m7s v5 中实现优雅内存分配器


v4 中使用了链表存储了不同大小的内存块的方式进行内存池的实现,实际测试中发现内存浪费比较严重,因此如何设计出使用效率高,操作简洁的内存池就成了 v5 的一个任务。
使用 make
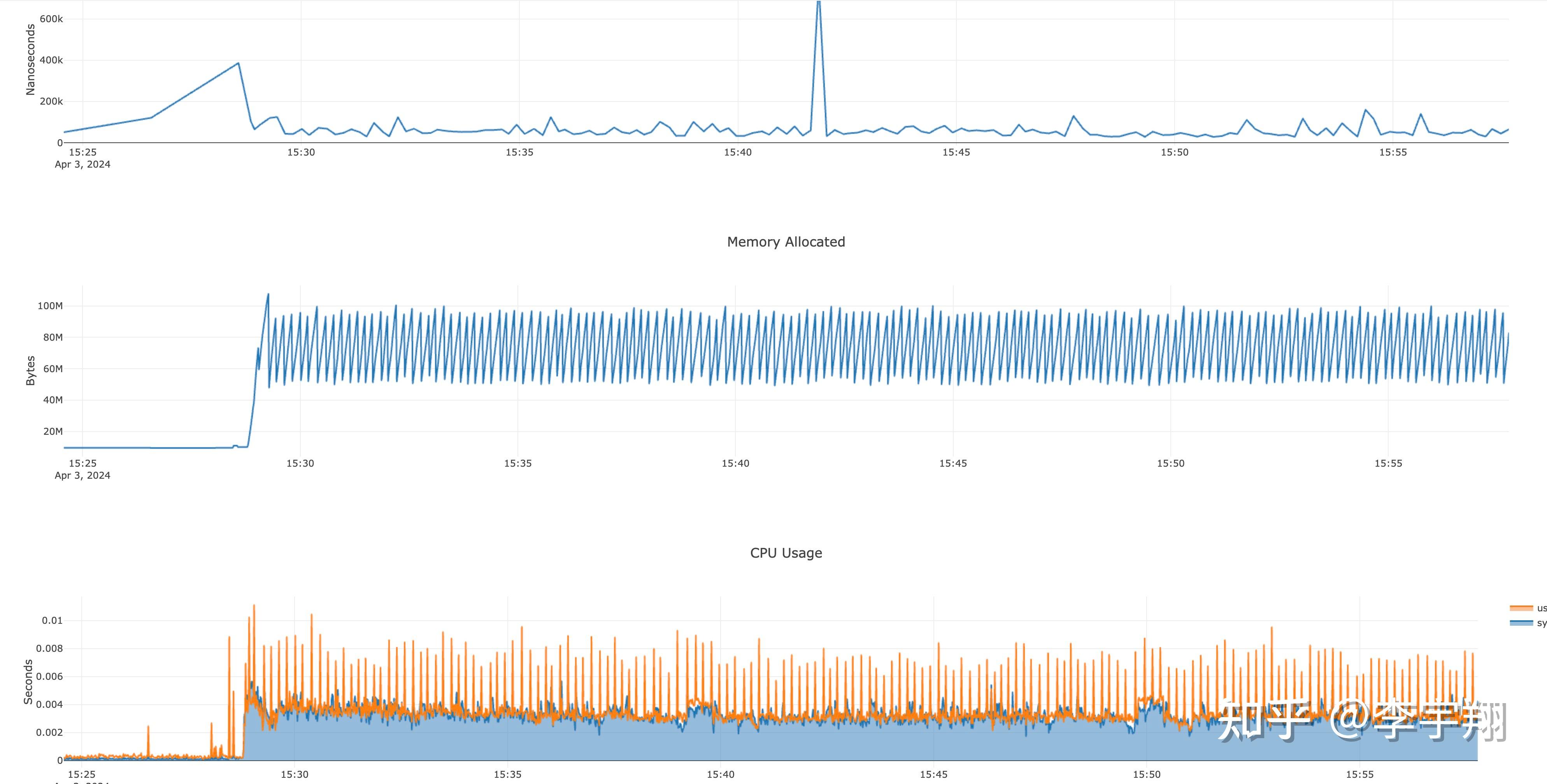
使用 go 原生的内存分配,意味着交给 GC 来回收,在m7s中测试发现gc 占据非常大的开销。
自定义内存分配
C 风格的内存分配
void * mem = malloc(100)
free(mem)这种分配方式最广为人知,也是最简洁易懂的,因此如果能实现这种方式,是最佳的。
设想一下
func (ma *MemoryAllocator) Malloc(size int) (memory []byte) {
}
func (ma *MemoryAllocator) Free(memory []byte) {
}问题:如何在 Free 的时候知道是哪块内存?如果把这个字节数组直接存储就会回到 v4 的版本,显然不是我们想要的。 我们想要的是在一块大的数组中切割分配,这样才能有效利用内存。
切片分配
假设有一个大数组,用来缓存内存,防止 GC
var mem = make([]byte,65535)分配内存,就是切片
s1 := mem[0:1024]分配第二块内存s2
s2 := mem[1024:2048]最简单的方式就是记录一个已经分配的索引,第一次为 0,第二次为 1024
type MemoryAllocator struct {
start int64
memory []byte
}
func (ma *MemoryAllocator) Malloc(size int) (memory []byte) {
memory = ma.memory[ma.start:size]
ma.start+= size
return
}回收
内存切出去容易,如何回收呢?
ma.Free(s2)如何知道 s2 属于哪一部分呢?即使知道,如何修改原来的结构体使得下次分配可以利用回收过的内存呢?
使用附加信息
这种方式,就和 v4 一样,将额外的信息随同分配的内存给出去,回收的时候再一起带回来,但是不够简洁,我们希望回收的时候就是传[]byte
判断指针
我们知道同一块内存的底层的指针值肯定是相同的,即使切片被浅复制也一样。
ptr := uintptr(unsafe.Pointer(&mem[0]))当然,有可能传入的切片长度为 0,可以用下面的方法规避
