基于 Jetson 在 kubeedge上 搭建 机器学习环境(docker/containerd)

基于 Jetson 在 kubeedge上 搭建 机器学习环境(docker/containerd)

operator开发工程师
发布于 2024-03-22 09:39:12
发布于 2024-03-22 09:39:12
应用的部署流程图
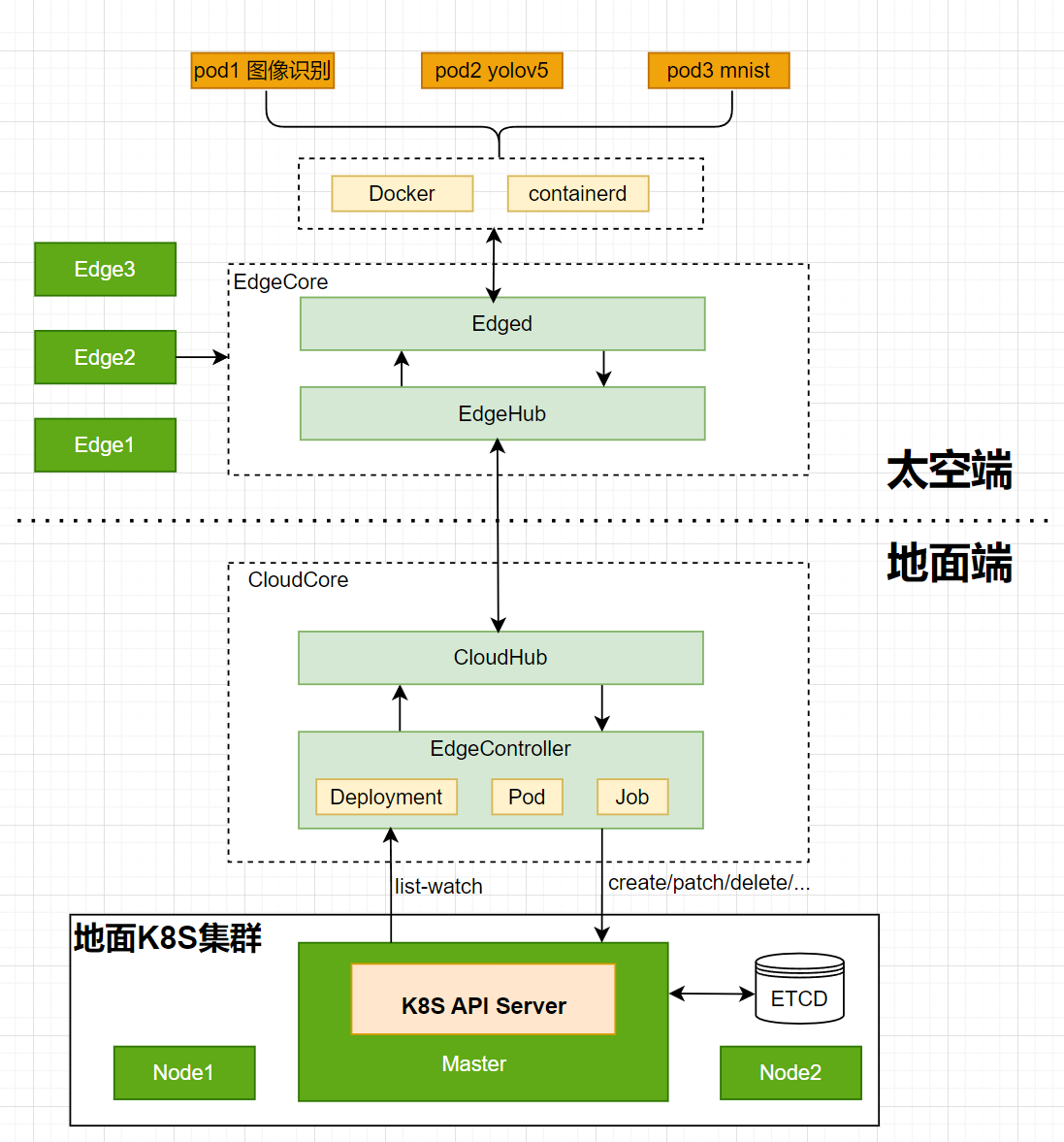
https://zhuyaguang-1308110266.cos.ap-shanghai.myqcloud.com/img/image-20240315111505144.png
环境配置
安装jtop
1 2 3 | sudo apt-get install python3-pip python3-dev -y sudo -H pip3 install jetson-stats sudo systemctl restart jtop.service |
|---|
安装JetPack
- 什么是 JetPack (https://developer.nvidia.com/embedded/develop/software)
The Jetson software stack begins with NVIDIA JetPack™ SDK, which provides Jetson Linux, developer tools, and CUDA-X accelerated libraries and other NVIDIA technologies. JetPack enables end-to-end acceleration for your AI applications, with NVIDIA TensorRT and cuDNN for accelerated AI inferencing, CUDA for accelerated general computing, VPI for accelerated computer vision and image processing, Jetson Linux API’s for accelerated multimedia, and libArgus and V4l2 for accelerated camera processing. NVIDIA container runtime is also included in JetPack, enabling cloud-native technologies and workflows at the edge. Transform your experience of developing and deploying software by containerizing your AI applications and managing them at scale with cloud-native technologies. Jetson Linux provides the foundation for your applications with a Linux kernel, bootloader, NVIDIA drivers, flashing utilities, sample filesystem, and toolchains for the Jetson platform. It also includes security features, over-the-air update capabilities and much more. JetPack will soon come with a collection of system services which are fundamental capabilities for building edge AI solutions. These services will simplify integration into developer workflows and spare them the arduous task of building them from the ground up.
- JetPack 组成
- 安装命令
1 2 3 4 | sudo apt update sudo apt install nvidia-jetpack sudo apt show nvidia-jetpack |
|---|
参考文档:NVIDIA JetPack Documentation
- 无法安装,更换镜像源
1 2 3 4 5 6 7 8 Please edit your nvidia-l4t-apt-source.list to r34.1: deb https://repo.download.nvidia.com/jetson/common r34.1 main deb https://repo.download.nvidia.com/jetson/t234 r34.1 main Run below command to upgrade and install sdk components: sudo apt dist-upgrade sudo reboot sudo apt install nvidia-jetpack
安装 NVIDIA Container Toolkit
1 2 3 4 | sudo apt-get install -y nvidia-container-toolkit sudo nvidia-ctk runtime configure --runtime=containerd sudo systemctl restart containerd |
|---|
安装教程:Installing the NVIDIA Container Toolkit
故障排除:Trobleshooting
nvidia-docker 与 nvidia container runtime 的区别
地卫二 Jetson安装组件版本信息
- nvidia-ctk 版本信息:NVIDIA Container Toolkit CLI version 1.11.0-rc.1
- jetpack 版本信息
安装 Docker
nvidia 在 jetson 上对 containerd 运行时支持不太友好
在普通的 GPU 服务器上是可以支持 containerd 运行
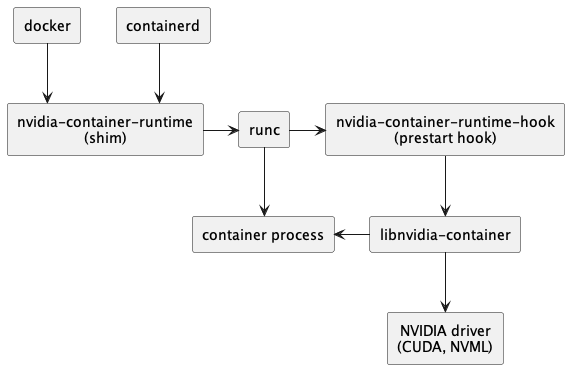
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/_images/runtime-architecture.png
