使用GBDT算法实现敏感词匹配


GBDT算法介绍
GBDT(Gradient Boosting Decision Tree)在数据分析和预测中的效果很好。它是一种基于决策树的集成算法。其中Gradient Boosting 是集成方法boosting中的一种算法,通过梯度下降来对新的学习器进行迭代。而GBDT中采用的就是CART决策树。
GBDT(Gradient Boosting Decision Tree),全名叫梯度提升决策树,是一种迭代的决策树算法,又叫 MART(Multiple Additive Regression Tree),它通过构造一组弱的学习器(树),并把多颗决策树的结果累加起来作为最终的预测输出。该算法将决策树与集成思想进行了有效的结合。
资料:
图解机器学习 | GBDT模型详解 (showmeai.tech)
图解机器学习 | 决策树模型详解 (showmeai.tech)
现有匹配算法
常用敏感词屏蔽算法(非法词/脏词检测过滤)如下:
DFA确定有限自动机匹配屏蔽,我们将敏感词构造成DFA形式,如敏感词集合 。如DFA算法,我们对每一个节点状态标记,1代表结束,也就是敏感词结束,0代表还未结束。将敏感词构造成DFA结构后,就可以开始匹配句子,此种算法优势是使用类是决策树的形式,减少循环遍历,优化了系统性能。缺点是如果敏感词库很大,DFA的构建也会很大,很占内存。
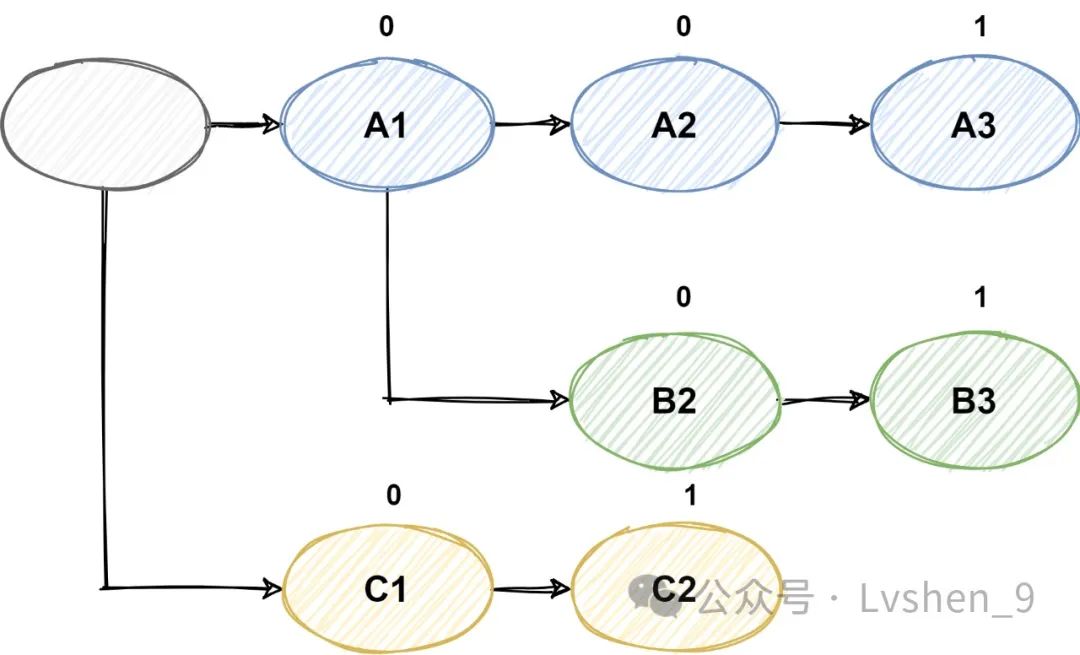
DFA匹配算法
AC自动机多模字符串匹配屏蔽,对Trie进行了改进,在Trie的基础上结合了KMP算法的思想,在树中加入了类似next数组的失效指针。需要将敏感词集合构建成Trie树,如AC自动机多模字符串匹配算法。匹配句子时,遍历Trie树,从敏感词集合中找出可匹配的敏感词。
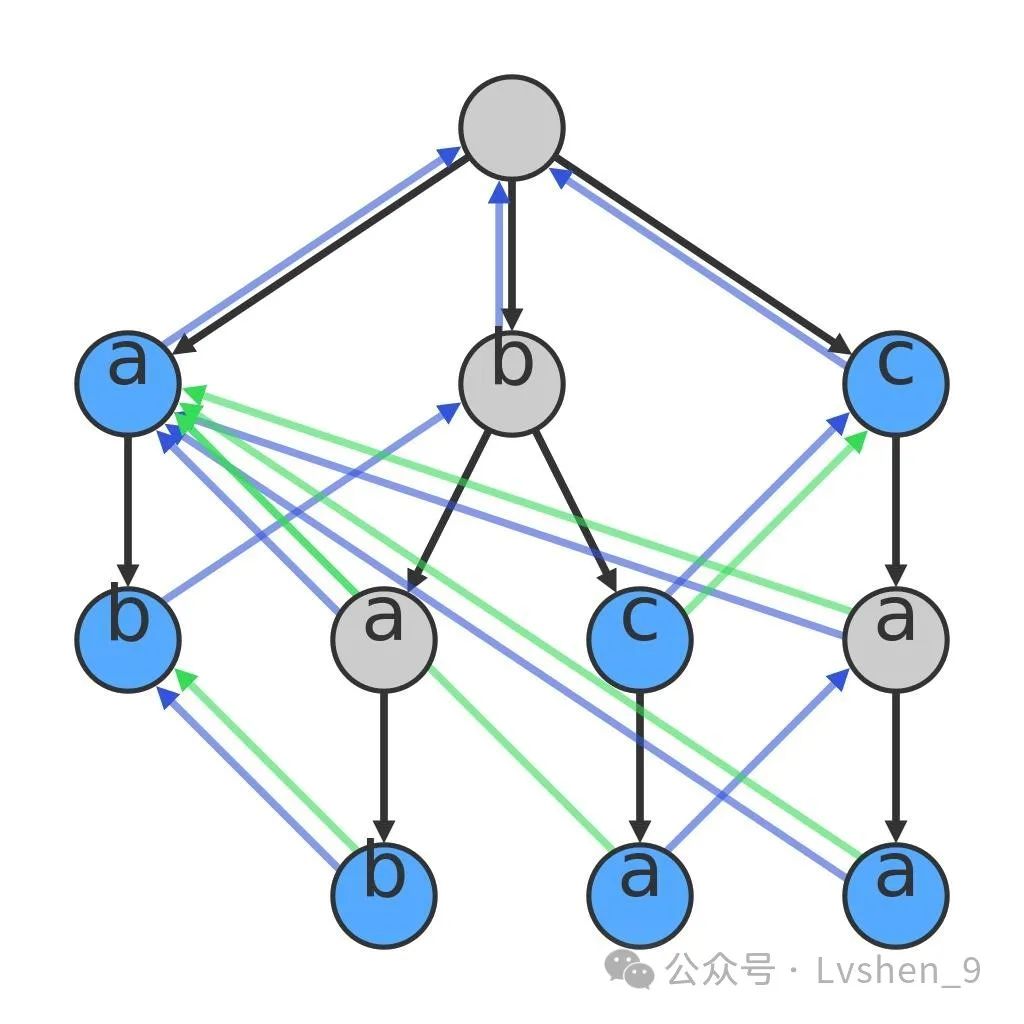
AC自动机多模式
