深度学习500问——Chapter06: 循环神经网络(RNN)(3)

深度学习500问——Chapter06: 循环神经网络(RNN)(3)

JOYCE_Leo16
发布于 2024-04-09 08:19:41
发布于 2024-04-09 08:19:41
6.11 LSTM
6.11.1 LSTM的产生原因
RNN在处理长期依赖(时间序列上距离较远的节点)时会遇到巨大的困难,因为计算距离较远的节点之间联系时会涉及雅可比矩阵的多次相乘,会造成梯度消失或者梯度膨胀的现象。为了解决该问题,研究人员提出了许多解决办法,例如ESN(Echo State Network),增加有漏单元(Leaky Units)等等,其中成功应用最广泛的就是门限RNN(Gated RNN),而LSTM就是门限RNN中最著名的一种。有漏单元通过设计连接间的权重系数,从而允许RNN累积距离较远节点间的长期联系;而门限RNN则泛化了这样的思想,允许在不同时刻改变该系数,且允许网络忘记当前已经积累的信息。
6.11.2 图解标准RNN和LSTM的区别
所有RNN都具有一种重复神经网络模块的链式的形式。在标准的RNN中,这个重复的模块只有一个非常简单的结构,例如一个tanh层,如下图所示:
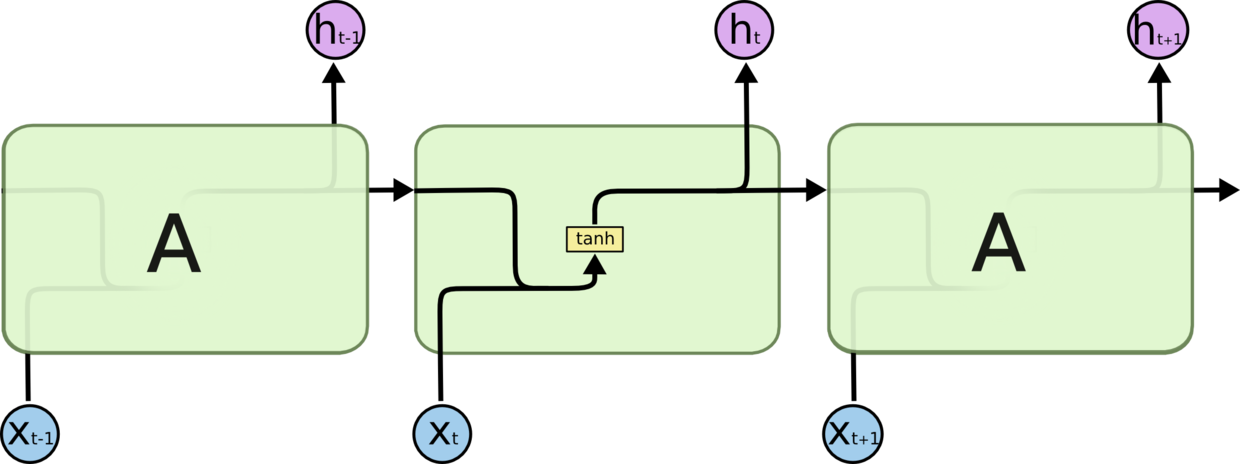
LSTM同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于单一神经网络层,这里有四个,以一种非常特殊的方式进行交互。

注:上图图标具体含义如下所示:

