FLATTEN: 针对文本到视频一致性编辑的光流引导注意力机制

FLATTEN: 针对文本到视频一致性编辑的光流引导注意力机制

用户1324186
发布于 2024-02-21 17:34:28
发布于 2024-02-21 17:34:28
来源:ICLR2024 作者:Yuren Cong 等 论文题目:FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing 论文链接:https://arxiv.org/pdf/2310.05922.pdf 项目主页:https://flatten-video-editing.github.io/ 内容整理:陈相宜 文本到视频编辑任务中的一个主要挑战是确保编辑后视频的帧间一致性。最近的研究致力于将文生图扩散模型应用于视频编辑任务,通过将U-Net中的2D空间注意力机制扩张为3D时空注意力机制。尽管扩张后的时空注意力机制能提供跨越时间维度的信息,但这可能会为每个图像块引入一些不相关的信息,因此导致编辑后视频时间一致性较差。因此本文提出了FLATTEN,它将光流引入了扩散模型U-Net中的注意力模块。具体来说,FLATTEN 强制使不同帧上处于相同光流路径上的图像块在注意力模块中相互关注,以此提高编辑后的视频一致性。FLATTEN 无需训练,并且可以无缝集成到任何基于扩散的文本到视频编辑方法中,来提高它们的视觉一致性。实验证明,在文本到视频编辑基准任务上,FLATTEN实现了新的SOTA。
引言
最近,文本到视频(T2V)编辑引起了广泛关注。与文本到图像(T2I)编辑相比,文本到视频编辑面临的一个关键挑战是视觉一致性。这意味着,编辑后视频中的内容在所有帧中应该具有平滑且不变的视觉外观,并且编辑后的视频应尽可能保留源视频的运动。
由于文生视频的基础扩散模型通常需要大量计算资源,并且很多模型并未开源,因而大多最近的研究尝试将现有的文生图模型扩张成文本引导的视频编辑模型。他们通过将空间自注意力扩张为时空自注意力来实现这一目标。具体而言,在扩张的密集时空注意力模块中,每一帧上的每个图像块都关注视频中其他帧中的所有图像块,并聚合它们的特征。然而,这种简单的扩张为视频编辑引入了不相关的信息。这是由于视频中的不相关图像块互相注意可能会误导注意力的生成过程。这对编辑后视频的跨帧一致性控制构成了威胁。
本文首次提出了一种光流引导的注意力机制FLATTEN。我们首先使用预训练的光流预测模型来估计源视频的光流。然后,使用估计的光流来计算图像块的轨迹,引导图像块之间的注意力机制。具体而言,FLATTEN强制使处于相同光流路径上的不同帧上的图像块在注意力模块中相互关注。此外,我们提出了一种有效的方法将光流引导的注意力集成到现有的扩散生成模型中。
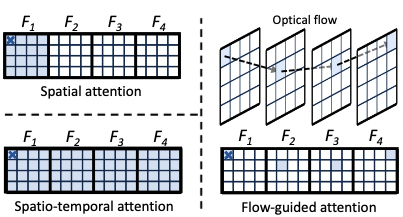
图1 展示了空间注意力、时空注意力和本文提出的光流引导的注意力
方法