上述敏感词屏蔽算法只能精确屏蔽,如果新增敏感词规则,就需要人工维护敏感词集合,这种迭代更新完全依赖人力,无法自动挖掘敏感词的匹配规则。
同时面对复杂的语言环境,当前匹配算法会丧失匹配精度,出现误伤情况。例如:“中华”一词多义,如果指香烟,可能算烟草违规的敏感词,但如果指牙膏,那就不算敏感词了。
如果出现主题漂移的情况,上述敏感词屏蔽算法也会出现跨越分词边界匹配,例如:“吃肯德基吧”。这段句子再正常不过了,如果“基吧”在敏感词集合中,就会被屏蔽,最后显示出来就是“吃肯德**”。
如果出现词语变异,如通过音近、形近、暗喻等手段企图蒙混过关。例如“香烟”是敏感词,可能使用者会使用“香yan”来逃脱算法屏蔽。
因此为了解决当前准确率低,敏感词规则词库维护成本高问题,需要一套可自动挖掘,高准确率的算法用于敏感词屏蔽中。
基于GBDT算法的匹配
主要步骤为:
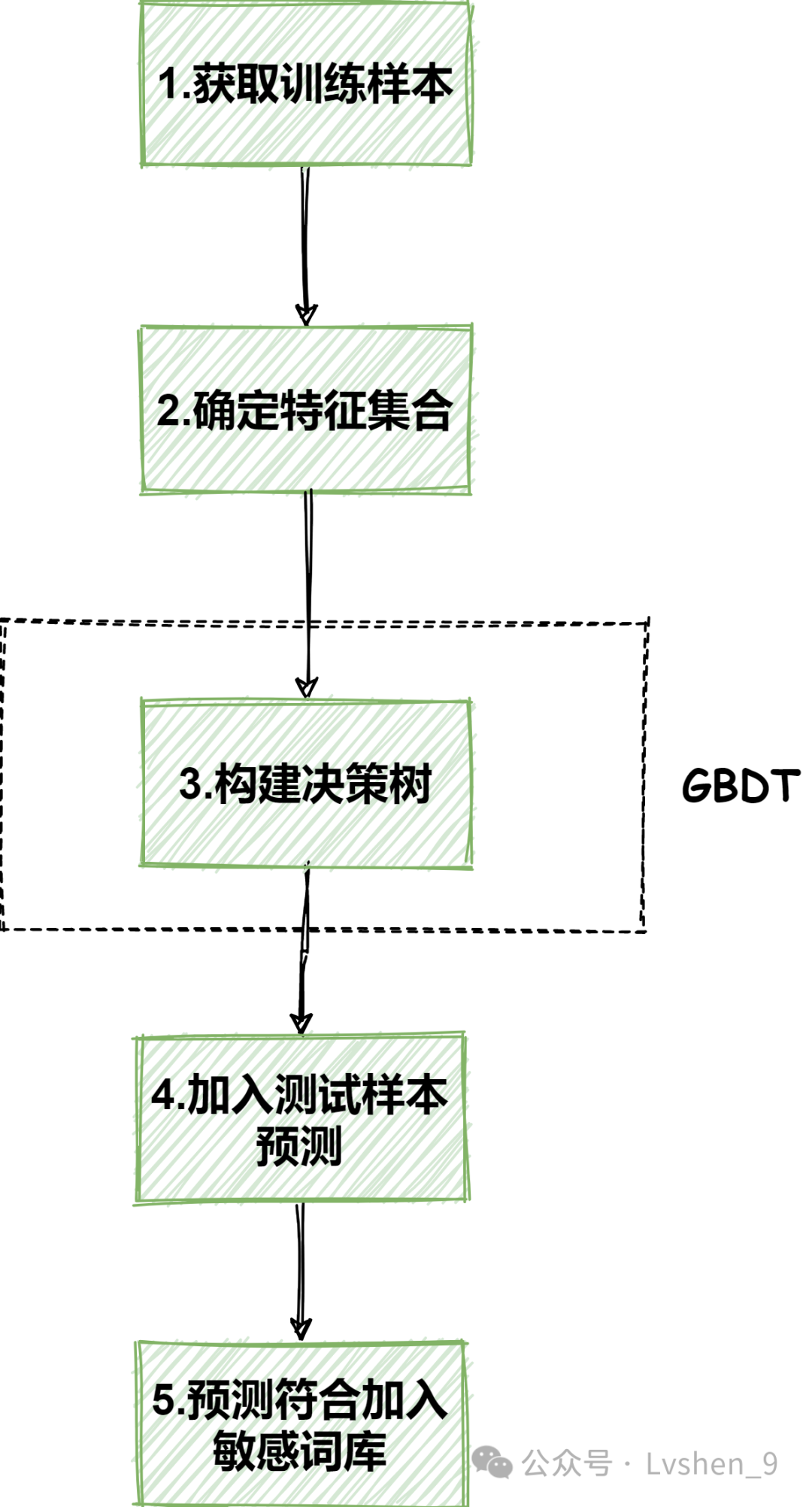
如上图,为训练算法的主要步骤。
获取训练样本集
首先需要获取训练集,我们从已屏蔽的敏感词数据中获取训练样本。获取训练样本后我们需要确定样本的特征属性。
划分特征属性
样本的结果为是否在敏感词集合中(是/否),所以这类问题为分类问题,在GBDT中所有的树为cart回归树,需要将分类问题转换为回归问题。我们将样本处理,并选取特征属性,形式如下:
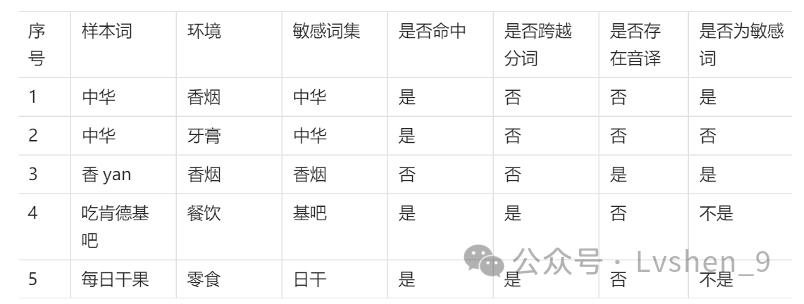
确定特征属性后我们就需要构建用于分类的回归树,也就是决策树。这里我们选取 作为构建树的节点属性。这里树的特征选取可以通过基尼指数计算得来,我们选取基尼指数最大的前几个值即可 。
构建决策树
这里需要获取初始的弱学习器计算公式为:
F0(x)=logP(Y=1∣x)1−P(Y=1∣x)
样本属于1的概率 / 样本属于0的概率,再取个log (数学上没指出底数,底数默认为10)
如案例中为敏感词(是和否我们约定用1和0表示)的集合为:1,3 ,非敏感词的集合为:2,4,5。那么:
