docker实践(7) 容器网络和网络SR-IOV插件


我们去年为了上云,先逐步是使用docker部署,然后逐步k8s部署,为此搭建了docker容器平台,该平台分配ip需要绑定宿主机cvm的弹性网卡,为此专门引入了网络SR-IOV插件,趁此补充完善该文。
一、 容器网络
从容器诞生开始,存储和网络这两个话题就一直为大家津津乐道。我们今天这个环境下讲网络这个问题,其实是因为容器对网络的需求,和传统物理、虚拟环境对网络环境需求是有差别的,主要面临以下两个问题:
- 过去IaaS层在网络方便做了很多工作,已经形成了成熟的环境,如果和容器环境适配,两边都需要做很多改造
- 容器时代提倡微服务,导致容器的粒度之小,离散程度之大,原有IaaS层网络解决方案很难承载如此复杂的需求
1、Docker 容器网络的发展历史
最初的网络
在 Dokcer 发布之初,Docker 是将网络、管理、安全等集成在一起的,其中网络模块可以为容器提供桥接网络、主机网络等简单的网络功能。
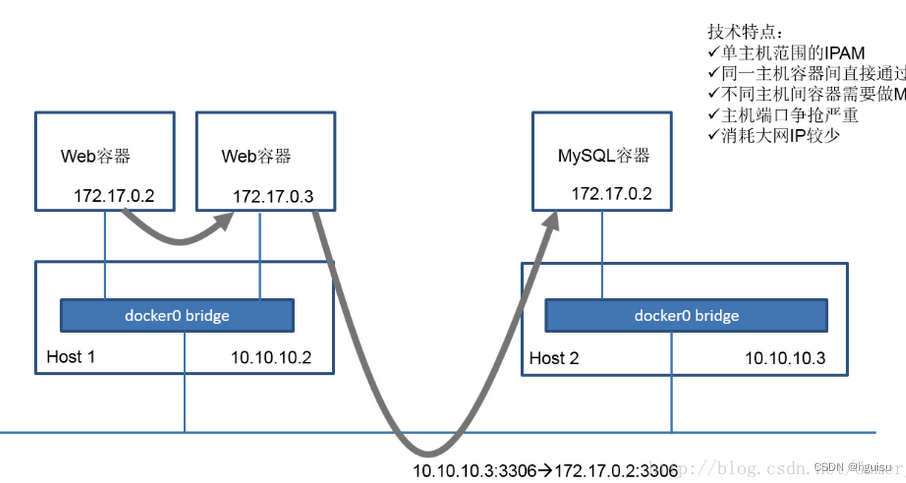
石器时代网络模型,它是Docker1.9之前的容器网络,实现方式是只针对单台主机进行IPAM管理,所有主机上的容器都会连接到主机内部的一个Linux Bridge,叫Docker0,主机的IP它默认会分配172.17网段中的一个IP,因为有Docker0,所以在一个主机上的容器可以实现互联互通。但是因为IP分配的范围是基于单主机的,所以你会发现在其他主机上,也会出现完全相同的IP地址。很明显,这两个地址肯定没办法直接通信。为了解决这个问题,在石器时代我们会用端口映射,实际上就是NAT的方法。比如说我有一个应用,它有Web和Mysql,分别在不同的主机上,Web需要去访问Mysql,我们会把这个Mysql的3306端口映射到主机上的3306这个端口,然后这个服务实际上是去访问主机IP 10.10.10.3 的3306端口,这是过去的石器时代的一个做法。
总结一下它的典型技术特征:基于单主机的IPAM;主机之内容器通讯实际上通过一个docker0的Linux Bridge;如果服务想要暴露到外部的话需要做NAT,会导致端口争抢非常严重;当然它有一个好处,对大网IP消耗比较少。
从 1.7 版本开始
从 1.7 版本开始,Docker正是把网络和存储这两部分的功能都以插件化形式剥离出来,允许用户通过指令来选择不同的后端实现。剥离出来的独立容器网络项目叫 libnetwork。
在此之后,容器的网络接口就成为了一个个可替换的插件模块。由于这次变化进行的十分平顺,作为Docker的使用者几乎不会感觉到其中的差异,然而这个改变为接下来的一系列扩展埋下了很好的伏笔。它遵从为docker提供高内聚,低耦合的软件模块的目标,以组合的方式为容器提供网络支持。
在 1.9 版本时
在 1.9 版本时,Docker 又引入了一整套 network 子命令和跨主机网络支持,这允许用户可以根据他们应用的拓扑结构创建虚拟网络并将容器接入其所对应的网络。
从命令行可以看到新增如下命令:
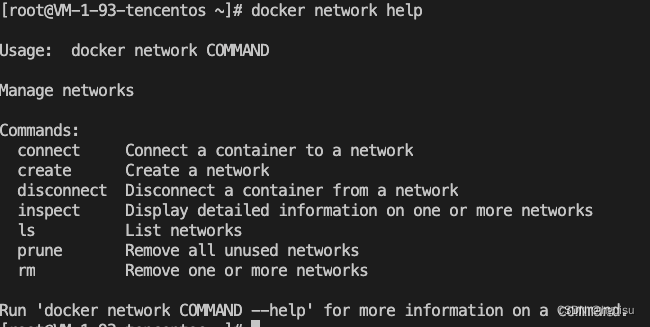
可以看到Docker daemon启动后默认创建了3个网络: 分别使用了bridge、null、host三种内置network driver。

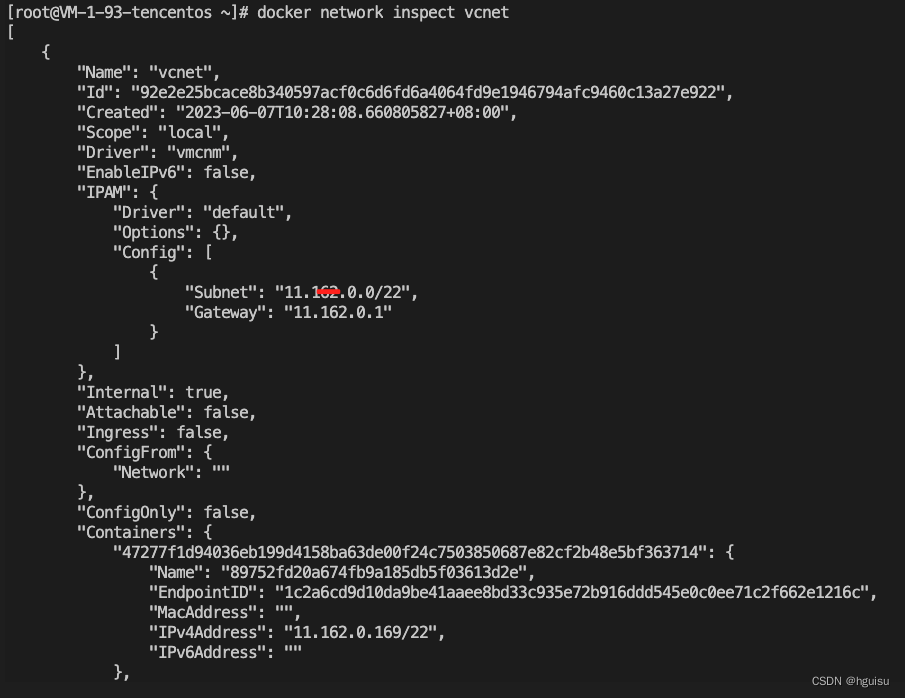
我们来仔细看下三个网络的详细信息:
Id 是network内部的uuid,全局唯一。 Name是network的名字,用户可以随意定义。
Driver是指network driver的名字。 Scope 目前有两个值“local”、“remote”,表示是本机网络还是多机网络。 IPAM是负责IP管理发放的driver名字与配置信息(我们在bridge网络中可以看到该信息)。 Container内记录了使用这个网络的容器的信息。 Options内记录了driver所需的各种配置信息。
2、容器网络接入方案
我们来看下一些主流的容器网络接入方案:
Host network
最简单的网络模型就是让容器共享Host的network namespace,使用宿主机的网络协议栈。这样,不需要额外的配置,容器就可以共享宿主的各种网络资源。
共享物理网卡