ptr := uintptr(unsafe.Pointer(&mem[:1][0]))有了这个指针值,我只需要和内存池的起始指针进行比较,就可以得到在内存池中的偏移。从而为回收奠定基础。
标记
为了回收再利用,需要对可以分配的内存信息进行存储,这个信息就是标记偏移地址段,即 start:end。 可以用链表存储,[start,end],[start,end],[start,end],[start,end]
每一段代表可用的内存。当回收内存时,只需按照大小顺序插入这个链表即可
用数组也可以,但是由于数组对随机插入性能较差,因此用链表更合适
当然如果前一个 end 等于下一个 start,就可以合并: 例如[1:1024],[1024,2048] 就可以合并成 [1:2048],相当于碎片整理。
实现
type MemoryAllocator struct {
start int64
memory []byte
Size int
blocks *List[Block]
}
func NewMemoryAllocator(size int) (ret *MemoryAllocator) {
ret = &MemoryAllocator{
Size: size,
memory: make([]byte, size),
blocks: NewList[Block](),
}
ret.start = int64(uintptr(unsafe.Pointer(&ret.memory[0])))
ret.blocks.PushBack(Block{0, size})
return
}具体代码可以到仓库 github.com/langhuihui/monibuca 的 v5 分支里面找到
进阶
单个内存分配器可分配的内存有限,那么一个可以不断增长的需求如何满足呢? 可以实现动态创建内存分配器的高阶内存分配器就可以解决了
type ScalableMemoryAllocator []*MemoryAllocator原理也很简单,不够就创建,Free 的时候就挨个查找。
最终如下图,内存不再不停的申请了,CPU 也没有了毛刺。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-04-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号