上图中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表pointwise的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
6.11.3 LSTM核心思想图解
LSTM的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。示意图如下所示:
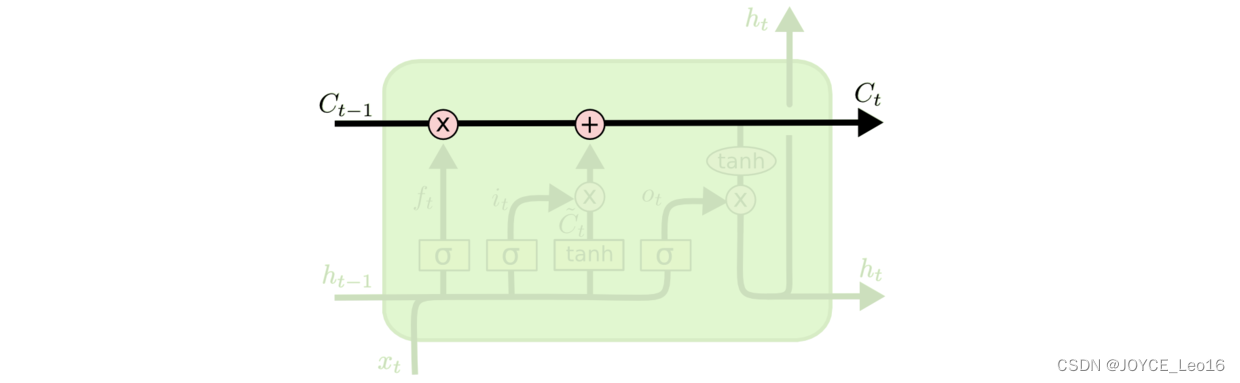
LSTM有通过精心设计的称作“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个sigmoid神经网络层和一个pointwise乘法操作。示意图如下:
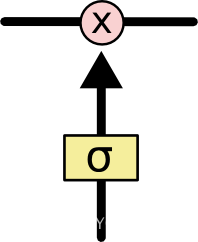
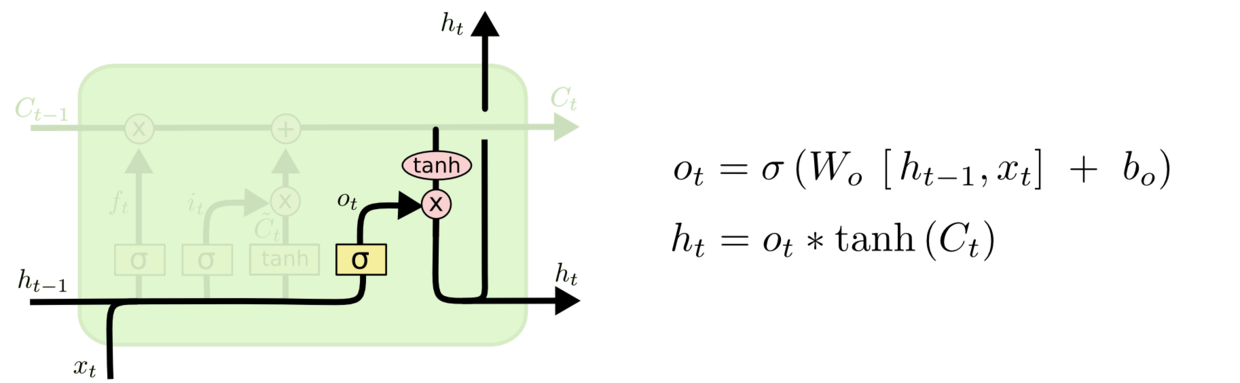
LSTM拥有三个门,分别是忘记层门,输入层门和输出层门,来保护和控制细胞状态。
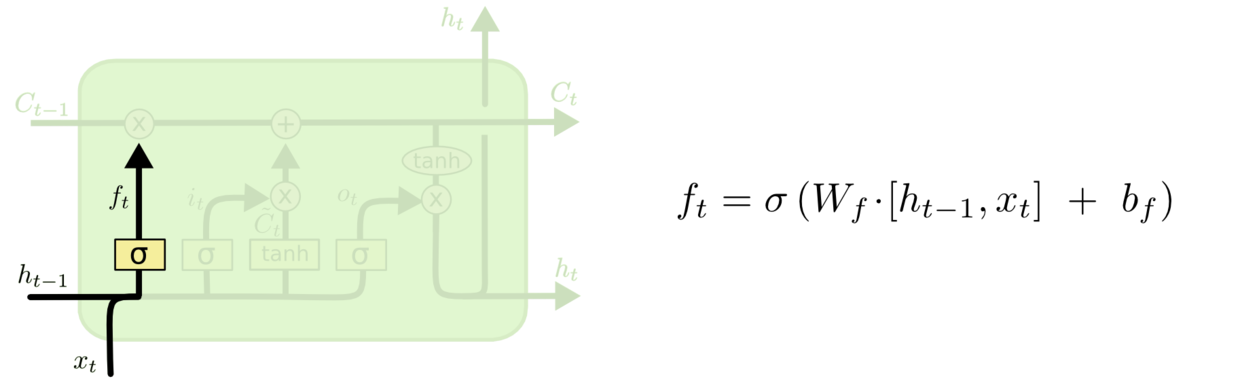
忘记层门
- 作用对象:细胞状态。
- 作用:将细胞状态中的信息选择性的遗忘。
- 操作步骤:该门会读取
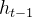
和
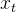
,输出一个在0到1之间的数值给每个在细胞状态