F0(x)=log23=−0.176
接下来需要计算负梯度:
yi−11+e−F(xi)
yi为第i个样本的真实值,如下表格第1条样本 真实值 是否为敏感词的值为1,那么第一个样本值
yi=y1=1,F(xi)可理解为第i轮学习器计算的值,初始值=F0(x) = -0.176,我们把样本的F0(x)都设置为 -0.176。
计算 F0(x)时的负梯度为:
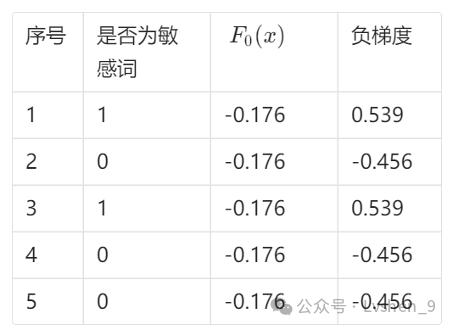
我们用负梯度作为第一颗树的拟和目标:
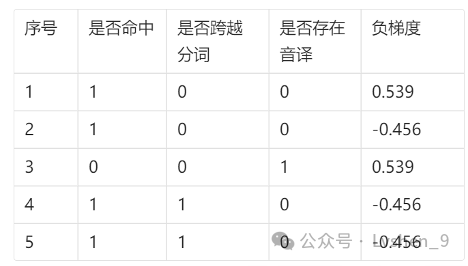
接下来我们需要寻找树的最佳划分点:我们需要将每种划分方式列出来,依次计算划分后的平方损失。SEL 为左节点的平方损失, SER 为右节点的平方损失,然后计算平方损失和:
SESUM=SEL+SER
某节点平方损失计算公式(如左节点)[(负梯度值-负梯度值/划分该节点的样本数量)差的平方]之和/样本数量。
例如对于划分节点是否命中,我们计算SER ,样本均值为
(0.539−0.456−0.456−0.456)/4=−0.21,=[(0.539+0.21)2+(−0.456+0.21)2+(−0.456+0.21)2+(−0.456+0.21)2]/4=0.186
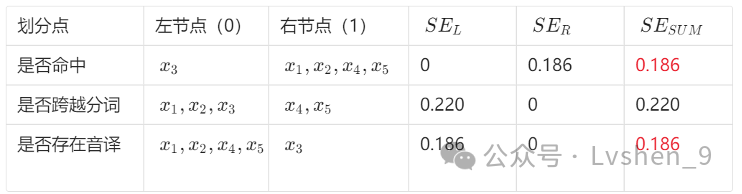
我们选取【是否命中】为第一棵树第一的划分节点(选平方损失和最小,如有多个,选其一)。
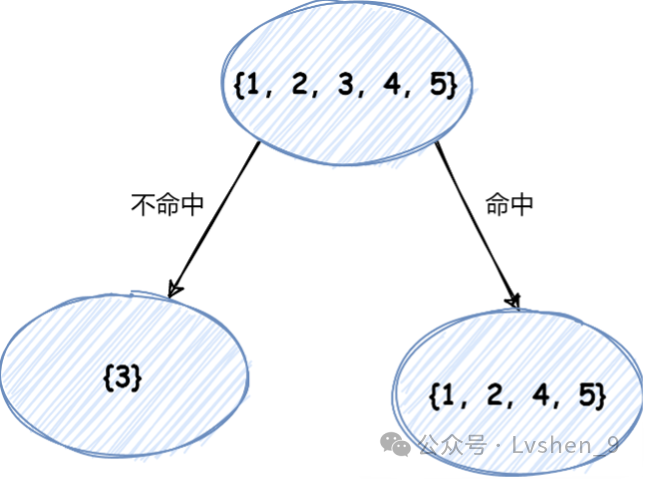
选取第一划分节点划分后,我们需要继续划分,划分停止为:节点无法继续划分,如上图左节点3,只有一个样本,这里就不用再划分了。对于右节点,我们按【是否存在音译】(选剩余最小损失和的属性)继续划分,发现都是在节点的一边(都是否),这里我们也不继续划分