这种接入方式主要使用SR-IOV技术,每个容器被分配一个VF,直接通过PCIe网卡与外界通信。SR-IOV 技术是一种基于硬件的虚拟化解决方案,可提高性能和可伸缩性。
SR-IOV 标准允许在虚拟机之间高效共享 PCIe设备,并且它是在硬件中实现的,可以获得能够与本机性能媲美的 I/O 性能。启用了 SR-IOV 并且具有适当的硬件和 OS 支持的 PCIe 设备(例如以太网端口)可以显示为多个单独的物理设备,每个都具有自己的 PCIe 配置空间。
SR-IOV主要用于虚拟化中,当然也可以用于容器:
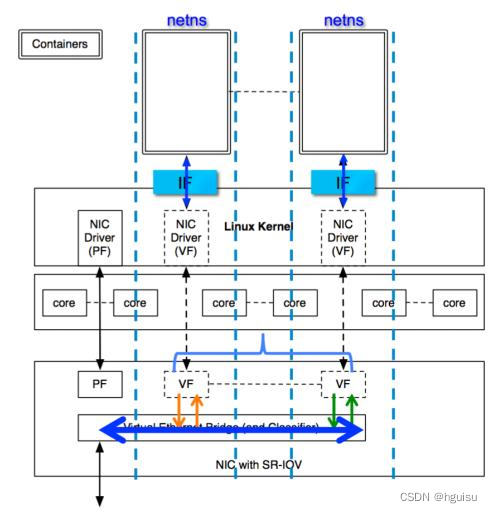
SR-IOV配置(需要网卡支持,线上主流万兆卡Intel 540可以支持128个VF(Virtual Function)):
modprobe ixgbevf lspci -Dvmm|grep -B 1 -A 4 Ethernet
echo 2 > /sys/bus/pci/devices/0000:82:00.0/sriov_numvfs
check ifconfig -a. You should see a number of new interfaces created, starting with “eth”, e.g. eth4
Intel也给Docker实现了一个[SR-IOV network plugin](https://github.com/clearcontainers/sriov 'SR-IOV network plugin'),同样也有相应的[CNI(后面会提到)Plugin](https://github.com/Intel-Corp/sriov-cni'CNI(后面会提到)Plugin')。SR-IOV的接入方式可以达到物理网卡的性能,但是需要硬件支持,而且VF的数量是有限的。
共享容器网络
多个容器共享同一个netns,只需要第一个容器配置网络。比如Kubernetes Pod就是所有容器共享同一个pause容器的网络。
VSwitch/Bridge
容器拥有独立的network namespace,通过veth-pair连接到vswitch或者bridge上。
3、什么是 Docker Libnetwork
为了标准化网络的驱动开发步骤和支持多种网络驱动,Docker 将网络部分代码被抽离成为了单独的网络库(Libnetwork),Libnetwork 提供了可以用于开发多种网络驱动的标准化接口和组件。
libnetwork是docker 在版本1.9中引入的项目,它有一整套的自定义网络命令和跨主机网络支持。
概括来说,libnetwork所做的最核心事情是定义了一组标准的容器网络模型(Container Network Model,简称CNM),只要符合这个模型的网络接口就能被用于容器之间通信,而通信的过程和细节可以完全由网络接口来实现。
Docker daemon 通过调用 Libnetwork 对外提供的 API 完成网络的创建和管理等功能,Libnetwork 内置了5种驱动来提供不同类型的网络: bridge driver, host driver, null driver, overlay driver, remote driver
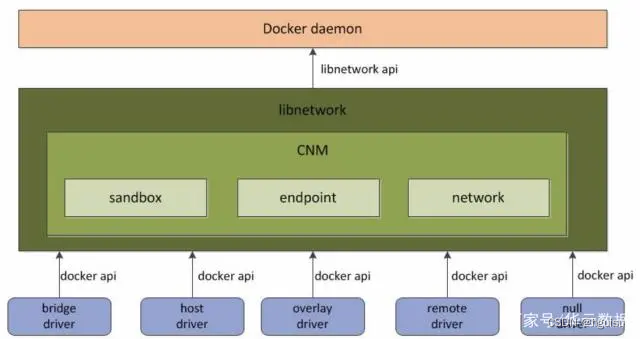
bridge driver
此驱动为Docker的默认设置驱动,使用这个驱动的时候,libnetwork将创建出来的Docker容器连接到Docker网桥上。作为最常规的模式,bridge模式已经可以满足Docker容器最基本的使用需求了。然而其与外界通信使用NAT,增加了通信的复杂性,在复杂场景下使用会有诸多限制。
host driver
使用这种驱动的时候,libnetwork将不为Docker容器创建网络协议栈,即不会创建独立的network namespace。Docker容器中的进程处于宿主机的网络环境中,相当于Docker容器和宿主机共同用一个network namespace,使用宿主机的网卡、IP和端口等信息。
但是,容器其他方面,如文件系统、进程列表等还是和宿主机隔离的。host模式很好地解决了容器与外界通信的地址转换问题,可以直接使用宿主机的IP进行通信,不存在虚拟化网络带来的额外性能负担。但是host驱动也降低了容器与容器之间、容器与宿主机之间网络层面的隔离性,引起网络资源的竞争与冲突。