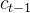
中的数字。1表示“完全保留”,0表示“完全舍弃”。示意图如下:
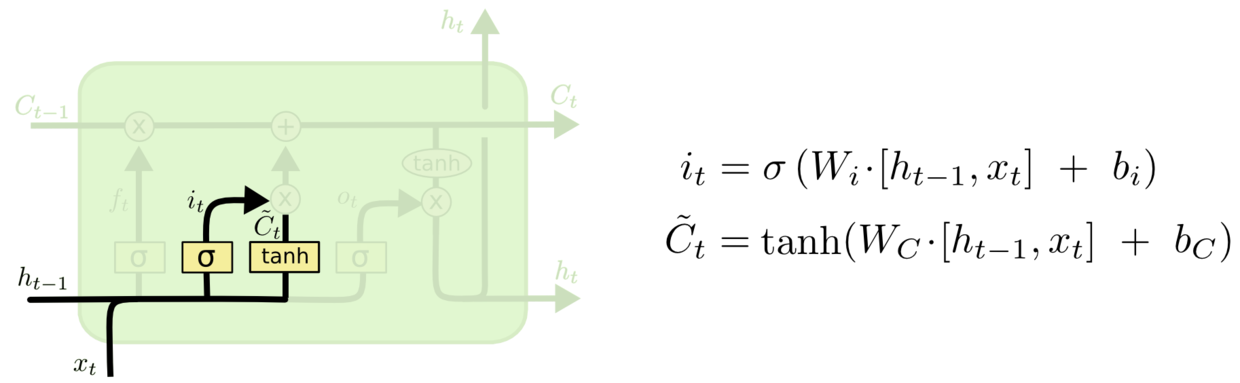
输入层门
- 作用对象:细胞状态。
- 作用:将新的信息选择性的记录到细胞状态中。
- 操作步骤:
Step1:sigmoid层称“输入门层”决定什么值我们将要更新。
Step2:tanh层创建一个新的候选值向量
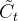
加入到状态中。其示意图如下:
Step3:将
更新为
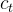
。将旧状态与
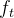
相乘。丢弃掉我们确定需要丢弃的信息。接着加上
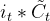
得到新的候选值,根据我们决定更新每个状态的程度进行变化。其示意图如下:

输出层门
- 作用对象:隐藏层
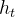
。
- 作用:确定输出什么值。
- 操作步骤:
Step1:通过sigmoid层来确定细胞状态的哪个部分将输出。
Step2:把细胞状态通过tanh进行处理,并将它和sigmoid门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
其示意图如下所示:
