CVPR2024 | DCNv4来袭,更快收敛、更高速度、更高性能!

CVPR2024 | DCNv4来袭,更快收敛、更高速度、更高性能!

AIWalker
发布于 2024-03-18 18:39:53
发布于 2024-03-18 18:39:53

https://arxiv.org/pdf/2401.06197.pdf https://github.com/OpenGVLab/DCNv4
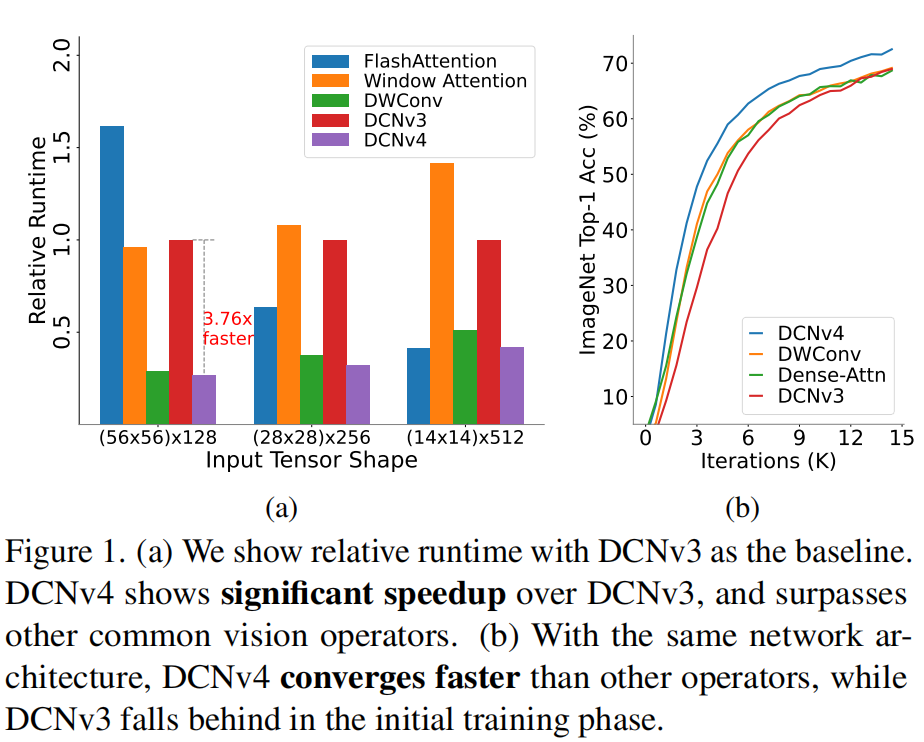
本文介绍了一种高效和有效的算子DCNv 4,它是专为广泛的视觉应用而设计的。与其前身DCNv 3相比,DCNv 4有两个关键增强功能:(1) 去除空间聚合中的softmax归一化,以增强其动态性和表达能力;(2) 优化存储器访问以最小化冗余操作以加速。这些改进显著加快了收敛速度,并大幅提高了处理速度,DCNv 4实现了三倍以上的前向速度。