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | sudo apt-get update sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg \ lsb-release curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.io |
|---|
Nvida 官方的机器学习 docker 镜像
其中 l4t-base container 是基础镜像,可以在此基础上构建。
例如:
1 2 3 4 5 6 7 8 9 10 | FROM nvcr.io/nvidia/l4t-base:r32.4.2 WORKDIR / RUN apt update && apt install -y --fix-missing make g++ python3-pip libhdf5-serial-dev hdf5-tools libhdf5-dev \ zlib1g-dev zip libjpeg8-dev liblapack-dev libblas-dev gfortran python3-h5py && \ pip3 install --no-cache-dir --upgrade pip && \ pip3 install --no-cache-dir --upgrade testresources setuptools cython && \ pip3 install --pre --no-cache-dir --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v44 tensorflow && \ apt-get clean CMD [ "bash" ] |
|---|
应用部署
手动部署
镜像准备
- pytorch 训练代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 | from __future__ import print_function import argparse import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms from torch.optim.lr_scheduler import StepLR class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout(0.25) self.dropout2 = nn.Dropout(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return output def train(args, model, device, train_loader, optimizer, epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % args.log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) if args.dry_run: break def test(model, device, test_loader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability correct += pred.eq(target.view_as(pred)).sum().item() test_loss /= len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset))) def main(): # Training settings parser = argparse.ArgumentParser(description='PyTorch MNIST Example') parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default: 64)') parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N', help='input batch size for testing (default: 1000)') parser.add_argument('--epochs', type=int, default=14, metavar='N', help='number of epochs to train (default: 14)') parser.add_argument('--lr', type=float, default=1.0, metavar='LR', help='learning rate (default: 1.0)') parser.add_argument('--gamma', type=float, default=0.7, metavar='M', help='Learning rate step gamma (default: 0.7)') parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training') parser.add_argument('--no-mps', action='store_true', default=False, help='disables macOS GPU training') parser.add_argument('--dry-run', action='store_true', default=False, help='quickly check a single pass') parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)') parser.add_argument('--log-interval', type=int, default=10, metavar='N', help='how many batches to wait before logging training status') parser.add_argument('--save-model', action='store_true', default=False, help='For Saving the current Model') args = parser.parse_args() use_cuda = not args.no_cuda and torch.cuda.is_available() use_mps = not args.no_mps and torch.backends.mps.is_available() torch.manual_seed(args.seed) if use_cuda: device = torch.device("cuda") elif use_mps: device = torch.device("mps") else: device = torch.device("cpu") train_kwargs = {'batch_size': args.batch_size} test_kwargs = {'batch_size': args.test_batch_size} if use_cuda: cuda_kwargs = {'num_workers': 1, 'pin_memory': True, 'shuffle': True} train_kwargs.update(cuda_kwargs) test_kwargs.update(cuda_kwargs) transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) dataset1 = datasets.MNIST('../data', train=True, download=True, transform=transform) dataset2 = datasets.MNIST('../data', train=False, transform=transform) train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs) test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs) model = Net().to(device) optimizer = optim.Adadelta(model.parameters(), lr=args.lr) scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma) for epoch in range(1, args.epochs + 1): train(args, model, device, train_loader, optimizer, epoch) test(model, device, test_loader) scheduler.step() if args.save_model: torch.save(model.state_dict(), "mnist_cnn.pt") if __name__ == '__main__': main() |
|---|
Dockerfile 打镜像
1 2 3 | FROM nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3 COPY pytorch-mnist.py /home/ |
|---|
docker 运行命令:
1 2 3 | sudo docker run -it --rm --runtime nvidia --network host -v /home/user/project:/location/in/container nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3 python3 pytorch-minst.py |
|---|
- 镜像转换
1 2 3 | docker save nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3 -o pytorch.tar ctr -n k8s.io images import pytorch.tar |
|---|
- containerd 运行命令:
1 2 3 4 5 6 7 8 9 | ctr c create nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3 gpu-demo ctr task start -d gpu-demo ctr task exec --exec-id 2 -t gpu-demo sh python3 pytorch-minst.py ctr tasks kill gpu-demo --signal SIGKILL |
|---|
kubectl apply 部署
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | apiVersion: v1 kind: Pod metadata: name: gpu-test spec: nodeSelector: kubernetes.io/hostname: edge1 containers: - image: docker.io/library/pytorch-mnist:latest imagePullPolicy: IfNotPresent name: gpu-test command: - "/bin/bash" - "-c" - "python3 /home/pytorch-mnist.py" restartPolicy: Never |
|---|
界面部署
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | apiVersion: apps/v1 kind: Deployment metadata: name: gpu-test labels: app: gpu-test spec: replicas: 1 selector: matchLabels: app: gpu-test template: metadata: labels: app: gpu-test spec: containers: - name: gpu-test image: docker.io/library/pytorch-mnist:latest imagePullPolicy: IfNotPresent command: - "/bin/bash" - "-c" - "python3 /home/pytorch-mnist.py" strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 25% maxSurge: 25% |
|---|
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-03-21,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号