生信学习-Day5-数据结构
原创

花豆寄语!!!!
(1)R的规范赋值符号是 <- ,也可以用 = 代替。
(2)在Console 控制台输入命令,相当于Linux的命令行。
(3)R的代码都是带括号的,括号必须是英文的。
(4)显示工作路径 getwd()。
(5)向量是由元素组成的,元素可以是数字或者字符串。
(6)表格在R语言中称为数据框。
(7)别只复制代码,要理解其中的命令、函数的意思。函数或者命令不会用时,除了百度/谷歌搜索以外,用这个命令查看帮助:?read.table,调出对应的帮助文档,翻到example部分研究一下。
(8)数据类型(重点只有两个,剩下的不看)
①向量(vector)
②矩阵(Matrix)
③数组(Array)
④数据框(Data frame)
⑤List
向量
1.标量和向量的区别

x=c(1,2,3)#常用的向量写法,意为将x定义为由元素1,2,3组成的向量
x=1:10#从1-10之间所有的整数
x<- seq(1,10,by = 0.5) #1-10之间每隔0.5取一个数
x<- rep(1:3,times=2) #1-3 重复2次
2.从向量中提取元素
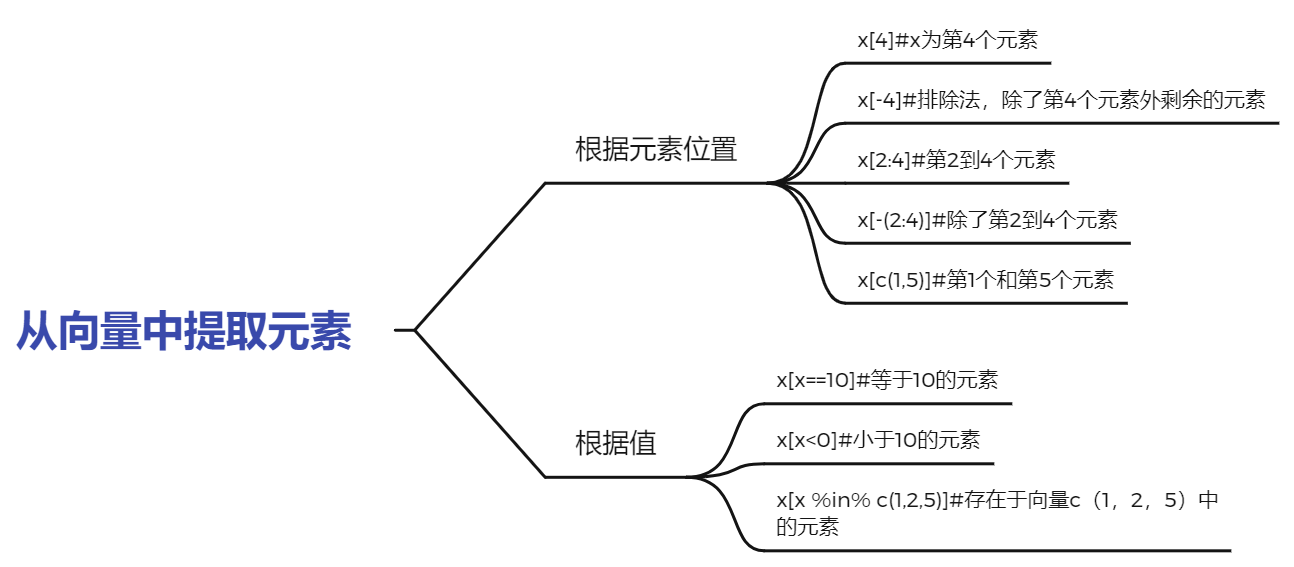
两种主要方法
数据框
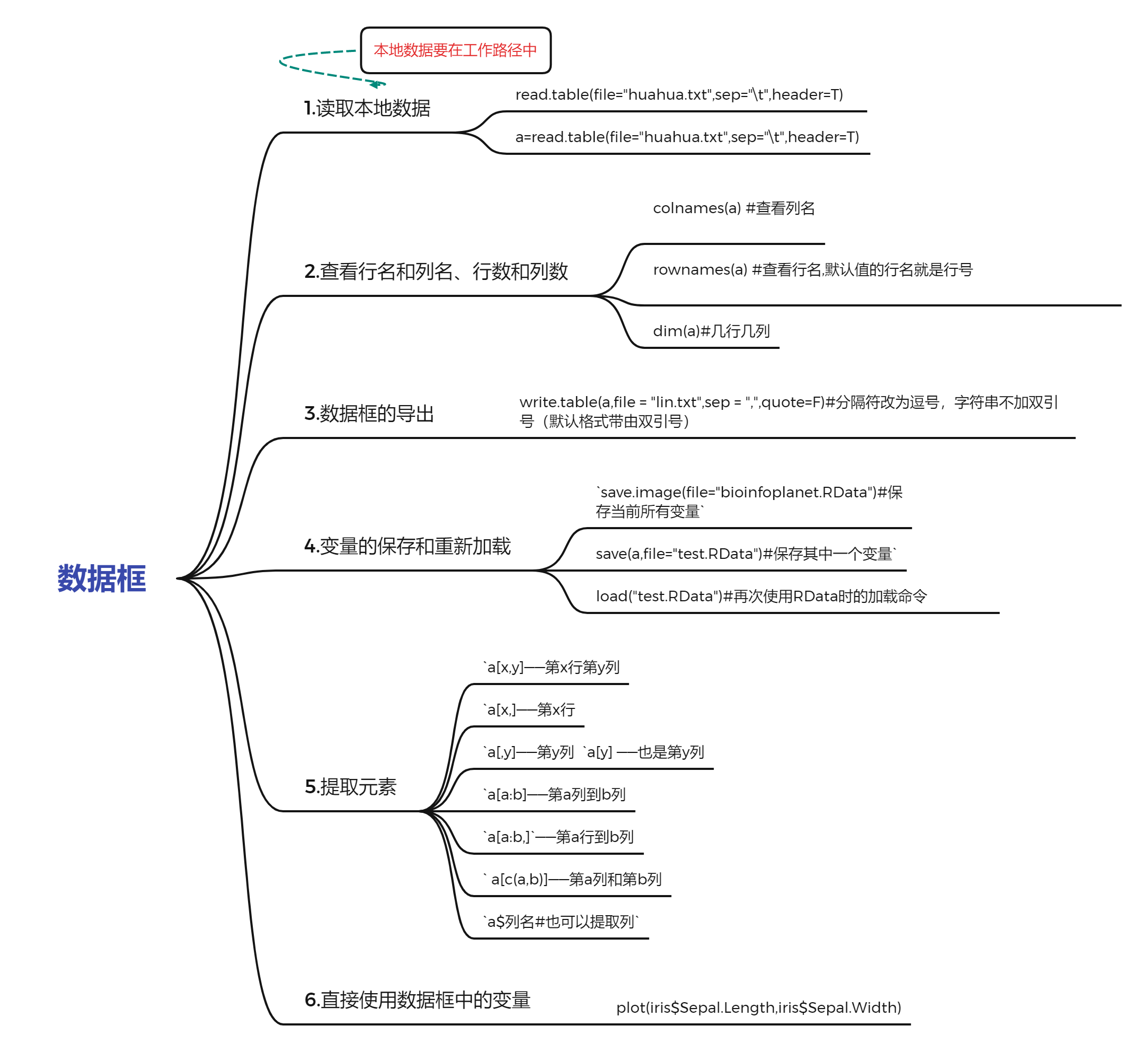
思维导图
如果教程里让你新建,又没说在哪里,你就默认在工作目录下新建。修改工作目录的方法:setwd("")或者可视化修改:在菜单栏中,选择Session > Set Working Directory > Choose Directory...。会出现一个对话框,让您在文件系统中浏览并选择目录。选择目录后,RStudio会自动运行setwd()函数来更改工作目录。
1.读取本地数据
读取:read.table(file="huahua.txt",sep="\t",header=T)
赋值:a=read.table(file="huahua.txt",sep="\t",header=T)
2.查看行名和列名、行数和列数
colnames(a) #查看列名
rownames(a) #查看行名,默认值的行名就是行号,1.2.3.4...