因此可以认为host驱动适用于对于容器集群规模不大的场景。
null driver(none driver)
使用这种驱动的时候,Docker容器拥有自己的network namespace,但是并不为Docker容器进行任何网络配置。也就是说,这个Docker容器除了network namespace自带的loopback网卡名,没有其他任何网卡、IP、路由等信息,需要用户为Docker容器添加网卡、配置IP等。
这种模式如果不进行特定的配置是无法正常使用的,但是优点也非常明显,它给了用户最大的自由度来自定义容器的网络环境。
overlay driver
此驱动采用IETE标准的VXLAN方式,并且是VXLAN中被普遍认为最适合大规模的云计算虚拟化环境的SDN controller模式。在使用过程中,需要一个额外的配置存储服务,例如Consul、etcd和zookeeper。还需要在启动Docker daemon的时候额外添加参数来指定所使用的配置存储服务地址。
remote Driver
这个驱动实际上并未做真正的网络服务实现,而是调用了用户自行实现的网络驱动插件,使libnetwork实现了驱动的可插件化,更好地满足了用户的多种需求。用户只需要根据libnetwork提供的协议标准,实现其所要求的各个接口并向Docker daemon进行注册。
二、 容器网络模型CNM
容器网络技术日新月异,有些相当复杂,而且提供某种功能的方式也多种多样。这样就给容器runtime与调度系统的实现与各种接入方式的适配带来的很大的困难。为了解决这些问题,Docker与CoreOS相继发布了容器网络标准,便是CNM与CNI,为Linux容器网络提供了统一的接口。
1、CNM模型:
Docker Libnetwork 中使用了 CNM 的容器网络模式概念,CNM定义了构建容器虚拟化网络的模型,此后容器网络模式也被抽象变成了统一接口的驱动。
CNM 中主要有 sandbox、endpoint 和 network 3 种核心组件CNM 中核心组件的使用模型如下图:
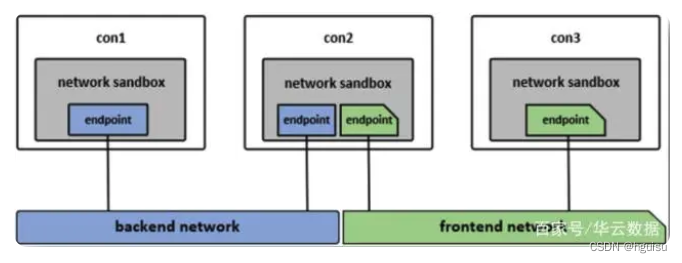
沙盒 (sandbox):一个沙盒包含了一个容器网络栈的信息。沙盒可以对容器的接口(interface)、路由和 DNS 设置等进行管理,沙盒的实现可以是Linux netns、FreeBSD Jail 或者类似的机制,一个沙盒可以有多个端点和多个网络。
端点 (endpoint):一个端点可以加入一个沙盒和一个网络。端点的实现可以是 veth pair、ovs 内部端口或者相似的设备,一个端点只属于一个网络并且只属于一个沙盒。
网络 (network):一个网络是一组可以直接互相联通的端点。网络的实现可以是 Linux bridge、VLAN等,一个网络可以包含多个端点。
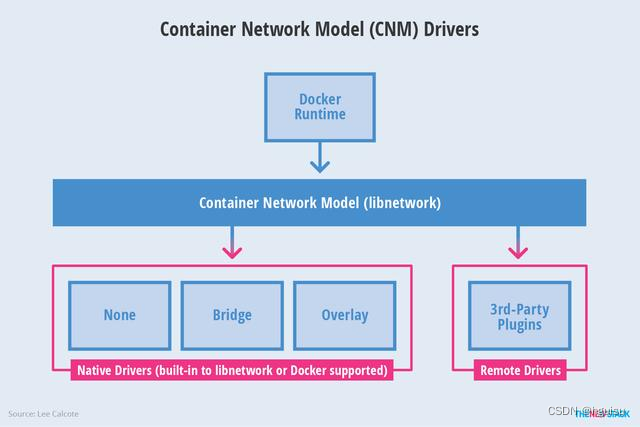
Libnetwork是CNM的原生实现。它为Docker daemon和网络驱动程序之间提供了接口。网络控制器负责将驱动和一个网络进行对接。每个驱动程序负责管理它所拥有的网络以及为该网络提供的各种服务,例如IPAM等等。由多个驱动支撑的多个网络可以同时并存。网络驱动可以按提供方被划分为原生驱动(libnetwork内置的或Docker支持的)或者远程驱动 (第三方插件)。
原生驱动包括 none, bridge, overlay 以及 MACvlan。驱动也可以被按照适用范围被划分为本地(单主机)的和全局的 (多主机)。
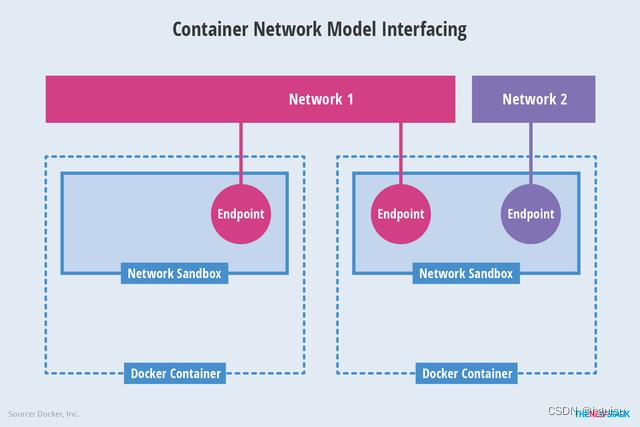
- Sandbox:一个Sandbox对应一个容器的网络栈,能够对该容器的interface、route、dns等参数进行管理。一个Sandbox中可以有多个Endpoint,这些Endpoint可以属于不同的Network。Sandbox的实现可以为linux network namespace、FreeBSD Jail或其他类似的机制。
- Endpoint: Sandbox通过Endpoint接入Network,一个Endpoint只能属于一个Network。Endpoint的实现可以是veth pair、Open vSwitch internal port或者其他类似的设备。
