python读excel文件最佳实践?直接请教pandas比gpt还好用

python读excel文件最佳实践?直接请教pandas比gpt还好用

咋咋
发布于 2024-01-03 17:13:18
发布于 2024-01-03 17:13:18
前言
说到 python 读取 excel 文件,网上使用 openpyxl 的文章一大堆。我自己很少直接使用 openpyxl,一般使用 pandas 间接使用。
但如果你不希望引入 pandas,该如何轻松使用 openpyxl?到底有没有最佳实践写法?
这好办,今天就带大家看看 pandas 里面,是如何使用 openpyxl 读取 excel 文件。
不要忘记一键三连。你的点赞、收藏、关注,是我创作的动力。
本文查看的是 pandas 2.1.4 版本的代码。
使用任何能导航代码的 ide,我使用的是 vscode ,输入 pandas 的 read_excel 方法,按住 ctrl 键,鼠标点击方法,即可进入源码文件。

通过查找,你会找到一个很重要的类定义 ExcelFile :
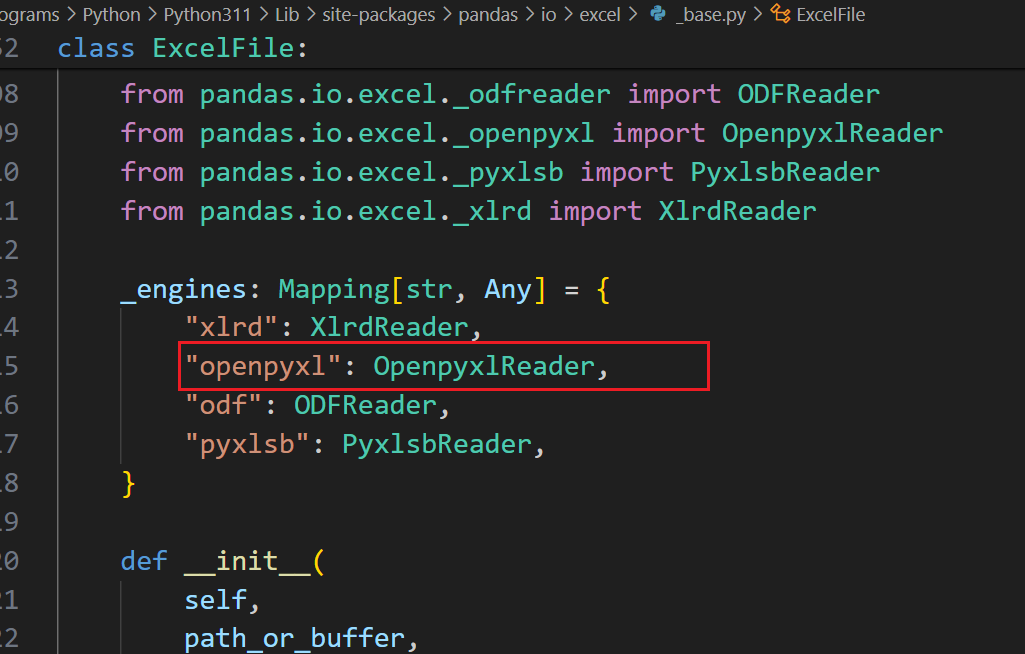