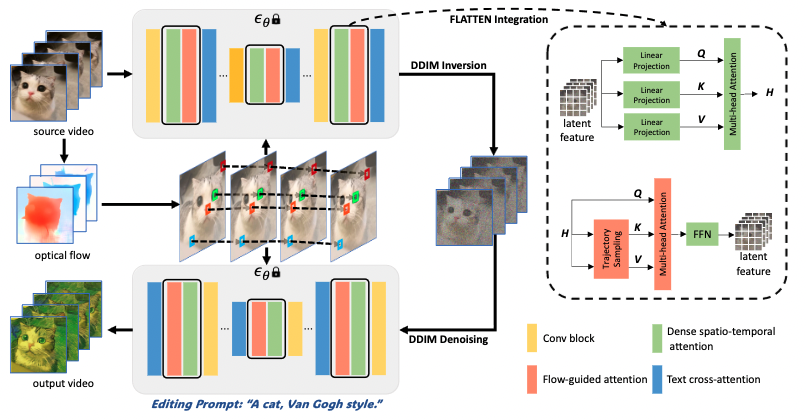
图2
我们的模型旨在根据编辑文本提示
编辑源视频
,输出一个视觉上与文本一致的视频。为此,我们在时间维度上扩张了 T2I 扩散模型中的 U-Net 架构。我们将光流引导的注意力融入到 U-Net 中,无需引入新的参数。我们使用重新设计的 U-Net 结合 DDIM 逆转来从源视频中估计潜在噪声
。最后,我们使用潜在噪声
和文本提示
进行 DDIM 过程生成编辑后的视频。
U-Net 扩张
与之前的工作相同,我们在时间维度上扩张了原始文本到图像 U-Net 中的卷积残差块和空间注意力块。卷积残差块中的 3×3 卷积核通过添加一个伪时间通道转换为 1×3×3 的卷积核。我们将原本的空间自注意力扩张成密集时空自注意力。原本的空间自注意力策略仅计算单个帧中的图像块之间的注意力关系。相反,在扩张的密集时空注意力中,整个视频中所有帧的所有图像块嵌入被用来作为查询(
)、键(
)和值(
)。换言之,视频中不同帧的所有图像块相互关注。
光流引导的注意力机制(FLATTEN)
我们将本文提出的光流引导的注意力机制(FLATTEN)与密集时空注意力结合起来。给定潜在视频特征,我们首先执行密集时空注意力,其结果表示为
。我们直接将
作为光流引导注意力的输入。在执行光流引导注意力之后,输出被发送到来自密集时空注意力块的前馈网络。
光流预测
给定源视频中的两个连续的 RGB 帧,我们使用 RAFT 来估计光流得到密集位移场
。每个像素
在第
帧中的坐标可以根据
投影到其在
帧中的相应坐标。具体表达为,
我们将所有帧对的位移场下采样到潜在空间的分辨率得到潜空间位移场
。
图像块轨迹采样
我们从第一帧的图像块开始。对于图像块中坐标为
的像素点,我们根据潜空间位移场
推导其在所有后续帧上的对应坐标。图像块轨迹序列表示为
真实世界视频中,一些图像块的内容会随着时间消失,一些新的图像块又会出现。为了简化光流引导注意力的实现,当发生遮挡时,我们随机选择一个轨迹继续采样,并停止其他冲突的轨迹。这一策略确保视频中的每个图像块都被唯一地分配给一个单独的轨迹。
注意力计算过程
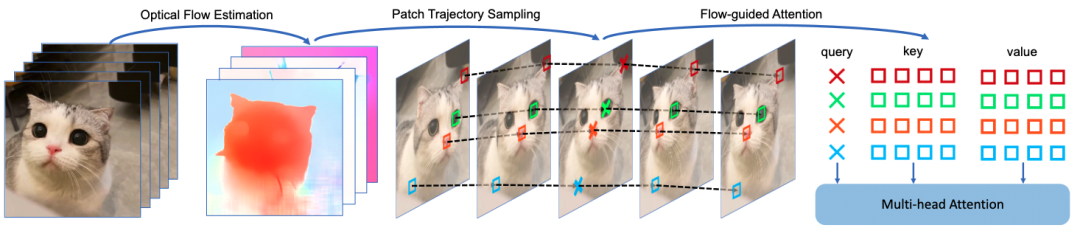
图3
在轨迹
上的图像块的嵌入表达可以表示为:
我们对相同轨迹上的图像块嵌入执行多头注意力。对于查询
,相应的键和值是同一轨迹上的其他图像块嵌入
。注意,我们无需引入额外的位置编码。光流引导注意力可以表示如下:
潜在特征
根据通过光流引导注意力更新,有助于消除密集时空注意力中不相关图像块的特征聚合所带来的,对视频帧间一致性的负面影响。
实验
实验设定
数据集
FLATTEN 的评估使用了来源于 LOVEU-TGVE 的 53 个视频(https://sites.google.com/view/loveucvpr23/track4)。其中 16 个视频来自 DAVIS,37 个视频来自 Videvo。视频的分辨率被重新调整为 512 × 512。每个视频包含 32 帧。