在各种任务中,包括图像分类、实例和语义分割,特别是图像生成中,DCNv 4表现出卓越的性能。当集成到潜在扩散模型中的U-Net等生成模型中时,DCNv 4的性能优于其基线,强调了其增强生成模型的潜力。在实际应用中,在InternImage模型中使用DCNv 4替换DCNv 3创建FlashInternImage,可以在不进行进一步修改的情况下将速度提高高达80%,并进一步提高性能。DCNv 4的速度和效率的进步,以及其在各种视觉任务中的强大性能,显示出其作为未来视觉模型基础构建块的潜力。
本文方案
重思考DCNv3的动态属性
给定输入
,带K个点的DCNv3算子可以描述如下:
注:
表示空域聚合权值,
表示预定义采样点,
表示每个采样点的偏移。
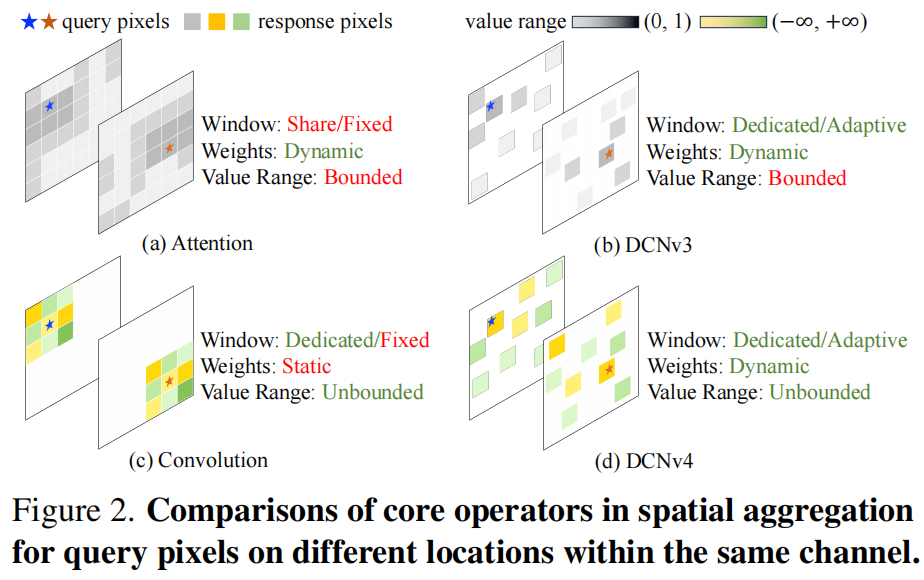
DCNv3可视作卷积与注意力的组合,它一方面以滑动窗口形式对输入进行处理,遵循卷积的计算流程,另一方面采样偏移与空域聚合权值又与输入相关,达成了类似注意力的动态属性。
