具身智能中的多模态三维感知思考

具身智能中的多模态三维感知思考

OpenMMLab 官方账号
发布于 2024-03-07 14:18:11
发布于 2024-03-07 14:18:11
本期精彩
从驾驶场景到室内场景,具身三维感知系统面对的是更复杂的室内语义,更多样的物体类别和朝向,以及大不相同的感知空间和需求。重新思考其中差异和数据基础,EmbodiedScan 团队构造了一套基于第一视角的多模态全场景三维感知系统/工具包,从数据标注到模型训练,从基准构建到任务评测,以大规模真实场景扫描和面向下游的全面标注为基础,训练出一套可直接部署、且在开放场景表现优异的基础模型,旨在构建一套可量化的、面向通用具身场景的感知系统基准,并希望通过开源推动领域发展。
本期社区开放麦,我们特别邀请到上海人工智能实验室青年研究员王泰带来《具身智能中的多模态三维感知思考》的分享,该研究近期被 CVPR 2024 接收,更多精彩内容请锁定本周四晚 20:00 的社区开放麦直播。
分享内容
•从驾驶场景到室内场景:新的问题与挑战
•EmbodiedScan:首个多模态、基于第一视角的真实场景三维感知数据集
•Embodied Perceptron:适配任意帧输入的统一基线框架
•从 Benchmark 看 EmbodiedScan 的价值
•未来工作:从开源到比赛,共建具身智能研究社区

王泰
博士毕业于香港中文大学 MMLab,现为上海人工智能实验室青年研究员,研究方向为三维视觉和具身智能。过往工作有十余篇论文在顶级会议上发表,在 nuScenes,Waymo 等竞赛中多次获奖,曾获 ICCV 纯视觉 3D 检测研讨会最佳论文。其中一系列工作如 FCOS3D, Cylinder3D, DfM 以及相应的开源算法库 MMDetection3D 在学界和业界具有广泛影响。
内容详情