但是如果特征属性很多,也能继续往下划分,我们不能无限划分下去,(树的深度越深,会影响查询效率,应为最后的概率计算是通过叶子节点的拟合值计算而来,我们可以按3层深度来进行训练,如果最后的结果不准确,无法很好预测,我们再调整树的深度,和树的数量。
这里我们假定训练树的深度=2,训练1棵树(实际情况需要根据大量的经验来判定)。我们计算左右节点的拟合值,根据公式:
c1,j=Σxi∈R1,jr1,iΣxi∈R1,j(yi−r1,i)(1−yi+r1,i)
c1,j第一颗树j节点的拟合值,例如: c1,1表示第一个树左节点的拟合值,分子为第一棵树j节点左右划分的样本的负梯度值( r1,i代表第一棵树第i个样本负梯度值)之和, yi=为样本i的实际值(是否为敏感词的值(0或1)),
c1,1= (0.539)/[(1-0.539)(1-1+0.539)] = 2.17
c1,2= (0.539-0.456-0.456-0.456)/[(1-0.539)(1-1+0.539)+ (0+0.456)(1-0-0.456)+ (0+0.456)(1-0-0.456)+ (0+0.456)(1-0-0.456)] = -1.67
c1,1 表示第一棵树左节点拟合值,c1,2表示第一棵树右节点拟合值。
c1,1=2.17,c1,2=−1.67
更新学习器:
F1(x)=F0(x)+∑j=12c1,jI(x∈R1,j)
对于第一个样本xj来说:
Fi(xj)=Fi−1(xj)+∑j=12c1,jl(x∈R1,j)
Fi(xj)表示第i棵树样本j的学习器值, Fi−1(xj) 表示第i-1一颗树的负梯度值。
这里 x0表示第一个样本, F0(x)代表初始学习器时的值。但对于特定样本,例如样本1,取对应的负梯度值,例如 F0(x0)=0.539, c1,j表示第一棵树j节点的拟合值,I为计算的系数,样本落在哪个节点上就取1,不落在就取0,如第一条样本落在右节点:
F1(x0)=F0(x0)+1∗c1,1∗0+1∗c1,2∗1=0.539+0−1.67=−1.131
