MultiFS: 深度推荐系统中的自动多场景特征选择


标题:MultiFS: Automated Multi-Scenario Feature Selection in Deep Recommender Systems 论文链接:https://dgliu.github.io/pubs/WSDM_2024_MultiFS.pdf 代码地址:https://github.com/dgliu/WSDM24_MultiFS 会议:WSDM 2024
1 引言
传统的多场景推荐系统(MSRS)通常不加区别的使用所有相关的特征,忽视了特征在不同场景下的不同重要性,往往会导致模型性能下降。本文提出了多场景特征选择(MultiFS)框架来解决此问题,MultiFS能考虑场景间的关系,并通过分层门控机制为每个场景选择独特的特征。
具体的做法为:MultiFS首先通过场景共享门控机制获取所有场景下的特征重要性;然后通过场景特定的门控机制,从前者较低的重要性特征中识别出场景独特的特征重要性;最后对这两个门控机制进行约束使得模型可学习,将两者结合起来为不同场景选择不同的特征。
2 问题定义
对于单场景中成对的用户和item,定义X和Y分别为特征空间和标签空间。X由用户特征、item特征和上下文特征组成,Y定义为用户行为,通常为二元标签。当同时含有K个场景时,通常由共享和特定组件组成多场景模型:
其中f代表特征到标签的映射函数,
代表场景共享参数,
代表场景特有参数,损失通常采用交叉熵函数。 基于上述公式进一步定义 MSRS 的特征选择问题,通常情况对于特征向量
有m个特征域,为更好的表征原始特征,推荐系统中会使用embedding table来映射原始特征,MSRS中的特征选择问题定义为:对每个场景的embedding table 应用门控掩码操作,并产生相应的掩蔽embedding table,即:
门控掩码由场景共享门控向量和相关的场景特殊门控向量组成
3 网络结构
3.1 框架概述
MultiFS的整体框架如图所示,遵循多场景学习的主要框架,首先特征掩码被分解成两种类型,共享掩码(蓝色标记)专注于选择在所有场景中都有用共享特征,而特定掩码(其他颜色标记)服务于特定场景,该掩码过滤了对该场景无用的特征。因此特定掩码的集合可以根据共享掩码来确定。注意,一个样本只会属于一个场景,并将被用来训练共享网络和对应场景的特定网络。这意味着共享掩码和特定掩码的组合将为embedding table产生embedding掩码,进而转换该样本的特征。