评估指标
我们使用 CLIP 来衡量编辑后视频帧与文本提示之间的平均余弦相似度,表示为
,以此评估文本忠实度。我们使用流变形误差
来评估视觉一致性。我们还提出
作为综合考量的主要评估指标。额外地,我们还采用
(它计算所有帧的CLIP表达间的平均余弦相似度),以及 PickScore(它表示与人类偏好的估计对齐程度),来评估视频质量。
训练细节
FLATTEN 无需任何训练或微调步骤。我们使用 RAFT 进行光流估计。我们采用 100 个时间步长用于 DDIM 逆转,以及 50 个时间步长用于 DDIM 采样。
定量和定性比较
定量比较
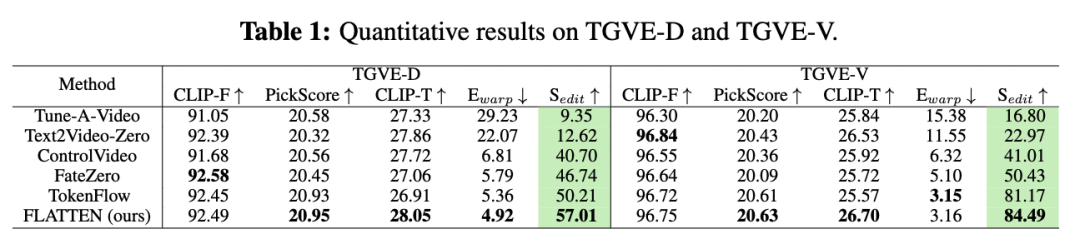
表1
表1显示了FLATTEN与现有方法的定量比较,表格中的
/
/
的值被放大了 100/100/1000 倍。FLATTEN 在 CLIP-T、PickScore 和综合编辑评分
方面优于其他比较方法。就变形误差
而言,我们的方法略低于 TokenFlow。但在考虑文本忠实度时,我们的 CLIP-T 得分显著更高。Text2Video-Zero 在 CLIP-F 和 CLIP-T 上得分较高,但在视觉一致性方面表现较差。尽管 FateZero 在 TGVE-D 上的 CLIP-F 最高,但其输出视频有时与源视频非常相似。总的来说,FLATTEN在综合评分上优于其他所有比较方法。
定性比较

图4
上图展示了分别来自DAVIS和Videvo数据集的对比编辑结果。可以看出,FLATTEN在时间一致性和与编辑文本的契合程度方面明显优于现有的文本到视频编辑方法。
消融性实验
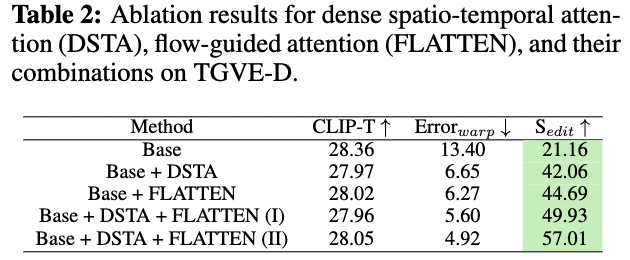
表2
我们从我们的框架中分别剔除密集时空注意力(DSTA)和光流引导注意力(FLATTEN)作消融实验。更进一步,我们还以两种不同的方式将DSTA和FLATTEN结合起来,并探索它们的有效性:(I)密集时空注意力的输出被发送到线性投影层,以重新计算FLATTEN的查询、键和值;(II)DSTA的输出直接用作FLATTEN的查询、键和值。我们发现,第一种组合有时会导致模糊,从而降低了编辑质量。第二种组合效果更好,并被采纳为最终解决方案。对消融研究的定量结果见表2。
结论
我们提出了 FLATTEN,一种新颖的光流引导注意力方法,用于改善文本到视频编辑的视觉一致性,并呈现了一个无需训练的框架。此外,FLATTEN 还可以无缝集成到任何其他基于扩散的 T2V 编辑方法中,以提高它们的视觉一致性。我们进行了全面的实验来验证我们方法的有效性,并证明FLATTEN在现有的文本到视频编辑任务基准测试上实现了新的SOTA。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-02-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号