dim(a)#几行几列
3.数据框的导出
chatGPT (1)a: 这是要写入文件的数据。a 应该是R中的一个数据框(data.frame)或其他类似表格结构的对象。
(2)file = "yu.txt": 这指定了输出文件的名称,即将数据写入名为 "yu.txt" 的文本文件中。这个文件将会被保存在当前工作目录下,除非你指定了一个完整的路径。
(3)sep = ",": 这定义了字段之间的分隔符。在这里,它指定逗号(,)作为列的分隔符,这意味着输出的文件将是一个逗号分隔值(CSV)文件,可以用电子表格软件如Microsoft Excel打开。
(4)quote = F: 这指定是否将数据的每个元素用引号括起来。F 是 FALSE 的缩写,意味着在输出的文件中,数据将不会被引号包围。
综上所述,这段代码的作用是将名为 a 的数据集以CSV格式(逗号分隔)写入当前工作目录下的 "yu.txt" 文件,且数据字段不会被引号包围。如果 "yu.txt" 文件已经存在,它将被这个新文件覆盖。
4.变量的保存与重新加载
这次没有处理完的数据下次想接着用怎么办?--学会保存和重新加载。保存的格式是RData。
save.image(file="bioinfoplanet.RData")#保存当前所有变量
save(a,file="test.RData")#保存其中一个变量
load("test.RData")#再次使用RData时的加载命令
您提供的R代码中包含了三个与R数据存储和加载相关的函数的使用:
(1)save.image(file="bioinfoplanet.RData"):这个命令将保存当前R会话中的所有对象(变量、数据框、函数等)到一个名为"bioinfoplanet.RData"的文件中。这个文件会被保存在当前工作目录下,除非您指定了一个完整的路径。
(2)save(a, file="test.RData"):这个命令仅仅保存名为a的对象到一个名为"test.RData"的文件中。这也是一个二进制文件,可以存储任何R对象(比如向量、矩阵、数据框等)。如果您有多个对象要保存,可以一起传递它们的名字,例如save(a, b, c, file="test.RData")。
(3)load("test.RData"):这个命令用于加载之前保存的"test.RData"文件。这会将文件中的对象恢复到当前R会话中。如果这个文件包含了对象a,那么a将被重新创建在当前环境中。
请注意,使用load()函数时,它将直接在当前环境中恢复对象,不需要赋值给一个变量。如果文件中的对象在当前环境中已存在,它们将被覆盖。因此,在使用load()之前,请确保您不会意外覆盖重要的数据。
5.提取元素
a[x,y]#第x行第y列
a[x,]#第x行
a[,y]#第y列
a[y] #也是第y列
a[a:b]#第a列到第b列或者 a[,a:b]
a[a:b,]#第a行到第b行
a[c(a,b)]#第a列和第b列
a$列名#也可以提取列(只能提取一列)
6.直接使用数据框中的变量
plot(iris$Sepal.Length,iris$Sepal.Width)
问题:save(a,file="test.RData")这句代码如果报错object a not found,是为什么,应该怎么解决?
(1)对象未定义:在尝试保存之前,您可能没有创建或定义对象 a。确保在执行 save() 函数之前,对象 a 已经在您的R环境中被正确创建并包含了数据。
(2)拼写错误:可能是您在引用对象时拼写错误。检查对象名 a 是否正确,注意R是区分大小写的。
(3)对象不在当前环境:如果您正在使用某种形式的作用域(如函数内部),a 可能不在当前作用域中。
为解决这个问题,您可以:
(1)确保在执行 save() 之前创建并赋值给 a。例如:
a <- [您的数据]
save(a, file="test.RData")
(2)检查 a 是否已经存在于您的环境中。您可以使用 ls() 函数列出当前环境中的所有对象,以确认 a 是否存在:
ls()
(3)如果 a 是在某个特定环境(例如函数内部)中创建的,确保在正确的作用域内进行操作,或者将 a 传递到可以访问它的作用域中。
(4)检查是否有任何拼写错误,包括大小写错误。
通过这些步骤,您应该能够识别并解决 "object a not found" 的错误。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号