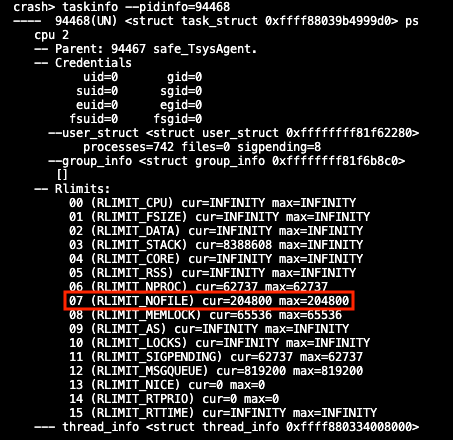
4) 其它常用的命令
打印内存中的路由表信息
xportshow -r
显示进程树
pstree -p
除了上述常用命令外,还可以通过编写python脚本的方式实现自动分析.有兴趣的同学可以继续深入研究下.
6 参考资料
1) Centos7/RHEL7 开启kdump
https://www.cnblogs.com/augusite/p/10613794.html
2) ubuntu下配置kdump
https://ubuntu.com/server/docs/kernel-crash-dump
3) White Paper: Crash Utility
https://crash-utility.github.io/crash_whitepaper.html
4) Red Hat Enterprise Linux 7 Kernel Crash Dump Guide
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/kernel_administration_guide/kernel_crash_dump_guide
5) Crash工具说明
https://crash-utility.github.io/help_pages/irq.html
6) mpykdump
https://pykdump.readthedocs.io/en/latest/index.html
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
作者已关闭评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号