众所周知,pandas 能指定不同的第三方库读写 excel 文件。今天我们只看 openpyxl 。进去查看,基本上所有的读取逻辑都在这个类里面。
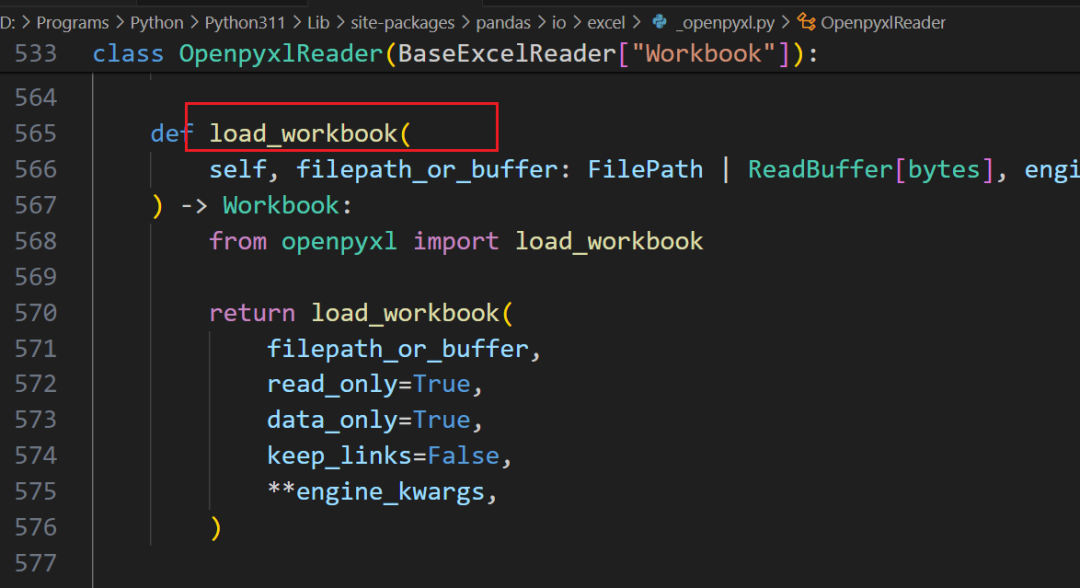
很明显,这是读取文件的代码。由于只需要读取,设置 read only 和 data only ,能以最优性能执行。
接着是工作表相关:
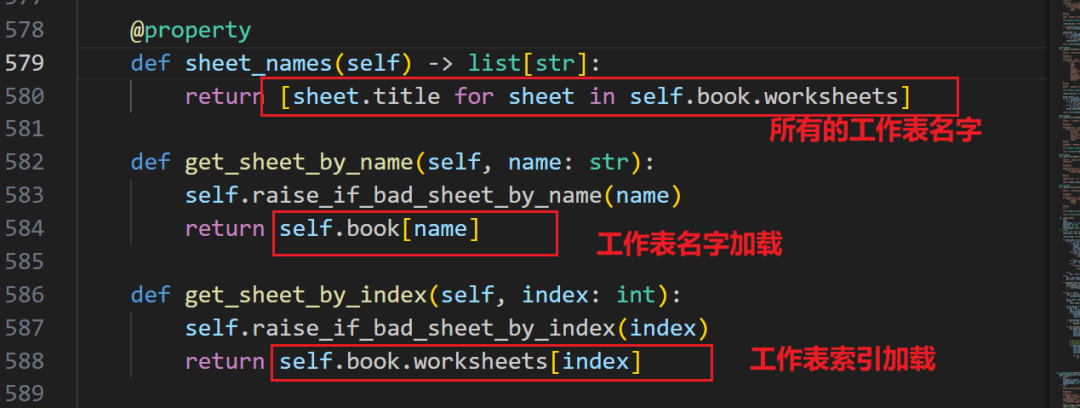
有了具体的某个工作表对象,下一步就是最重要的加载数据,现在才是我们最关注的地方。到底 pandas 是如何组织代码?代码中一些奇怪的操作,是为什么?我们一一拆解。

行 612 是什么鬼?通过查 openpyxl 的文档,可以知道,原来有些程序(wps?)或库,在保存文件的时候,会写入关于工作表数据的范围最大行和列的信息。但是他们有可能会写错,通过 reset_dimensions 可以重置
接着就开始遍历读取:

同时我们注意到,行 614 和 623,这就是读取出来的所有数据,是一个 嵌套 list 结构。
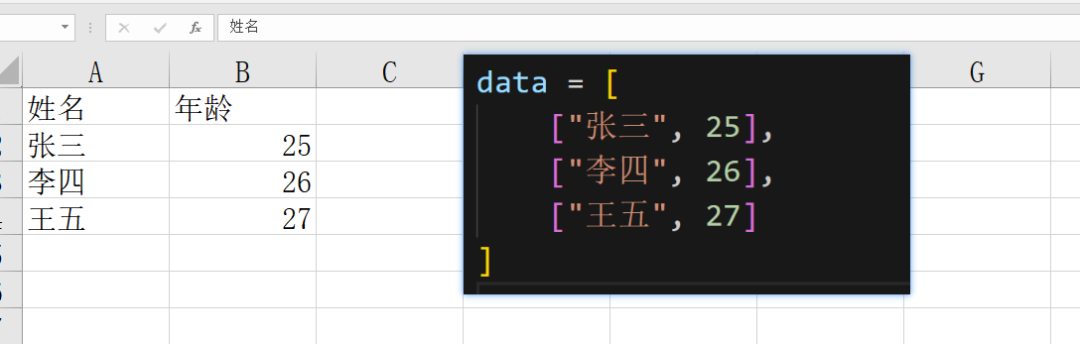
但是,里面竟然有一个 while 循环?