- Network:一个Network由一组Endpoint组成,这些Endpoint彼此间可以直接进行通信,不同的Network间Endpoint的通信彼此隔离。Network的实现可以是linux bridge、Open vSwitch等。
2、CNM创建容器的工作流
我们可以以Docker操作为例,简单看下CNM创建容器的工作流:
- Create Network(docker network create)
- IpamDriver.RequestPool: 创建subnetpool用于分配IP
- IpamDriver.RequestAddress: 为gateway获取IP
- - NetworkDriver.CreateNetwork: 创建network和subnet
- Create Container(docker run / docker network connect)
- IpamDriver.RequestAddress: 为容器获取IP
- NetworkDriver.CreateEndpoint: 创建port
- NetworkDriver.Join: 为容器和port绑定
- NetworkDriver.ProgramExternalConnectivity
- - NetworkDriver.EndpointOperInfo
调用过程
- Create Network
这一系列调用发生在使用docker network create的过程中。
/IpamDriver.RequestPool: 创建subnetpool用于分配IP /IpamDriver.RequestAddress: 为gateway获取IP /NetworkDriver.CreateNetwork: 创建neutron network和subnet
- Create Container
这一系列调用发生在使用docker run,创建一个contain的过程中。当然,也可以通过docker network connect触发。
/IpamDriver.RequestAddress: 为容器获取IP /NetworkDriver.CreateEndpoint: 创建neutron port /NetworkDriver.Join: 为容器和port绑定 /NetworkDriver.ProgramExternalConnectivity: /NetworkDriver.EndpointOperInfo
- Delete Container
这一系列调用发生在使用docker delete,删除一个contain的过程中。当然,也可以通过docker network disconnect触发。
/NetworkDriver.RevokeExternalConnectivity /NetworkDriver.Leave: 容器和port解绑 /NetworkDriver.DeleteEndpoint /IpamDriver.ReleaseAddress: 删除port并释放IP
- Delete Network
这一系列调用发生在使用docker network delete的过程中。
/NetworkDriver.DeleteNetwork: 删除network /IpamDriver.ReleaseAddress: 释放gateway的IP /IpamDriver.ReleasePool: 删除subnetpool
2、Docker 网络的生命周期
Docker 用户可以通过与 CNM 的 Object 以及 API 的交互来管理对应容器的网络,下面是一个典型的容器网络生命周期:
1、Driver要向NetworkController注册。内置的Driver在Libnetwork内注册,远程的Driver则通过Plugin mechanism注册。每一个Driver处理特定的networkType。
2、libnetwork.New():NetworkController通过libnetwork.New()创建,用于Network的创建以及通过一些特定的Options配置Driver。