6.11.4 LSTM流行的变体
增加peephole连接
在正常的LSTM结构中,Gers F A等人提出增加peephole连接,可以门层接受细胞状态的输入。示意图如下所示:
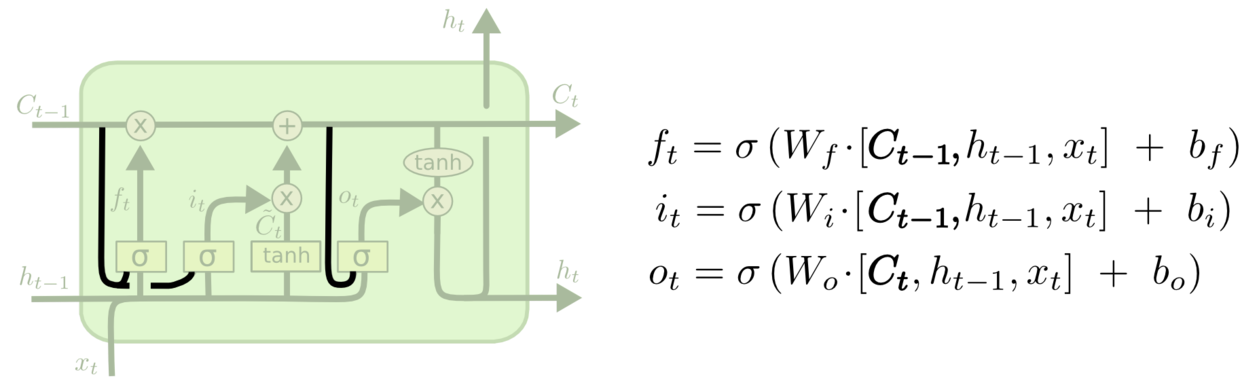
对忘记门和输入门同时确定
不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是一同做出决定。示意图如下所示:
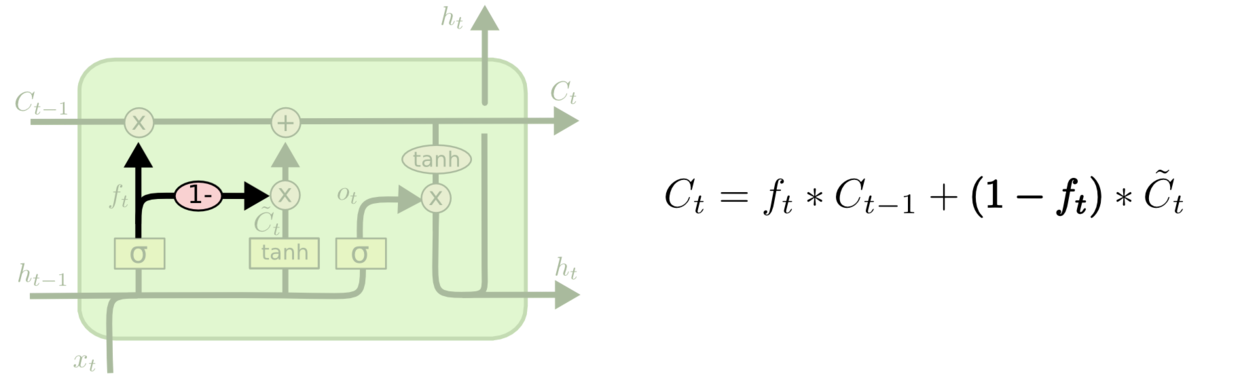
Gated Recurrent Unit(GRU)
由Kyunghyun Cho等人提出的Gated Recurrent Unit(GRU),其将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。其示意图如下所示:

最终模型的比标准的LSTM模型要简单,也是非常流行的变体。
6.12 LSTMs与GRUs的区别
LSTMs与GRUs的区别如图所示:
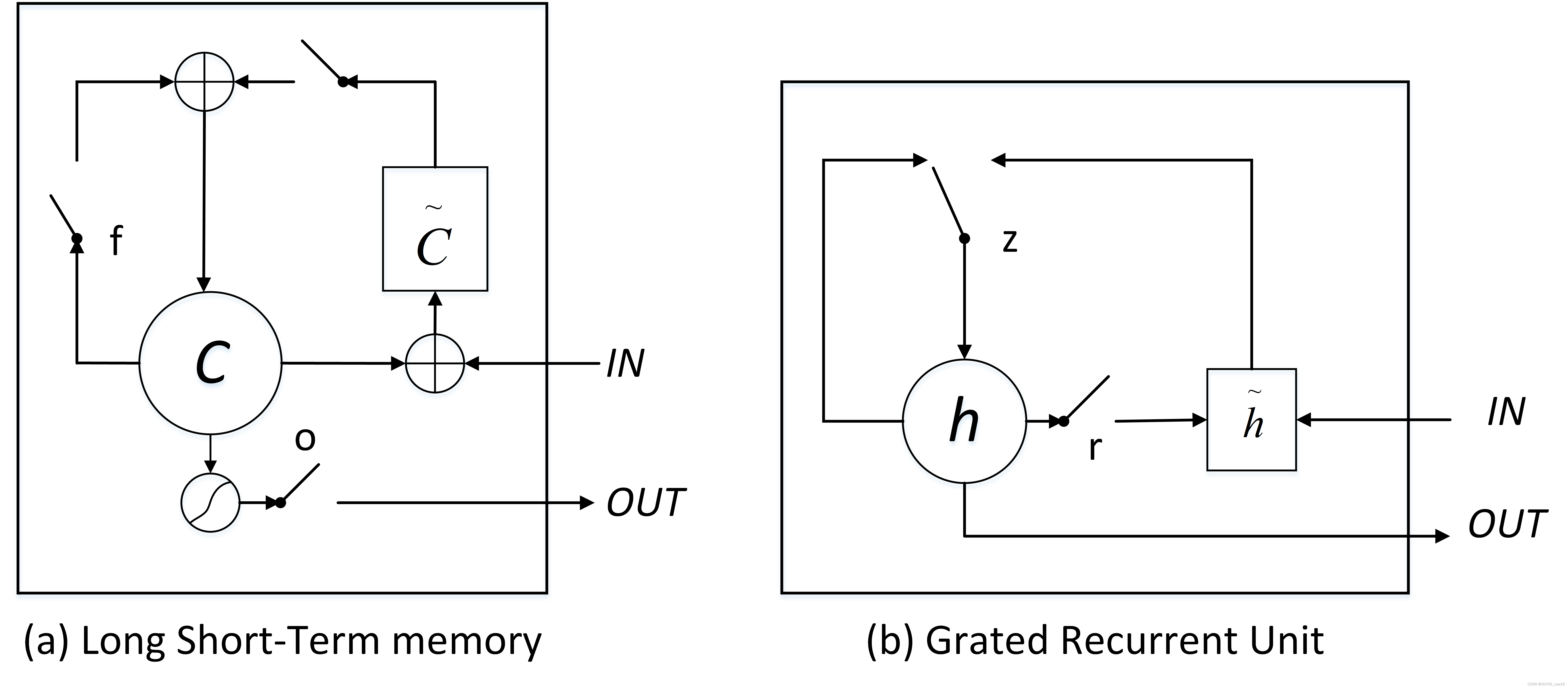
从上图可以看出,二者结构十分相似,不同在于:
- new memory都是根据之前state及input进行计算,但是GRUs中有一个reset gate控制之前的state的进入量,而在LSTMs里没有类似gate;
- 产生新的state的方式不同,LSTMs有两个不同的gate,分别是forget gate(f gate)和input gate(i gate),而GRUs只有一种update gate(z gate);
- LSTMs对新产生的state可以通过output gate(o gate)进行调节,而GRUs对输出无任何调节。
6.13 RNNs在NLP中的典型应用
1. 语言模型与文本生成(Language Modeling and Generating Text)
给定一组单词序列,需要根据前面单词预测每个单词出现的可能性。语言模型能够评估某个语句正确的可能性,可能性越大,语句越正确。另一种应用便是使用生成模型预测下一个单词的出现概率,从而利用输出概率的采样生成新的文本。
2. 机器翻译(Machine Translation)
机器翻译是将一种源语言语句变成意思相同的另一种源语言语句,如将英语语句变成同样意思的中文语句。与语言模型关键的区别在于,需要将源语言语句序列输入后,才进行输出,即输出第一个单词时,便需要从完整的输入序列中进行获取。
3. 语音识别(Speech Recognition)
语音识别是指给定一段声波的声音信号,预测该声波对应的某种指定源语言语句以及计算该语句的概率值。
4. 图像描述生成(Generating Image Description)
同卷积神经网络一样,RNNs已经在对无标图像描述自动生成中得到应用。CNNs与RNNs结合也被应用于图像描述自动生成。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-04-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号