独家 | 在一个4GBGPU上运行70B大模型推理的新技术

独家 | 在一个4GBGPU上运行70B大模型推理的新技术

数据派THU
发布于 2024-01-07 14:27:43
发布于 2024-01-07 14:27:43
作者:Gavin Li
翻译:潘玏妤校对:赵鉴开本文约2400字,建议阅读5分钟本文介绍了一个4GBGPU上运行70B大模型推理的新技术。关键词:AI,生成式人工智能解决方案,AI 推理,LLM,大型语言模型
大语言模型通常需要较大的GPU内存。那能不能在单个GPU上运行推理?如果可以,那么所需的最小GPU内存又是多少?

这个70B的大型语言模型具有130GB的参数大小,仅仅将该模型加载到GPU中就需要两个拥有100GB内存的A100 GPU。
在推理过程中,整个输入序列还需要加载到内存中进行复杂的“注意力”计算。这个注意力机制的内存需求与输入长度的平方成正比,因此除了130GB的模型大小之外,还需要更多的内存。那么,有哪些技术可以节省如此多的内存并使得在单个4GB GPU上进行推理成为可能呢?
请注意,这里的内存优化技术并不需要进行任何模型压缩,比如量化(quantization)、模型蒸馏(distillation)、模型修剪(pruning),这些压缩技术可能会牺牲模型性能。
今天我们将解释大型模型极致内存优化的关键技术。在文章的结尾,我们还分享了一个开源库,可以通过几行代码实现这一目标!
01 层级推理
最关键的技术是层级推理(layer-wise inference)。实质上,这是计算机科学中基本的分治法(divide and conquer approach)的应用。
让我们首先看一下大型语言模型的架构。当今的大型语言模型都采用了谷歌论文《Attention is all you need》中提出的Multi-head self-attention架构,即后来的Transformer。
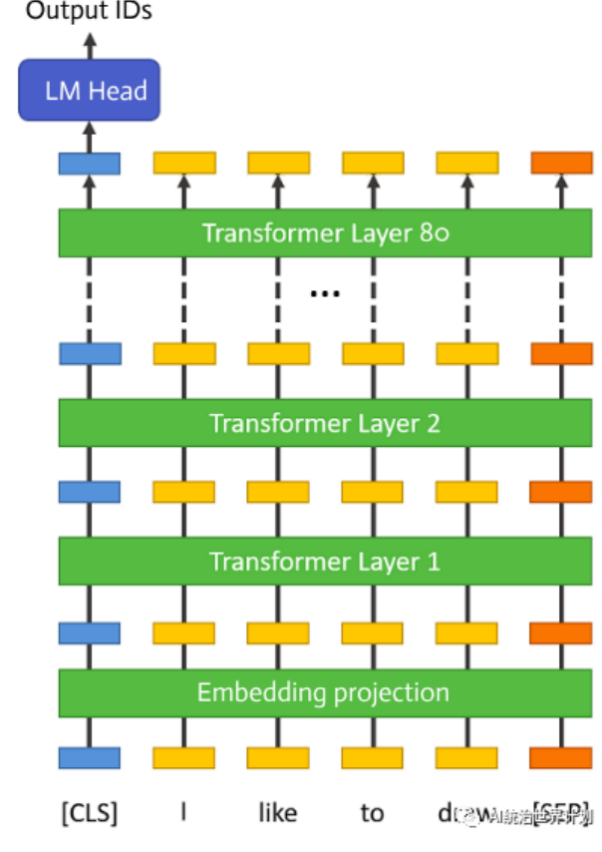
大型语言模型首先有一个嵌入投影层(embedding projection layer)。然后是80个完全相同的Transformer层。最后有一个规范化(normalization)和全连接层(fully connected layer),用于预测标记(token)ID的概率。
在推理过程中,前一层的输出是下一层的输入,每次只有一个层在执行。因此,完全没有必要将所有层都保留在GPU内存中。我们可以在执行特定层时从磁盘加载需要的层,进行所有计算,然后在执行完毕后完全释放内存。
这样,每个层需要的GPU内存仅约为一个Transformer层的参数大小,即全模型的1/80,大约为1.6GB。此外,一些输出缓存也存储在GPU内存中,其中最大的是KV(key-value)缓存,用以避免重复计算。
以70B模型为例,KV缓存大小约为:
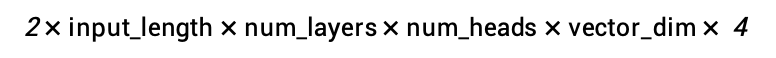
当输入长度为100时,这个缓存大小等于的GPU内存。
根据我们的监测,整个推理过程使用的GPU内存不到4GB!
02 单层优化––Flash Attention技术
Flash Attention可能是当今发展大型语言模型过程中最重要、最关键的优化之一。所有不同的大型语言模型本质上使用相同的基础代码,而Flash Attention是其间最大的改进。
然而,Flash Attention优化的思想并非全新,我们必须提到另一篇论文《Self-attention Does Not Need O(n²) Memory》。起初,自注意力(self-attention)机制需要O(n²)的内存(其中n为序列长度)。该论文提出,我们实际上不需要保留 O(n²) 的全部中间结果。我们可以按顺序计算它们,不断更新一个中间结果并丢弃其他所有内容。这可以将内存复杂度降低到O(logn)。
Flash Attention的本质类似这一思想,但内存复杂度略高,为O(n),不过Flash Attention通过深度优化CUDA内存访问,在推理和训练中实现了多倍的加速。
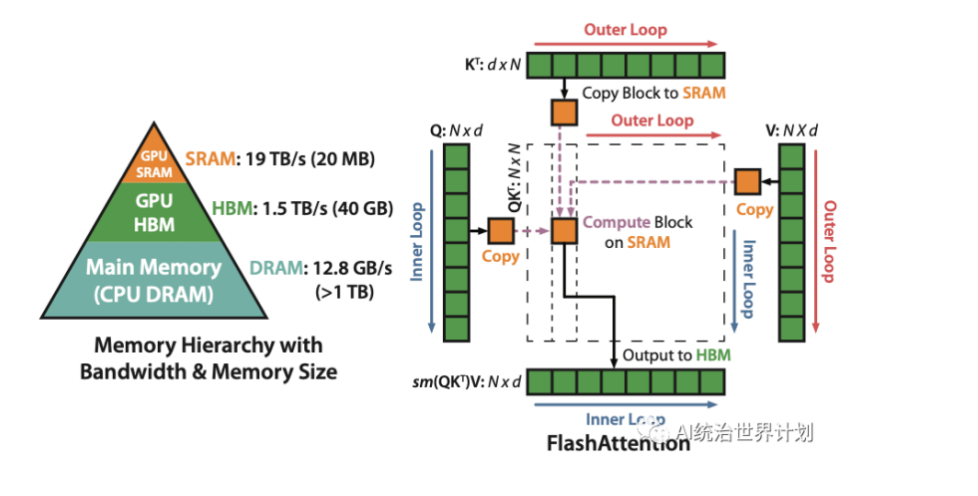
正如图中所示,原始的自注意力机制计算并存储O(n²)的中间结果。Flash Attention将计算分割成许多小块,逐块计算并将内存降低到一个块的大小。
03 模型文件分片
原始模型文件通常被分割成多个块,每个块通常为10GB。我们的执行是逐层进行的,每一层只有1.6GB。如果我们基于原始的10GB分片加载,那么每一层的执行都将需要重新加载整个10GB的文件,但实际上只使用了1.6GB。