3、controller.NewNetwork():Network通过给这个API提供name和networkType来创建,networkType参数用来选择特定的Driver并且将创建的Network和该Driver相关联。从此以后,对于Network的任何操作都由Driver处理。controller.NewNetwork() 还有一个可选的options参数,用于提供特定Driver的options和Labels。
4、network.CreateEndpoint():可以用于在给定的Network中创建一个新的Endpoint。同时该API还有一个可选的options参数供Driver使用。这个"options"既可以携带已知的labels,也可以携带和特定Driver相关的labels。之后调用相应的Driver的driver.CreateEndpoint,它可以为在一个Endpoint在Network中被创建时,为它们保留IP地址。Driver会通过driverapi中定义的InterfaceInfo进行这些地址的赋值。IP地址将和endpoint暴露的端口用来完善Endpoint作为Service的定义。事实上,Service endpoint不是其他什么东西,仅仅只是一个网络地址以及该应用的容器监听的端口号。
5、endpoint.Join():用于将Endpoint与一个容器相连接。Join操作会先创建一个Sandbox如果对应的容器中还没有的话。Driver可以使用Sandbox Key来识别连接到同一个容器的多个Endpoint。这个API同样接受可选的options参数供Driver使用。
- 虽然这并不是Libnetwork直接的设计要求,但是我们鼓励像Docker这样的用户在执行容器的Start()操作时,即在容器可以操作之前,调用endpoint.Join()。
- 另一个关于endpoint.join()这个API经常被提到的问题是,为什么我们需要一个API创建Endpoint和另一个API来join endpoint。事实上Endpoint代表的是一个Service,它可能有,也可能并没有容器支持。当一个Endpoint被创建的时候,会预留它所需的资源,因此任何容器都能连接该Endpoint并且获得一个一致的网络行为。
6、endpoint.Leave():会在容器停止的时候被调用。Driver可以清除它在调用Join()时获取的状态。Libnetwork会在最后一个Endpoint离开的时候删除Sandbox。但是只要该Endpoint依旧存在,Libnetwork会依然保有IP地址并且在有新的容器加入的时候进行重用。这保证了容器的资源在停止并重启的过程中能够重用。
7、endpoint.Delete():用于从一个Network中删除Endpoint。这将导致Endpoint的删除以及清空缓存的sandbox.Info。
8、network.Delete():用于删除Network。如果还有Endpoint连接到该网络,Libnetwork是不允许对它进行删除的。
三、 容器CNI网络
容器网络的配置是一个复杂的过程,为了应对各式各样的需求,容器网络的解决方案也多种多样,例如有Flannel,Calico,Kube-OVN,Weave等。同时,容器平台/运行时也是多样的,例如有Kubernetes,OpenShift,rkt等。如果每种容器平台都要跟每种网络解决方案一一对接适配,这将是一项巨大且重复的工程。当然,聪明的程序员们肯定不会允许这样的事情发生。想要解决这个问题,我们需要一个抽象的接口层,将容器网络配置方案与容器平台方案解耦。
1、CNI是什么
CNI(Container Network Interface)就是这样的一个接口层,它定义了一套接口标准,提供了规范文档以及一些标准实现。采用CNI规范来设置容器网络的容器平台不需要关注网络的设置的细节,只需要按CNI规范来调用CNI接口即可实现网络的设置。
CNI (Container Network Interface) 定义了一组用于实现容器网络接口的配置以及 IP 地址的分配的规范。CNI 只关注容器的网络连接以及当容器删除时移除被分配的网络资源,因此 CNI 得到了广泛的支持,并且规范也易于实现。
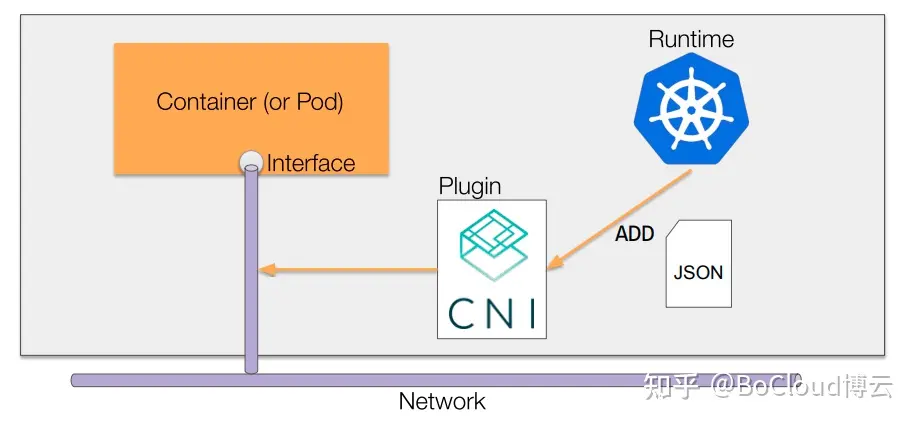