依次计算四个样本的F1(x),再通过:
yi−11+e−F(xi)
计算负梯度,生成第下一颗树。为了说明,这里我们只训练一颗树,后面的树,我们重复上面的方式计算即可。
这里篇幅有限,只生成一棵树,实际上树的生成是由程序来做,我可以生成无数颗,即迭代无数次,但是次数过多,也会影响程序性能。
关于树的数量,以树的数量为横轴,计算出对应的概率为纵轴,一般纵轴值在一定范围内稳定波动,一般训练样本的预测值与真实值接近,我们认为树的数量可以预测值了。
之前计算第一棵树时,上述公式F(xi)之前的 = -0.176,计算完之后我们计算下一颗树
的学习器值,对于第一个样本 F1(x0)= -1.131。
最终生成的强学习器函数为:
FM(x)=F0(x)+∑m=1M∑j=1Jmcm,jI(x∈Rm,j)
最终学习器中的 F0(x)为初始学习器的值,cm,j 为第m棵树j节点的拟合值之和。
加入测试样本预测
由上面可得:F0(x) =-0.176
这里的 F0(x)代表初始学习器的值。
在 F1(x)中【是否命中】属性为【不命中】时预测(拟合值)为2.17。如果我们新加入是否命中属性为不命中的样本,这里在最终学习器中需要乘一个学习率系数0.1,可理解为规定值,最终预测结果为:
F(X)=−0.176+0.1∗2.17=0.041
P(Y=1∣x)=11+e−F(x)=11+e−0.041=0.51
这里我们认为是敏感词的概率为0.51。
预测符合的加入敏感词库
由上可知,对于特征【是否命中】属性为【不命中】的样本我们认为大于0.5,粗略的认为可以加入到敏感词库中。
这里只生成了一颗树,结果为0.51,一棵树一般还不能作预测,我们还需要继续生成树,当生成结果趋于稳定,在某个值上下波动不大时,我们可以停止生成树,这时的结果就可以进行预测了。
预测准确率会根据训练的树棵数,树深度,挖掘出的特征质量有密切关系。迭代次数越多,预测结果也会越精准,当让然迭代到一定次数后,预测结果就已经趋近于结果了,至于迭代次数选择,需要大量的训练经验才能得出结论。