这个过程浪费了大量内存用于加载和磁盘读取。磁盘读取速度实际上是整个推理过程中最慢的环节,我们希望尽量减少读取以突破速度瓶颈。因此,我们首先对原始的HuggingFace模型文件进行预处理,并按层进行分片。存储上我们使用了SafeTensors技术(https://github.com/huggingface/safetensors)。SafeTensors可以确保存储格式和内存格式紧密匹配,并使用内存映射技术(memory mapping)进行加载,以最大化速度。
04 Meta Device
在实现中,我们使用了HuggingFace Accelerate提供的meta device(https://huggingface.co/docs/accelerate/usage\_guides/big\_modeling)。Meta device是专为运行超大型模型而设计的虚拟设备。当通过meta device加载模型时,实际上并未读取模型数据,只加载了代码。内存使用为0。在执行过程中,你可以动态地将模型的部分从meta device转移到实际设备,比如CPU或GPU。只有在这时,它才会实际加载到内存中。
from accelerate import init_empty_weights
with init_empty_weights():
my_model = ModelClass(...)05 开源库
我们开源了所有的代码––AirLLM。它允许你用几行代码实现这个目标(https://github.com/lyogavin/Anima/tree/main/air_llm)。
使用方法非常简单。首先安装该包:
pip install airllm然后,层次推理(layered inference)可以像普通的Transformer模型一样进行:
from airllm import AirLLMLlama2
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AirLLMLlama2("garage-bAInd/Platypus2-70B-instruct")
# or use model's local path...
#model = AirLLMLlama2("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?',
]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=True)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=20,
use_cache=True,
return_dict_in_generate=True)
output = model.tokenizer.decode(generation_output.sequences[0])
print(output)我们在一台16GB的Nvidia T4 GPU上测试了这个代码。整个推理过程使用的GPU内存不到4GB。请注意,像T4这样的低端GPU在推理方面可能会比较慢。对于像聊天机器人这样的交互式场景可能不太适用,更适合一些离线数据分析,比如RAG、PDF分析等。
AirLLM目前只支持基于Llam2的模型。
06 70B的模型训练能否在单个GPU上进行?
推理可以通过分层进行优化,那么在单个GPU上是否可以进行类似训练呢?推理在执行下一个Transformer层时只需要前一层的输出,因此在有限的数据情况下可以进行分层执行。
训练需要更多的数据。训练过程首先进行前向传播,以获取每个层和tensor的输出,然后进行反向传播,计算每个tensor的梯度。梯度计算需要保存前向传播层的结果,因此分层执行并不会减少内存占用。有一些其他技术,比如梯度检查点(gradient checkpointing),可以达到类似的效果。
07
我们的代码参考了SIMJEG在Kaggle上的实现:https://www.kaggle.com/code/simjeg/platypus2-70b-with-wikipedia-rag/notebook。
向出色的Kaggle社区表示敬意,感谢他们的贡献!
原文标题:
Unbelievable! Run 70B LLM Inference on a Single 4GB GPU with This NEW Technique
原文链接:
https://ai.gopubby.com/unbelievable-run-70b-llm-inference-on-a-single-4gb-gpu-with-this-new-technique-93e2057c7eeb
编辑:王菁
译者简介
潘玏妤,流连于剧院和美术馆的CS本科生,沉迷于AI与数据科学相关学术前沿信息的古典音乐爱好者。
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号