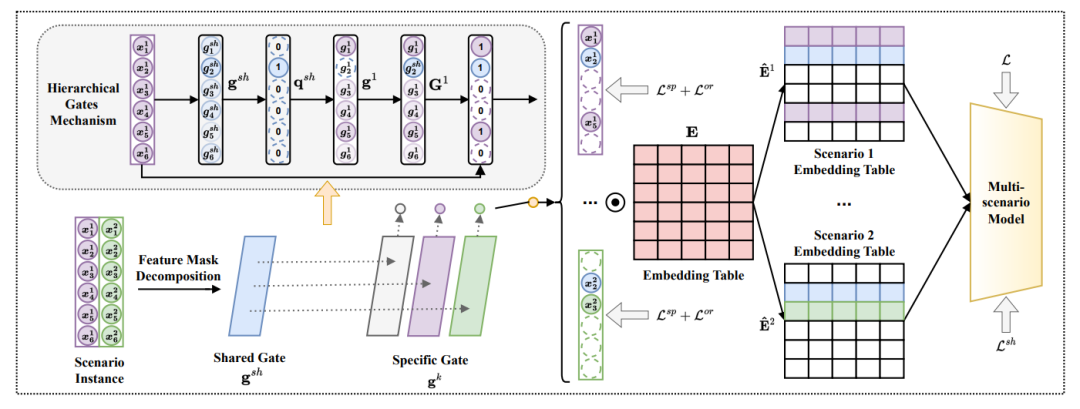
3.2 特征掩码分解
为解决MSRSs在选择特征值时面临的难以处理的大搜索空间问题,MultiFS第一步采用分解特征掩码,目标是确定一组场景特定的特征门控。将场景特征选择表述成为每个特征emb表征分配一个二进制门控向量。向量中的0-1值表示丢弃或者保留这个特征。通过选择后,特征表征可以表述如下:
然而,MSRSs中的场景之间通常有许多重叠的特征,因此独立优化每个门控G无法有效利用跨场景的共享信息。于是引入了场景共享特征门控来识别有用的共享特征。我们可以将每个G分解为场景共享特征选择和场景特定特征选择:
3.3 分层门控机制
为获得有效且统一的门控机制G,需要克服两个挑战:1.二元门控向量
和
的梯度难以计算;2.优化门控掩码G和网络参数可能会损害模型的性能。因此引入层次化门控机制,采用learning-by-continuation的训练方法,训练过程如上图左上角。
为了有效的优化G,引入连续的场景特定门控向量集
和连续的场景共享门控集
,因此二元门控向量分别定义为:
其中
是sigmoid函数。通过在训练期间用连续门控向量替换掩码,可以以可微的方式优化门控向量和网络参数。然而连续门控将使得难以层次化地获取剩余特征,针对这种情况,本文在训练期间对场景共享门控使用直通估计操作S(),即在前向预测时将其转换为二进制代理掩码,同时保持反向可微性属性。
其中e是可学习的阈值,于是门控机制变成
通过T轮的训练后,最终可得
3.4 训练优化
首先为保证门控向量的稀疏性,引入L1正则
其次,理想的MSRS应该使场景特定的表示彼此解耦,因此本文设计了一个正交惩罚项如下:
然后多场景数据集中不平衡的数据分布会影响性能,对多场景特征选择也是有害的。例如,假设一个场景的样本太少,将导致难以有效优化该场景的特征掩码,将影响整个模型的性能。为了解决这个问题并确保本文方法的普适性,引入了对
的单一预测作为嵌入掩码,相应的损失可以表述如下:
最终的loss定义为:
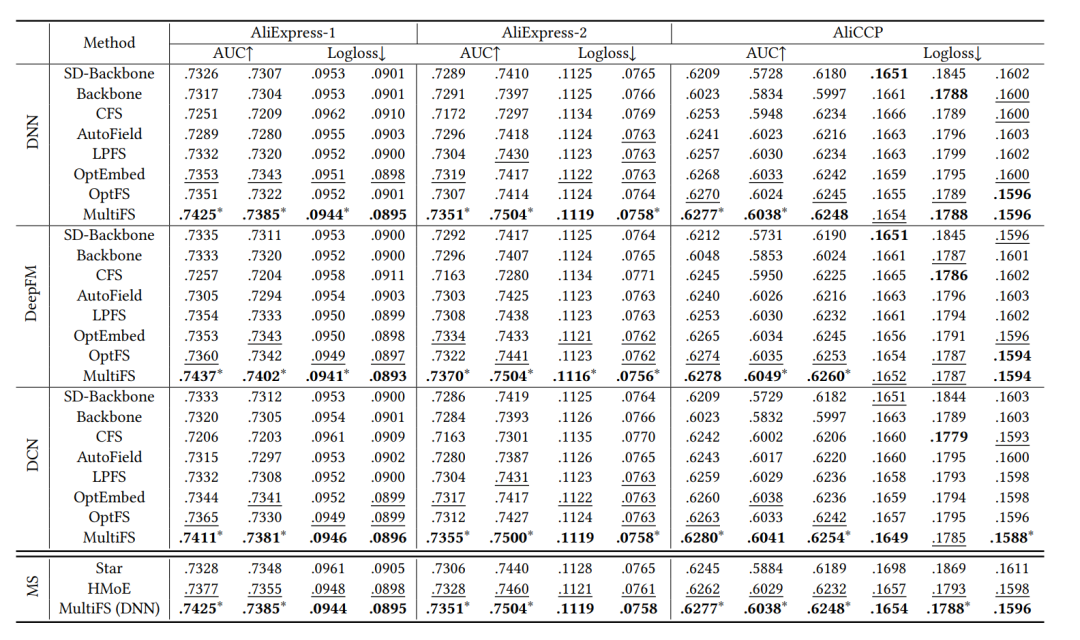
4 实验效果
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号