CNI最初是由CoreOS为rkt容器引擎创建的,随着不断发展,已经成为事实标准。目前绝大部分的容器平台都采用CNI标准(rkt,Kubernetes,OpenShift等)。本篇内容基于CNI最新的发布版本v0.4.0。
随着kuberntes飞速发展,如今涌现出很多优秀的开源 CNI,如calico,flannel,cilium。每个 CNI 都有各自的特点以及应用场景,但是也有各自的不足之处。因此,针对不同的场景使用合适的 CNI 就变得尤为重要。有时为了满足更复杂的网络需求,甚至于需要多种 CNI 联合使用,这样会使网络模型变得更为复杂,大大增加维护难度。
值得注意的是,Docker并没有采用CNI标准,而是在CNI创建之初同步开发了CNM(Container Networking Model)标准。但由于技术和非技术原因,CNM模型并没有得到广泛的应用。
CNI本身并不完全针对docker的容器,而是提供一种普适的容器网络解决方案。因此他的模型只涉及两个概念:
容器(container) : 容器是拥有独立linux网络命名空间的独立单元。比如rkt/docker创建出来的容器。 这里很关键的是容器需要拥有自己的linux网络命名空间。这也是加入网络的必要条件。
网络(network): 网络指代了可以相互联系的一组实体。这些实体拥有各自独立唯一的ip。这些实体可以是容器,是物理机,或者其他网络设备(比如路由器)等。
2、CNI接口及实现
CNI的接口设计的非常简洁,只有两个接口ADD/DELETE。
以 ADD接口为例
Add container to network
参数主要包括:
- Version. CNI版本号
- Container ID. 这是一个可选的参数,提供容器的id
- Network namespace path. 容器的命名空间的路径,比如 /proc/[pid]/ns/net。
- Network configuration. 这是一个json的文档,具体可以参看network-configuration
- Extra arguments. 其他参数
- Name of the interface inside the container. 容器内的网卡名
返回值:
- IPs assigned to the interface. ipv4或者ipv6地址
- DNS information. DNS相关信息
3、CNI是怎么工作的
CNI的接口并不是指HTTP,gRPC接口,CNI接口是指对可执行程序的调用(exec)。这些可执行程序称之为CNI插件,以Kubernetes为例,Kubernetes节点默认的CNI插件路径为/opt/cni/bin,在Kubernetes节点上查看该目录,可以看到可供使用的CNI插件:
$ ls /opt/cni/bin/ bandwidth bridge dhcp firewall flannel host-device host-local ipvlan loopback macvlan portmap ptp sbr static tuning vlan
CNI的工作过程大致如下图所示:
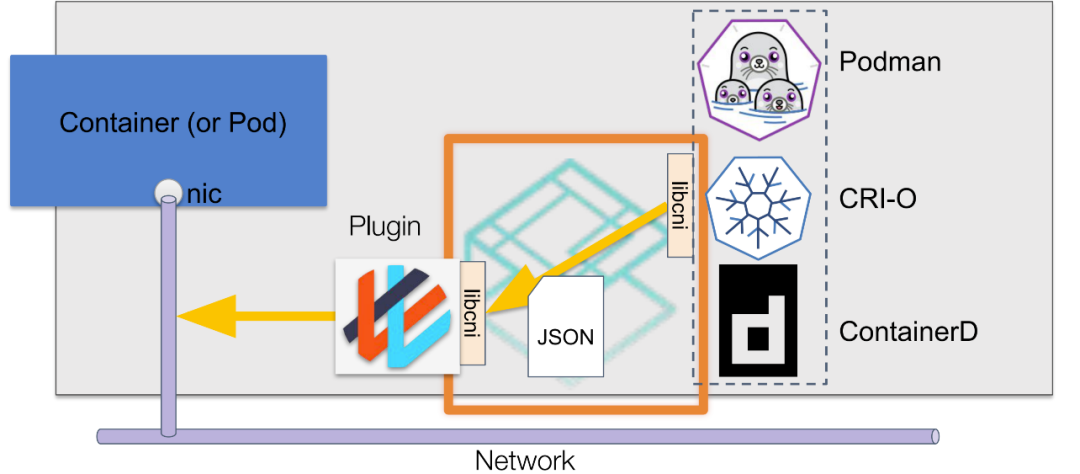
CNI通过JSON格式的配置文件来描述网络配置,当需要设置容器网络时,由容器运行时负责执行CNI插件,并通过CNI插件的标准输入(stdin)来传递配置文件信息,通过标准输出(stdout)接收插件的执行结果。图中的 libcni 是CNI提供的一个go package,封装了一些符合CNI规范的标准操作,便于容器运行时和网络插件对接CNI标准。
举一个直观的例子,假如我们要调用bridge插件将容器接入到主机网桥,则调用的命令看起来长这样:
# CNI_COMMAND=ADD 顾名思义表示创建。 # XXX=XXX 其他参数定义见下文。 # < config.json 表示从标准输入传递配置文件 CNI_COMMAND=ADD XXX=XXX ./bridge < config.json
四、 CNI与CNM的转化
CNI和CNM并非是完全不可调和的两个模型。二者可以进行转化。比如calico项目就是直接支持两种接口模型。