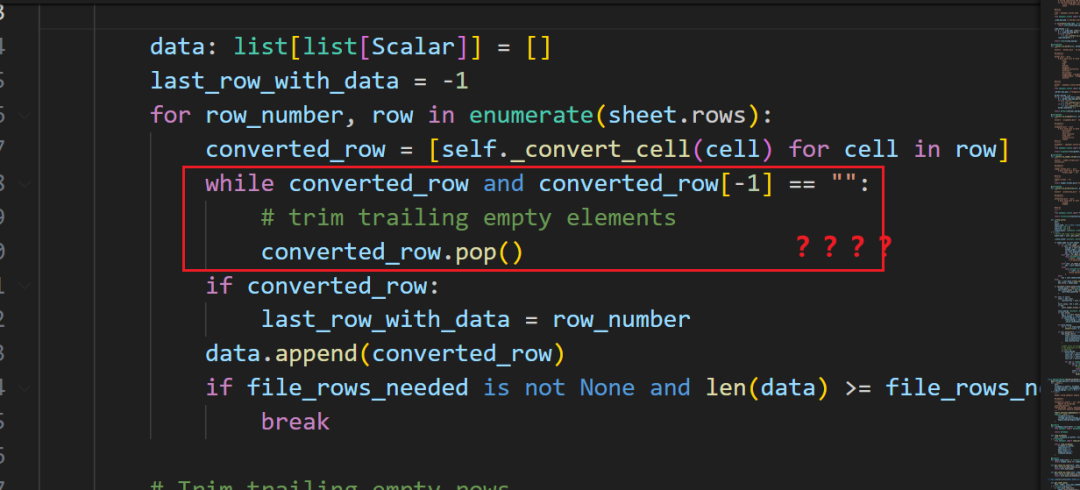
原来,如果用户设置了一个单元格的格式,即使没有内容,也算一个有效的单元格。
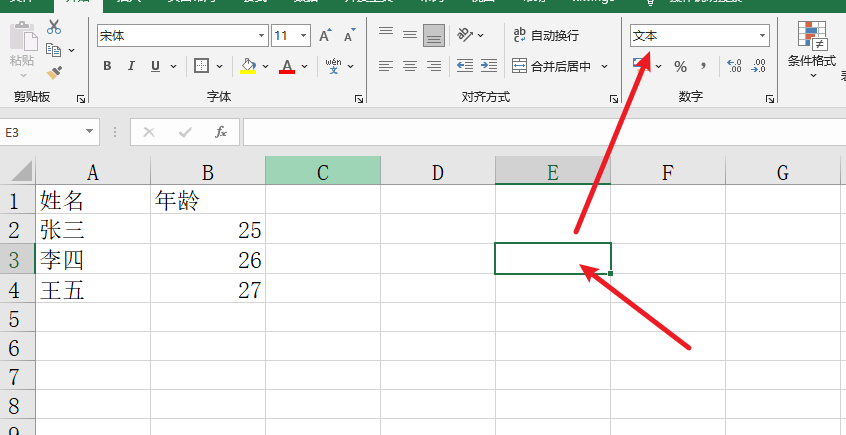
此时如果只是正常遍历读取,得到的结果是
所以 while 循环就是移除这些多余的空单元格
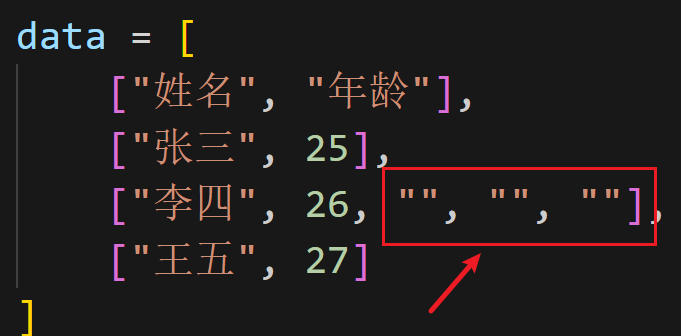
如果这种"假单元格"出现在数据行下方:
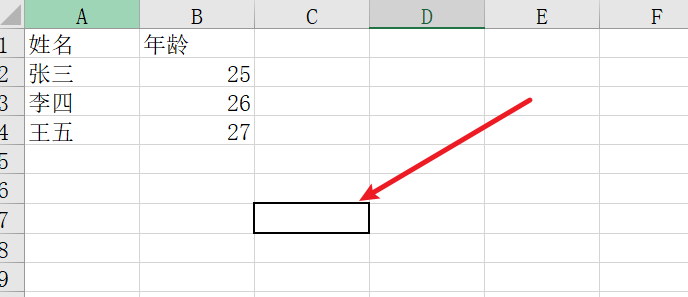
此时就多了许多空行

所以,pandas 在遍历过程中,记录了最后有记录的行索引,遍历后截取一下就可以搞定:
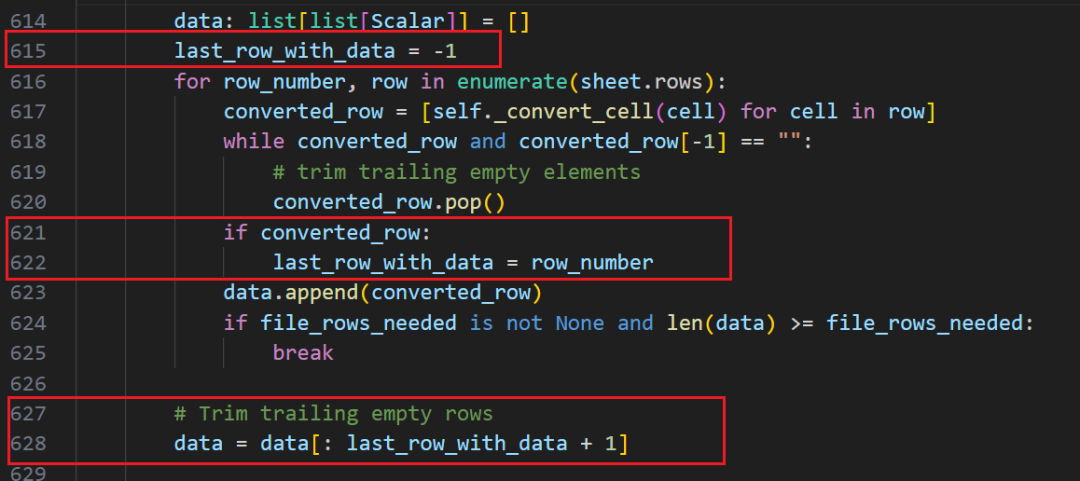
看起来好像结束了?对于 pandas 来说,还没完