从图示可以看到,卷积与DCNv3的一个关键差异在于:DCNv3对空域聚合权值进行softmax规范化,这种处理延续了自注意力机制的点乘处理。相反,卷积并未对其权值进行规范处理且表现良好。
为什么自注意力需要softmax呢?从其定义出发(见上式),如果没有softmax,
先进行计算,进而退化为在相同的注意力窗口内对所有query执行线性投影,进而会出现显著的性能下降。
但是,对于卷积与DCNv3而言,每个点有其自身的聚合窗口,且聚合窗口内信息存在差异性,即没有"key"的概念,上述退化问题就不再存在,也就是说:规范化操作并非必需。
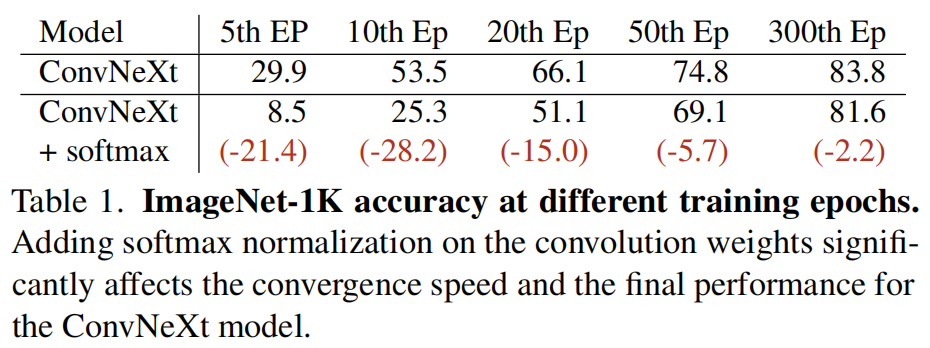
作者基于ConvNeXt进行了上述论证,见上表。可以看到:当引入softmax后,模型出现了明显的性能下降。也就是说,对于滑动窗口类算子(如卷积、DCN),无界限聚合权值可以提供更强的表达能力。
基于上述发现,作者移除了DCNv3中的softmax规范化,将调制因子的范围从[0,1]变为无界限动态权值。通过这种简单的调整,DCNv4取得了更快的收敛速度。