GBDT算法思路
- 计算初始学习器值,F0(x) ,计算公式见文中。
- 通过F0(x) 计算负梯度值。
- 将每个特征属性划分节点(左右节点),计算平方损失和。
- 将平方损失和最小的特征属性(如最小有多个选其一)作为树的第一个划分节点(为第一层),然后选取其余特征属性划分第二层,第三层。层数约定为:不能再划分左右节点;不超过约定层数,如约定不超过5层。
- 4步骤为构建树的过程,接下来要计算叶子节点的拟合值,计算公式见上文。这里我们就构建成了一棵树。
- 得到拟合值后,我们计算F1(x) ,每个样本都有一个对应的F1(x),例如F1(x0),F1(x1),F1(x2) 代表样本1,2,3的F1(x) 值。
- 重复2-6步骤,计算第二棵树,和拟合值。
- 这样我们就会得出, , F1(x), F2(x), F3(x),…..以及对应的左右节点的拟合值。
- 最终学习器为F0(x)的值 + 前面所有树的拟合值之和 *系数,这个系数一般为0.1,至于是左节点的拟合值还是右节点的拟合值,要看添加预测的样本最后落在树的哪个节点。
- 加入新样本,进行预测,按照步骤9计算,然后通过公式计算概率,见上文最后一个公式:
P(Y=1∣x)=11+e−F(x)
该匹配算法与传统匹配算法优点
现有的敏感词屏蔽算法主要有DFA算法,基于AC自动机的算法。当前敏感词屏蔽算法在算法性能上有自己的特点,然而只能识别指定敏感词库的词语。这样敏感词库的迭代就需要人力去添加维护,无形之中增加人力成本。
目前机器学习技术很擅长挖掘与目标具有相关联关系的特征,在机器学习领域中,GBDT算法在数据分析和预测中的效果比较好,使用该算法,能有效识别多义词,不同语境下面的词语,一些变异词语,敏感词滥用等。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号