对于 pandas 来说,最终它会把得到的嵌套 list 数据传给 pd.DataFrame 。这里有一个前提,嵌套的每一行的列表长度必需一致才行。
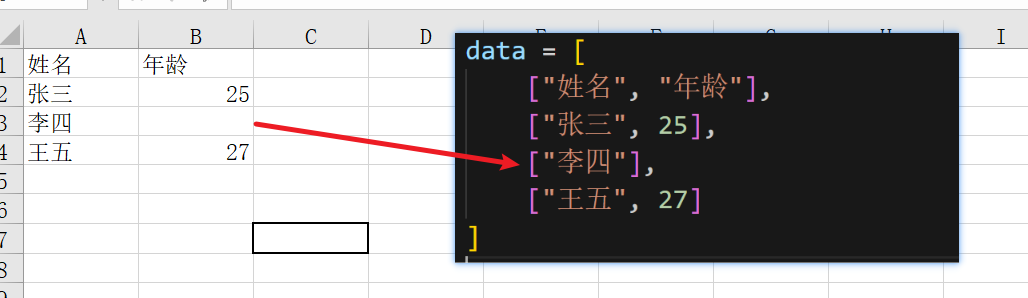
但是行的长度有可能不一致。所以你会看到 pandas 的处理中,最后有一段逻辑用于补齐这些"短列表"
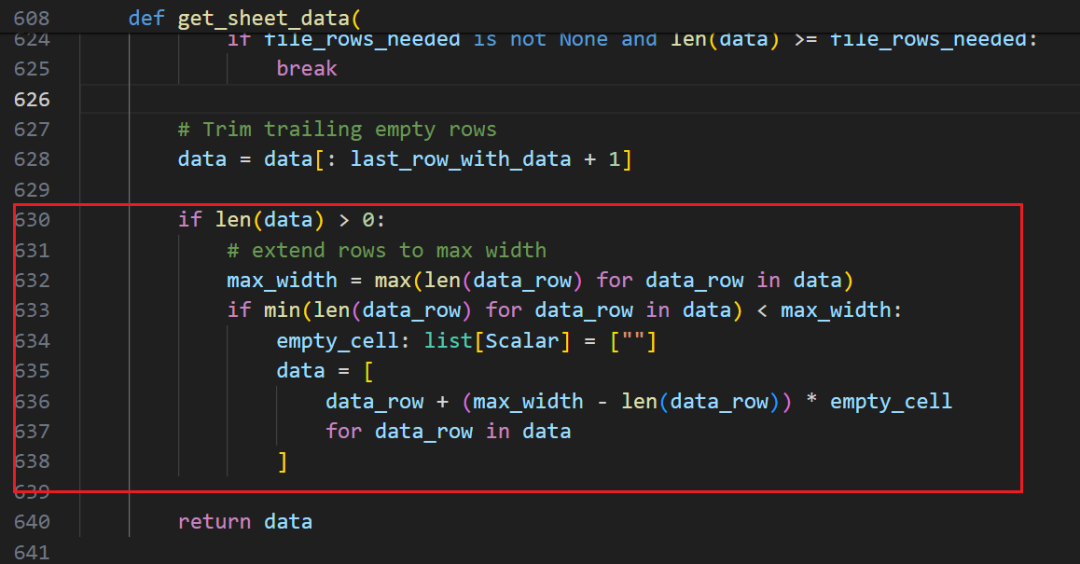
可以注意到,其中有3处地方在遍历 data 数据。所以,如果记录越多,这里就比较耗时。你能想到优化的方法吗?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-12-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号