加速DCN
理论上,DCN应当具有比其他大窗口稠密算子(如
深度卷积、稠密注意力)更快的处理速度,但事实并非如此,见前述Fig1a。针对此,作者首先对GPU进行了理论分析并发现:不同的内存读取方式会导致极大的访存消耗。基于此,作者进一步对通过节省额外内存指令显著改善了DCN访的处理速度,将稀疏运算的速度优势变成了现实。
假设输入与输出尺寸均为
,DCNv3计算量为
FLOPs(注:
窗口,因子4用于补偿双线性插值),MAC为
(
,
),这是理想情况。
为估计最大访存需求,我们考虑一个没有告诉缓存的情况:每个输出需要fresh内存读取,包含36个读取、27个偏移/聚合权值、一个写操作,即
,大约是理想情况的17倍。
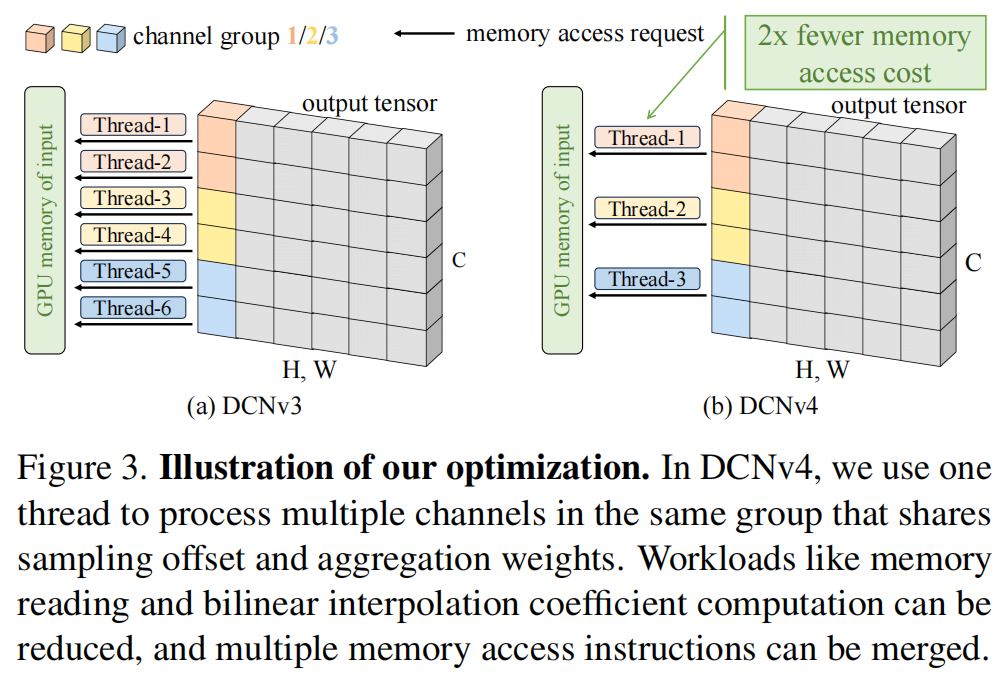
在实际执行时,现在的DCN内核计算起来更加轻量级,因为对所有的