图1:EmbodiedScan 训练出的模型迁移部署到 Kinect 上后在开放场景(in the wild)中的测试
从动机和差异性看我们的数据集
本次报告将从不同场景的对比出发,首先回顾之前研究相对较多的驾驶场景和室内具身场景中感知问题的具体差异。从输入角度考虑,室内场景下 RGB-D 传感器成本一般都是可接受的,而且一般伴随着给予机器人的指令。因此某种程度上讲,使用第一视角的多模态输入是常态。其次,从感知内容上讲,物体类别数不必赘述,large-vocabulary 和 open-vocabulary 是常态;物体朝向也更加多样,在深度一般更容易估计的情况下,物体朝向的预测要困难的多,也会更加多样且更加重要,在这方面我们虽不一定做到 6D pose 那种准确程度,但也提出了更高的要求;另外,自身的定位是特别的难点,相比驾驶场景,室内没有了 GPS,只能更多依靠 IMU 以及一些 SLAM 的方式计算;最后,室内场景空间相对封闭、大小有限,虽感知范围有所减小,但遮挡严重,且经常需要建图和更新地图以支持物体的查找、导航等下游需求,而建图本身不包含语义、且建图前需要依赖感知来避障,如何将感知和建图更好地融合在一套系统中是一个在此场景下独有的问题。
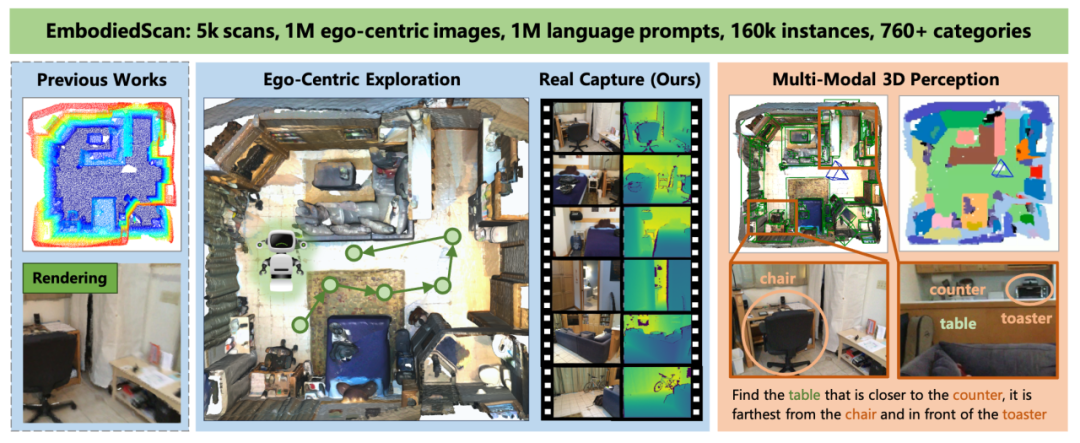
图 2:EmbodiedScan 提供了一个多模态、基于第一视角的三维感知数据集,其中包含大量的真实扫描数据和全面且丰富的标注,从而构建了一个针对真实世界机器人基于语言的三维场景整体理解方面的评测基准。
除了自动驾驶场景的数据集之外,其实很早之前,甚至在大家现在常用的 ScanNet 之前,也已经有了 SUN RGB-D 和 NYU Depth v2 等数据集专注在室内的感知研究上。更有另外一批 embodied AI 的研究人员已经收集了大到 1000 个 building 的巨大室内真实扫描数据 Habitat-Matterport 3D。那我们的数据和这些工作有什么不同?我们在报告中将从 1) 第一视角、真实扫描的重要性,2) 小物体也覆盖,更系统的物体类别和朝向标注,3) 面向下游的全面标注 三个方面展开介绍了 EmbodiedScan 数据集的独特性。除了分析与之前数据在统计上的差异之外,还会介绍我们自己开发的一套标注工具,结合 SAM 的预训练模型,实现大小物体覆盖、带朝向的三维物体框标注。
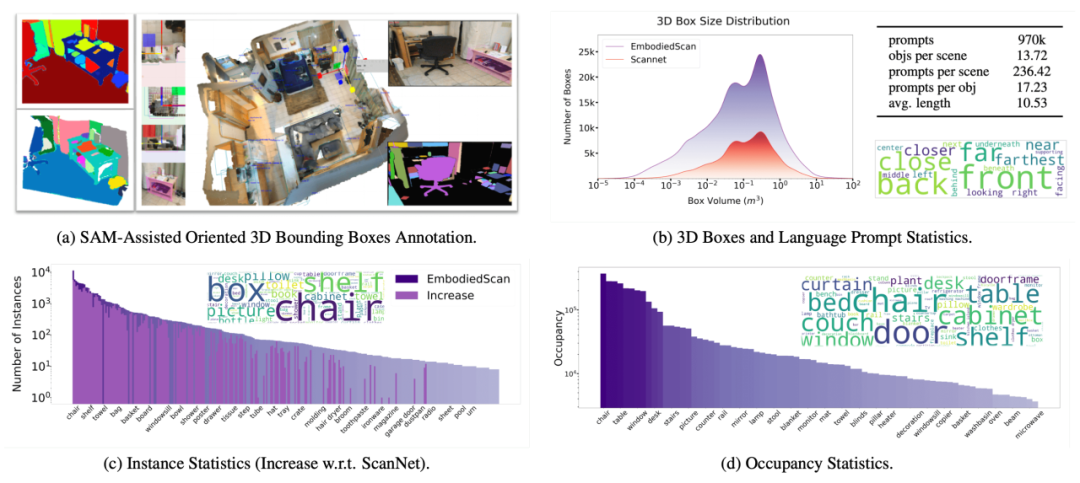
图 3:SAM 辅助标注示意图和相关标注定量统计