从模型中来看,CNI中的container应与CNM的sandbox概念一致,CNI中的network与CNM中的network一致。在CNI中,CNM中的endpoint被隐含在了ADD/DELETE的操作中。CNI接口更加简洁,把更多的工作托管给了容器的管理者和网络的管理者。从这个角度来说,CNI的ADD/DELETE接口其实只是实现了docker network connect和docker network disconnect两个命令。
kubernetes/contrib项目提供了一种从CNI向CNM转化的过程。其中原理很简单,就是直接通过shell脚本执行了docker network connect和docker network disconnect命令,来实现从CNI到CNM的转化。
五、Libnetwork Remote Driver
Remote Driver的出现为业界提供了自定义网络的可能。远程驱动作为服务端,libnetwork作为客户端,两者通过一系列带Json格式的http POST请求进行交互。
这种形式对网络实现的可维护性,可扩展性有很大好处。对于千差万别的网络实施方案而言,docker算是解放了双手,把更多精力放在自己擅长的容器方面。 代码位于libnetwork/drivers/remote。对应的远端驱动,只要实现了以下接口,就能支持docker网络相关的生命周期。
dispatchMap := map[string]func(http.ResponseWriter, *http.Request){
"/Plugin.Activate": activate(hostname),
"/Plugin.Deactivate": deactivate(hostname),
"/NetworkDriver.GetCapabilities": getCapability,
"/NetworkDriver.CreateNetwork": createNetwork,
"/NetworkDriver.DeleteNetwork": deleteNetwork,
"/NetworkDriver.CreateEndpoint": createEndpoint(hostname),
"/NetworkDriver.DeleteEndpoint": deleteEndpoint(hostname),
"/NetworkDriver.EndpointOperInfo": endpointInfo,
"/NetworkDriver.Join": join,
"/NetworkDriver.Leave": leave,}
六、容器的SR-IOV
1、SR-IOV简介
SR-IOV的全称是Single Root I/O Virtualization。
虚拟机中的网卡看起来是真实的硬件,实际则是宿主机虚拟化出来的设备,也就是运行的软件程序;这也意味着,虚拟设备是需要CPU去运行的,这样设备的性能会随着宿主机性能而改变,可能会产生额外的延时。
VT-D技术可以将物理机的PCIe设备直接分配给虚拟机,让虚拟机直接控制硬件,来避免上述问题。但是虚拟机会独占直通的PCIe设备,如果一台宿主机上有多个虚拟机,那就要求对应数量的物理网卡,这显然不现实。
为解决这样的问题,Intel提出来SR-IOV技术,该技术最初应用在网卡上。简单来讲,就是将一个物理网卡虚拟出多个轻量化的PCIe物理设备,再分配给虚拟机使用。
启用SR-IOV技术,可以大大减轻宿主机的CPU负荷,提高网络性能、降低网络延时,也避免了PCI-passthrough下各个物理网卡被各个容器独占的问题。
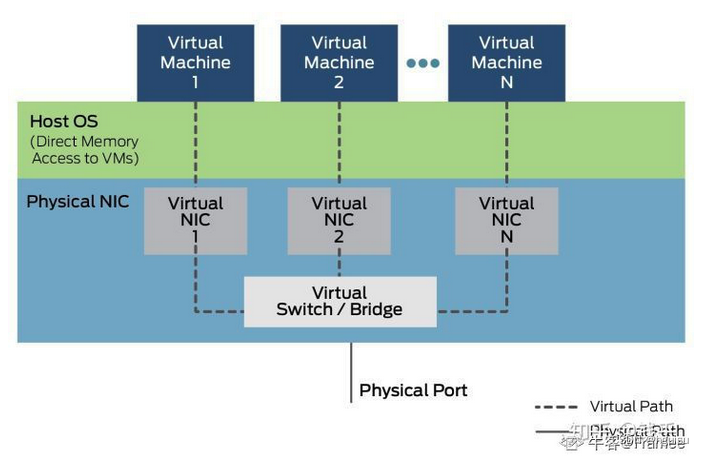
根据Oracle Solaris的文档描述,SR-IOV规范定义了新的标准,创建的新设备能将虚拟机直接连接到I/O设备,并获得于本机性能媲美的I/O性能。具体规范由PCI-SIG定义和维护。
2、Functions
SR-IOV包含2种新功能类型:
- 物理功能(Physical Function, PF):用于支持SR-IOV功能的PCI功能。
- 虚拟功能(Virtual Function, VF):与物理功能关联的一种功能。
更具体来说,PF是包含完全的PCIe功能,可以像其他任何PCIe设备一样进行发现、管理和处理;PF拥有完全配置资源,可用于配置或控制PCIe设备。