通道只需要执行一次双线性插值,从而节省了大量的时间。而大部分工作负载是从不同通道读取输入信息。当内存排布给是为NHWC时,所有的
是连续的,我们可以利用向量加载(比如,一次指令读取4个32位浮点数,而不是通过四个指令读取四次,进而减少了指令数与每个线性执行时间)。我们将类似的技术应用于GPU写入处理以减少访存时间提升带宽利用。此外,fp16/bf16数据格式可以进一步改善访存效率。
DCN模块微观改造
在引入上述优化后,在DCNv3模块还有以下两点可以进一步优化:
- 移除softmax后,调制因子变成了动态聚合权值,那么用于计算偏移与动态权值的线性层就可以合成一个,这可以进一步减少网络碎片化,进而消除额外负载,提升运行效率;
- 在原始DCNv3模块中,复杂子网络(
深度卷积+LN+GELU+线性层)用于计算偏移与动态权值。参考Xception设计,作者移除了LN-GELU仅采用原始分离卷积结构,进一步减少了运行耗时。作者进一步发现:如果延迟优先级非常高,甚至可以移除深度卷积且仅造成轻微性能牺牲。
本文实验
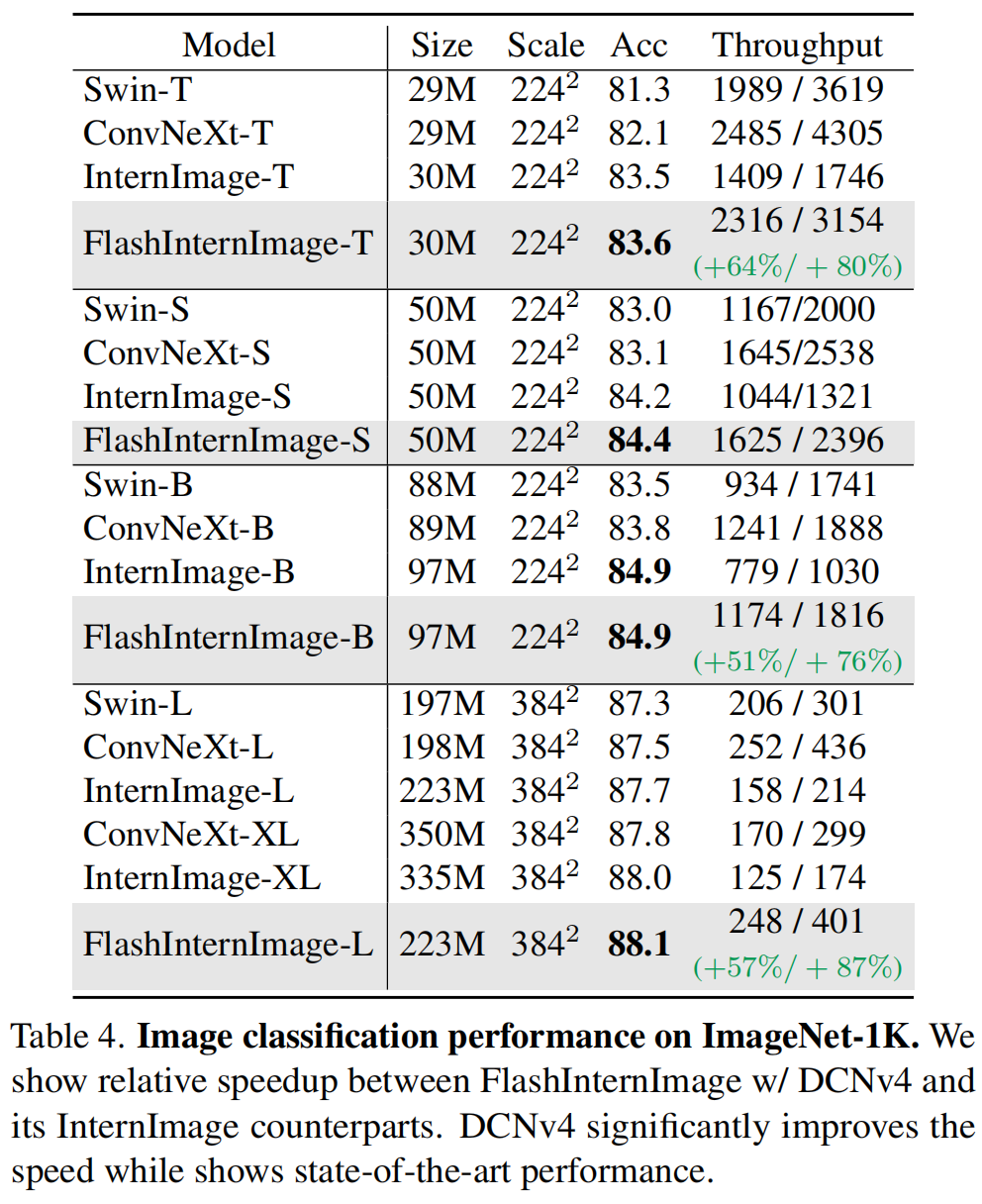
上表为ImageNet分类任务上不同方案性能对比,可以看到:
- 加持DCNv4后,FlashInternImage大幅改善了InternImage的吞吐量约50%~80%,同时性能轻微提升;
- FlashInternImage在推理速度上媲美ConvNeXt,但精度更高,达成更优速度-精度均衡。
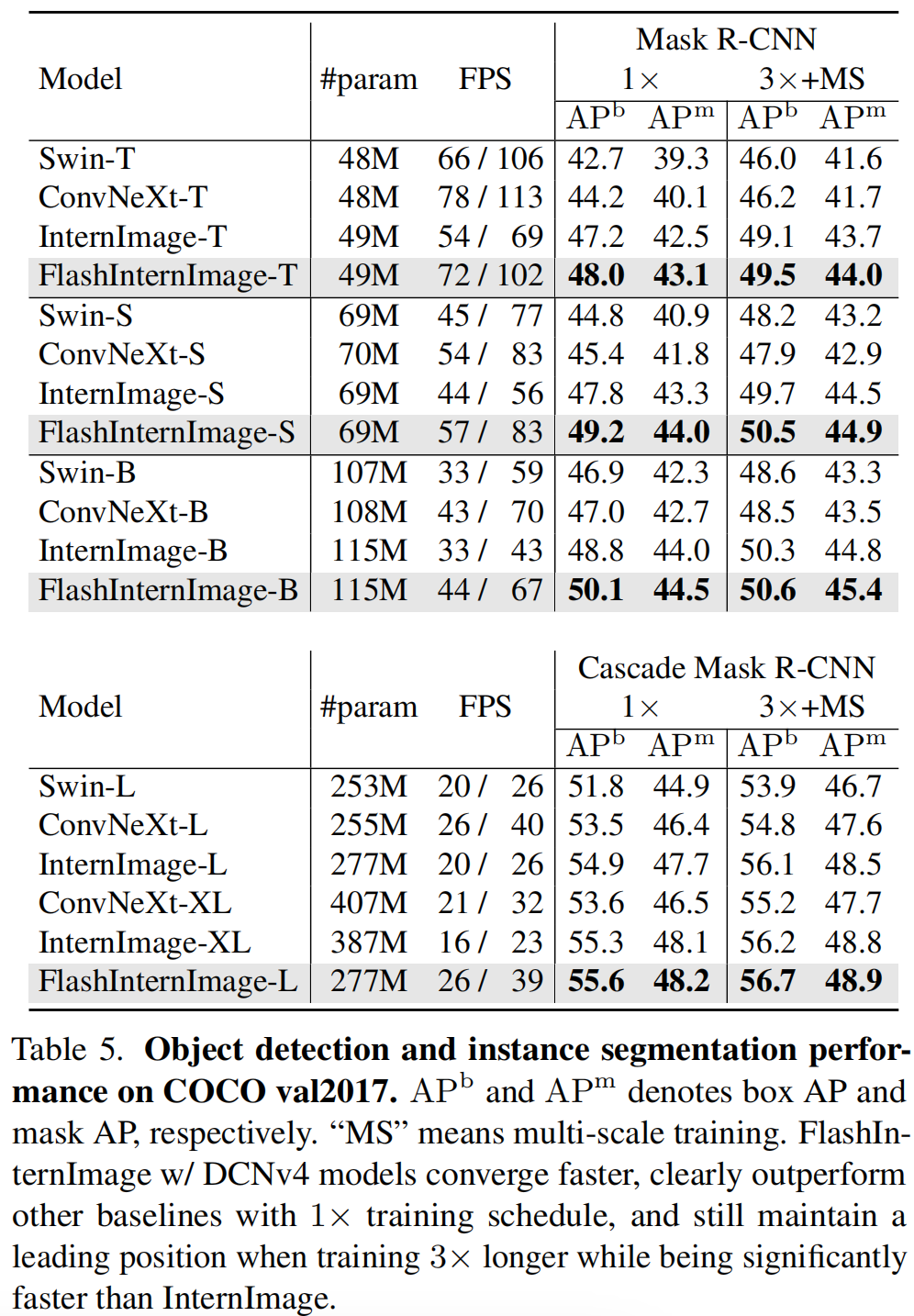
上左表为COCO分割任务上不同方案性能对比,可以看到:FlashInternImage在所有模型尺寸上均表现出了优异的性能。
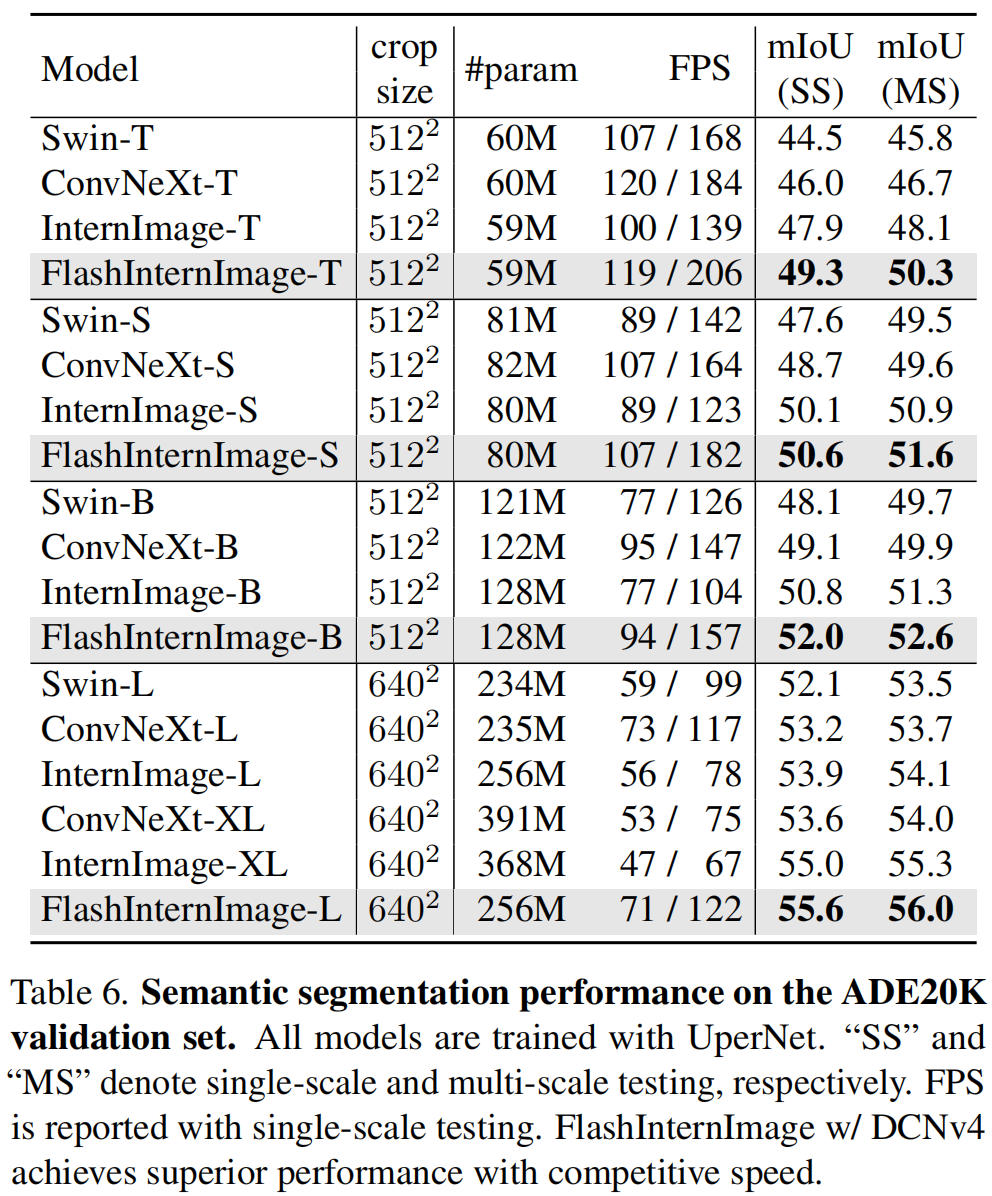
上右表给出了ADE20K任务上不同方案性能对比,可以看到:FlashInternImage去的了更快速度、更高性能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号