图 4:SAM 辅助标注的过程和界面。点一下相应物体的 mask,便会初始化一个框用来进一步调整
配套的基线方法
介绍完我们的数据和标注之后,更重要的事情还是利用这些数据能够训练出来一个真正好用的模型。基于上述分析,我们的模型需要读入任意帧的 RGB-D 序列,配合语言指令,能够实现 sparse (检测) / dense (occupancy) / grounding 三种下游任务,因此有了如图 5 所示的基线框架,我们暂且称之为 Embodied Perceptron。这套框架首先采用不同模态的预训练网络(稀疏卷积的 Mink ResNet / 图片的 ResNet / BERT)分别处理三种模态数据,而后针对稀疏和稠密的下游任务分别在点云/预设网格点上进行特征融合,再配合相应的预测头输出;同时稀疏点云的特征和语言特征融合进行相应的视觉定位,整体框架简单统一且有效。值得一提的是,在进行稀疏特征融合的时候,我们发现低层/高层特征在每个特征层分别做融合,要比只采用经过 FPN 后的高层图像特征效果更好,训练也更稳定。其中更多的算法侧细节请详见论文和开源代码。
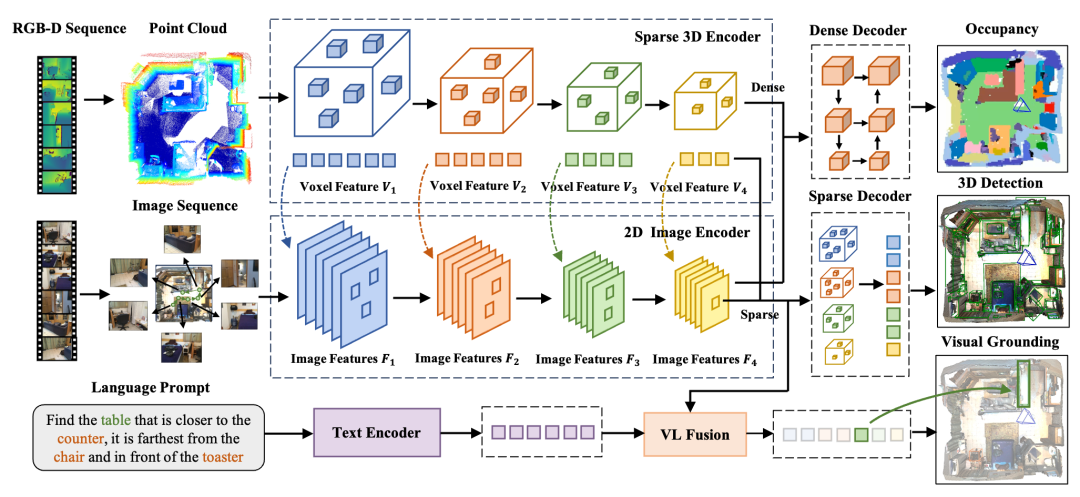
图 5:基线方法框架示意图
从基准和实验看 EmbodiedScan 的价值
一些常规性量化实验结果
最终我们构建了针对传统感知任务和多模态场景理解的两套基准,其中传统感知任务包括 3D 目标检测和 semantic occupancy 预测,而多模态场景理解以多视角三维视觉定位作为初步尝试。针对实际使用场景,我们还提出了连续(continuous)感知的 setting,即从第一帧开始,每帧都评估到目前为止场景中可见物体检测的准确率。我们实现了一系列领域内相关任务的工作,以构建一个原始的基准供社区后续持续研究。在这过程中我们发现,这些传统任务仍然没有实现令人满意的性能,体现了在我们这个 setting 下仍然存在较大的研究空间。另外我们在实验结果中也发现了一些合理且有趣的现象,比如稀疏输出的检测任务中,基于纯深度点云已经可以实现一个接近多模态的性能(17.16→19.07);而稠密输出的 occupancy 预测任务中,视觉的输入能够帮忙纯深度点云的方法实现一个长足的提升(14.44→20.09)。最后,我们针对 EmbodiedScan 的核心价值做了定量分析,包括带朝向的三维框、原始 RGB-D 输入的影响、真实扫描 vs. 渲染图以及数据量的增益。更多定量的实验结果和分析请详见论文。
开放场景测试
除了定量的分析之外,更让我们感到欣喜的是算法在开放场景(in the wild)中的可迁移性和良好性能。我们采用与训练数据不完全相同的 RGB-D 传感器( Kinect )在实验室的室内场景中做了几组测试,推文最开始的图 1 是其中一组预测结果的可视化(并没有挑选一些特例,测试的所有结果详见项目主页完整版视频)。可以看到我们的模型能够很顺利地部署到一个新的设备上,并且在新的环境中有相当不错的表现,这也正呼应了我们的初衷,希望能够推动最终实现真正“通用”、“好用”的具身感知系统。
相关内容
论文:
https://arxiv.org/abs/2312.16170
项目:
http://tai-wang.github.io/embodiedscan
代码:
https://github.com/OpenRobotLab/EmbodiedScan
比赛:
https://opendrivelab.com/challenge2024/#multiview_3d_visual_grounding
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号