VF是一种轻量级的PCIe功能,可以与物理功能及同一物理功能关联的其他VF共享一个或多个物理资源,且仅允许拥有用于其自身行为的配置资源。
每个SR-IOV设备都可以有一个PF,每个PF最多可以关联64,000个VF。PF可以通过专用寄存器创建VF。
一旦在PF中启用了SR-IOV,就可以通过PF的总线、设备和路由ID访问各个VF的PCI配置空间。每个VF具有一个映射了其寄存器集的PCI内存空间,VF设备驱动程序对寄存器集进行操作以启用其功能,并显示为实际存在的PCI设备。 创建VF后,可以直接将其指定给IO guest域的各个应用程序。
此功能试的虚拟功能可以在没有CPU和VMM开销的情况下执行I/O。 缺省状态下,SR-IOV功能处于禁用状态,PF充当传统PCIe设备。
SR-IOV技术也有其局限性,比如同一PF可关联的VF数量是有限的,而且是硬件绑定的,不支持容器迁移。
3、Docker with SR-IOV
SR-IOV在虚拟化中应用广泛,理所当然地可以被用在容器上。
Intel官方就维护了一个SR-IOV的CNI插件,Intel/sriov-cni。除此之外,其开发的clearcontainers项目下也有一个SR-IOV的network plugin,支持docker指定容器运行时为runc或clearcontainer时使用,见clearcontainers/sriov。
下面我们采用clearcontainers提供的SR-IOV Docker Plugin进行安装。
Install Clear Containers SRIOV Docker Plugin
环境要求:
- 物理机(VM中可能找不到支持SR-IOV的PF)
- Golang
- Docker Engine
克隆源码。
git clone https://github.com/clearcontainers/sriov.git
cd sriov用Go Mod或者Dep等工具初始化go pkg依赖,配置docker/libnetwork项目到较新版本(旧版本会导致编译失败)。
$ go mod init
$ go mod vendor
$ cat go.mod
module github.com/clearcontainers/sriov
go 1.13
require (
github.com/01org/ciao v0.0.0-20180108144400-194264adc583
github.com/boltdb/bolt v1.3.1
github.com/docker/libnetwork v0.7.2-rc.1
github.com/golang/glog v0.0.0-20160126235308-23def4e6c14b
github.com/gorilla/mux v1.7.3
github.com/vishvananda/netlink v1.1.0
)编译源码。
go build在host上安装SR-IOV插件,并在后台启动插件。
sudo cp sriov.json /etc/docker/plugins
sudo ./sriov &以Docker默认的runc容器运行时来测试插件功能。
# Create a virtual network on physical network b2b with vlanid 100
sudo docker network create -d sriov --internal --opt pf_iface=eth0 --opt vlanid vfnet
# Create container on the network vfnet
docker run --net=vfnet -itd busybox top
# Check that container is running
docker ps
# Cleanup
docker stop $(docker ps -a -q)
docker rm $(docker ps -a -q)
sudo docker network rm vfnet本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-12-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号